 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAblateCell: A Reproduce-then-Ablate Agent for Virtual Cell Repositories
Apr 21, 2026Systematic ablations are essential to attribute performance gains in AI Virtual Cells, yet they are rarely performed because biological repositories are under-standardized and tightly coupled to domain-specific data and formats. While recent coding agents can translate ideas into implementations, they typically stop at producing code and lack a verifier that can reproduce strong baselines and rigorously test which components truly matter. We introduce AblateCell, a reproduce-then-ablate agent for virtual cell repositories that closes this verification gap. AblateCell first reproduces reported baselines end-to-end by auto-configuring environments, resolving dependency and data issues, and rerunning official evaluations while emitting verifiable artifacts. It then conducts closed-loop ablation by generating a graph of isolated repository mutations and adaptively selecting experiments under a reward that trades off performance impact and execution cost. Evaluated on three single-cell perturbation prediction repositories (CPA, GEARS, BioLORD), AblateCell achieves 88.9% (+29.9% to human expert) end-to-end workflow success and 93.3% (+53.3% to heuristic) accuracy in recovering ground-truth critical components. These results enable scalable, repository-grounded verification and attribution directly on biological codebases.
SCALE:Scalable Conditional Atlas-Level Endpoint transport for virtual cell perturbation prediction
Mar 19, 2026Virtual cell models aim to enable in silico experimentation by predicting how cells respond to genetic, chemical, or cytokine perturbations from single-cell measurements. In practice, however, large-scale perturbation prediction remains constrained by three coupled bottlenecks: inefficient training and inference pipelines, unstable modeling in high-dimensional sparse expression space, and evaluation protocols that overemphasize reconstruction-like accuracy while underestimating biological fidelity. In this work we present a specialized large-scale foundation model SCALE for virtual cell perturbation prediction that addresses the above limitations jointly. First, we build a BioNeMo-based training and inference framework that substantially improves data throughput, distributed scalability, and deployment efficiency, yielding 12.51* speedup on pretrain and 1.29* on inference over the prior SOTA pipeline under matched system settings. Second, we formulate perturbation prediction as conditional transport and implement it with a set-aware flow architecture that couples LLaMA-based cellular encoding with endpoint-oriented supervision. This design yields more stable training and stronger recovery of perturbation effects. Third, we evaluate the model on Tahoe-100M using a rigorous cell-level protocol centered on biologically meaningful metrics rather than reconstruction alone. On this benchmark, our model improves PDCorr by 12.02% and DE Overlap by 10.66% over STATE. Together, these results suggest that advancing virtual cells requires not only better generative objectives, but also the co-design of scalable infrastructure, stable transport modeling, and biologically faithful evaluation.
HarmonyCell: Automating Single-Cell Perturbation Modeling under Semantic and Distribution Shifts
Mar 02, 2026Single-cell perturbation studies face dual heterogeneity bottlenecks: (i) semantic heterogeneity--identical biological concepts encoded under incompatible metadata schemas across datasets; and (ii) statistical heterogeneity--distribution shifts from biological variation demanding dataset-specific inductive biases. We propose HarmonyCell, an end-to-end agent framework resolving each challenge through a dedicated mechanism: an LLM-driven Semantic Unifier autonomously maps disparate metadata into a canonical interface without manual intervention; and an adaptive Monte Carlo Tree Search engine operates over a hierarchical action space to synthesize architectures with optimal statistical inductive biases for distribution shifts. Evaluated across diverse perturbation tasks under both semantic and distribution shifts, HarmonyCell achieves a 95% valid execution rate on heterogeneous input datasets (versus 0% for general agents) while matching or even exceeding expert-designed baselines in rigorous out-of-distribution evaluations. This dual-track orchestration enables scalable automatic virtual cell modeling without dataset-specific engineering.
Protein-SE(3): Benchmarking SE(3)-based Generative Models for Protein Structure Design
Jul 27, 2025SE(3)-based generative models have shown great promise in protein geometry modeling and effective structure design. However, the field currently lacks a modularized benchmark to enable comprehensive investigation and fair comparison of different methods. In this paper, we propose Protein-SE(3), a new benchmark based on a unified training framework, which comprises protein scaffolding tasks, integrated generative models, high-level mathematical abstraction, and diverse evaluation metrics. Recent advanced generative models designed for protein scaffolding, from multiple perspectives like DDPM (Genie1 and Genie2), Score Matching (FrameDiff and RfDiffusion) and Flow Matching (FoldFlow and FrameFlow) are integrated into our framework. All integrated methods are fairly investigated with the same training dataset and evaluation metrics. Furthermore, we provide a high-level abstraction of the mathematical foundations behind the generative models, enabling fast prototyping of future algorithms without reliance on explicit protein structures. Accordingly, we release the first comprehensive benchmark built upon unified training framework for SE(3)-based protein structure design, which is publicly accessible at https://github.com/BruthYU/protein-se3.
MELO: Enhancing Model Editing with Neuron-Indexed Dynamic LoRA
Dec 19, 2023Large language models (LLMs) have shown great success in various Natural Language Processing (NLP) tasks, whist they still need updates after deployment to fix errors or keep pace with the changing knowledge in the world. Researchers formulate such problem as Model Editing and have developed various editors focusing on different axes of editing properties. However, current editors can hardly support all properties and rely on heavy computational resources. In this paper, we propose a plug-in Model Editing method based on neuron-indexed dynamic LoRA (MELO), which alters the behavior of language models by dynamically activating certain LoRA blocks according to the index built in an inner vector database. Our method satisfies various editing properties with high efficiency and can be easily integrated into multiple LLM backbones. Experimental results show that our proposed MELO achieves state-of-the-art editing performance on three sequential editing tasks (document classification, question answering and hallucination correction), while requires the least trainable parameters and computational cost.
Counterfactual reasoning: Testing language models' understanding of hypothetical scenarios
May 26, 2023Current pre-trained language models have enabled remarkable improvements in downstream tasks, but it remains difficult to distinguish effects of statistical correlation from more systematic logical reasoning grounded on the understanding of real world. We tease these factors apart by leveraging counterfactual conditionals, which force language models to predict unusual consequences based on hypothetical propositions. We introduce a set of tests from psycholinguistic experiments, as well as larger-scale controlled datasets, to probe counterfactual predictions from five pre-trained language models. We find that models are consistently able to override real-world knowledge in counterfactual scenarios, and that this effect is more robust in case of stronger baseline world knowledge -- however, we also find that for most models this effect appears largely to be driven by simple lexical cues. When we mitigate effects of both world knowledge and lexical cues to test knowledge of linguistic nuances of counterfactuals, we find that only GPT-3 shows sensitivity to these nuances, though this sensitivity is also non-trivially impacted by lexical associative factors.
Counterfactual reasoning: Do language models need world knowledge for causal understanding?
Dec 06, 2022Current pre-trained language models have enabled remarkable improvements in downstream tasks, but it remains difficult to distinguish effects of statistical correlation from more systematic logical reasoning grounded on understanding of the real world. In this paper we tease these factors apart by leveraging counterfactual conditionals, which force language models to predict unusual consequences based on hypothetical propositions. We introduce a set of tests drawn from psycholinguistic experiments, as well as larger-scale controlled datasets, to probe counterfactual predictions from a variety of popular pre-trained language models. We find that models are consistently able to override real-world knowledge in counterfactual scenarios, and that this effect is more robust in case of stronger baseline world knowledge -- however, we also find that for most models this effect appears largely to be driven by simple lexical cues. When we mitigate effects of both world knowledge and lexical cues to test knowledge of linguistic nuances of counterfactuals, we find that only GPT-3 shows sensitivity to these nuances, though this sensitivity is also non-trivially impacted by lexical associative factors.
"No, they did not": Dialogue response dynamics in pre-trained language models
Oct 05, 2022

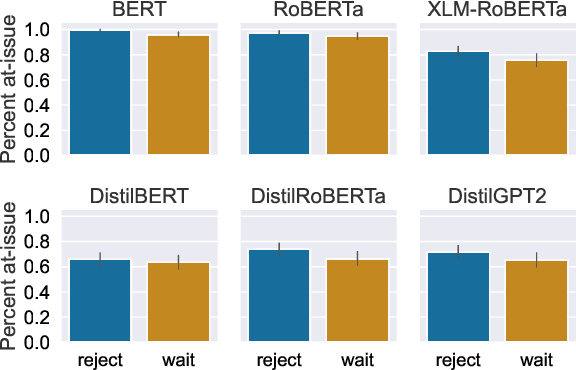
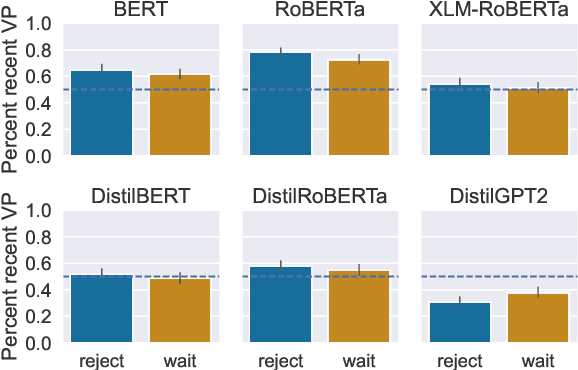
A critical component of competence in language is being able to identify relevant components of an utterance and reply appropriately. In this paper we examine the extent of such dialogue response sensitivity in pre-trained language models, conducting a series of experiments with a particular focus on sensitivity to dynamics involving phenomena of at-issueness and ellipsis. We find that models show clear sensitivity to a distinctive role of embedded clauses, and a general preference for responses that target main clause content of prior utterances. However, the results indicate mixed and generally weak trends with respect to capturing the full range of dynamics involved in targeting at-issue versus not-at-issue content. Additionally, models show fundamental limitations in grasp of the dynamics governing ellipsis, and response selections show clear interference from superficial factors that outweigh the influence of principled discourse constraints.
On the Interplay Between Fine-tuning and Composition in Transformers
Jun 01, 2021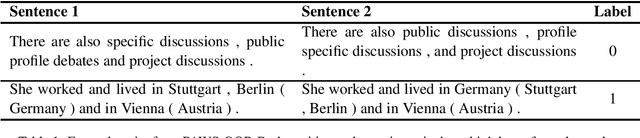
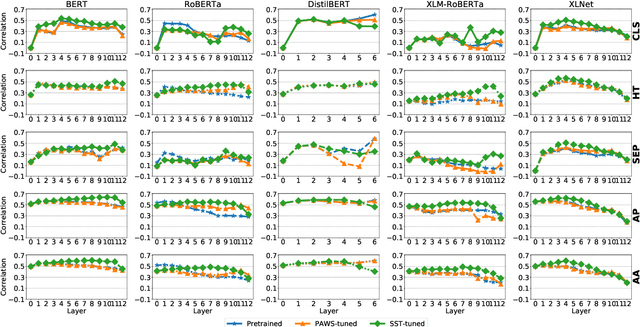
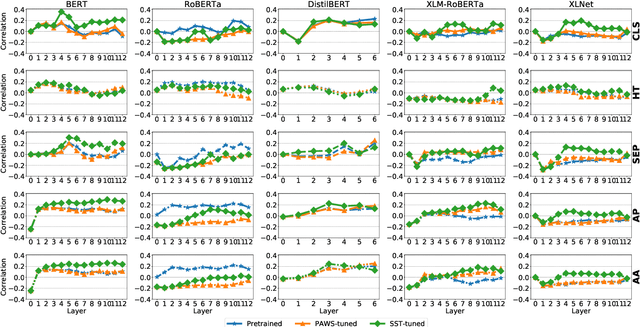
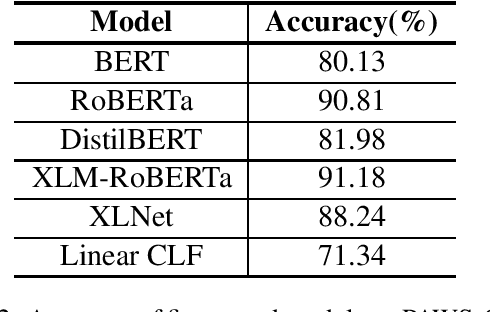
Pre-trained transformer language models have shown remarkable performance on a variety of NLP tasks. However, recent research has suggested that phrase-level representations in these models reflect heavy influences of lexical content, but lack evidence of sophisticated, compositional phrase information. Here we investigate the impact of fine-tuning on the capacity of contextualized embeddings to capture phrase meaning information beyond lexical content. Specifically, we fine-tune models on an adversarial paraphrase classification task with high lexical overlap, and on a sentiment classification task. After fine-tuning, we analyze phrasal representations in controlled settings following prior work. We find that fine-tuning largely fails to benefit compositionality in these representations, though training on sentiment yields a small, localized benefit for certain models. In follow-up analyses, we identify confounding cues in the paraphrase dataset that may explain the lack of composition benefits from that task, and we discuss potential factors underlying the localized benefits from sentiment training.
Assessing Phrasal Representation and Composition in Transformers
Oct 14, 2020
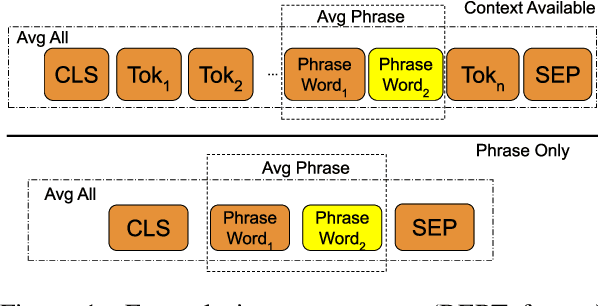

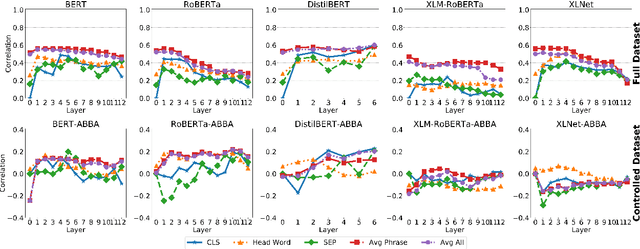
Deep transformer models have pushed performance on NLP tasks to new limits, suggesting sophisticated treatment of complex linguistic inputs, such as phrases. However, we have limited understanding of how these models handle representation of phrases, and whether this reflects sophisticated composition of phrase meaning like that done by humans. In this paper, we present systematic analysis of phrasal representations in state-of-the-art pre-trained transformers. We use tests leveraging human judgments of phrase similarity and meaning shift, and compare results before and after control of word overlap, to tease apart lexical effects versus composition effects. We find that phrase representation in these models relies heavily on word content, with little evidence of nuanced composition. We also identify variations in phrase representation quality across models, layers, and representation types, and make corresponding recommendations for usage of representations from these models.