 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Monte Carlo Methods for Parameter Estimation
Jul 25, 2021
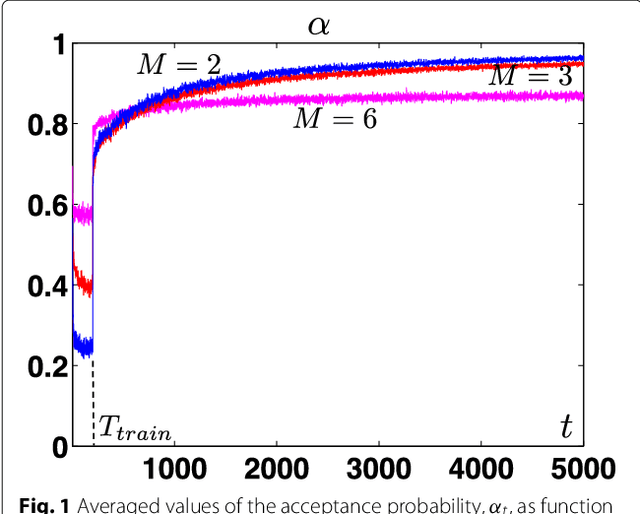
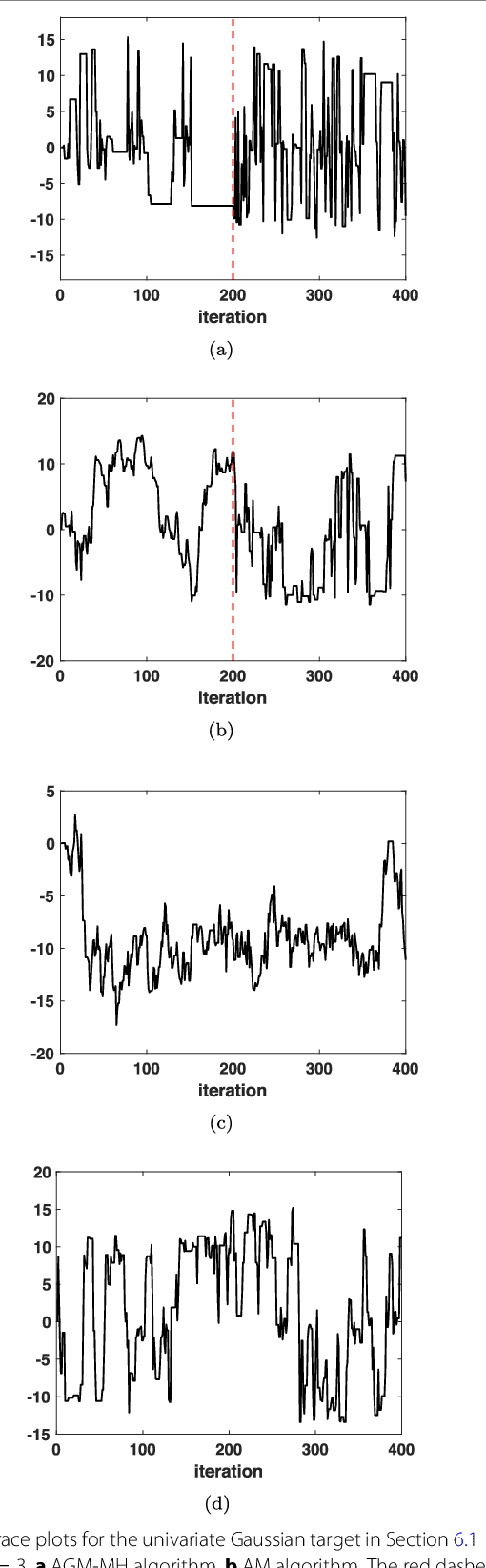
Statistical signal processing applications usually require the estimation of some parameters of interest given a set of observed data. These estimates are typically obtained either by solving a multi-variate optimization problem, as in the maximum likelihood (ML) or maximum a posteriori (MAP) estimators, or by performing a multi-dimensional integration, as in the minimum mean squared error (MMSE) estimators. Unfortunately, analytical expressions for these estimators cannot be found in most real-world applications, and the Monte Carlo (MC) methodology is one feasible approach. MC methods proceed by drawing random samples, either from the desired distribution or from a simpler one, and using them to compute consistent estimators. The most important families of MC algorithms are Markov chain MC (MCMC) and importance sampling (IS). On the one hand, MCMC methods draw samples from a proposal density, building then an ergodic Markov chain whose stationary distribution is the desired distribution by accepting or rejecting those candidate samples as the new state of the chain. On the other hand, IS techniques draw samples from a simple proposal density, and then assign them suitable weights that measure their quality in some appropriate way. In this paper, we perform a thorough review of MC methods for the estimation of static parameters in signal processing applications. A historical note on the development of MC schemes is also provided, followed by the basic MC method and a brief description of the rejection sampling (RS) algorithm, as well as three sections describing many of the most relevant MCMC and IS algorithms, and their combined use.
Layered Adaptive Importance Sampling
Nov 27, 2016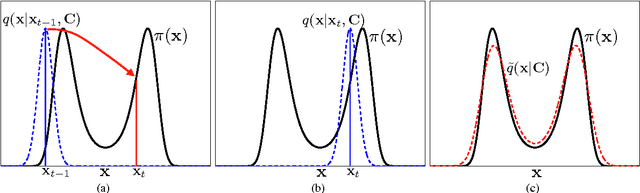


Monte Carlo methods represent the "de facto" standard for approximating complicated integrals involving multidimensional target distributions. In order to generate random realizations from the target distribution, Monte Carlo techniques use simpler proposal probability densities to draw candidate samples. The performance of any such method is strictly related to the specification of the proposal distribution, such that unfortunate choices easily wreak havoc on the resulting estimators. In this work, we introduce a layered (i.e., hierarchical) procedure to generate samples employed within a Monte Carlo scheme. This approach ensures that an appropriate equivalent proposal density is always obtained automatically (thus eliminating the risk of a catastrophic performance), although at the expense of a moderate increase in the complexity. Furthermore, we provide a general unified importance sampling (IS) framework, where multiple proposal densities are employed and several IS schemes are introduced by applying the so-called deterministic mixture approach. Finally, given these schemes, we also propose a novel class of adaptive importance samplers using a population of proposals, where the adaptation is driven by independent parallel or interacting Markov Chain Monte Carlo (MCMC) chains. The resulting algorithms efficiently combine the benefits of both IS and MCMC methods.
Orthogonal parallel MCMC methods for sampling and optimization
Sep 25, 2016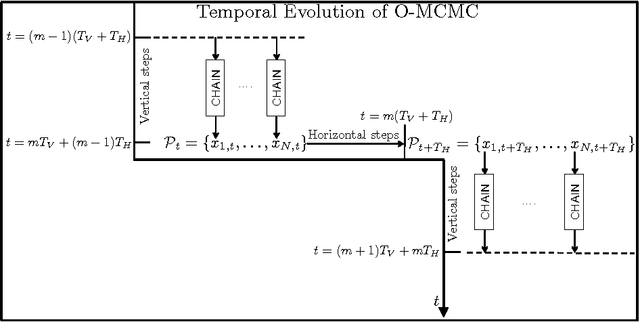

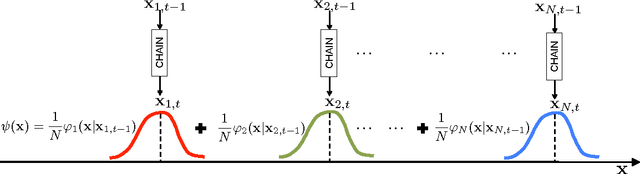
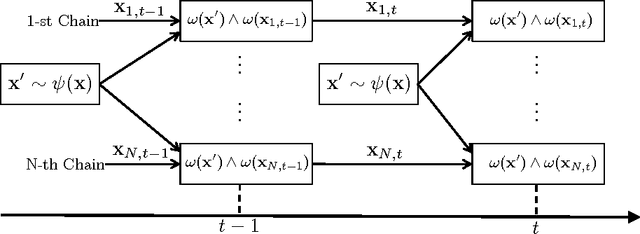
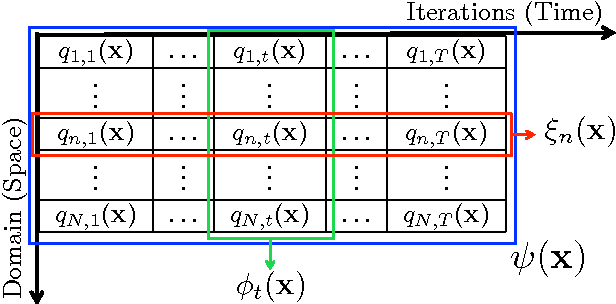
Monte Carlo (MC) methods are widely used for Bayesian inference and optimization in statistics, signal processing and machine learning. A well-known class of MC methods are Markov Chain Monte Carlo (MCMC) algorithms. In order to foster better exploration of the state space, specially in high-dimensional applications, several schemes employing multiple parallel MCMC chains have been recently introduced. In this work, we describe a novel parallel interacting MCMC scheme, called {\it orthogonal MCMC} (O-MCMC), where a set of "vertical" parallel MCMC chains share information using some "horizontal" MCMC techniques working on the entire population of current states. More specifically, the vertical chains are led by random-walk proposals, whereas the horizontal MCMC techniques employ independent proposals, thus allowing an efficient combination of global exploration and local approximation. The interaction is contained in these horizontal iterations. Within the analysis of different implementations of O-MCMC, novel schemes in order to reduce the overall computational cost of parallel multiple try Metropolis (MTM) chains are also presented. Furthermore, a modified version of O-MCMC for optimization is provided by considering parallel simulated annealing (SA) algorithms. Numerical results show the advantages of the proposed sampling scheme in terms of efficiency in the estimation, as well as robustness in terms of independence with respect to initial values and the choice of the parameters.
Adaptive Independent Sticky MCMC algorithms
Jan 02, 2016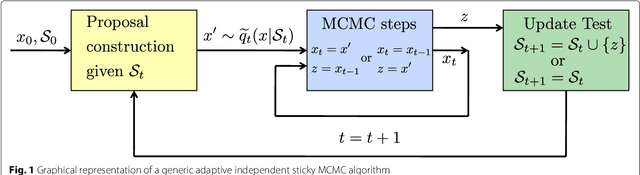
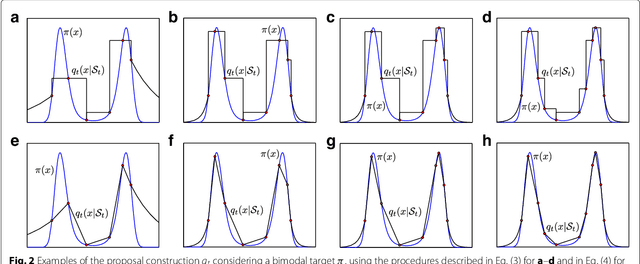

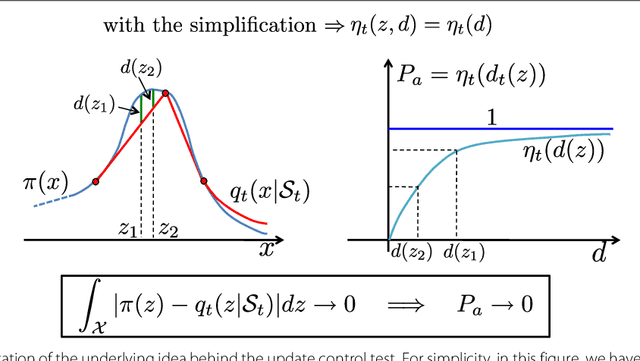
In this work, we introduce a novel class of adaptive Monte Carlo methods, called adaptive independent sticky MCMC algorithms, for efficient sampling from a generic target probability density function (pdf). The new class of algorithms employs adaptive non-parametric proposal densities which become closer and closer to the target as the number of iterations increases. The proposal pdf is built using interpolation procedures based on a set of support points which is constructed iteratively based on previously drawn samples. The algorithm's efficiency is ensured by a test that controls the evolution of the set of support points. This extra stage controls the computational cost and the convergence of the proposal density to the target. Each part of the novel family of algorithms is discussed and several examples are provided. Although the novel algorithms are presented for univariate target densities, we show that they can be easily extended to the multivariate context within a Gibbs-type sampler. The ergodicity is ensured and discussed. Exhaustive numerical examples illustrate the efficiency of sticky schemes, both as a stand-alone methods to sample from complicated one-dimensional pdfs and within Gibbs in order to draw from multi-dimensional target distributions.
Scalable Multi-Output Label Prediction: From Classifier Chains to Classifier Trellises
Jan 20, 2015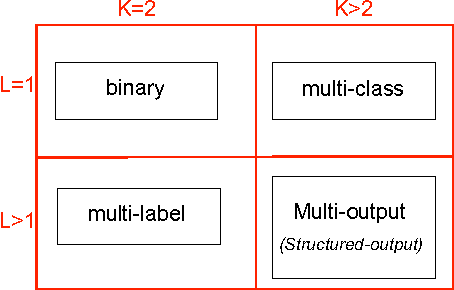

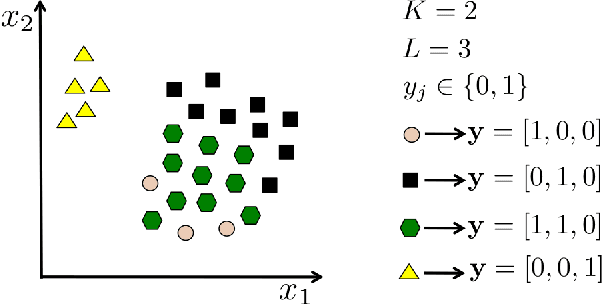

Multi-output inference tasks, such as multi-label classification, have become increasingly important in recent years. A popular method for multi-label classification is classifier chains, in which the predictions of individual classifiers are cascaded along a chain, thus taking into account inter-label dependencies and improving the overall performance. Several varieties of classifier chain methods have been introduced, and many of them perform very competitively across a wide range of benchmark datasets. However, scalability limitations become apparent on larger datasets when modeling a fully-cascaded chain. In particular, the methods' strategies for discovering and modeling a good chain structure constitutes a mayor computational bottleneck. In this paper, we present the classifier trellis (CT) method for scalable multi-label classification. We compare CT with several recently proposed classifier chain methods to show that it occupies an important niche: it is highly competitive on standard multi-label problems, yet it can also scale up to thousands or even tens of thousands of labels.
* (accepted in Pattern Recognition)