 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclic Test-Time Adaptation on Monocular Video for 3D Human Mesh Reconstruction
Aug 12, 2023



Despite recent advances in 3D human mesh reconstruction, domain gap between training and test data is still a major challenge. Several prior works tackle the domain gap problem via test-time adaptation that fine-tunes a network relying on 2D evidence (e.g., 2D human keypoints) from test images. However, the high reliance on 2D evidence during adaptation causes two major issues. First, 2D evidence induces depth ambiguity, preventing the learning of accurate 3D human geometry. Second, 2D evidence is noisy or partially non-existent during test time, and such imperfect 2D evidence leads to erroneous adaptation. To overcome the above issues, we introduce CycleAdapt, which cyclically adapts two networks: a human mesh reconstruction network (HMRNet) and a human motion denoising network (MDNet), given a test video. In our framework, to alleviate high reliance on 2D evidence, we fully supervise HMRNet with generated 3D supervision targets by MDNet. Our cyclic adaptation scheme progressively elaborates the 3D supervision targets, which compensate for imperfect 2D evidence. As a result, our CycleAdapt achieves state-of-the-art performance compared to previous test-time adaptation methods. The codes are available at https://github.com/hygenie1228/CycleAdapt_RELEASE.
Overcoming Distribution Mismatch in Quantizing Image Super-Resolution Networks
Jul 25, 2023Quantization is a promising approach to reduce the high computational complexity of image super-resolution (SR) networks. However, compared to high-level tasks like image classification, low-bit quantization leads to severe accuracy loss in SR networks. This is because feature distributions of SR networks are significantly divergent for each channel or input image, and is thus difficult to determine a quantization range. Existing SR quantization works approach this distribution mismatch problem by dynamically adapting quantization ranges to the variant distributions during test time. However, such dynamic adaptation incurs additional computational costs that limit the benefits of quantization. Instead, we propose a new quantization-aware training framework that effectively Overcomes the Distribution Mismatch problem in SR networks without the need for dynamic adaptation. Intuitively, the mismatch can be reduced by directly regularizing the variance in features during training. However, we observe that variance regularization can collide with the reconstruction loss during training and adversely impact SR accuracy. Thus, we avoid the conflict between two losses by regularizing the variance only when the gradients of variance regularization are cooperative with that of reconstruction. Additionally, to further reduce the distribution mismatch, we introduce distribution offsets to layers with a significant mismatch, which either scales or shifts channel-wise features. Our proposed algorithm, called ODM, effectively reduces the mismatch in distributions with minimal computational overhead. Experimental results show that ODM effectively outperforms existing SR quantization approaches with similar or fewer computations, demonstrating the importance of reducing the distribution mismatch problem. Our code is available at https://github.com/Cheeun/ODM.
ICF-SRSR: Invertible scale-Conditional Function for Self-Supervised Real-world Single Image Super-Resolution
Jul 24, 2023Single image super-resolution (SISR) is a challenging ill-posed problem that aims to up-sample a given low-resolution (LR) image to a high-resolution (HR) counterpart. Due to the difficulty in obtaining real LR-HR training pairs, recent approaches are trained on simulated LR images degraded by simplified down-sampling operators, e.g., bicubic. Such an approach can be problematic in practice because of the large gap between the synthesized and real-world LR images. To alleviate the issue, we propose a novel Invertible scale-Conditional Function (ICF), which can scale an input image and then restore the original input with different scale conditions. By leveraging the proposed ICF, we construct a novel self-supervised SISR framework (ICF-SRSR) to handle the real-world SR task without using any paired/unpaired training data. Furthermore, our ICF-SRSR can generate realistic and feasible LR-HR pairs, which can make existing supervised SISR networks more robust. Extensive experiments demonstrate the effectiveness of the proposed method in handling SISR in a fully self-supervised manner. Our ICF-SRSR demonstrates superior performance compared to the existing methods trained on synthetic paired images in real-world scenarios and exhibits comparable performance compared to state-of-the-art supervised/unsupervised methods on public benchmark datasets.
Recovering 3D Hand Mesh Sequence from a Single Blurry Image: A New Dataset and Temporal Unfolding
Mar 27, 2023Hands, one of the most dynamic parts of our body, suffer from blur due to their active movements. However, previous 3D hand mesh recovery methods have mainly focused on sharp hand images rather than considering blur due to the absence of datasets providing blurry hand images. We first present a novel dataset BlurHand, which contains blurry hand images with 3D groundtruths. The BlurHand is constructed by synthesizing motion blur from sequential sharp hand images, imitating realistic and natural motion blurs. In addition to the new dataset, we propose BlurHandNet, a baseline network for accurate 3D hand mesh recovery from a blurry hand image. Our BlurHandNet unfolds a blurry input image to a 3D hand mesh sequence to utilize temporal information in the blurry input image, while previous works output a static single hand mesh. We demonstrate the usefulness of BlurHand for the 3D hand mesh recovery from blurry images in our experiments. The proposed BlurHandNet produces much more robust results on blurry images while generalizing well to in-the-wild images. The training codes and BlurHand dataset are available at https://github.com/JaehaKim97/BlurHand_RELEASE.
ACL-SPC: Adaptive Closed-Loop system for Self-Supervised Point Cloud Completion
Mar 17, 2023Point cloud completion addresses filling in the missing parts of a partial point cloud obtained from depth sensors and generating a complete point cloud. Although there has been steep progress in the supervised methods on the synthetic point cloud completion task, it is hardly applicable in real-world scenarios due to the domain gap between the synthetic and real-world datasets or the requirement of prior information. To overcome these limitations, we propose a novel self-supervised framework ACL-SPC for point cloud completion to train and test on the same data. ACL-SPC takes a single partial input and attempts to output the complete point cloud using an adaptive closed-loop (ACL) system that enforces the output same for the variation of an input. We evaluate our proposed ACL-SPC on various datasets to prove that it can successfully learn to complete a partial point cloud as the first self-supervised scheme. Results show that our method is comparable with unsupervised methods and achieves superior performance on the real-world dataset compared to the supervised methods trained on the synthetic dataset. Extensive experiments justify the necessity of self-supervised learning and the effectiveness of our proposed method for the real-world point cloud completion task. The code is publicly available from https://github.com/Sangminhong/ACL-SPC_PyTorch
Rethinking Self-Supervised Visual Representation Learning in Pre-training for 3D Human Pose and Shape Estimation
Mar 09, 2023



Recently, a few self-supervised representation learning (SSL) methods have outperformed the ImageNet classification pre-training for vision tasks such as object detection. However, its effects on 3D human body pose and shape estimation (3DHPSE) are open to question, whose target is fixed to a unique class, the human, and has an inherent task gap with SSL. We empirically study and analyze the effects of SSL and further compare it with other pre-training alternatives for 3DHPSE. The alternatives are 2D annotation-based pre-training and synthetic data pre-training, which share the motivation of SSL that aims to reduce the labeling cost. They have been widely utilized as a source of weak-supervision or fine-tuning, but have not been remarked as a pre-training source. SSL methods underperform the conventional ImageNet classification pre-training on multiple 3DHPSE benchmarks by 7.7% on average. In contrast, despite a much less amount of pre-training data, the 2D annotation-based pre-training improves accuracy on all benchmarks and shows faster convergence during fine-tuning. Our observations challenge the naive application of the current SSL pre-training to 3DHPSE and relight the value of other data types in the pre-training aspect.
MEIL-NeRF: Memory-Efficient Incremental Learning of Neural Radiance Fields
Dec 31, 2022



Hinged on the representation power of neural networks, neural radiance fields (NeRF) have recently emerged as one of the promising and widely applicable methods for 3D object and scene representation. However, NeRF faces challenges in practical applications, such as large-scale scenes and edge devices with a limited amount of memory, where data needs to be processed sequentially. Under such incremental learning scenarios, neural networks are known to suffer catastrophic forgetting: easily forgetting previously seen data after training with new data. We observe that previous incremental learning algorithms are limited by either low performance or memory scalability issues. As such, we develop a Memory-Efficient Incremental Learning algorithm for NeRF (MEIL-NeRF). MEIL-NeRF takes inspiration from NeRF itself in that a neural network can serve as a memory that provides the pixel RGB values, given rays as queries. Upon the motivation, our framework learns which rays to query NeRF to extract previous pixel values. The extracted pixel values are then used to train NeRF in a self-distillation manner to prevent catastrophic forgetting. As a result, MEIL-NeRF demonstrates constant memory consumption and competitive performance.
MultiAct: Long-Term 3D Human Motion Generation from Multiple Action Labels
Dec 12, 2022



We tackle the problem of generating long-term 3D human motion from multiple action labels. Two main previous approaches, such as action- and motion-conditioned methods, have limitations to solve this problem. The action-conditioned methods generate a sequence of motion from a single action. Hence, it cannot generate long-term motions composed of multiple actions and transitions between actions. Meanwhile, the motion-conditioned methods generate future motions from initial motion. The generated future motions only depend on the past, so they are not controllable by the user's desired actions. We present MultiAct, the first framework to generate long-term 3D human motion from multiple action labels. MultiAct takes account of both action and motion conditions with a unified recurrent generation system. It repetitively takes the previous motion and action label; then, it generates a smooth transition and the motion of the given action. As a result, MultiAct produces realistic long-term motion controlled by the given sequence of multiple action labels. The code will be released.
MonoNHR: Monocular Neural Human Renderer
Oct 02, 2022
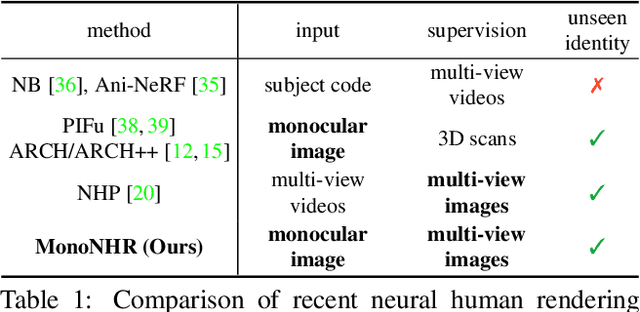
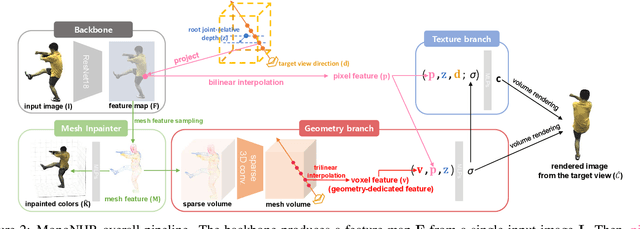
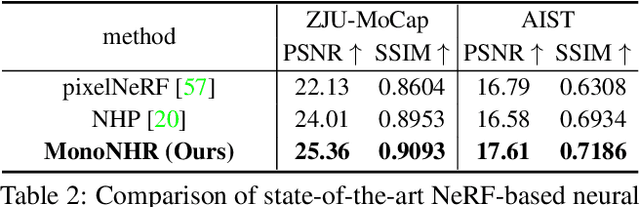
Existing neural human rendering methods struggle with a single image input due to the lack of information in invisible areas and the depth ambiguity of pixels in visible areas. In this regard, we propose Monocular Neural Human Renderer (MonoNHR), a novel approach that renders robust free-viewpoint images of an arbitrary human given only a single image. MonoNHR is the first method that (i) renders human subjects never seen during training in a monocular setup, and (ii) is trained in a weakly-supervised manner without geometry supervision. First, we propose to disentangle 3D geometry and texture features and to condition the texture inference on the 3D geometry features. Second, we introduce a Mesh Inpainter module that inpaints the occluded parts exploiting human structural priors such as symmetry. Experiments on ZJU-MoCap, AIST, and HUMBI datasets show that our approach significantly outperforms the recent methods adapted to the monocular case.
Extraction of Coronary Vessels in Fluoroscopic X-Ray Sequences Using Vessel Correspondence Optimization
Jul 28, 2022We present a method to extract coronary vessels from fluoroscopic x-ray sequences. Given the vessel structure for the source frame, vessel correspondence candidates in the subsequent frame are generated by a novel hierarchical search scheme to overcome the aperture problem. Optimal correspondences are determined within a Markov random field optimization framework. Post-processing is performed to extract vessel branches newly visible due to the inflow of contrast agent. Quantitative and qualitative evaluation conducted on a dataset of 18 sequences demonstrates the effectiveness of the proposed method.