 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACE-POLAR-1: A Polarisable Electrostatic Foundation Model for Molecular Chemistry
Feb 23, 2026Accurate modelling of electrostatic interactions and charge transfer is fundamental to computational chemistry, yet most machine learning interatomic potentials (MLIPs) rely on local atomic descriptors that cannot capture long-range electrostatic effects. We present a new electrostatic foundation model for molecular chemistry that extends the MACE architecture with explicit treatment of long-range interactions and electrostatic induction. Our approach combines local many-body geometric features with a non-self-consistent field formalism that updates learnable charge and spin densities through polarisable iterations to model induction, followed by global charge equilibration via learnable Fukui functions to control total charge and total spin. This design enables an accurate and physical description of systems with varying charge and spin states while maintaining computational efficiency. Trained on the OMol25 dataset of 100 million hybrid DFT calculations, our models achieve chemical accuracy across diverse benchmarks, with accuracy competitive with hybrid DFT on thermochemistry, reaction barriers, conformational energies, and transition metal complexes. Notably, we demonstrate that the inclusion of long-range electrostatics leads to a large improvement in the description of non-covalent interactions and supramolecular complexes over non-electrostatic models, including sub-kcal/mol prediction of molecular crystal formation energy in the X23-DMC dataset and a fourfold improvement over short-ranged models on protein-ligand interactions. The model's ability to handle variable charge and spin states, respond to external fields, provide interpretable spin-resolved charge densities, and maintain accuracy from small molecules to protein-ligand complexes positions it as a versatile tool for computational molecular chemistry and drug discovery.
Solving High-Dimensional Inverse Problems with Auxiliary Uncertainty via Operator Learning with Limited Data
Mar 20, 2023In complex large-scale systems such as climate, important effects are caused by a combination of confounding processes that are not fully observable. The identification of sources from observations of system state is vital for attribution and prediction, which inform critical policy decisions. The difficulty of these types of inverse problems lies in the inability to isolate sources and the cost of simulating computational models. Surrogate models may enable the many-query algorithms required for source identification, but data challenges arise from high dimensionality of the state and source, limited ensembles of costly model simulations to train a surrogate model, and few and potentially noisy state observations for inversion due to measurement limitations. The influence of auxiliary processes adds an additional layer of uncertainty that further confounds source identification. We introduce a framework based on (1) calibrating deep neural network surrogates to the flow maps provided by an ensemble of simulations obtained by varying sources, and (2) using these surrogates in a Bayesian framework to identify sources from observations via optimization. Focusing on an atmospheric dispersion exemplar, we find that the expressive and computationally efficient nature of the deep neural network operator surrogates in appropriately reduced dimension allows for source identification with uncertainty quantification using limited data. Introducing a variable wind field as an auxiliary process, we find that a Bayesian approximation error approach is essential for reliable source inversion when uncertainty due to wind stresses the algorithm.
Train Like a Pro: Efficient Training of Neural Networks with Variable Projection
Jul 26, 2020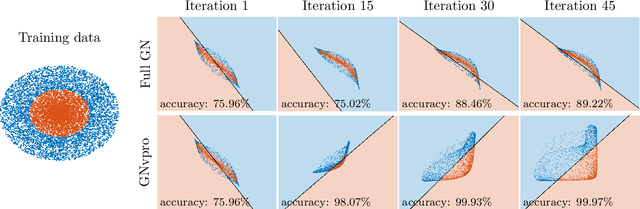
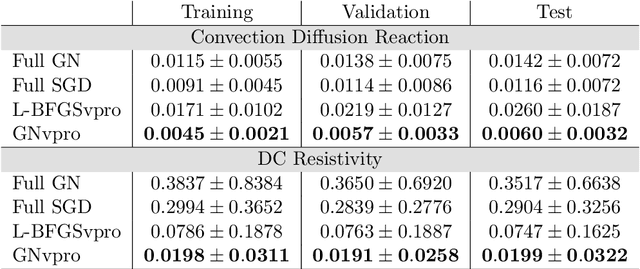
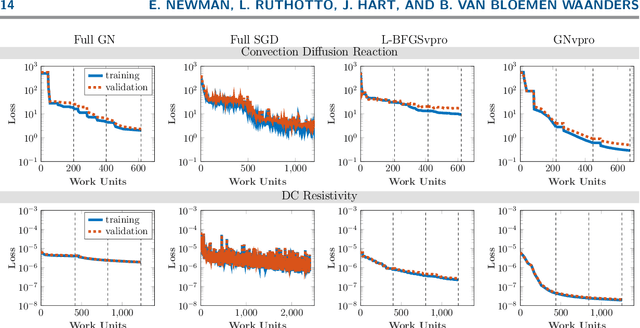
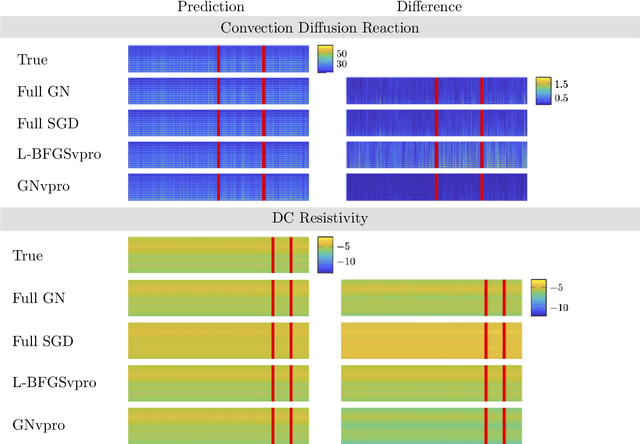
Deep neural networks (DNNs) have achieved state-of-the-art performance across a variety of traditional machine learning tasks, e.g., speech recognition, image classification, and segmentation. The ability of DNNs to efficiently approximate high-dimensional functions has also motivated their use in scientific applications, e.g., to solve partial differential equations (PDE) and to generate surrogate models. In this paper, we consider the supervised training of DNNs, which arises in many of the above applications. We focus on the central problem of optimizing the weights of the given DNN such that it accurately approximates the relation between observed input and target data. Devising effective solvers for this optimization problem is notoriously challenging due to the large number of weights, non-convexity, data-sparsity, and non-trivial choice of hyperparameters. To solve the optimization problem more efficiently, we propose the use of variable projection (VarPro), a method originally designed for separable nonlinear least-squares problems. Our main contribution is the Gauss-Newton VarPro method (GNvpro) that extends the reach of the VarPro idea to non-quadratic objective functions, most notably, cross-entropy loss functions arising in classification. These extensions make GNvpro applicable to all training problems that involve a DNN whose last layer is an affine mapping, which is common in many state-of-the-art architectures. In numerical experiments from classification and surrogate modeling, GNvpro not only solves the optimization problem more efficiently but also yields DNNs that generalize better than commonly-used optimization schemes.