 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fashion Compatibility with Bidirectional LSTMs
Jul 18, 2017
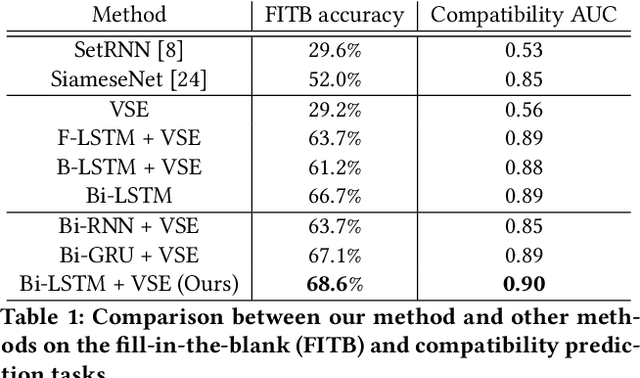
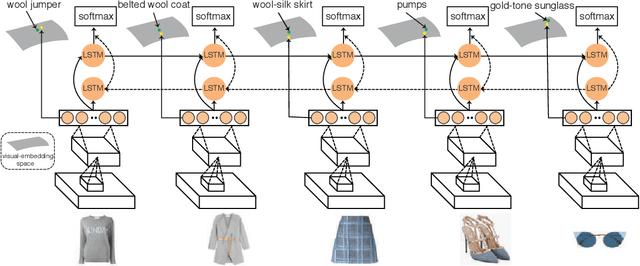

The ubiquity of online fashion shopping demands effective recommendation services for customers. In this paper, we study two types of fashion recommendation: (i) suggesting an item that matches existing components in a set to form a stylish outfit (a collection of fashion items), and (ii) generating an outfit with multimodal (images/text) specifications from a user. To this end, we propose to jointly learn a visual-semantic embedding and the compatibility relationships among fashion items in an end-to-end fashion. More specifically, we consider a fashion outfit to be a sequence (usually from top to bottom and then accessories) and each item in the outfit as a time step. Given the fashion items in an outfit, we train a bidirectional LSTM (Bi-LSTM) model to sequentially predict the next item conditioned on previous ones to learn their compatibility relationships. Further, we learn a visual-semantic space by regressing image features to their semantic representations aiming to inject attribute and category information as a regularization for training the LSTM. The trained network can not only perform the aforementioned recommendations effectively but also predict the compatibility of a given outfit. We conduct extensive experiments on our newly collected Polyvore dataset, and the results provide strong qualitative and quantitative evidence that our framework outperforms alternative methods.
Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection
May 28, 2017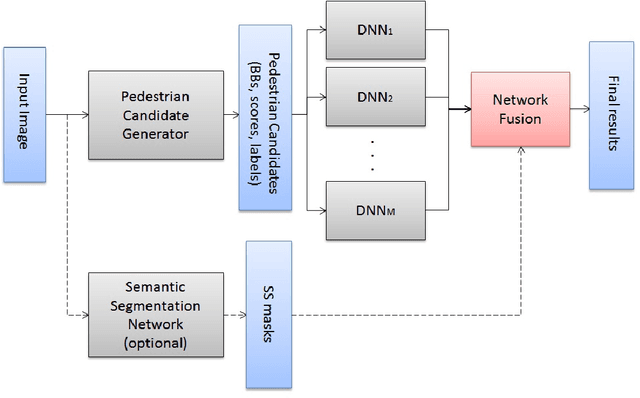
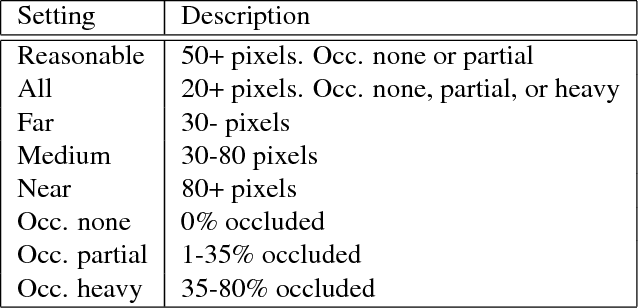
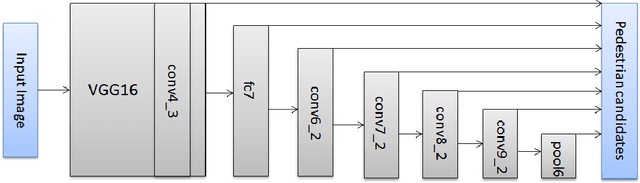
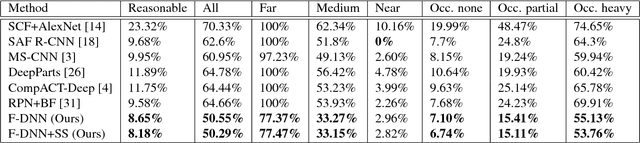
We propose a deep neural network fusion architecture for fast and robust pedestrian detection. The proposed network fusion architecture allows for parallel processing of multiple networks for speed. A single shot deep convolutional network is trained as a object detector to generate all possible pedestrian candidates of different sizes and occlusions. This network outputs a large variety of pedestrian candidates to cover the majority of ground-truth pedestrians while also introducing a large number of false positives. Next, multiple deep neural networks are used in parallel for further refinement of these pedestrian candidates. We introduce a soft-rejection based network fusion method to fuse the soft metrics from all networks together to generate the final confidence scores. Our method performs better than existing state-of-the-arts, especially when detecting small-size and occluded pedestrians. Furthermore, we propose a method for integrating pixel-wise semantic segmentation network into the network fusion architecture as a reinforcement to the pedestrian detector. The approach outperforms state-of-the-art methods on most protocols on Caltech Pedestrian dataset, with significant boosts on several protocols. It is also faster than all other methods.
Generating Holistic 3D Scene Abstractions for Text-based Image Retrieval
Apr 11, 2017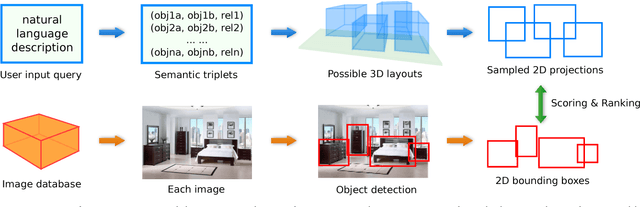

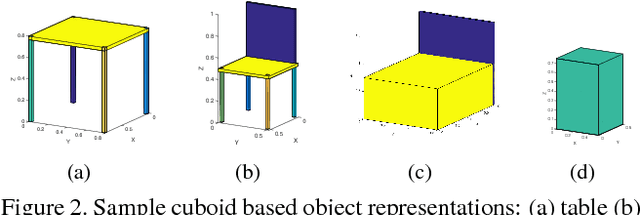
Spatial relationships between objects provide important information for text-based image retrieval. As users are more likely to describe a scene from a real world perspective, using 3D spatial relationships rather than 2D relationships that assume a particular viewing direction, one of the main challenges is to infer the 3D structure that bridges images with users' text descriptions. However, direct inference of 3D structure from images requires learning from large scale annotated data. Since interactions between objects can be reduced to a limited set of atomic spatial relations in 3D, we study the possibility of inferring 3D structure from a text description rather than an image, applying physical relation models to synthesize holistic 3D abstract object layouts satisfying the spatial constraints present in a textual description. We present a generic framework for retrieving images from a textual description of a scene by matching images with these generated abstract object layouts. Images are ranked by matching object detection outputs (bounding boxes) to 2D layout candidates (also represented by bounding boxes) which are obtained by projecting the 3D scenes with sampled camera directions. We validate our approach using public indoor scene datasets and show that our method outperforms baselines built upon object occurrence histograms and learned 2D pairwise relations.
Fast-AT: Fast Automatic Thumbnail Generation using Deep Neural Networks
Apr 10, 2017
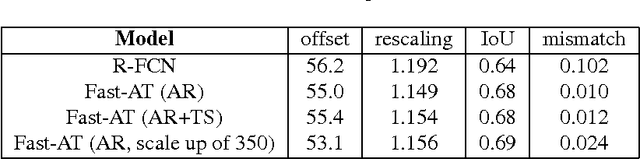

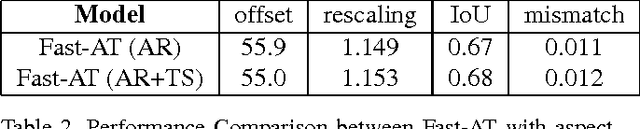
Fast-AT is an automatic thumbnail generation system based on deep neural networks. It is a fully-convolutional deep neural network, which learns specific filters for thumbnails of different sizes and aspect ratios. During inference, the appropriate filter is selected depending on the dimensions of the target thumbnail. Unlike most previous work, Fast-AT does not utilize saliency but addresses the problem directly. In addition, it eliminates the need to conduct region search on the saliency map. The model generalizes to thumbnails of different sizes including those with extreme aspect ratios and can generate thumbnails in real time. A data set of more than 70,000 thumbnail annotations was collected to train Fast-AT. We show competitive results in comparison to existing techniques.
Weakly-Supervised Spatial Context Networks
Apr 10, 2017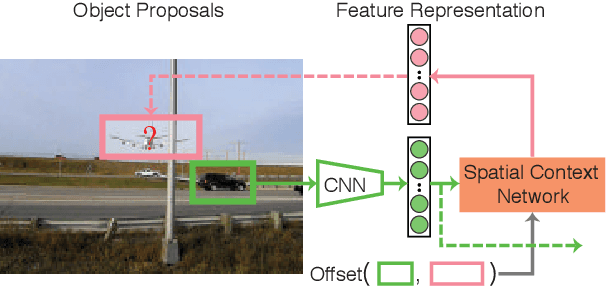
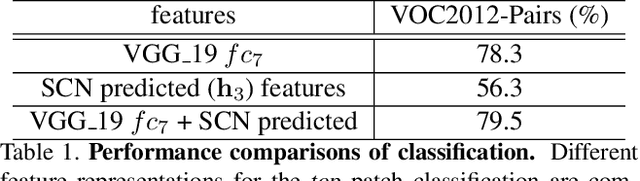
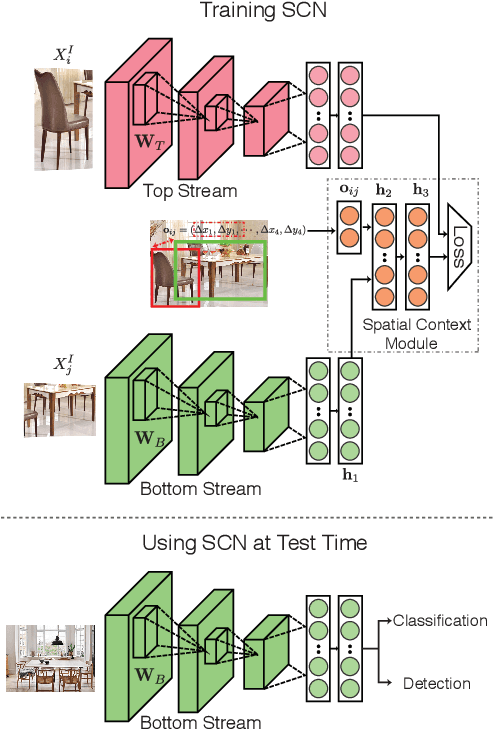
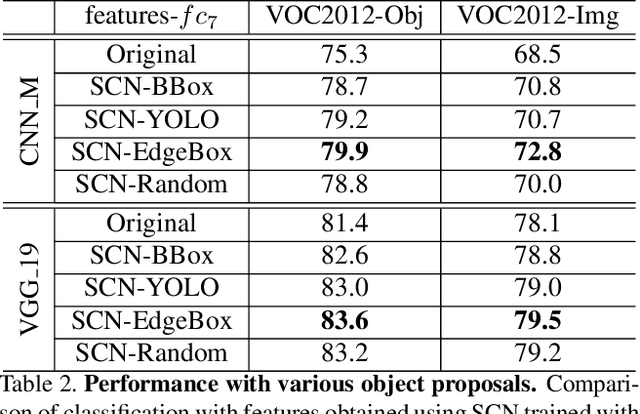
We explore the power of spatial context as a self-supervisory signal for learning visual representations. In particular, we propose spatial context networks that learn to predict a representation of one image patch from another image patch, within the same image, conditioned on their real-valued relative spatial offset. Unlike auto-encoders, that aim to encode and reconstruct original image patches, our network aims to encode and reconstruct intermediate representations of the spatially offset patches. As such, the network learns a spatially conditioned contextual representation. By testing performance with various patch selection mechanisms we show that focusing on object-centric patches is important, and that using object proposal as a patch selection mechanism leads to the highest improvement in performance. Further, unlike auto-encoders, context encoders [21], or other forms of unsupervised feature learning, we illustrate that contextual supervision (with pre-trained model initialization) can improve on existing pre-trained model performance. We build our spatial context networks on top of standard VGG_19 and CNN_M architectures and, among other things, show that we can achieve improvements (with no additional explicit supervision) over the original ImageNet pre-trained VGG_19 and CNN_M models in object categorization and detection on VOC2007.
VRFP: On-the-fly Video Retrieval using Web Images and Fast Fisher Vector Products
Apr 10, 2017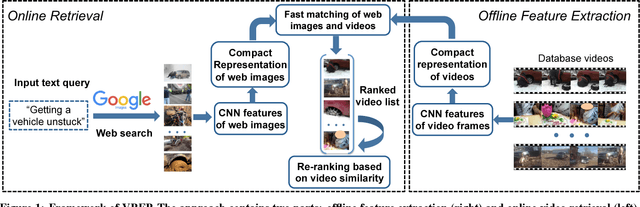
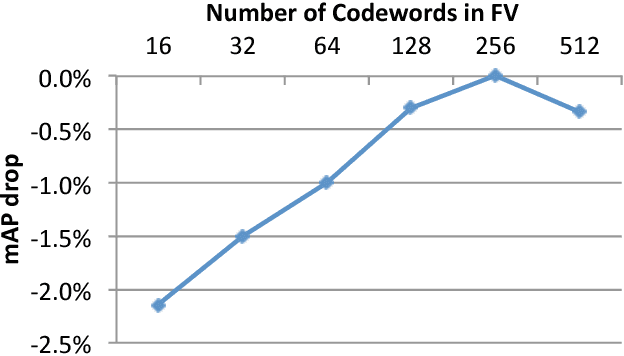
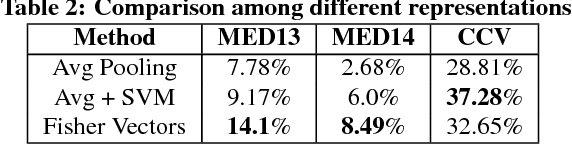
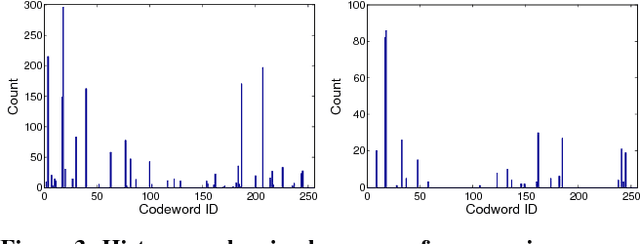
VRFP is a real-time video retrieval framework based on short text input queries, which obtains weakly labeled training images from the web after the query is known. The retrieved web images representing the query and each database video are treated as unordered collections of images, and each collection is represented using a single Fisher Vector built on CNN features. Our experiments show that a Fisher Vector is robust to noise present in web images and compares favorably in terms of accuracy to other standard representations. While a Fisher Vector can be constructed efficiently for a new query, matching against the test set is slow due to its high dimensionality. To perform matching in real-time, we present a lossless algorithm that accelerates the inner product computation between high dimensional Fisher Vectors. We prove that the expected number of multiplications required decreases quadratically with the sparsity of Fisher Vectors. We are not only able to construct and apply query models in real-time, but with the help of a simple re-ranking scheme, we also outperform state-of-the-art automatic retrieval methods by a significant margin on TRECVID MED13 (3.5%), MED14 (1.3%) and CCV datasets (5.2%). We also provide a direct comparison on standard datasets between two different paradigms for automatic video retrieval - zero-shot learning and on-the-fly retrieval.
Generalized Deep Image to Image Regression
Dec 10, 2016
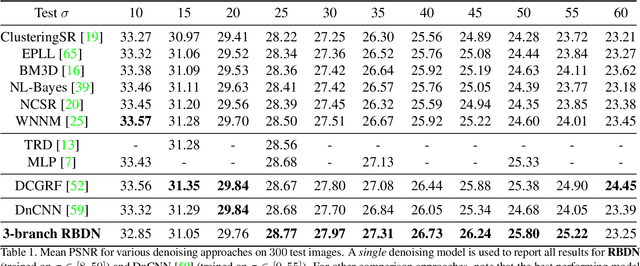
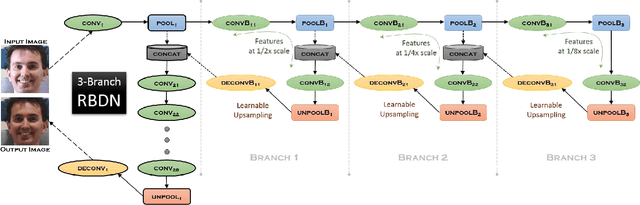

We present a Deep Convolutional Neural Network architecture which serves as a generic image-to-image regressor that can be trained end-to-end without any further machinery. Our proposed architecture: the Recursively Branched Deconvolutional Network (RBDN) develops a cheap multi-context image representation very early on using an efficient recursive branching scheme with extensive parameter sharing and learnable upsampling. This multi-context representation is subjected to a highly non-linear locality preserving transformation by the remainder of our network comprising of a series of convolutions/deconvolutions without any spatial downsampling. The RBDN architecture is fully convolutional and can handle variable sized images during inference. We provide qualitative/quantitative results on $3$ diverse tasks: relighting, denoising and colorization and show that our proposed RBDN architecture obtains comparable results to the state-of-the-art on each of these tasks when used off-the-shelf without any post processing or task-specific architectural modifications.
ModelHub: Towards Unified Data and Lifecycle Management for Deep Learning
Nov 18, 2016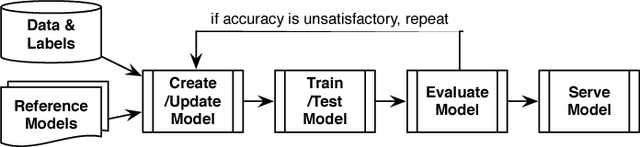
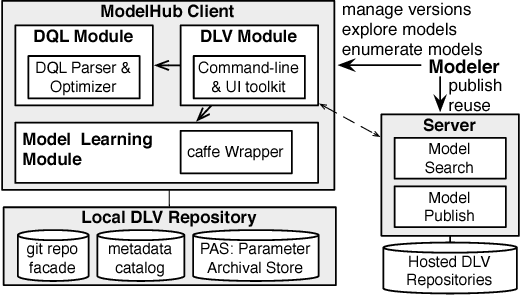
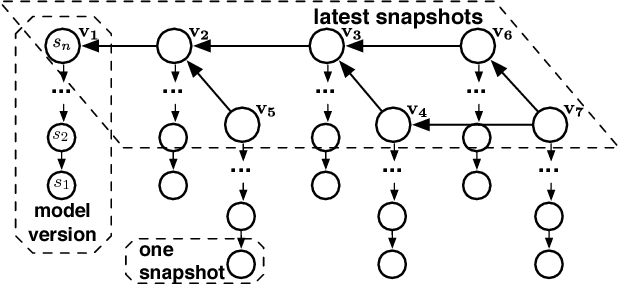
Deep learning has improved state-of-the-art results in many important fields, and has been the subject of much research in recent years, leading to the development of several systems for facilitating deep learning. Current systems, however, mainly focus on model building and training phases, while the issues of data management, model sharing, and lifecycle management are largely ignored. Deep learning modeling lifecycle generates a rich set of data artifacts, such as learned parameters and training logs, and comprises of several frequently conducted tasks, e.g., to understand the model behaviors and to try out new models. Dealing with such artifacts and tasks is cumbersome and largely left to the users. This paper describes our vision and implementation of a data and lifecycle management system for deep learning. First, we generalize model exploration and model enumeration queries from commonly conducted tasks by deep learning modelers, and propose a high-level domain specific language (DSL), inspired by SQL, to raise the abstraction level and accelerate the modeling process. To manage the data artifacts, especially the large amount of checkpointed float parameters, we design a novel model versioning system (dlv), and a read-optimized parameter archival storage system (PAS) that minimizes storage footprint and accelerates query workloads without losing accuracy. PAS archives versioned models using deltas in a multi-resolution fashion by separately storing the less significant bits, and features a novel progressive query (inference) evaluation algorithm. Third, we show that archiving versioned models using deltas poses a new dataset versioning problem and we develop efficient algorithms for solving it. We conduct extensive experiments over several real datasets from computer vision domain to show the efficiency of the proposed techniques.
The Role of Context Selection in Object Detection
Sep 09, 2016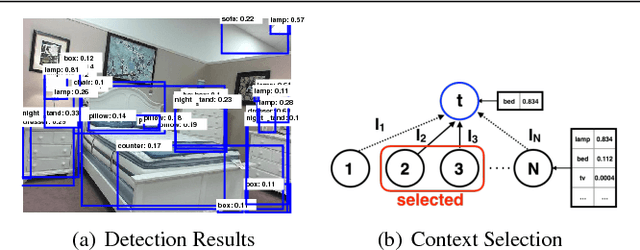
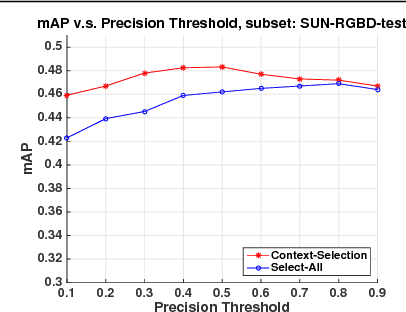


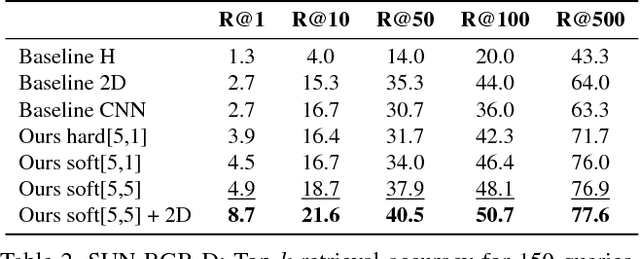
We investigate the reasons why context in object detection has limited utility by isolating and evaluating the predictive power of different context cues under ideal conditions in which context provided by an oracle. Based on this study, we propose a region-based context re-scoring method with dynamic context selection to remove noise and emphasize informative context. We introduce latent indicator variables to select (or ignore) potential contextual regions, and learn the selection strategy with latent-SVM. We conduct experiments to evaluate the performance of the proposed context selection method on the SUN RGB-D dataset. The method achieves a significant improvement in terms of mean average precision (mAP), compared with both appearance based detectors and a conventional context model without the selection scheme.
Modeling Context Between Objects for Referring Expression Understanding
Aug 01, 2016
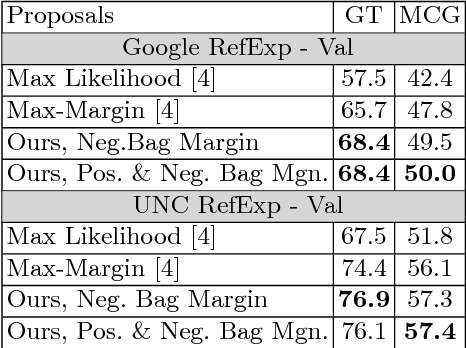
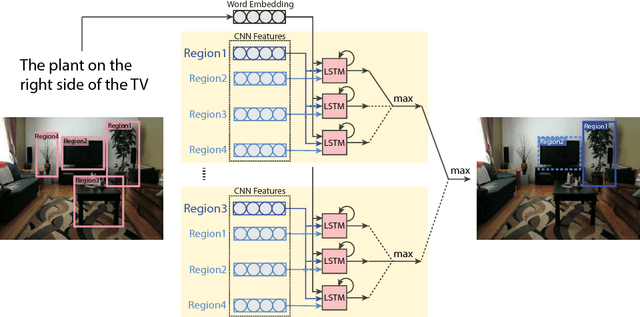
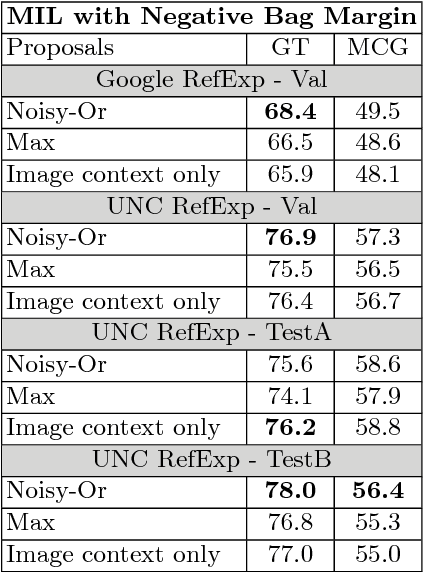
Referring expressions usually describe an object using properties of the object and relationships of the object with other objects. We propose a technique that integrates context between objects to understand referring expressions. Our approach uses an LSTM to learn the probability of a referring expression, with input features from a region and a context region. The context regions are discovered using multiple-instance learning (MIL) since annotations for context objects are generally not available for training. We utilize max-margin based MIL objective functions for training the LSTM. Experiments on the Google RefExp and UNC RefExp datasets show that modeling context between objects provides better performance than modeling only object properties. We also qualitatively show that our technique can ground a referring expression to its referred region along with the supporting context region.