 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeslimTrain -- A Stochastic Approximation Method for Training Separable Deep Neural Networks
Sep 28, 2021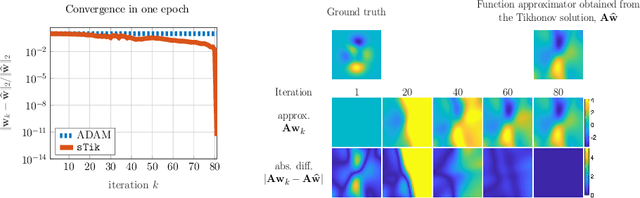
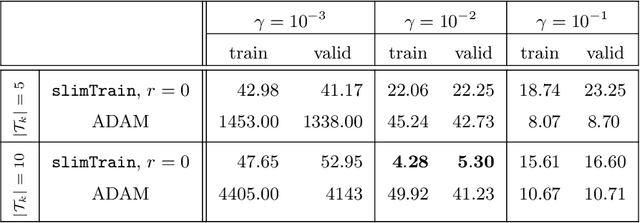
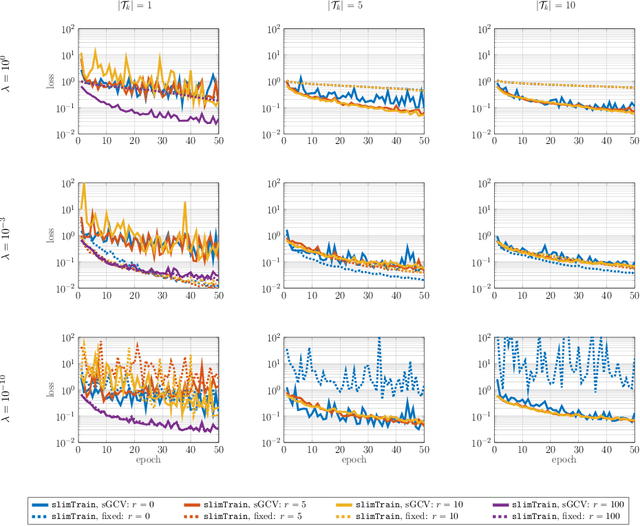
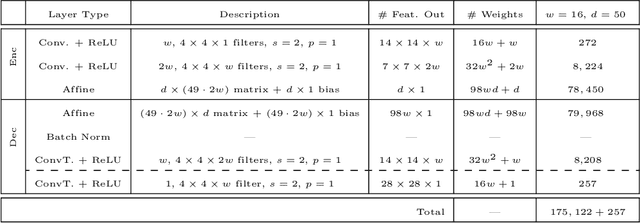
Deep neural networks (DNNs) have shown their success as high-dimensional function approximators in many applications; however, training DNNs can be challenging in general. DNN training is commonly phrased as a stochastic optimization problem whose challenges include non-convexity, non-smoothness, insufficient regularization, and complicated data distributions. Hence, the performance of DNNs on a given task depends crucially on tuning hyperparameters, especially learning rates and regularization parameters. In the absence of theoretical guidelines or prior experience on similar tasks, this requires solving many training problems, which can be time-consuming and demanding on computational resources. This can limit the applicability of DNNs to problems with non-standard, complex, and scarce datasets, e.g., those arising in many scientific applications. To remedy the challenges of DNN training, we propose slimTrain, a stochastic optimization method for training DNNs with reduced sensitivity to the choice hyperparameters and fast initial convergence. The central idea of slimTrain is to exploit the separability inherent in many DNN architectures; that is, we separate the DNN into a nonlinear feature extractor followed by a linear model. This separability allows us to leverage recent advances made for solving large-scale, linear, ill-posed inverse problems. Crucially, for the linear weights, slimTrain does not require a learning rate and automatically adapts the regularization parameter. Since our method operates on mini-batches, its computational overhead per iteration is modest. In our numerical experiments, slimTrain outperforms existing DNN training methods with the recommended hyperparameter settings and reduces the sensitivity of DNN training to the remaining hyperparameters.
An Introduction to Deep Generative Modeling
Mar 09, 2021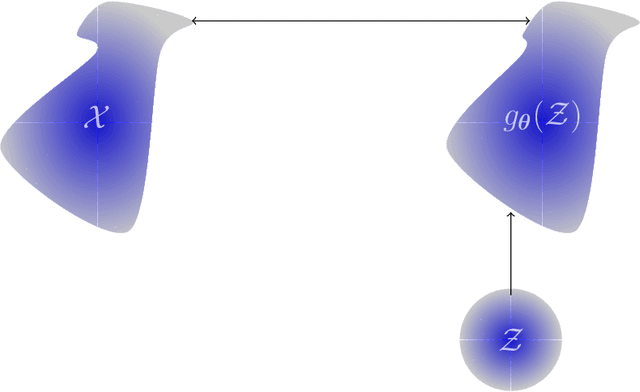
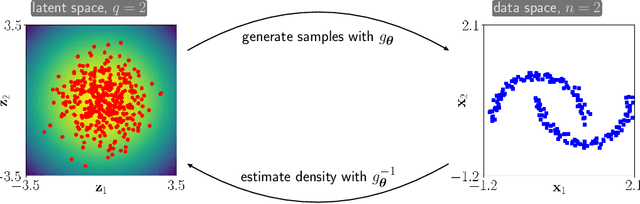
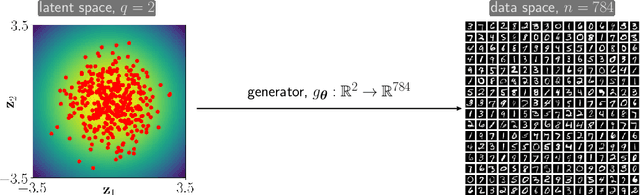
Deep generative models (DGM) are neural networks with many hidden layers trained to approximate complicated, high-dimensional probability distributions using a large number of samples. When trained successfully, we can use the DGMs to estimate the likelihood of each observation and to create new samples from the underlying distribution. Developing DGMs has become one of the most hotly researched fields in artificial intelligence in recent years. The literature on DGMs has become vast and is growing rapidly. Some advances have even reached the public sphere, for example, the recent successes in generating realistic-looking images, voices, or movies; so-called deep fakes. Despite these successes, several mathematical and practical issues limit the broader use of DGMs: given a specific dataset, it remains challenging to design and train a DGM and even more challenging to find out why a particular model is or is not effective. To help advance the theoretical understanding of DGMs, we provide an introduction to DGMs and provide a concise mathematical framework for modeling the three most popular approaches: normalizing flows (NF), variational autoencoders (VAE), and generative adversarial networks (GAN). We illustrate the advantages and disadvantages of these basic approaches using numerical experiments. Our goal is to enable and motivate the reader to contribute to this proliferating research area. Our presentation also emphasizes relations between generative modeling and optimal transport.
Avoiding The Double Descent Phenomenon of Random Feature Models Using Hybrid Regularization
Dec 11, 2020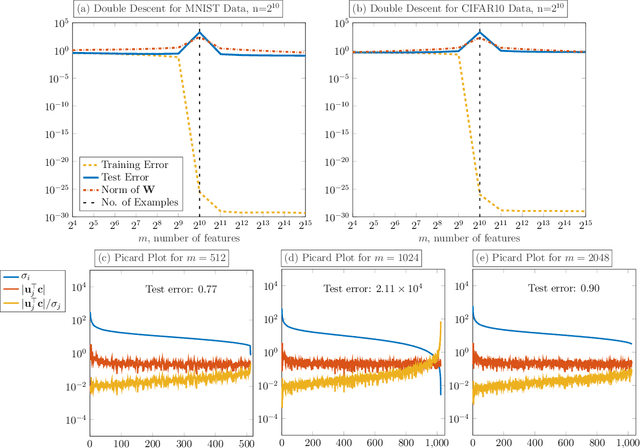
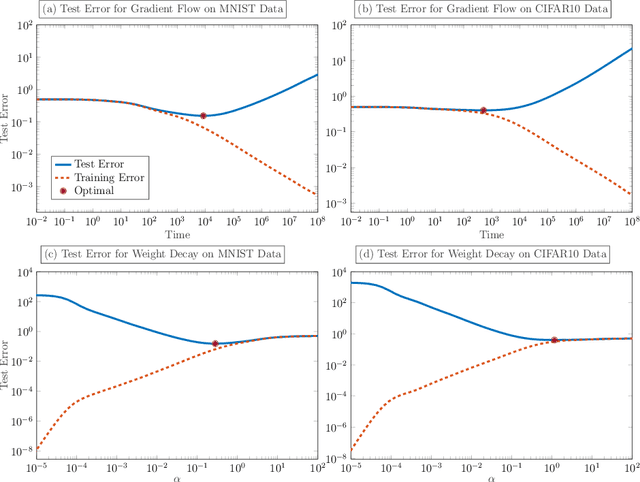
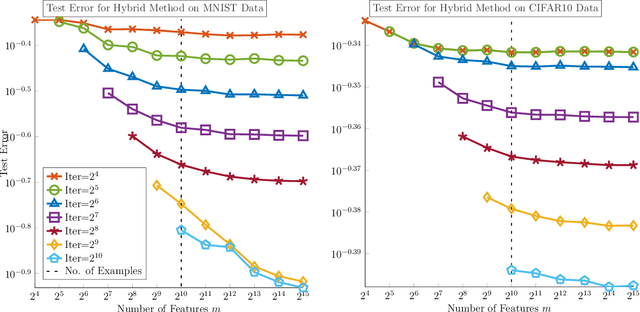
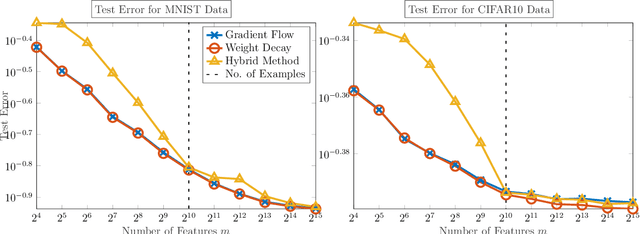
We demonstrate the ability of hybrid regularization methods to automatically avoid the double descent phenomenon arising in the training of random feature models (RFM). The hallmark feature of the double descent phenomenon is a spike in the regularization gap at the interpolation threshold, i.e. when the number of features in the RFM equals the number of training samples. To close this gap, the hybrid method considered in our paper combines the respective strengths of the two most common forms of regularization: early stopping and weight decay. The scheme does not require hyperparameter tuning as it automatically selects the stopping iteration and weight decay hyperparameter by using generalized cross-validation (GCV). This also avoids the necessity of a dedicated validation set. While the benefits of hybrid methods have been well-documented for ill-posed inverse problems, our work presents the first use case in machine learning. To expose the need for regularization and motivate hybrid methods, we perform detailed numerical experiments inspired by image classification. In those examples, the hybrid scheme successfully avoids the double descent phenomenon and yields RFMs whose generalization is comparable with classical regularization approaches whose hyperparameters are tuned optimally using the test data. We provide our MATLAB codes for implementing the numerical experiments in this paper at https://github.com/EmoryMLIP/HybridRFM.
Multigrid-in-Channels Neural Network Architectures
Nov 19, 2020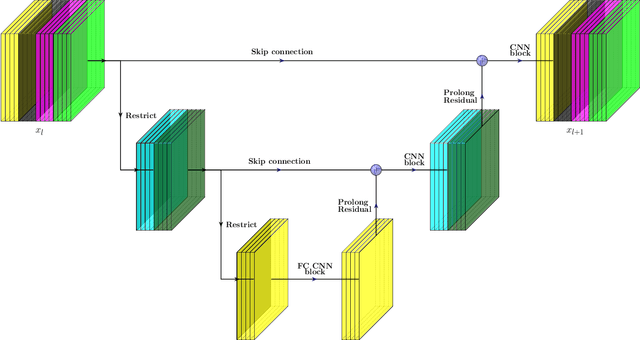
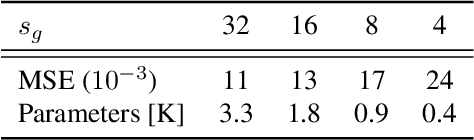
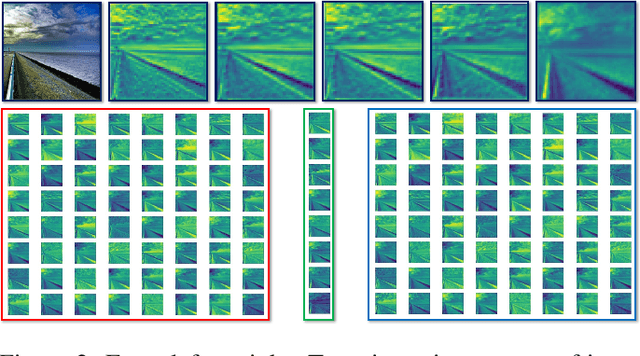
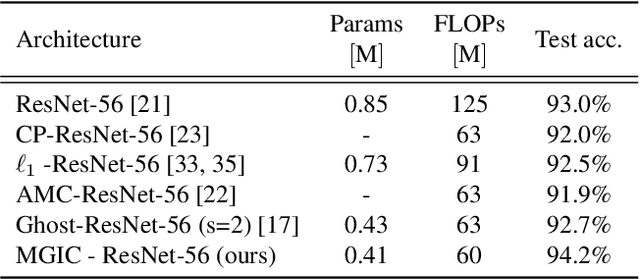
We present a multigrid-in-channels (MGIC) approach that tackles the quadratic growth of the number of parameters with respect to the number of channels in standard convolutional neural networks (CNNs). It has been shown that there is a redundancy in standard CNNs, as networks with light or sparse convolution operators yield similar performance to full networks. However, the number of parameters in the former networks also scales quadratically in width, while in the latter case, the parameters typically have random sparsity patterns, hampering hardware efficiency. Our approach for building CNN architectures scales linearly with respect to the network's width while retaining full coupling of the channels as in standard CNNs. To this end, we replace each convolution block with its MGIC block utilizing a hierarchy of lightweight convolutions. Our extensive experiments on image classification, segmentation, and point cloud classification show that applying this strategy to different architectures like ResNet and MobileNetV3 considerably reduces the number of parameters while obtaining similar or better accuracy. For example, we obtain 76.1% top-1 accuracy on ImageNet with a lightweight network with similar parameters and FLOPs to MobileNetV3.
Train Like a Pro: Efficient Training of Neural Networks with Variable Projection
Jul 26, 2020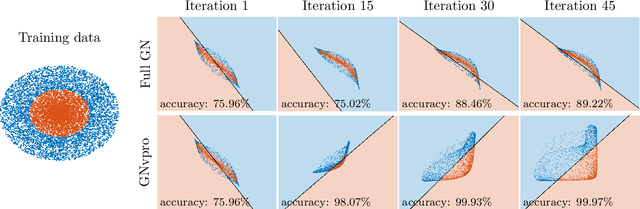
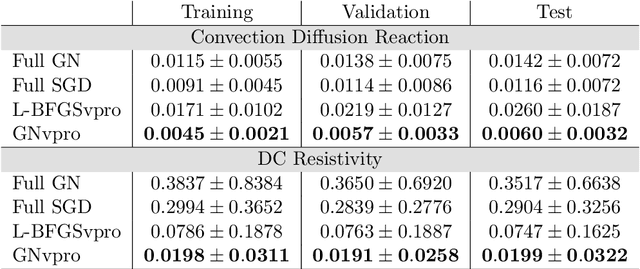
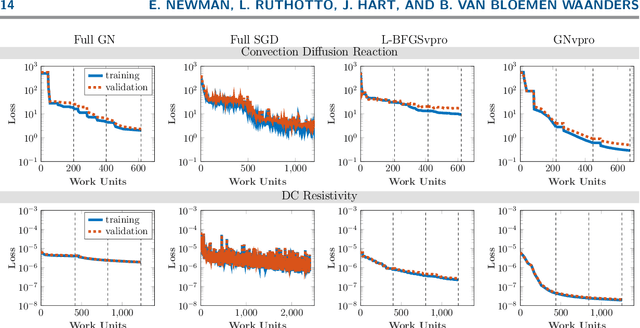
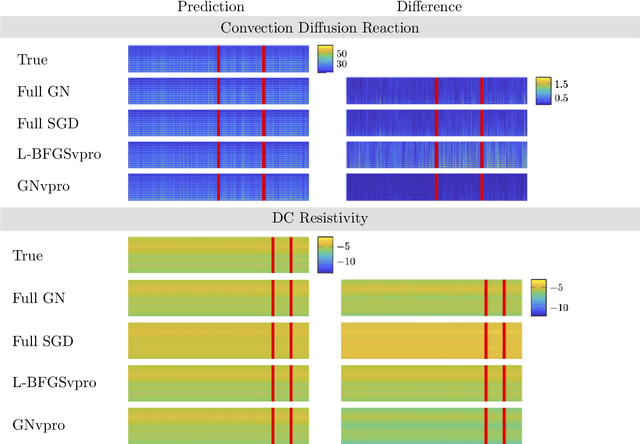
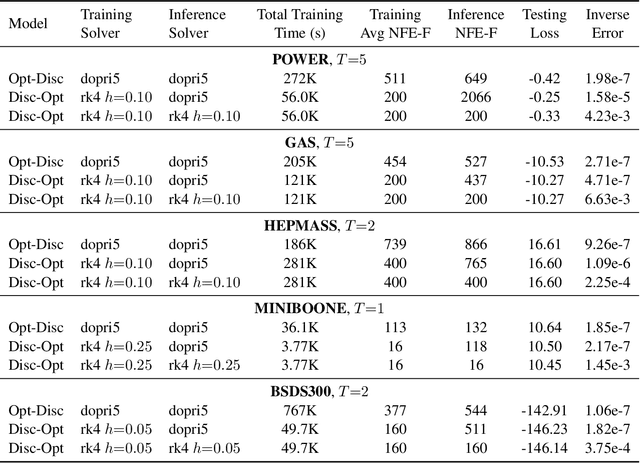
Deep neural networks (DNNs) have achieved state-of-the-art performance across a variety of traditional machine learning tasks, e.g., speech recognition, image classification, and segmentation. The ability of DNNs to efficiently approximate high-dimensional functions has also motivated their use in scientific applications, e.g., to solve partial differential equations (PDE) and to generate surrogate models. In this paper, we consider the supervised training of DNNs, which arises in many of the above applications. We focus on the central problem of optimizing the weights of the given DNN such that it accurately approximates the relation between observed input and target data. Devising effective solvers for this optimization problem is notoriously challenging due to the large number of weights, non-convexity, data-sparsity, and non-trivial choice of hyperparameters. To solve the optimization problem more efficiently, we propose the use of variable projection (VarPro), a method originally designed for separable nonlinear least-squares problems. Our main contribution is the Gauss-Newton VarPro method (GNvpro) that extends the reach of the VarPro idea to non-quadratic objective functions, most notably, cross-entropy loss functions arising in classification. These extensions make GNvpro applicable to all training problems that involve a DNN whose last layer is an affine mapping, which is common in many state-of-the-art architectures. In numerical experiments from classification and surrogate modeling, GNvpro not only solves the optimization problem more efficiently but also yields DNNs that generalize better than commonly-used optimization schemes.
OT-Flow: Fast and Accurate Continuous Normalizing Flows via Optimal Transport
Jun 22, 2020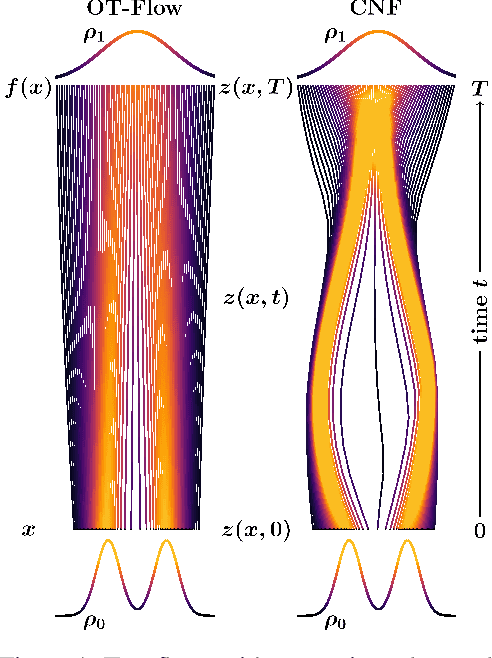

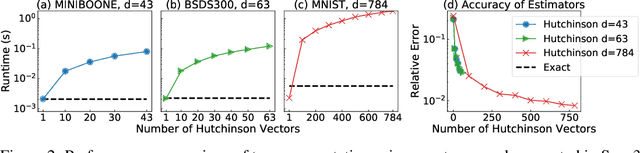
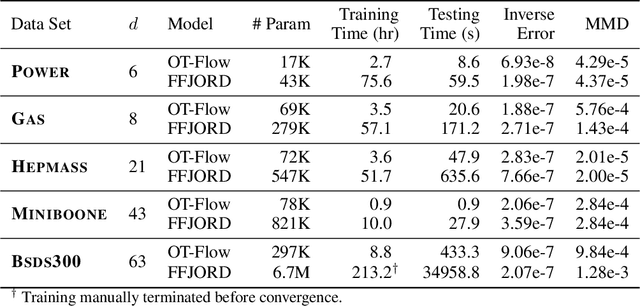
A normalizing flow is an invertible mapping between an arbitrary probability distribution and a standard normal distribution; it can be used for density estimation and statistical inference. Computing the flow follows the change of variables formula and thus requires invertibility of the mapping and an efficient way to compute the determinant of its Jacobian. To satisfy these requirements, normalizing flows typically consist of carefully chosen components. Continuous normalizing flows (CNFs) are mappings obtained by solving a neural ordinary differential equation (ODE). The neural ODE's dynamics can be chosen almost arbitrarily while ensuring invertibility. Moreover, the log-determinant of the flow's Jacobian can be obtained by integrating the trace of the dynamics' Jacobian along the flow. Our proposed OT-Flow approach tackles two critical computational challenges that limit a more widespread use of CNFs. First, OT-Flow leverages optimal transport (OT) theory to regularize the CNF and enforce straight trajectories that are easier to integrate. Second, OT-Flow features exact trace computation with time complexity equal to trace estimators used in existing CNFs. On five high-dimensional density estimation and generative modeling tasks, OT-Flow performs competitively to a state-of-the-art CNF while on average requiring one-fourth of the number of weights with 19x speedup in training time and 28x speedup in inference.
Multigrid-in-Channels Architectures for Wide Convolutional Neural Networks
Jun 11, 2020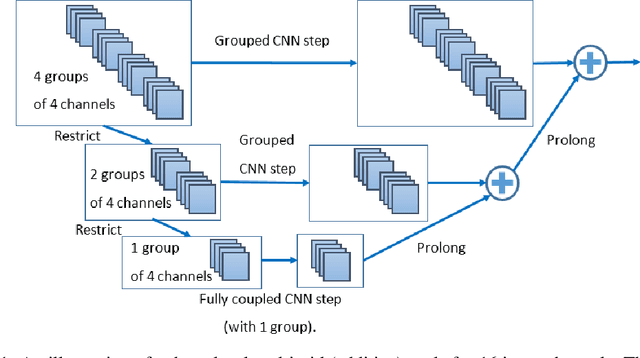
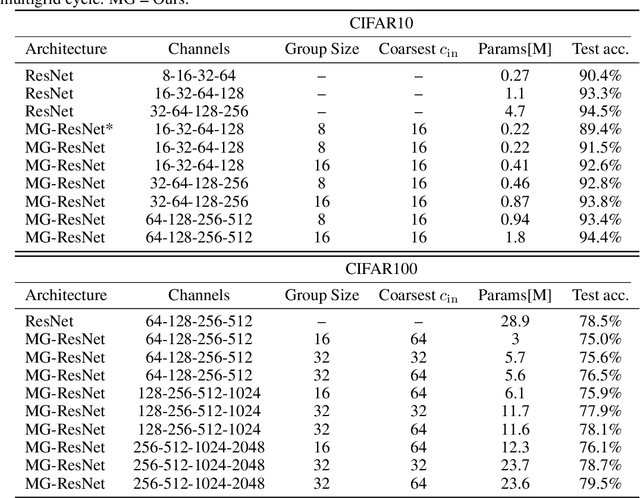
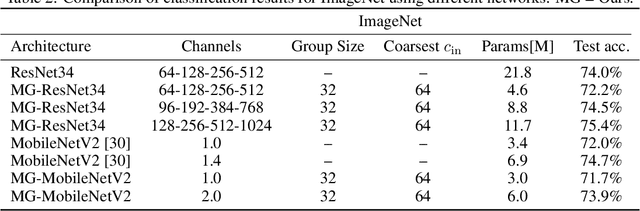
We present a multigrid approach that combats the quadratic growth of the number of parameters with respect to the number of channels in standard convolutional neural networks (CNNs). It has been shown that there is a redundancy in standard CNNs, as networks with much sparser convolution operators can yield similar performance to full networks. The sparsity patterns that lead to such behavior, however, are typically random, hampering hardware efficiency. In this work, we present a multigrid-in-channels approach for building CNN architectures that achieves full coupling of the channels, and whose number of parameters is linearly proportional to the width of the network. To this end, we replace each convolution layer in a generic CNN with a multilevel layer consisting of structured (i.e., grouped) convolutions. Our examples from supervised image classification show that applying this strategy to residual networks and MobileNetV2 considerably reduces the number of parameters without negatively affecting accuracy. Therefore, we can widen networks without dramatically increasing the number of parameters or operations.
Discretize-Optimize vs. Optimize-Discretize for Time-Series Regression and Continuous Normalizing Flows
May 27, 2020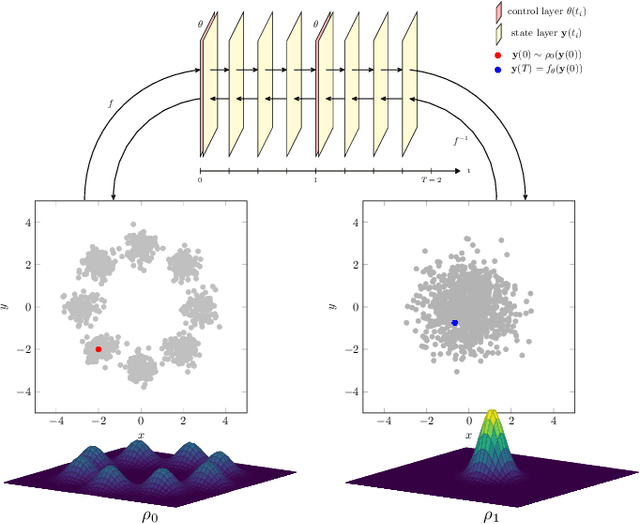
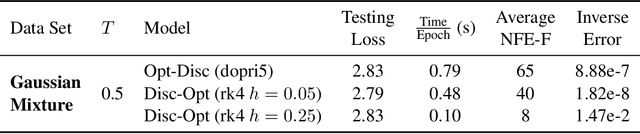
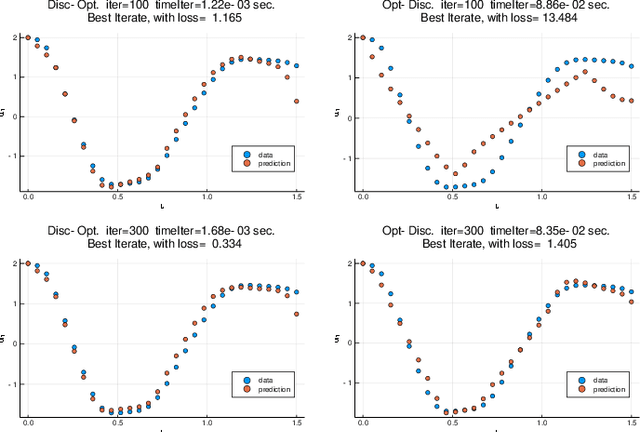
We compare the discretize-optimize (Disc-Opt) and optimize-discretize (Opt-Disc) approaches for time-series regression and continuous normalizing flows using neural ODEs. Neural ODEs, first described in Chen et al. (2018), are ordinary differential equations (ODEs) with neural network components; these models have competitively solved a variety of machine learning applications. Training a neural ODE can be phrased as an optimal control problem where the neural network weights are the controls and the hidden features are the states. Every iteration of gradient-based training involves solving an ODE forward in time and another backward in time, which can require large amounts of computation, time, and memory. Gholami et al. (2019) compared the Opt-Disc and Disc-Opt approaches for neural ODEs arising as continuous limits of residual neural networks used in image classification tasks. Their findings suggest that Disc-Opt achieves preferable performance due to the guaranteed accuracy of gradients. In this paper, we extend this comparison to neural ODEs applied to time-series regression and continuous normalizing flows (CNFs). Time-series regression and CNFs differ from classification in that the actual ODE model is needed in the prediction and inference phase, respectively. Meaningful models must also satisfy additional requirements, e.g., the invertibility of the CNF. As the continuous model satisfies these requirements by design, Opt-Disc approaches may appear advantageous. Through our numerical experiments, we demonstrate that with careful numerical treatment, Disc-Opt methods can achieve similar performance as Opt-Disc at inference with drastically reduced training costs. Disc-Opt reduced costs in six out of seven separate problems with training time reduction ranging from 39% to 97%, and in one case, Disc-Opt reduced training from nine days to less than one day.
A Machine Learning Framework for Solving High-Dimensional Mean Field Game and Mean Field Control Problems
Dec 18, 2019
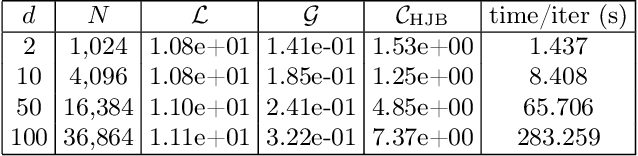

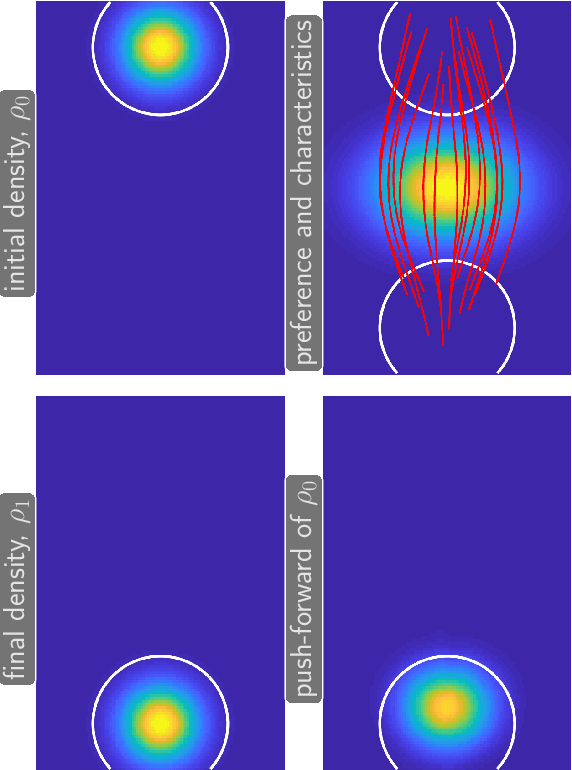
Mean field games (MFG) and mean field control (MFC) are critical classes of multi-agent models for efficient analysis of massive populations of interacting agents. Their areas of application span topics in economics, finance, game theory, industrial engineering, crowd motion, and more. In this paper, we provide a flexible machine learning framework for the numerical solution of potential MFG and MFC models. State-of-the-art numerical methods for solving such problems utilize spatial discretization that leads to a curse-of-dimensionality. We approximately solve high-dimensional problems by combining Lagrangian and Eulerian viewpoints and leveraging recent advances from machine learning. More precisely, we work with a Lagrangian formulation of the problem and enforce the underlying Hamilton-Jacobi-Bellman (HJB) equation that is derived from the Eulerian formulation. Finally, a tailored neural network parameterization of the MFG/MFC solution helps us avoid any spatial discretization. Our numerical results include the approximate solution of 100-dimensional instances of optimal transport and crowd motion problems on a standard work station. These results open the door to much-anticipated applications of MFG and MFC models that were beyond reach with existing numerical methods.
LeanConvNets: Low-cost Yet Effective Convolutional Neural Networks
Oct 29, 2019
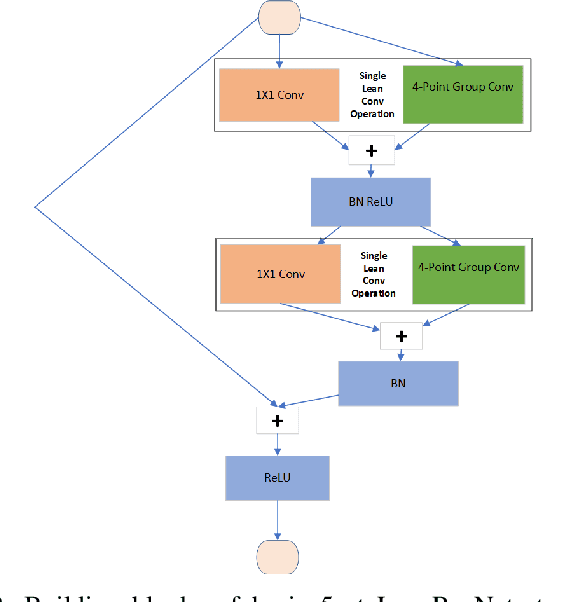
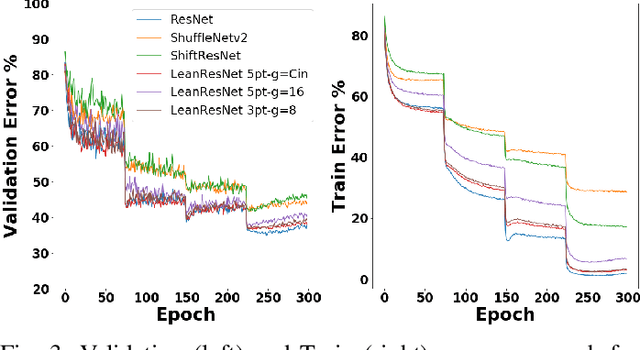
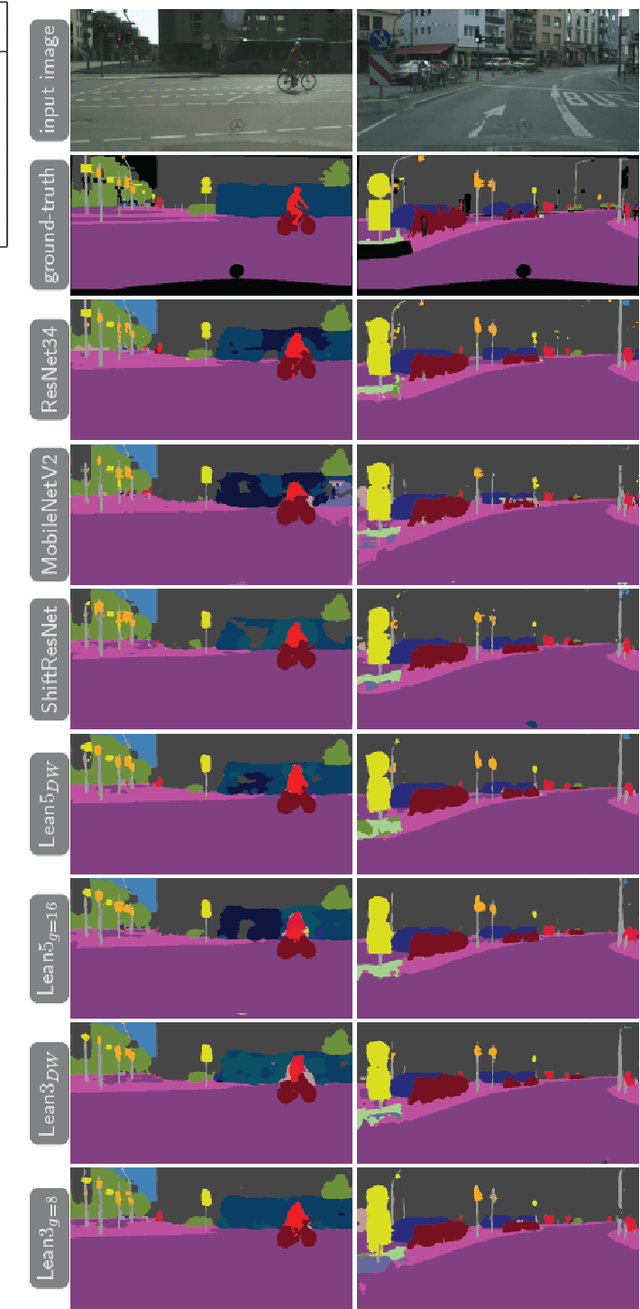
Convolutional Neural Networks (CNNs) have become indispensable for solving machine learning tasks in speech recognition, computer vision, and other areas that involve high-dimensional data. A CNN filters the input feature using a network containing spatial convolution operators with compactly supported stencils. In practice, the input data and the hidden features consist of a large number of channels, which in most CNNs are fully coupled by the convolution operators. This coupling leads to immense computational cost in the training and prediction phase. In this paper, we introduce LeanConvNets that are derived by sparsifying fully-coupled operators in existing CNNs. Our goal is to improve the efficiency of CNNs by reducing the number of weights, floating point operations and latency times, with minimal loss of accuracy. Our lean convolution operators involve tuning parameters that controls the trade-off between the network's accuracy and computational costs. These convolutions can be used in a wide range of existing networks, and we exemplify their use in residual networks (ResNets) and U-Nets. Using a range of benchmark problems from image classification and semantic segmentation, we demonstrate that the resulting LeanConvNet's accuracy is close to state-of-the-art networks while being computationally less expensive. In our tests, the lean versions of ResNet and U-net slightly outperforms comparable reduced architectures such as MobileNets and ShuffleNets.