 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Trust in AI Services through Supplier's Declarations of Conformity
Aug 22, 2018The accuracy and reliability of machine learning algorithms are an important concern for suppliers of artificial intelligence (AI) services, but considerations beyond accuracy, such as safety, security, and provenance, are also critical elements to engender consumers' trust in a service. In this paper, we propose a supplier's declaration of conformity (SDoC) for AI services to help increase trust in AI services. An SDoC is a transparent, standardized, but often not legally required, document used in many industries and sectors to describe the lineage of a product along with the safety and performance testing it has undergone. We envision an SDoC for AI services to contain purpose, performance, safety, security, and provenance information to be completed and voluntarily released by AI service providers for examination by consumers. Importantly, it conveys product-level rather than component-level functional testing. We suggest a set of declaration items tailored to AI and provide examples for two fictitious AI services.
Teaching machines to understand data science code by semantic enrichment of dataflow graphs
Jul 16, 2018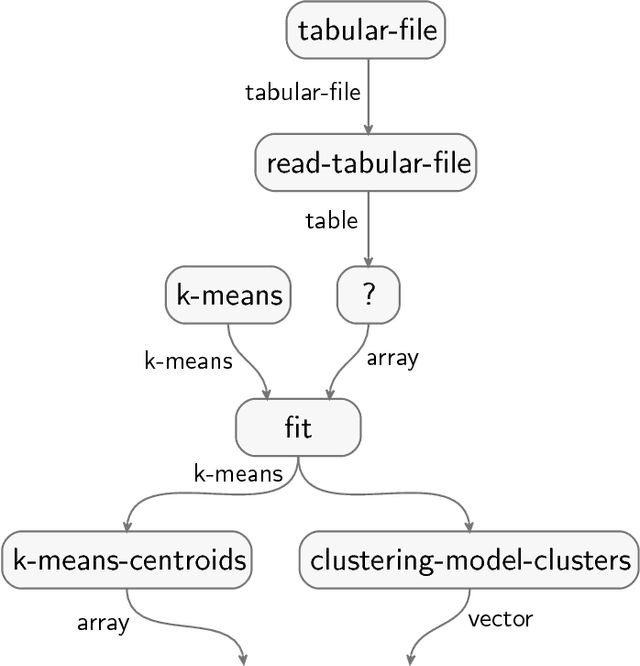

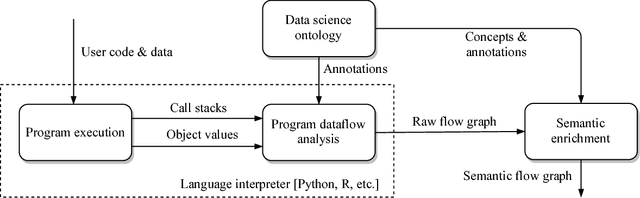
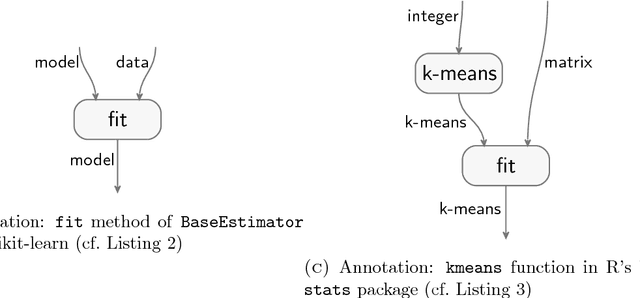
Your computer is continuously executing programs, but does it really understand them? Not in any meaningful sense. That burden falls upon human knowledge workers, who are increasingly asked to write and understand code. They would benefit greatly from intelligent tools that reveal the connections between their code and its subject matter. Towards this prospect, we develop an AI system that forms semantic representations of computer programs, using techniques from knowledge representation and program analysis. We focus on code written for data science, although our method is more generally applicable. The semantic representations are created through a novel algorithm for the semantic enrichment of dataflow graphs. This algorithm is undergirded by a new ontology language for modeling computer programs and a new ontology about data science, written in this language.
Proceedings of the 2018 ICML Workshop on Human Interpretability in Machine Learning
Jul 03, 2018This is the Proceedings of the 2018 ICML Workshop on Human Interpretability in Machine Learning (WHI 2018), which was held in Stockholm, Sweden, July 14, 2018. Invited speakers were Barbara Engelhardt, Cynthia Rudin, Fernanda Vi\'egas, and Martin Wattenberg.
Why Interpretability in Machine Learning? An Answer Using Distributed Detection and Data Fusion Theory
Jun 25, 2018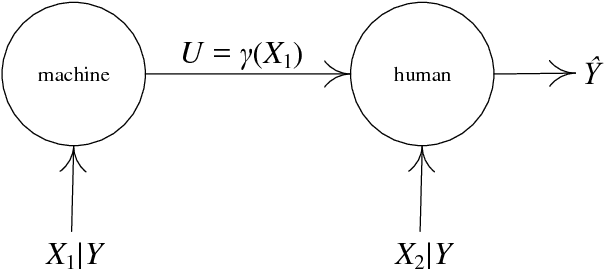
As artificial intelligence is increasingly affecting all parts of society and life, there is growing recognition that human interpretability of machine learning models is important. It is often argued that accuracy or other similar generalization performance metrics must be sacrificed in order to gain interpretability. Such arguments, however, fail to acknowledge that the overall decision-making system is composed of two entities: the learned model and a human who fuses together model outputs with his or her own information. As such, the relevant performance criteria should be for the entire system, not just for the machine learning component. In this work, we characterize the performance of such two-node tandem data fusion systems using the theory of distributed detection. In doing so, we work in the population setting and model interpretable learned models as multi-level quantizers. We prove that under our abstraction, the overall system of a human with an interpretable classifier outperforms one with a black box classifier.
Topological Data Analysis of Decision Boundaries with Application to Model Selection
May 25, 2018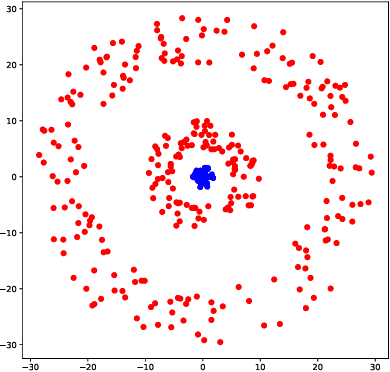
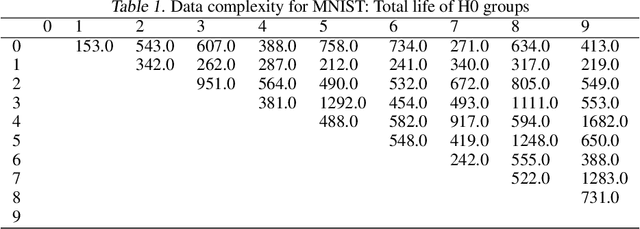
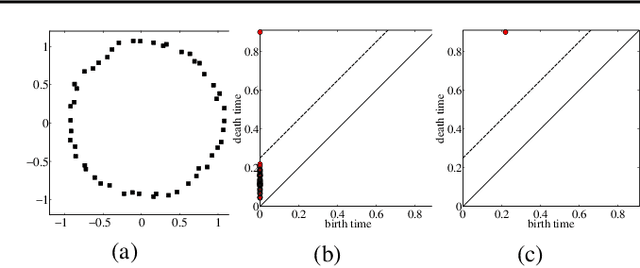
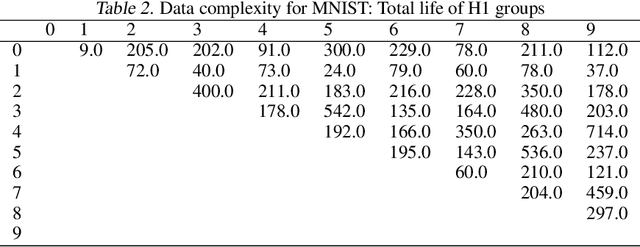
We propose the labeled \v{C}ech complex, the plain labeled Vietoris-Rips complex, and the locally scaled labeled Vietoris-Rips complex to perform persistent homology inference of decision boundaries in classification tasks. We provide theoretical conditions and analysis for recovering the homology of a decision boundary from samples. Our main objective is quantification of deep neural network complexity to enable matching of datasets to pre-trained models; we report results for experiments using MNIST, FashionMNIST, and CIFAR10.
Fairness GAN
May 24, 2018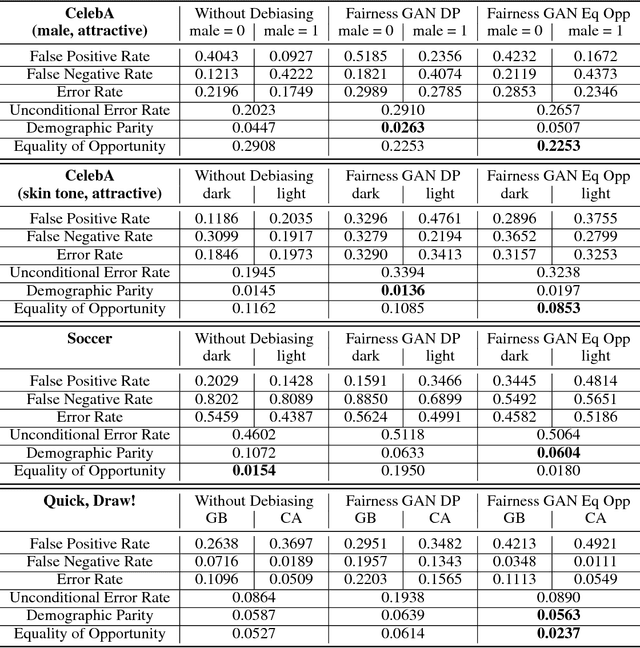
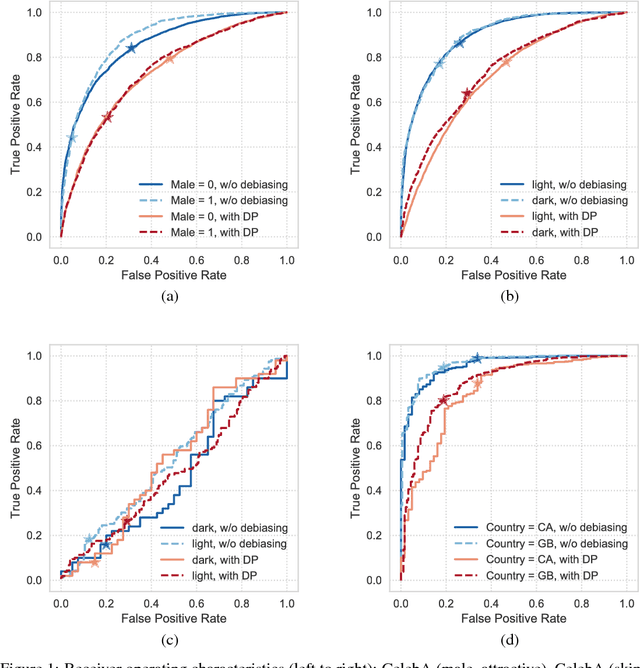
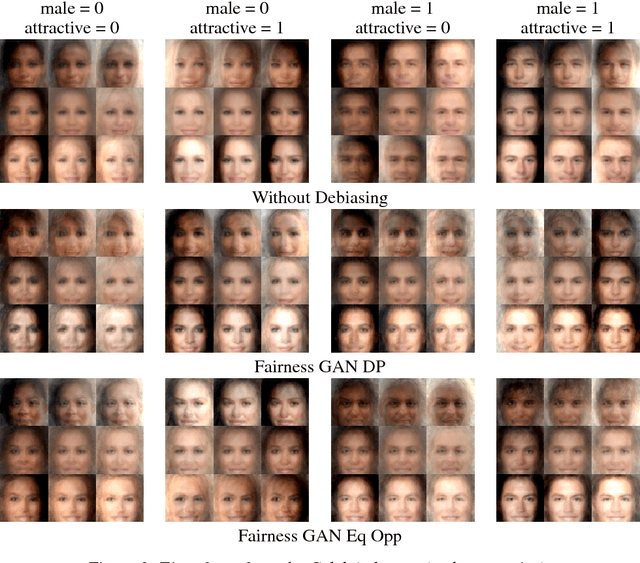
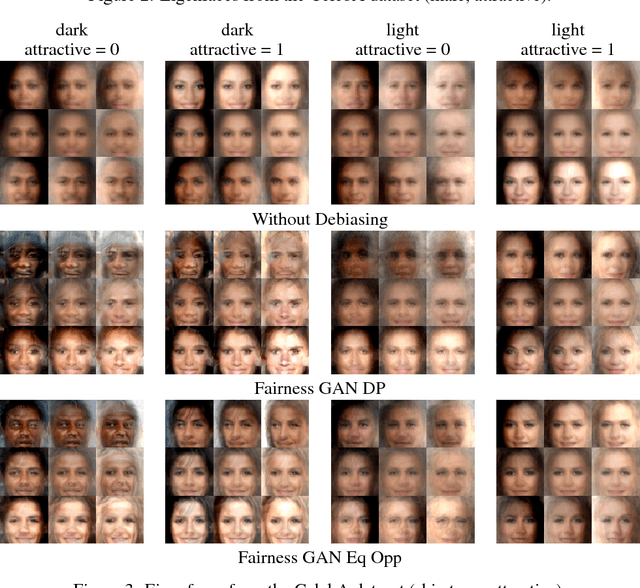
In this paper, we introduce the Fairness GAN, an approach for generating a dataset that is plausibly similar to a given multimedia dataset, but is more fair with respect to protected attributes in allocative decision making. We propose a novel auxiliary classifier GAN that strives for demographic parity or equality of opportunity and show empirical results on several datasets, including the CelebFaces Attributes (CelebA) dataset, the Quick, Draw!\ dataset, and a dataset of soccer player images and the offenses they were called for. The proposed formulation is well-suited to absorbing unlabeled data; we leverage this to augment the soccer dataset with the much larger CelebA dataset. The methodology tends to improve demographic parity and equality of opportunity while generating plausible images.
Structure Learning from Time Series with False Discovery Control
May 24, 2018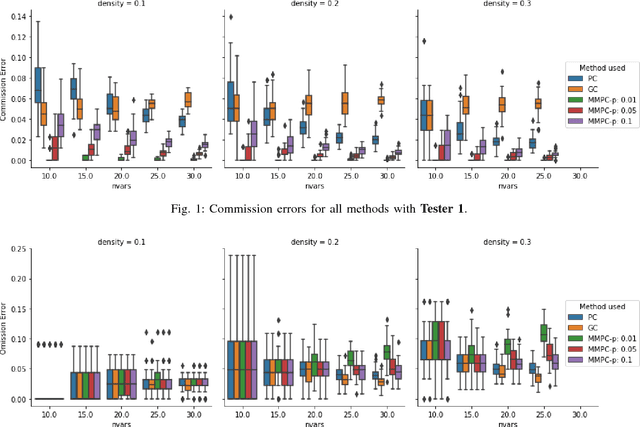
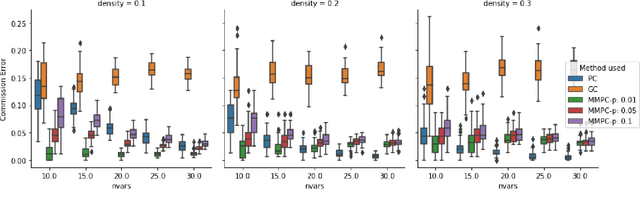
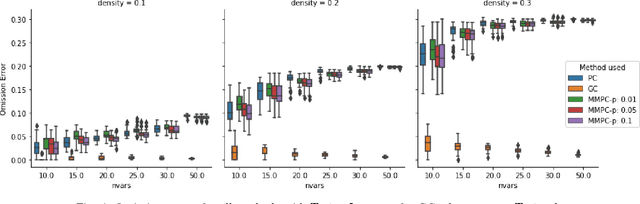
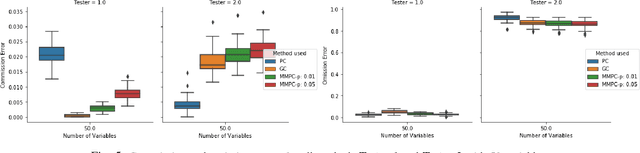
We consider the Granger causal structure learning problem from time series data. Granger causal algorithms predict a 'Granger causal effect' between two variables by testing if prediction error of one decreases significantly in the absence of the other variable among the predictor covariates. Almost all existing Granger causal algorithms condition on a large number of variables (all but two variables) to test for effects between a pair of variables. We propose a new structure learning algorithm called MMPC-p inspired by the well known MMHC algorithm for non-time series data. We show that under some assumptions, the algorithm provides false discovery rate control. The algorithm is sound and complete when given access to perfect directed information testing oracles. We also outline a novel tester for the linear Gaussian case. We show through our extensive experiments that the MMPC-p algorithm scales to larger problems and has improved statistical power compared to existing state of the art for large sparse graphs. We also apply our algorithm on a global development dataset and validate our findings with subject matter experts.
How an Electrical Engineer Became an Artificial Intelligence Researcher, a Multiphase Active Contours Analysis
Mar 29, 2018
This essay examines how what is considered to be artificial intelligence (AI) has changed over time and come to intersect with the expertise of the author. Initially, AI developed on a separate trajectory, both topically and institutionally, from pattern recognition, neural information processing, decision and control systems, and allied topics by focusing on symbolic systems within computer science departments rather than on continuous systems in electrical engineering departments. The separate evolutions continued throughout the author's lifetime, with some crossover in reinforcement learning and graphical models, but were shocked into converging by the virality of deep learning, thus making an electrical engineer into an AI researcher. Now that this convergence has happened, opportunity exists to pursue an agenda that combines learning and reasoning bridged by interpretable machine learning models.
Neurology-as-a-Service for the Developing World
Nov 22, 2017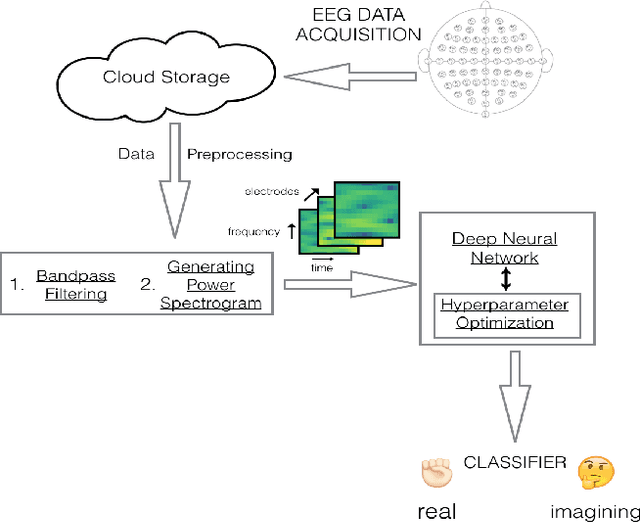

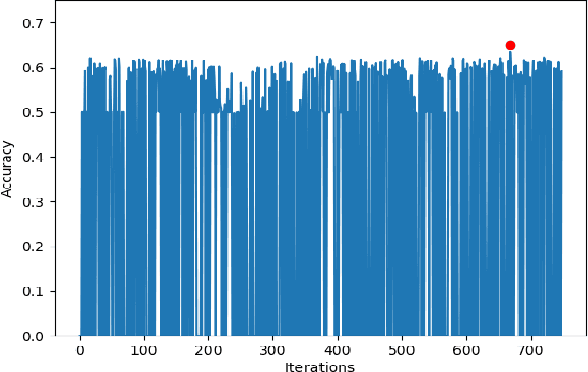
Electroencephalography (EEG) is an extensively-used and well-studied technique in the field of medical diagnostics and treatment for brain disorders, including epilepsy, migraines, and tumors. The analysis and interpretation of EEGs require physicians to have specialized training, which is not common even among most doctors in the developed world, let alone the developing world where physician shortages plague society. This problem can be addressed by teleEEG that uses remote EEG analysis by experts or by local computer processing of EEGs. However, both of these options are prohibitively expensive and the second option requires abundant computing resources and infrastructure, which is another concern in developing countries where there are resource constraints on capital and computing infrastructure. In this work, we present a cloud-based deep neural network approach to provide decision support for non-specialist physicians in EEG analysis and interpretation. Named `neurology-as-a-service,' the approach requires almost no manual intervention in feature engineering and in the selection of an optimal architecture and hyperparameters of the neural network. In this study, we deploy a pipeline that includes moving EEG data to the cloud and getting optimal models for various classification tasks. Our initial prototype has been tested only in developed world environments to-date, but our intention is to test it in developing world environments in future work. We demonstrate the performance of our proposed approach using the BCI2000 EEG MMI dataset, on which our service attains 63.4% accuracy for the task of classifying real vs. imaginary activity performed by the subject, which is significantly higher than what is obtained with a shallow approach such as support vector machines.
Distribution-Preserving k-Anonymity
Nov 05, 2017
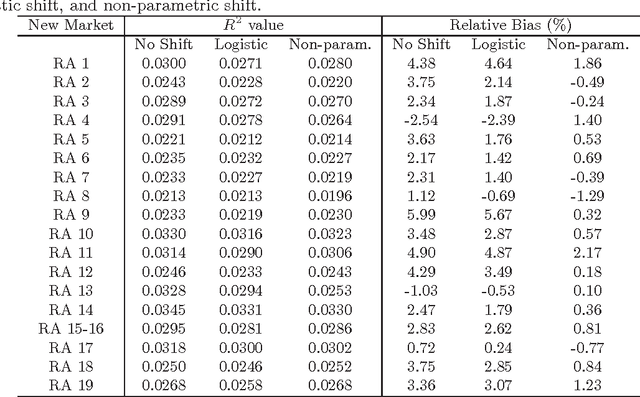
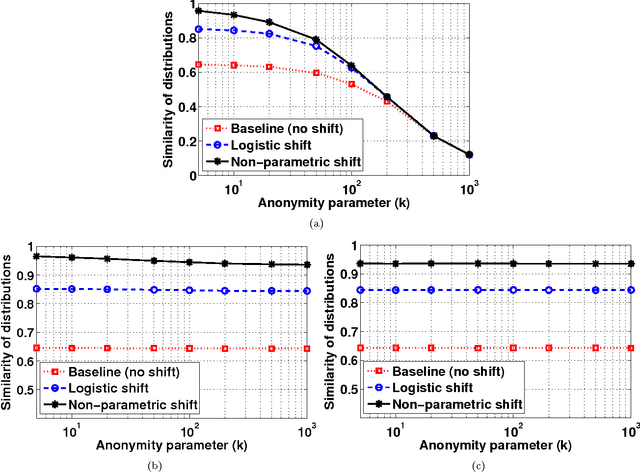
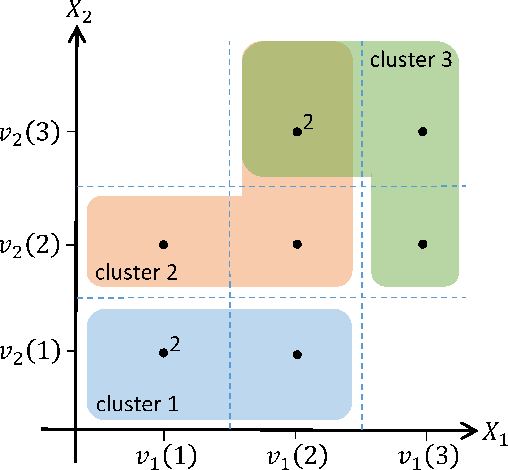
Preserving the privacy of individuals by protecting their sensitive attributes is an important consideration during microdata release. However, it is equally important to preserve the quality or utility of the data for at least some targeted workloads. We propose a novel framework for privacy preservation based on the k-anonymity model that is ideally suited for workloads that require preserving the probability distribution of the quasi-identifier variables in the data. Our framework combines the principles of distribution-preserving quantization and k-member clustering, and we specialize it to two variants that respectively use intra-cluster and Gaussian dithering of cluster centers to achieve distribution preservation. We perform theoretical analysis of the proposed schemes in terms of distribution preservation, and describe their utility in workloads such as covariate shift and transfer learning where such a property is necessary. Using extensive experiments on real-world Medical Expenditure Panel Survey data, we demonstrate the merits of our algorithms over standard k-anonymization for a hallmark health care application where an insurance company wishes to understand the risk in entering a new market. Furthermore, by empirically quantifying the reidentification risk, we also show that the proposed approaches indeed maintain k-anonymity.