 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsotuning With Applications To Scale-Free Online Learning
Dec 29, 2021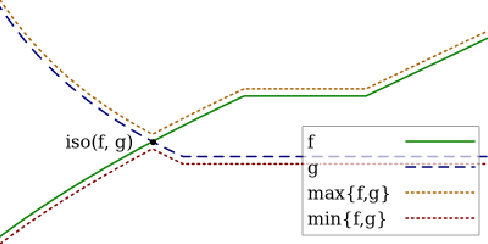
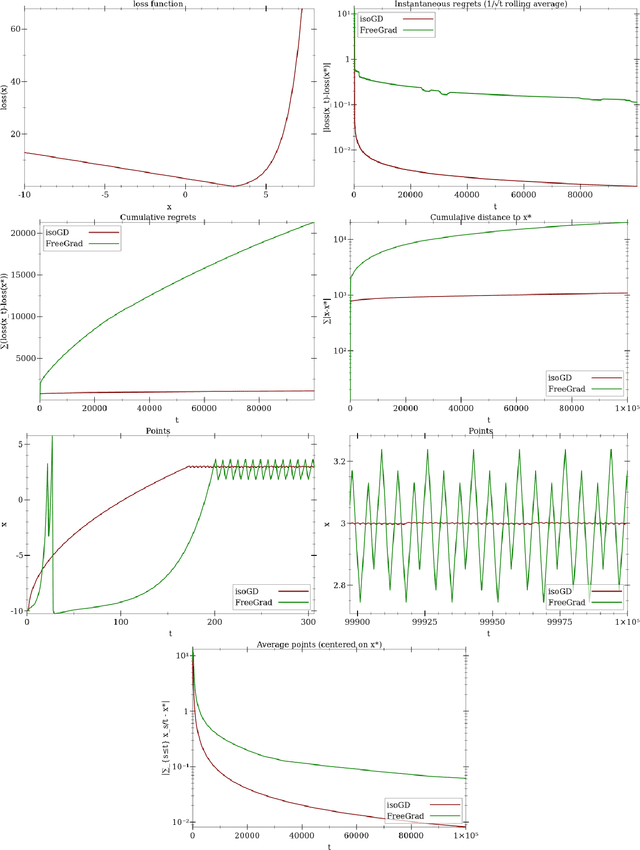
We extend and combine several tools of the literature to design fast, adaptive, anytime and scale-free online learning algorithms. Scale-free regret bounds must scale linearly with the maximum loss, both toward large losses and toward very small losses. Adaptive regret bounds demonstrate that an algorithm can take advantage of easy data and potentially have constant regret. We seek to develop fast algorithms that depend on as few parameters as possible, in particular they should be anytime and thus not depend on the time horizon. Our first and main tool, isotuning, is a generalization of the idea of balancing the trade-off of the regret. We develop a set of tools to design and analyze such learning rates easily and show that they adapts automatically to the rate of the regret (whether constant, $O(\log T)$, $O(\sqrt{T})$, etc.) within a factor 2 of the optimal learning rate in hindsight for the same observed quantities. The second tool is an online correction, which allows us to obtain centered bounds for many algorithms, to prevent the regret bounds from being vacuous when the domain is overly large or only partially constrained. The last tool, null updates, prevents the algorithm from performing overly large updates, which could result in unbounded regret, or even invalid updates. We develop a general theory using these tools and apply it to several standard algorithms. In particular, we (almost entirely) restore the adaptivity to small losses of FTRL for unbounded domains, design and prove scale-free adaptive guarantees for a variant of Mirror Descent (at least when the Bregman divergence is convex in its second argument), extend Adapt-ML-Prod to scale-free guarantees, and provide several other minor contributions about Prod, AdaHedge, BOA and Soft-Bayes.
Proving Theorems using Incremental Learning and Hindsight Experience Replay
Dec 20, 2021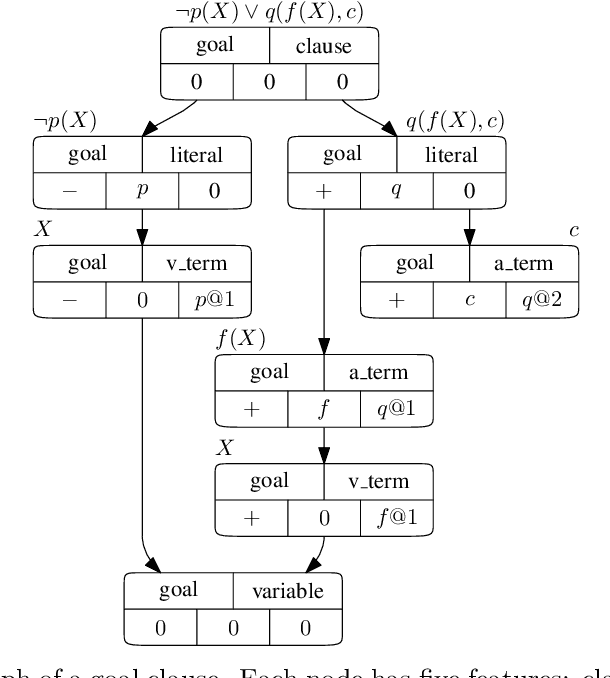
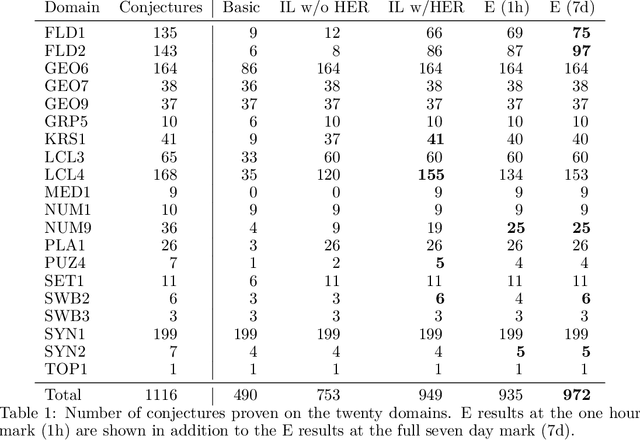
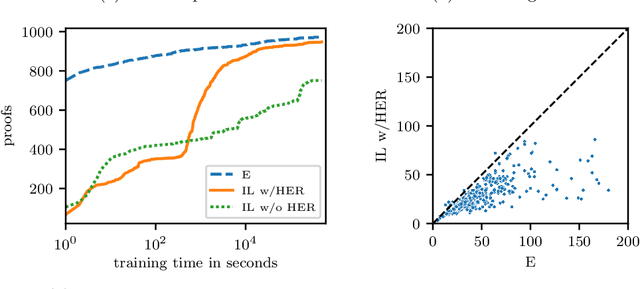
Traditional automated theorem provers for first-order logic depend on speed-optimized search and many handcrafted heuristics that are designed to work best over a wide range of domains. Machine learning approaches in literature either depend on these traditional provers to bootstrap themselves or fall short on reaching comparable performance. In this paper, we propose a general incremental learning algorithm for training domain specific provers for first-order logic without equality, based only on a basic given-clause algorithm, but using a learned clause-scoring function. Clauses are represented as graphs and presented to transformer networks with spectral features. To address the sparsity and the initial lack of training data as well as the lack of a natural curriculum, we adapt hindsight experience replay to theorem proving, so as to be able to learn even when no proof can be found. We show that provers trained this way can match and sometimes surpass state-of-the-art traditional provers on the TPTP dataset in terms of both quantity and quality of the proofs.
Policy-Guided Heuristic Search with Guarantees
Mar 21, 2021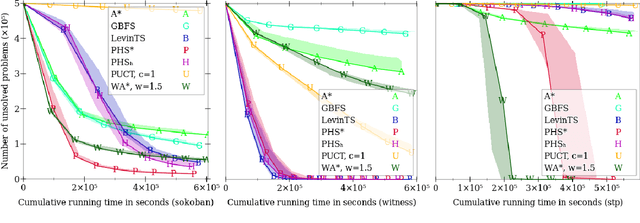
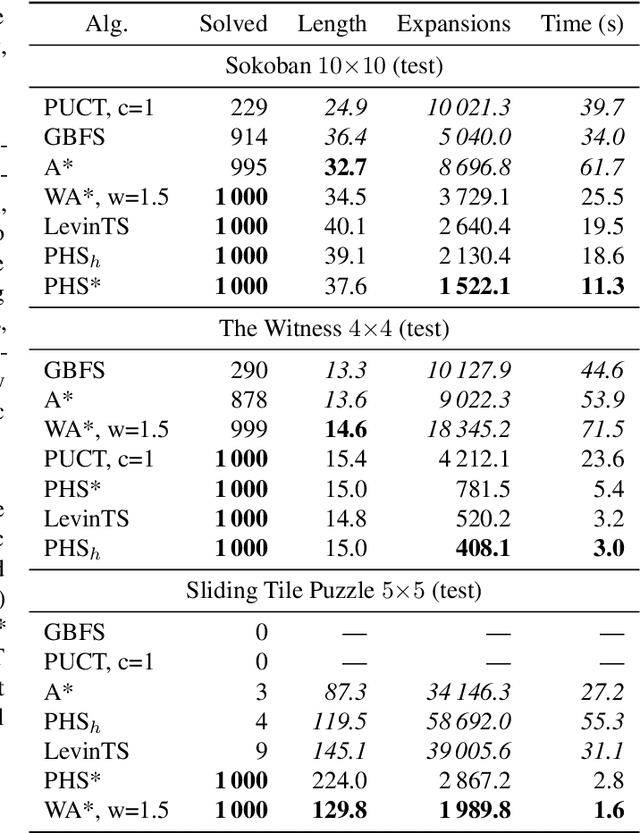


The use of a policy and a heuristic function for guiding search can be quite effective in adversarial problems, as demonstrated by AlphaGo and its successors, which are based on the PUCT search algorithm. While PUCT can also be used to solve single-agent deterministic problems, it lacks guarantees on its search effort and it can be computationally inefficient in practice. Combining the A* algorithm with a learned heuristic function tends to work better in these domains, but A* and its variants do not use a policy. Moreover, the purpose of using A* is to find solutions of minimum cost, while we seek instead to minimize the search loss (e.g., the number of search steps). LevinTS is guided by a policy and provides guarantees on the number of search steps that relate to the quality of the policy, but it does not make use of a heuristic function. In this work we introduce Policy-guided Heuristic Search (PHS), a novel search algorithm that uses both a heuristic function and a policy and has theoretical guarantees on the search loss that relates to both the quality of the heuristic and of the policy. We show empirically on the sliding-tile puzzle, Sokoban, and a puzzle from the commercial game `The Witness' that PHS enables the rapid learning of both a policy and a heuristic function and compares favorably with A*, Weighted A*, Greedy Best-First Search, LevinTS, and PUCT in terms of number of problems solved and search time in all three domains tested.
Training a First-Order Theorem Prover from Synthetic Data
Mar 05, 2021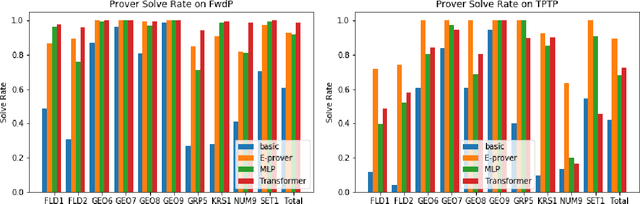
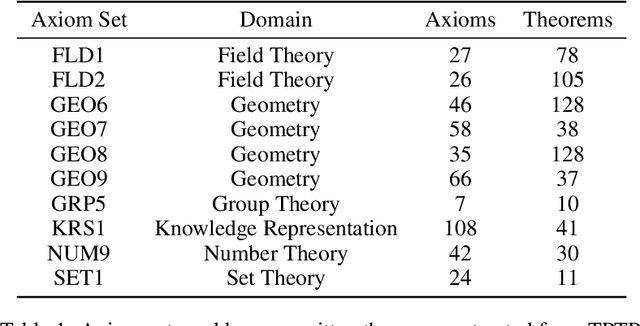
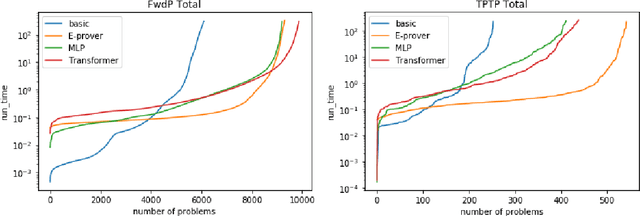
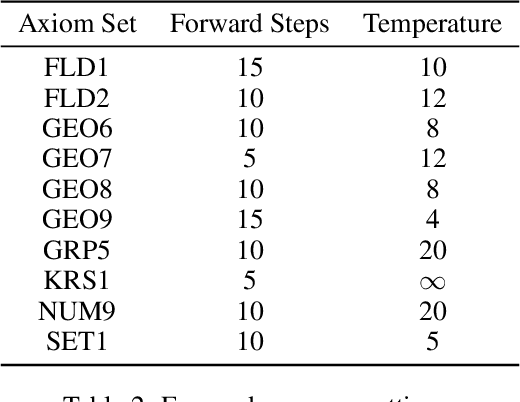
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training purely with synthetically generated theorems, without any human data aside from axioms. We use these theorems to train a neurally-guided saturation-based prover. Our neural prover outperforms the state-of-the-art E-prover on this synthetic data in both time and search steps, and shows significant transfer to the unseen human-written theorems from the TPTP library, where it solves 72\% of first-order problems without equality.
Avoiding Side Effects By Considering Future Tasks
Oct 15, 2020

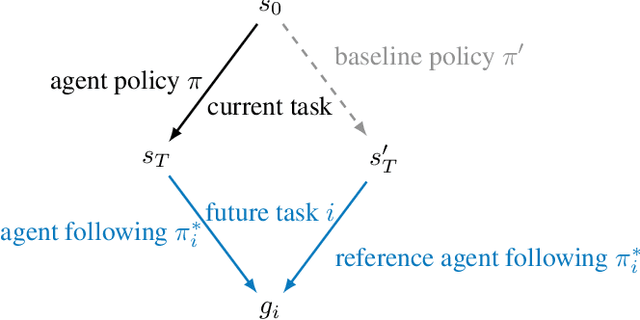
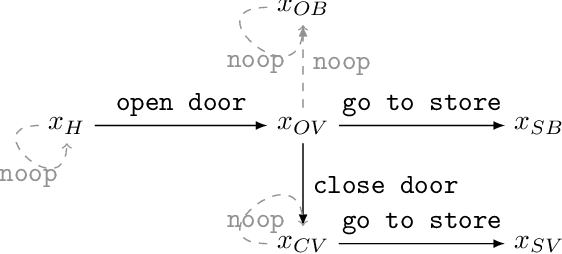
Designing reward functions is difficult: the designer has to specify what to do (what it means to complete the task) as well as what not to do (side effects that should be avoided while completing the task). To alleviate the burden on the reward designer, we propose an algorithm to automatically generate an auxiliary reward function that penalizes side effects. This auxiliary objective rewards the ability to complete possible future tasks, which decreases if the agent causes side effects during the current task. The future task reward can also give the agent an incentive to interfere with events in the environment that make future tasks less achievable, such as irreversible actions by other agents. To avoid this interference incentive, we introduce a baseline policy that represents a default course of action (such as doing nothing), and use it to filter out future tasks that are not achievable by default. We formally define interference incentives and show that the future task approach with a baseline policy avoids these incentives in the deterministic case. Using gridworld environments that test for side effects and interference, we show that our method avoids interference and is more effective for avoiding side effects than the common approach of penalizing irreversible actions.
Logarithmic Pruning is All You Need
Jun 22, 2020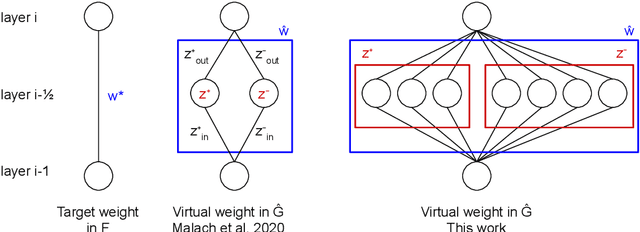
The Lottery Ticket Hypothesis is a conjecture that every large neural network contains a subnetwork that, when trained in isolation, achieves comparable performance to the large network. An even stronger conjecture has been proven recently: Every sufficiently overparameterized network contains a subnetwork that, even without training, achieves comparable accuracy to the trained large network. This theorem, however, relies on a number of strong assumptions and guarantees a polynomial factor on the size of the large network compared to the target function. In this work, we remove the most limiting assumptions of this previous work while providing significantly tighter bounds: the overparameterized network only needs a logarithmic factor (in all variables but depth) number of neurons per weight of the target subnetwork.
Learning to Prove from Synthetic Theorems
Jun 19, 2020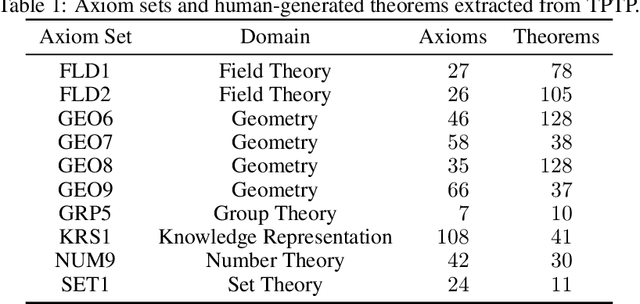
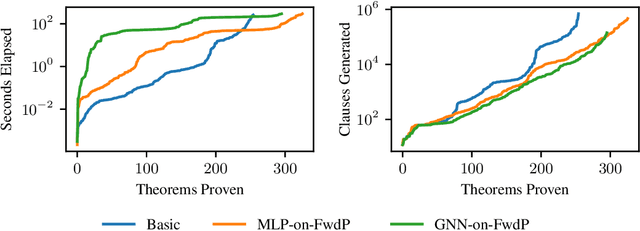
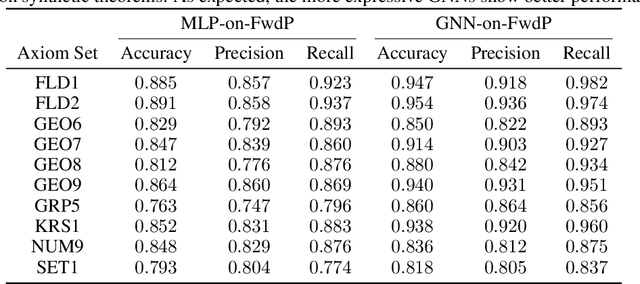
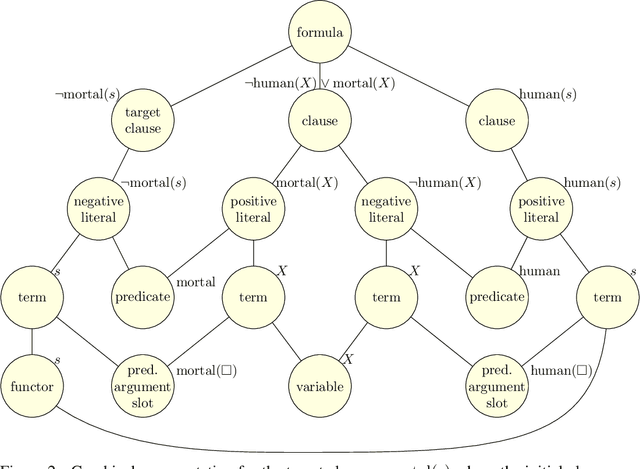
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training with synthetic theorems, generated from a set of axioms. We show that such theorems can be used to train an automated prover and that the learned prover transfers successfully to human-generated theorems. We demonstrate that a prover trained exclusively on synthetic theorems can solve a substantial fraction of problems in TPTP, a benchmark dataset that is used to compare state-of-the-art heuristic provers. Our approach outperforms a model trained on human-generated problems in most axiom sets, thereby showing the promise of using synthetic data for this task.
Pitfalls of learning a reward function online
Apr 28, 2020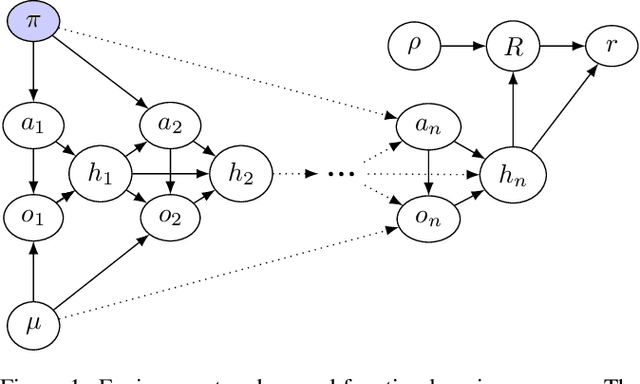
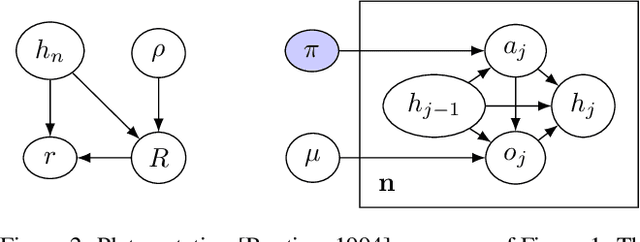
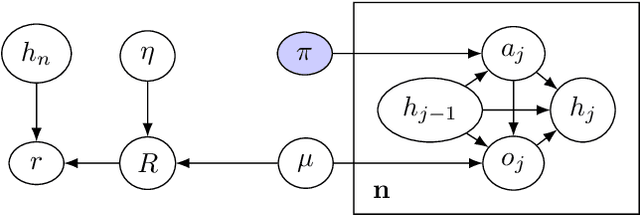

In some agent designs like inverse reinforcement learning an agent needs to learn its own reward function. Learning the reward function and optimising for it are typically two different processes, usually performed at different stages. We consider a continual (``one life'') learning approach where the agent both learns the reward function and optimises for it at the same time. We show that this comes with a number of pitfalls, such as deliberately manipulating the learning process in one direction, refusing to learn, ``learning'' facts already known to the agent, and making decisions that are strictly dominated (for all relevant reward functions). We formally introduce two desirable properties: the first is `unriggability', which prevents the agent from steering the learning process in the direction of a reward function that is easier to optimise. The second is `uninfluenceability', whereby the reward-function learning process operates by learning facts about the environment. We show that an uninfluenceable process is automatically unriggable, and if the set of possible environments is sufficiently rich, the converse is true too.
Iterative Budgeted Exponential Search
Jul 30, 2019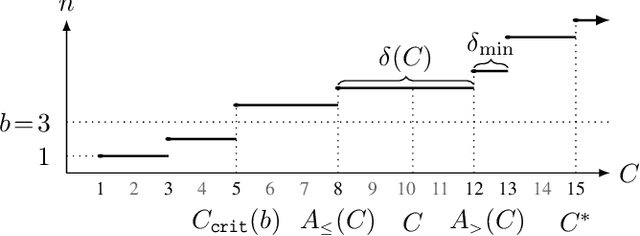
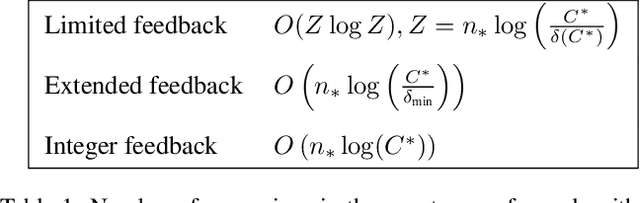
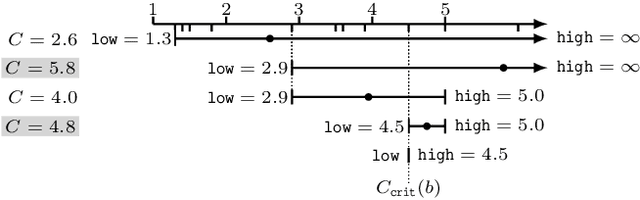
We tackle two long-standing problems related to re-expansions in heuristic search algorithms. For graph search, A* can require $\Omega(2^{n})$ expansions, where $n$ is the number of states within the final $f$ bound. Existing algorithms that address this problem like B and B' improve this bound to $\Omega(n^2)$. For tree search, IDA* can also require $\Omega(n^2)$ expansions. We describe a new algorithmic framework that iteratively controls an expansion budget and solution cost limit, giving rise to new graph and tree search algorithms for which the number of expansions is $O(n \log C)$, where $C$ is the optimal solution cost. Our experiments show that the new algorithms are robust in scenarios where existing algorithms fail. In the case of tree search, our new algorithms have no overhead over IDA* in scenarios to which IDA* is well suited and can therefore be recommended as a general replacement for IDA*.
Zooming Cautiously: Linear-Memory Heuristic Search With Node Expansion Guarantees
Jun 07, 2019
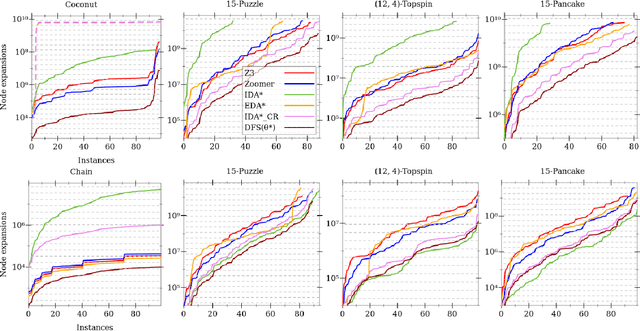

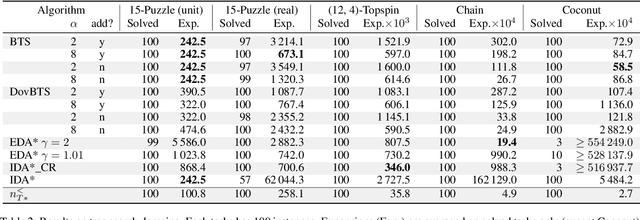
We introduce and analyze two parameter-free linear-memory tree search algorithms. Under mild assumptions we prove our algorithms are guaranteed to perform only a logarithmic factor more node expansions than A* when the search space is a tree. Previously, the best guarantee for a linear-memory algorithm under similar assumptions was achieved by IDA*, which in the worst case expands quadratically more nodes than in its last iteration. Empirical results support the theory and demonstrate the practicality and robustness of our algorithms. Furthermore, they are fast and easy to implement.