 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOT-Flow: Fast and Accurate Continuous Normalizing Flows via Optimal Transport
Jun 22, 2020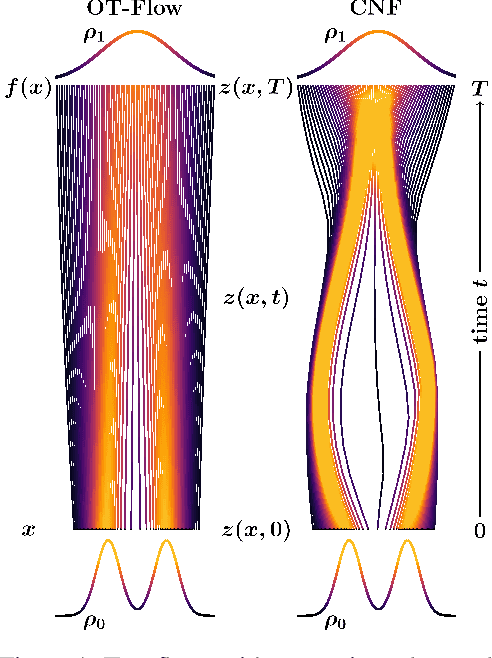

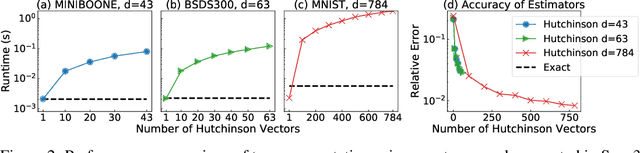
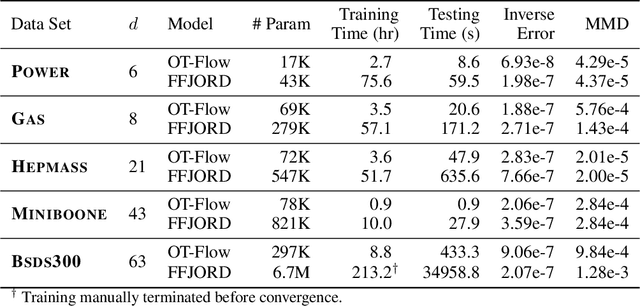
A normalizing flow is an invertible mapping between an arbitrary probability distribution and a standard normal distribution; it can be used for density estimation and statistical inference. Computing the flow follows the change of variables formula and thus requires invertibility of the mapping and an efficient way to compute the determinant of its Jacobian. To satisfy these requirements, normalizing flows typically consist of carefully chosen components. Continuous normalizing flows (CNFs) are mappings obtained by solving a neural ordinary differential equation (ODE). The neural ODE's dynamics can be chosen almost arbitrarily while ensuring invertibility. Moreover, the log-determinant of the flow's Jacobian can be obtained by integrating the trace of the dynamics' Jacobian along the flow. Our proposed OT-Flow approach tackles two critical computational challenges that limit a more widespread use of CNFs. First, OT-Flow leverages optimal transport (OT) theory to regularize the CNF and enforce straight trajectories that are easier to integrate. Second, OT-Flow features exact trace computation with time complexity equal to trace estimators used in existing CNFs. On five high-dimensional density estimation and generative modeling tasks, OT-Flow performs competitively to a state-of-the-art CNF while on average requiring one-fourth of the number of weights with 19x speedup in training time and 28x speedup in inference.
Discretize-Optimize vs. Optimize-Discretize for Time-Series Regression and Continuous Normalizing Flows
May 27, 2020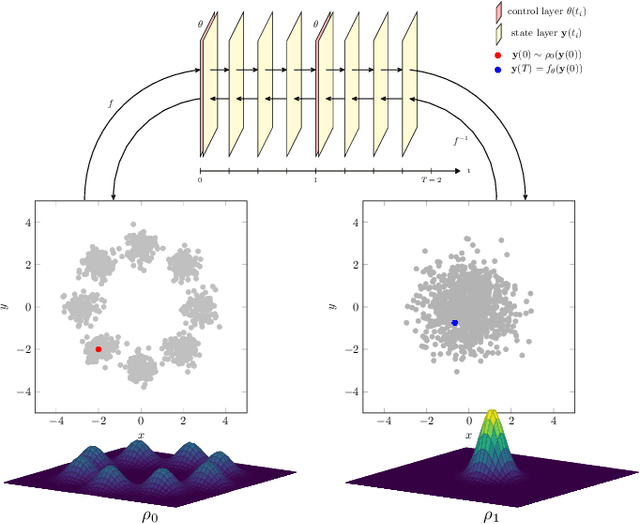
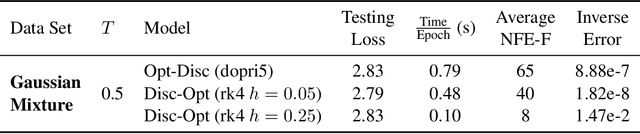
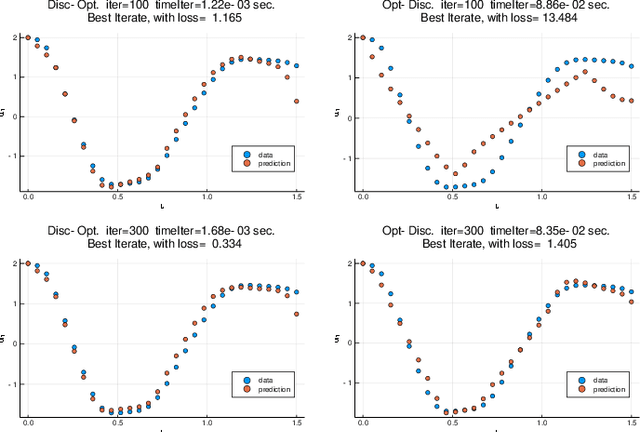
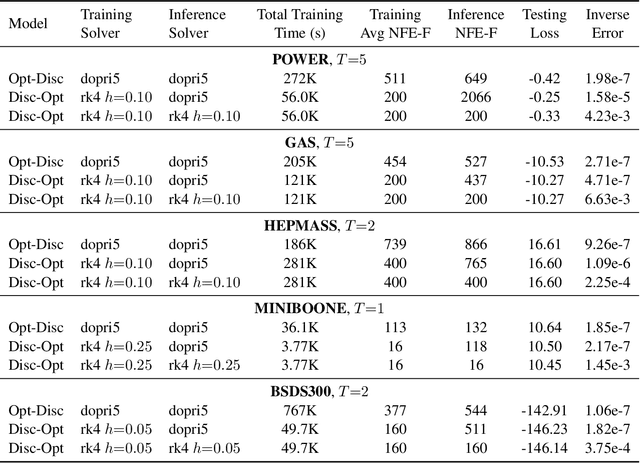
We compare the discretize-optimize (Disc-Opt) and optimize-discretize (Opt-Disc) approaches for time-series regression and continuous normalizing flows using neural ODEs. Neural ODEs, first described in Chen et al. (2018), are ordinary differential equations (ODEs) with neural network components; these models have competitively solved a variety of machine learning applications. Training a neural ODE can be phrased as an optimal control problem where the neural network weights are the controls and the hidden features are the states. Every iteration of gradient-based training involves solving an ODE forward in time and another backward in time, which can require large amounts of computation, time, and memory. Gholami et al. (2019) compared the Opt-Disc and Disc-Opt approaches for neural ODEs arising as continuous limits of residual neural networks used in image classification tasks. Their findings suggest that Disc-Opt achieves preferable performance due to the guaranteed accuracy of gradients. In this paper, we extend this comparison to neural ODEs applied to time-series regression and continuous normalizing flows (CNFs). Time-series regression and CNFs differ from classification in that the actual ODE model is needed in the prediction and inference phase, respectively. Meaningful models must also satisfy additional requirements, e.g., the invertibility of the CNF. As the continuous model satisfies these requirements by design, Opt-Disc approaches may appear advantageous. Through our numerical experiments, we demonstrate that with careful numerical treatment, Disc-Opt methods can achieve similar performance as Opt-Disc at inference with drastically reduced training costs. Disc-Opt reduced costs in six out of seven separate problems with training time reduction ranging from 39% to 97%, and in one case, Disc-Opt reduced training from nine days to less than one day.