 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Measuring the Diversity of Organizational Networks
May 14, 2021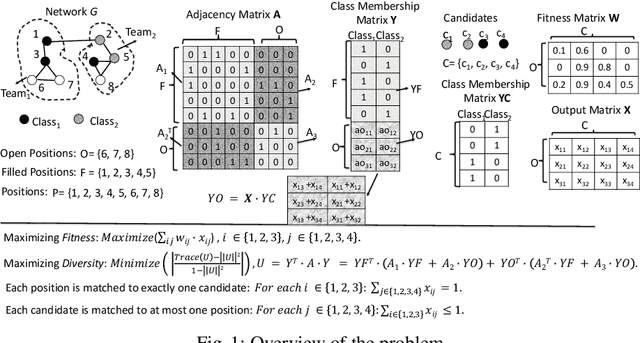
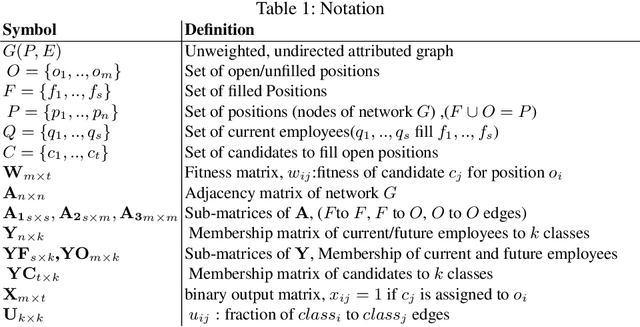
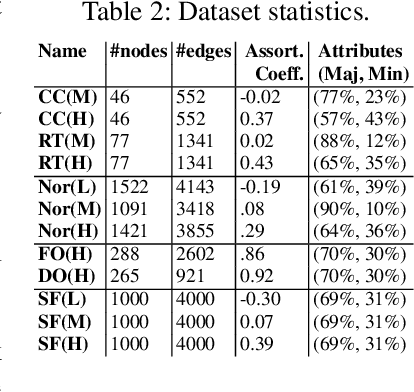
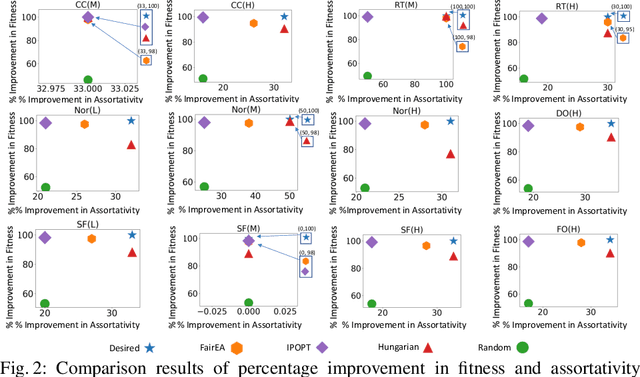
The interaction patterns of employees in social and professional networks play an important role in the success of employees and organizations as a whole. However, in many fields there is a severe under-representation of minority groups; moreover, minority individuals may be segregated from the rest of the network or isolated from one another. While the problem of increasing the representation of minority groups in various fields has been well-studied, diver- sification in terms of numbers alone may not be sufficient: social relationships should also be considered. In this work, we consider the problem of assigning a set of employment candidates to positions in a social network so that diversity and overall fitness are maximized, and propose Fair Employee Assignment (FairEA), a novel algorithm for finding such a matching. The output from FairEA can be used as a benchmark by organizations wishing to evaluate their hiring and assignment practices. On real and synthetic networks, we demonstrate that FairEA does well at finding high-fitness, high-diversity matchings.
Pairwise Fairness for Ordinal Regression
May 07, 2021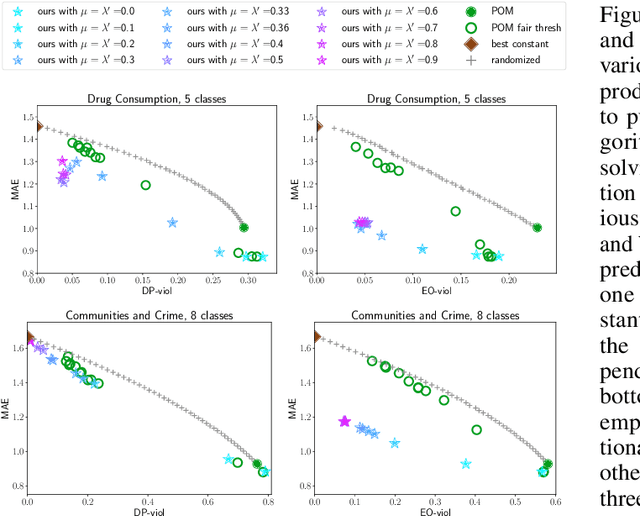
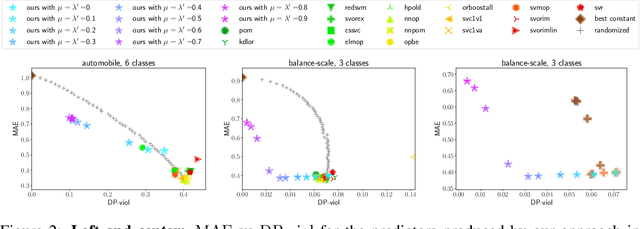
We initiate the study of fairness for ordinal regression, or ordinal classification. We adapt two fairness notions previously considered in fair ranking and propose a strategy for training a predictor that is approximately fair according to either notion. Our predictor consists of a threshold model, composed of a scoring function and a set of thresholds, and our strategy is based on a reduction to fair binary classification for learning the scoring function and local search for choosing the thresholds. We can control the extent to which we care about the accuracy vs the fairness of the predictor via a parameter. In extensive experiments we show that our strategy allows us to effectively explore the accuracy-vs-fairness trade-off and that it often compares favorably to "unfair" state-of-the-art methods for ordinal regression in that it yields predictors that are only slightly less accurate, but significantly more fair.
Differentially Private Query Release Through Adaptive Projection
Mar 11, 2021

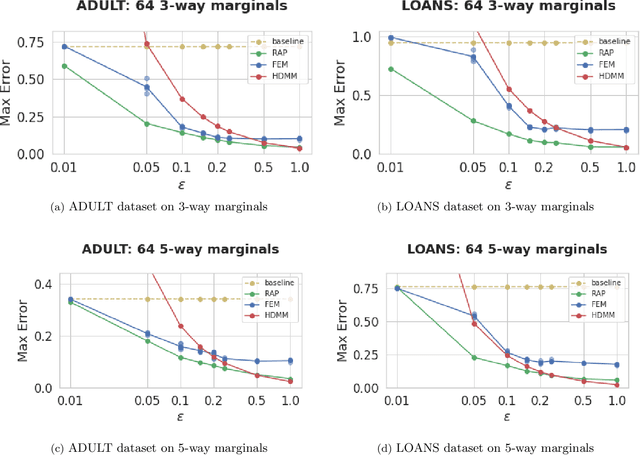
We propose, implement, and evaluate a new algorithm for releasing answers to very large numbers of statistical queries like $k$-way marginals, subject to differential privacy. Our algorithm makes adaptive use of a continuous relaxation of the Projection Mechanism, which answers queries on the private dataset using simple perturbation, and then attempts to find the synthetic dataset that most closely matches the noisy answers. We use a continuous relaxation of the synthetic dataset domain which makes the projection loss differentiable, and allows us to use efficient ML optimization techniques and tooling. Rather than answering all queries up front, we make judicious use of our privacy budget by iteratively and adaptively finding queries for which our (relaxed) synthetic data has high error, and then repeating the projection. We perform extensive experimental evaluations across a range of parameters and datasets, and find that our method outperforms existing algorithms in many cases, especially when the privacy budget is small or the query class is large.
Towards Unbiased and Accurate Deferral to Multiple Experts
Feb 25, 2021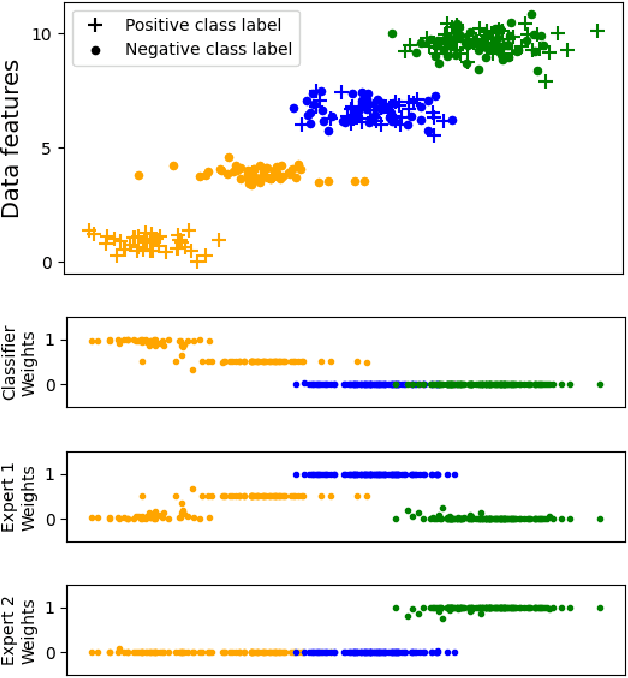
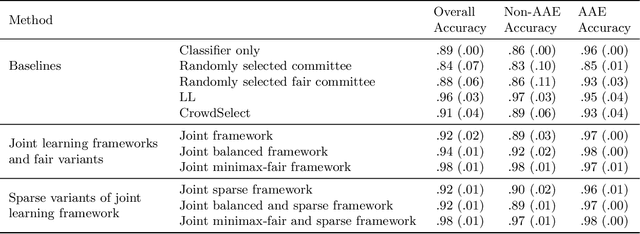
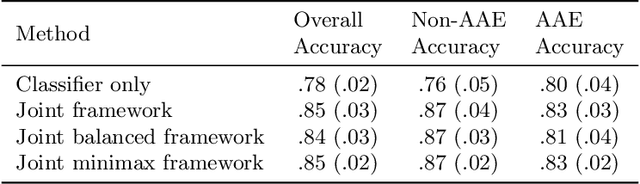
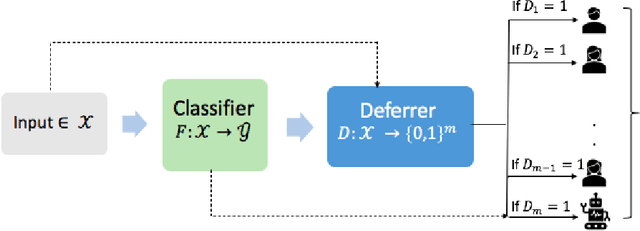
Machine learning models are often implemented in cohort with humans in the pipeline, with the model having an option to defer to a domain expert in cases where it has low confidence in its inference. Our goal is to design mechanisms for ensuring accuracy and fairness in such prediction systems that combine machine learning model inferences and domain expert predictions. Prior work on "deferral systems" in classification settings has focused on the setting of a pipeline with a single expert and aimed to accommodate the inaccuracies and biases of this expert to simultaneously learn an inference model and a deferral system. Our work extends this framework to settings where multiple experts are available, with each expert having their own domain of expertise and biases. We propose a framework that simultaneously learns a classifier and a deferral system, with the deferral system choosing to defer to one or more human experts in cases of input where the classifier has low confidence. We test our framework on a synthetic dataset and a content moderation dataset with biased synthetic experts, and show that it significantly improves the accuracy and fairness of the final predictions, compared to the baselines. We also collect crowdsourced labels for the content moderation task to construct a real-world dataset for the evaluation of hybrid machine-human frameworks and show that our proposed learning framework outperforms baselines on this real-world dataset as well.
Defuse: Harnessing Unrestricted Adversarial Examples for Debugging Models Beyond Test Accuracy
Feb 11, 2021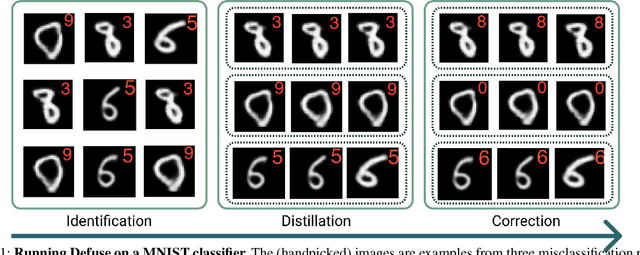
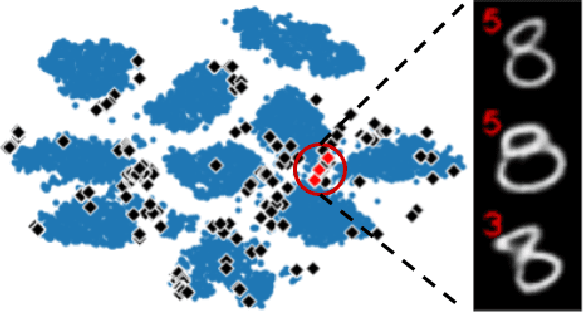

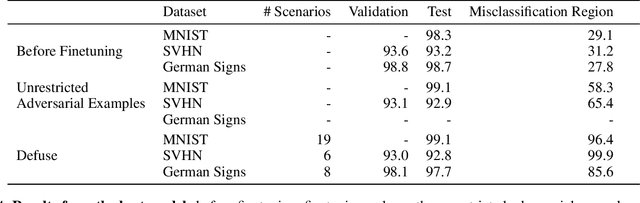
We typically compute aggregate statistics on held-out test data to assess the generalization of machine learning models. However, statistics on test data often overstate model generalization, and thus, the performance of deployed machine learning models can be variable and untrustworthy. Motivated by these concerns, we develop methods to automatically discover and correct model errors beyond those available in the data. We propose Defuse, a method that generates novel model misclassifications, categorizes these errors into high-level model bugs, and efficiently labels and fine-tunes on the errors to correct them. To generate misclassified data, we propose an algorithm inspired by adversarial machine learning techniques that uses a generative model to find naturally occurring instances misclassified by a model. Further, we observe that the generative models have regions in their latent space with higher concentrations of misclassifications. We call these regions misclassification regions and find they have several useful properties. Each region contains a specific type of model bug; for instance, a misclassification region for an MNIST classifier contains a style of skinny 6 that the model mistakes as a 1. We can also assign a single label to each region, facilitating low-cost labeling. We propose a method to learn the misclassification regions and use this insight to both categorize errors and correct them. In practice, Defuse finds and corrects novel errors in classifiers. For example, Defuse shows that a high-performance traffic sign classifier mistakes certain 50km/h signs as 80km/h. Defuse corrects the error after fine-tuning while maintaining generalization on the test set.
Amazon SageMaker Automatic Model Tuning: Scalable Black-box Optimization
Dec 15, 2020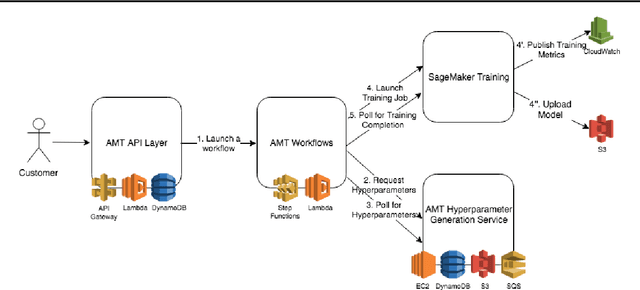
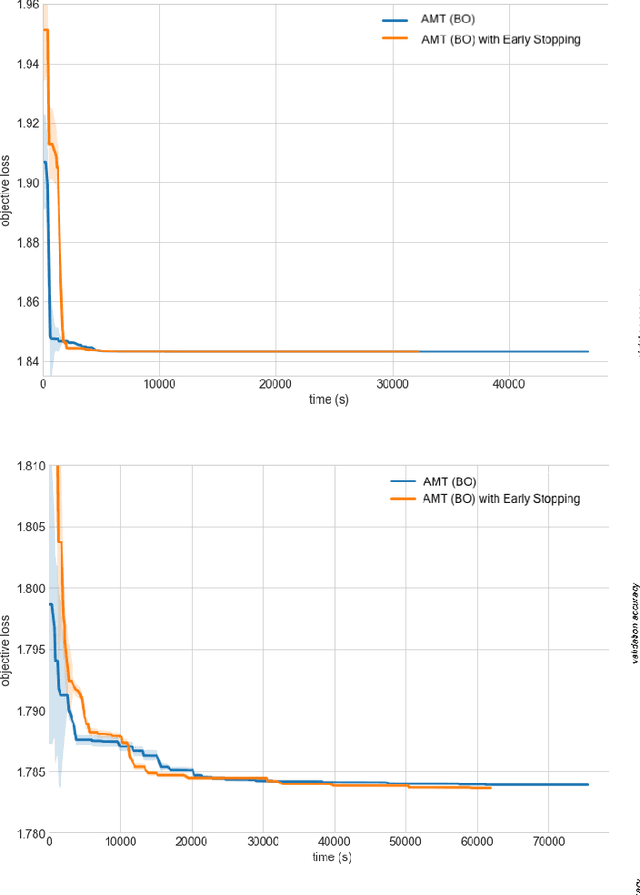
Tuning complex machine learning systems is challenging. Machine learning models typically expose a set of hyperparameters, be it regularization, architecture, or optimization parameters, whose careful tuning is critical to achieve good performance. To democratize access to such systems, it is essential to automate this tuning process. This paper presents Amazon SageMaker Automatic Model Tuning (AMT), a fully managed system for black-box optimization at scale. AMT finds the best version of a machine learning model by repeatedly training it with different hyperparameter configurations. It leverages either random search or Bayesian optimization to choose the hyperparameter values resulting in the best-performing model, as measured by the metric chosen by the user. AMT can be used with built-in algorithms, custom algorithms, and Amazon SageMaker pre-built containers for machine learning frameworks. We discuss the core functionality, system architecture and our design principles. We also describe some more advanced features provided by AMT, such as automated early stopping and warm-starting, demonstrating their benefits in experiments.
Convergent Algorithms for (Relaxed) Minimax Fairness
Nov 05, 2020
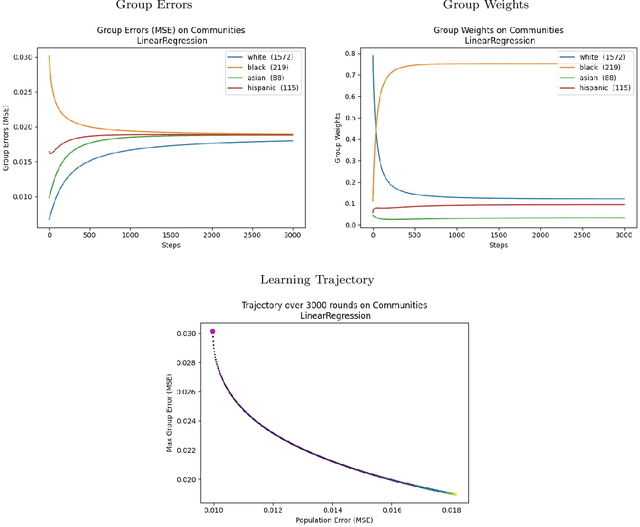
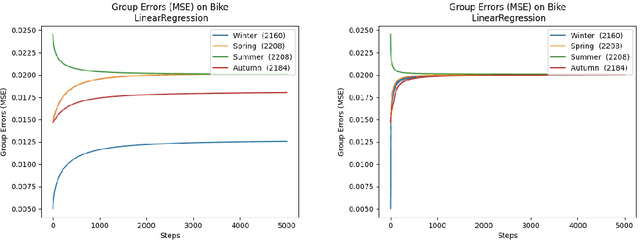
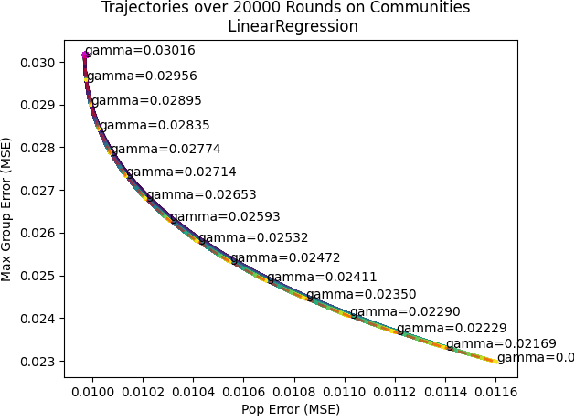
We consider a recently introduced framework in which fairness is measured by worst-case outcomes across groups, rather than by the more standard $\textit{difference}$ between group outcomes. In this framework we provide provably convergent $\textit{oracle-efficient}$ learning algorithms (or equivalently, reductions to non-fair learning) for $\textit{minimax group fairness}$. Here the goal is that of minimizing the maximum loss across all groups, rather than equalizing group losses. Our algorithms apply to both regression and classification settings and support both overall error and false positive or false negative rates as the fairness measure of interest. They also support relaxations of the fairness constraints, thus permitting study of the tradeoff between overall accuracy and minimax fairness. We compare the experimental behavior and performance of our algorithms across a variety of fairness-sensitive data sets and show cases in which minimax fairness is strictly and strongly preferable to equal outcome notions, in the sense that equal outcomes can only be obtained by artificially inflating the harm inflicted on some groups compared to what they suffer under the minimax solution.
Fairness-Aware Online Personalization
Sep 06, 2020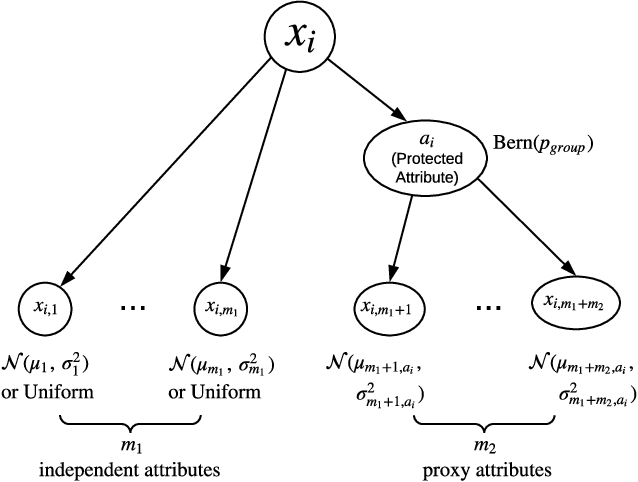
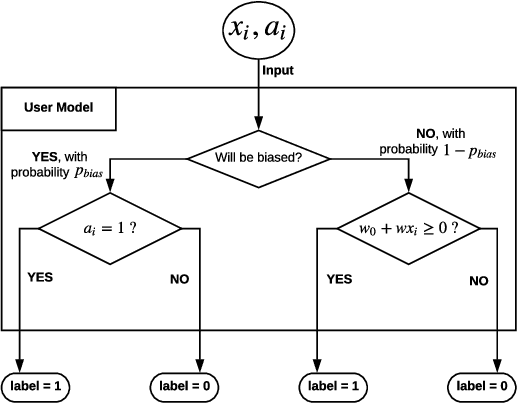
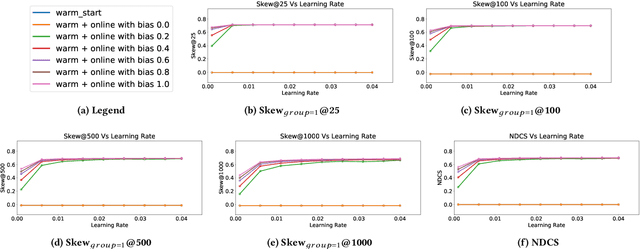
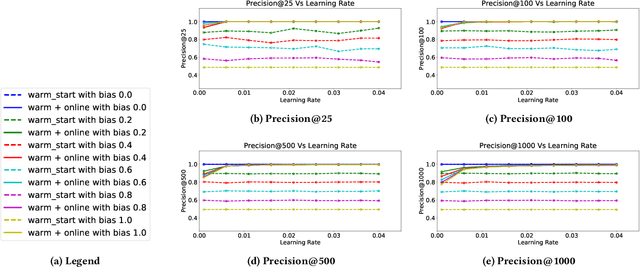
Decision making in crucial applications such as lending, hiring, and college admissions has witnessed increasing use of algorithmic models and techniques as a result of a confluence of factors such as ubiquitous connectivity, ability to collect, aggregate, and process large amounts of fine-grained data using cloud computing, and ease of access to applying sophisticated machine learning models. Quite often, such applications are powered by search and recommendation systems, which in turn make use of personalized ranking algorithms. At the same time, there is increasing awareness about the ethical and legal challenges posed by the use of such data-driven systems. Researchers and practitioners from different disciplines have recently highlighted the potential for such systems to discriminate against certain population groups, due to biases in the datasets utilized for learning their underlying recommendation models. We present a study of fairness in online personalization settings involving the ranking of individuals. Starting from a fair warm-start machine-learned model, we first demonstrate that online personalization can cause the model to learn to act in an unfair manner if the user is biased in his/her responses. For this purpose, we construct a stylized model for generating training data with potentially biased features as well as potentially biased labels and quantify the extent of bias that is learned by the model when the user responds in a biased manner as in many real-world scenarios. We then formulate the problem of learning personalized models under fairness constraints and present a regularization based approach for mitigating biases in machine learning. We demonstrate the efficacy of our approach through extensive simulations with different parameter settings. Code: https://github.com/groshanlal/Fairness-Aware-Online-Personalization
LiFT: A Scalable Framework for Measuring Fairness in ML Applications
Aug 14, 2020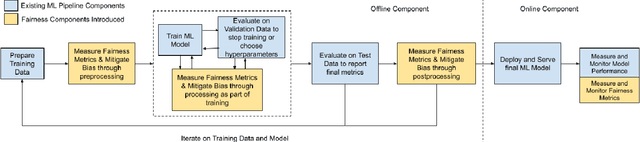
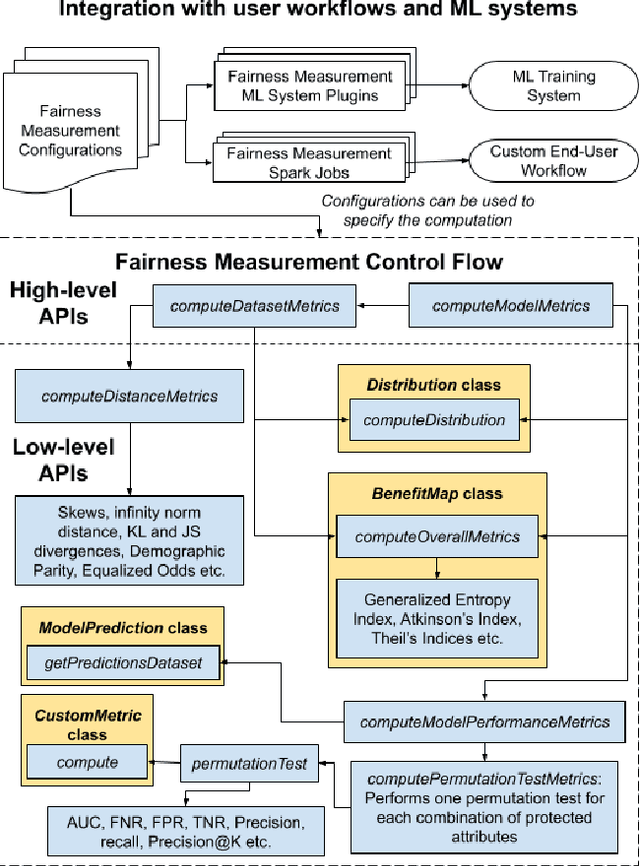
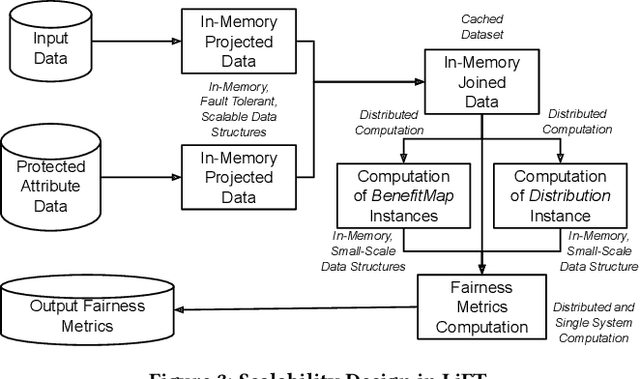
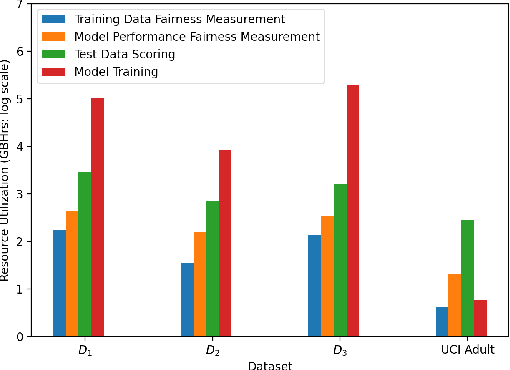
Many internet applications are powered by machine learned models, which are usually trained on labeled datasets obtained through either implicit / explicit user feedback signals or human judgments. Since societal biases may be present in the generation of such datasets, it is possible for the trained models to be biased, thereby resulting in potential discrimination and harms for disadvantaged groups. Motivated by the need for understanding and addressing algorithmic bias in web-scale ML systems and the limitations of existing fairness toolkits, we present the LinkedIn Fairness Toolkit (LiFT), a framework for scalable computation of fairness metrics as part of large ML systems. We highlight the key requirements in deployed settings, and present the design of our fairness measurement system. We discuss the challenges encountered in incorporating fairness tools in practice and the lessons learned during deployment at LinkedIn. Finally, we provide open problems based on practical experience.
Fair Bayesian Optimization
Jun 09, 2020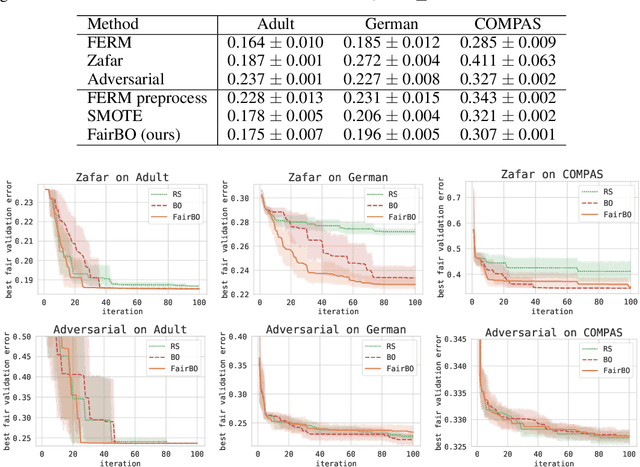
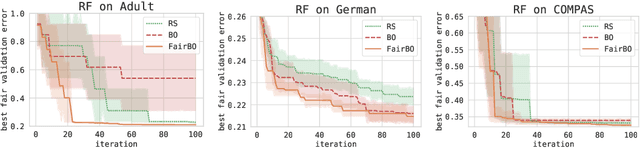

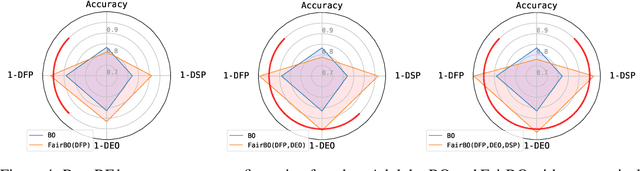
Given the increasing importance of machine learning (ML) in our lives, algorithmic fairness techniques have been proposed to mitigate biases that can be amplified by ML. Commonly, these specialized techniques apply to a single family of ML models and a specific definition of fairness, limiting their effectiveness in practice. We introduce a general constrained Bayesian optimization (BO) framework to optimize the performance of any ML model while enforcing one or multiple fairness constraints. BO is a global optimization method that has been successfully applied to automatically tune the hyperparameters of ML models. We apply BO with fairness constraints to a range of popular models, including random forests, gradient boosting, and neural networks, showing that we can obtain accurate and fair solutions by acting solely on the hyperparameters. We also show empirically that our approach is competitive with specialized techniques that explicitly enforce fairness constraints during training, and outperforms preprocessing methods that learn unbiased representations of the input data. Moreover, our method can be used in synergy with such specialized fairness techniques to tune their hyperparameters. Finally, we study the relationship between hyperparameters and fairness of the generated model. We observe a correlation between regularization and unbiased models, explaining why acting on the hyperparameters leads to ML models that generalize well and are fair.