 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMVI: 3D Test-Time Adaptation via Masked Multi-View Point Clouds
Jun 11, 20263D point cloud models suffer significant performance degradation under distribution shifts caused by sensor noise, occlusions, and environmental changes. Test-time adaptation (TTA) has emerged as a practical paradigm for mitigating this issue during inference. Recently, leveraging multi-view augmentation has shown promise in improving 3D TTA performance. However, existing multi-view approaches are often constrained by sequential optimization that treats each view independently. This sequential optimization leads to substantial inference latency due to repetitive optimization steps, making real-time adaptation impractical. To address this, we propose Masked Multi-View Test-Time Adaptation (MAMVI), which replaces sequential optimization with a unified single-step adaptation. Specifically, MAMVI utilizes a hybrid masking strategy that combines fixed ratios for stability with Beta-distributed sampling for diversity. By aggregating losses across multiple views, MAMVI performs adaptation through a single backward pass based on multi-view consensus. Additionally, a confidence-based adaptive learning rate is used to dynamically adjust the adaptation intensity for each sample. Extensive experiments on ModelNet-40C, ShapeNet-C, and ScanObjectNN-C demonstrate that MAMVI achieves state-of-the-art accuracy on ShapeNet-C and ScanObjectNN-C. Moreover, it remains competitive on ModelNet-40C while delivering 4.9-8.9 times faster inference, making it highly suitable for real-time applications. Our code is available at https://github.com/Inseok-kong/MAMVI
Generating Accurate and Detailed Captions for High-Resolution Images
Oct 31, 2025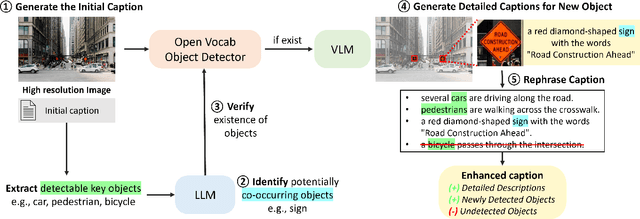
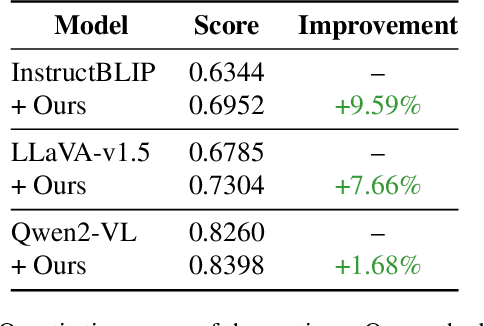
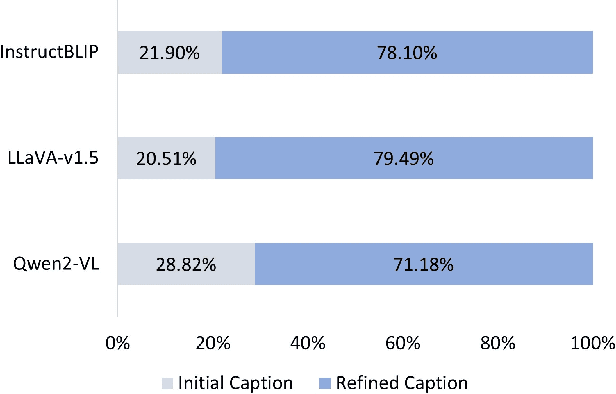
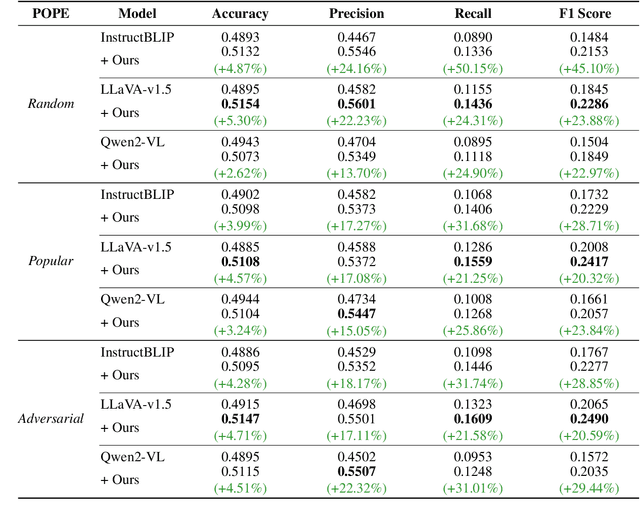
Vision-language models (VLMs) often struggle to generate accurate and detailed captions for high-resolution images since they are typically pre-trained on low-resolution inputs (e.g., 224x224 or 336x336 pixels). Downscaling high-resolution images to these dimensions may result in the loss of visual details and the omission of important objects. To address this limitation, we propose a novel pipeline that integrates vision-language models, large language models (LLMs), and object detection systems to enhance caption quality. Our proposed pipeline refines captions through a novel, multi-stage process. Given a high-resolution image, an initial caption is first generated using a VLM, and key objects in the image are then identified by an LLM. The LLM predicts additional objects likely to co-occur with the identified key objects, and these predictions are verified by object detection systems. Newly detected objects not mentioned in the initial caption undergo focused, region-specific captioning to ensure they are incorporated. This process enriches caption detail while reducing hallucinations by removing references to undetected objects. We evaluate the enhanced captions using pairwise comparison and quantitative scoring from large multimodal models, along with a benchmark for hallucination detection. Experiments on a curated dataset of high-resolution images demonstrate that our pipeline produces more detailed and reliable image captions while effectively minimizing hallucinations.
Enhancing Visual Classification using Comparative Descriptors
Nov 08, 2024



The performance of vision-language models (VLMs), such as CLIP, in visual classification tasks, has been enhanced by leveraging semantic knowledge from large language models (LLMs), including GPT. Recent studies have shown that in zero-shot classification tasks, descriptors incorporating additional cues, high-level concepts, or even random characters often outperform those using only the category name. In many classification tasks, while the top-1 accuracy may be relatively low, the top-5 accuracy is often significantly higher. This gap implies that most misclassifications occur among a few similar classes, highlighting the model's difficulty in distinguishing between classes with subtle differences. To address this challenge, we introduce a novel concept of comparative descriptors. These descriptors emphasize the unique features of a target class against its most similar classes, enhancing differentiation. By generating and integrating these comparative descriptors into the classification framework, we refine the semantic focus and improve classification accuracy. An additional filtering process ensures that these descriptors are closer to the image embeddings in the CLIP space, further enhancing performance. Our approach demonstrates improved accuracy and robustness in visual classification tasks by addressing the specific challenge of subtle inter-class differences.
Flat Posterior Does Matter For Bayesian Transfer Learning
Jun 21, 2024



The large-scale pre-trained neural network has achieved notable success in enhancing performance for downstream tasks. Another promising approach for generalization is Bayesian Neural Network (BNN), which integrates Bayesian methods into neural network architectures, offering advantages such as Bayesian Model averaging (BMA) and uncertainty quantification. Despite these benefits, transfer learning for BNNs has not been widely investigated and shows limited improvement. We hypothesize that this issue arises from the inability to find flat minima, which is crucial for generalization performance. To address this, we evaluate the sharpness of BNNs in various settings, revealing their insufficiency in seeking flat minima and the influence of flatness on BMA performance. Therefore, we propose Sharpness-aware Bayesian Model Averaging (SA-BMA), a Bayesian-fitting flat posterior seeking optimizer integrated with Bayesian transfer learning. SA-BMA calculates the divergence between posteriors in the parameter space, aligning with the nature of BNNs, and serves as a generalized version of existing sharpness-aware optimizers. We validate that SA-BMA improves generalization performance in few-shot classification and distribution shift scenarios by ensuring flatness.
BlackVIP: Black-Box Visual Prompting for Robust Transfer Learning
Mar 26, 2023



With the surge of large-scale pre-trained models (PTMs), fine-tuning these models to numerous downstream tasks becomes a crucial problem. Consequently, parameter efficient transfer learning (PETL) of large models has grasped huge attention. While recent PETL methods showcase impressive performance, they rely on optimistic assumptions: 1) the entire parameter set of a PTM is available, and 2) a sufficiently large memory capacity for the fine-tuning is equipped. However, in most real-world applications, PTMs are served as a black-box API or proprietary software without explicit parameter accessibility. Besides, it is hard to meet a large memory requirement for modern PTMs. In this work, we propose black-box visual prompting (BlackVIP), which efficiently adapts the PTMs without knowledge about model architectures and parameters. BlackVIP has two components; 1) Coordinator and 2) simultaneous perturbation stochastic approximation with gradient correction (SPSA-GC). The Coordinator designs input-dependent image-shaped visual prompts, which improves few-shot adaptation and robustness on distribution/location shift. SPSA-GC efficiently estimates the gradient of a target model to update Coordinator. Extensive experiments on 16 datasets demonstrate that BlackVIP enables robust adaptation to diverse domains without accessing PTMs' parameters, with minimal memory requirements. Code: \url{https://github.com/changdaeoh/BlackVIP}