 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Scoring for Machine Learning Classifier Error Impact Evaluation
Paper and Code
Aug 06, 2025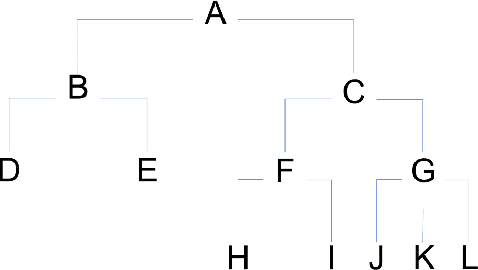
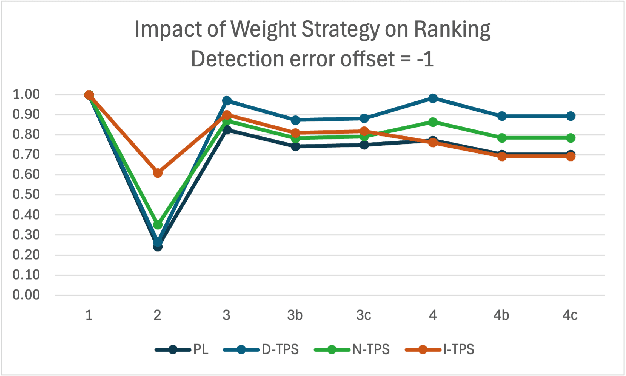
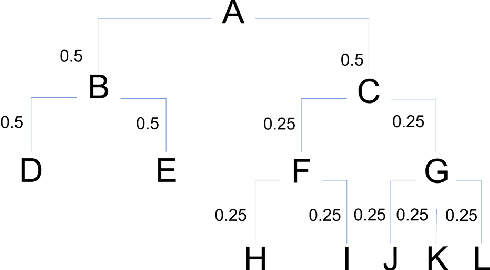
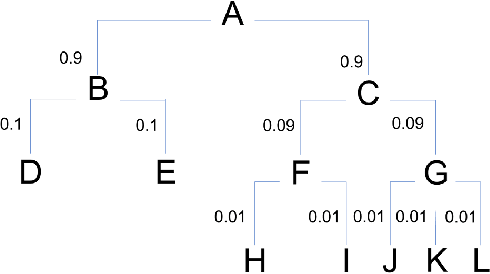
A common use of machine learning (ML) models is predicting the class of a sample. Object detection is an extension of classification that includes localization of the object via a bounding box within the sample. Classification, and by extension object detection, is typically evaluated by counting a prediction as incorrect if the predicted label does not match the ground truth label. This pass/fail scoring treats all misclassifications as equivalent. In many cases, class labels can be organized into a class taxonomy with a hierarchical structure to either reflect relationships among the data or operator valuation of misclassifications. When such a hierarchical structure exists, hierarchical scoring metrics can return the model performance of a given prediction related to the distance between the prediction and the ground truth label. Such metrics can be viewed as giving partial credit to predictions instead of pass/fail, enabling a finer-grained understanding of the impact of misclassifications. This work develops hierarchical scoring metrics varying in complexity that utilize scoring trees to encode relationships between class labels and produce metrics that reflect distance in the scoring tree. The scoring metrics are demonstrated on an abstract use case with scoring trees that represent three weighting strategies and evaluated by the kind of errors discouraged. Results demonstrate that these metrics capture errors with finer granularity and the scoring trees enable tuning. This work demonstrates an approach to evaluating ML performance that ranks models not only by how many errors are made but by the kind or impact of errors. Python implementations of the scoring metrics will be available in an open-source repository at time of publication.