 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAUVE Scores for Generative Models: Theory and Practice
Dec 30, 2022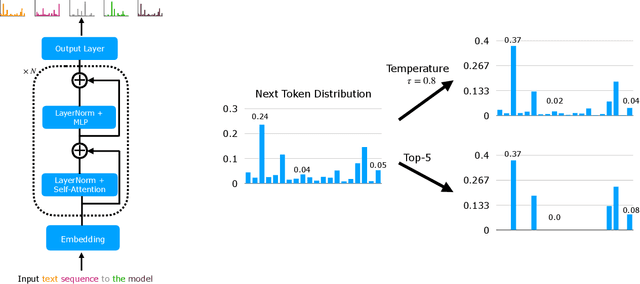
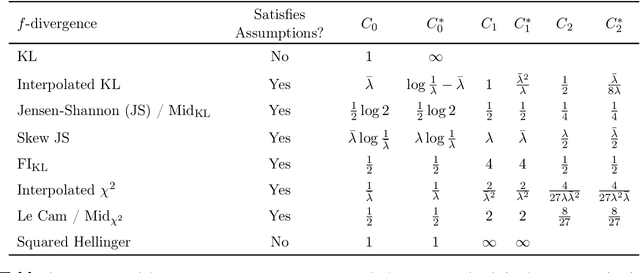
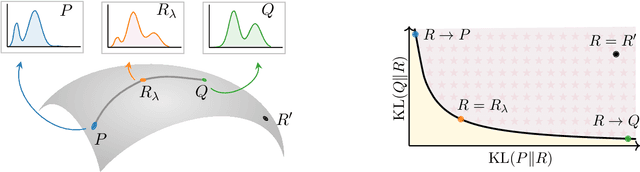

Generative AI has matured to a point where large-scale models can generate text that seems indistinguishable from human-written text and remarkably photorealistic images. Automatically measuring how close the distribution of generated data is to the target real data distribution is a key step in diagnosing existing models and developing better models. We present MAUVE, a family of comparison measures between pairs of distributions such as those encountered in the generative modeling of text or images. These scores are statistical summaries of divergence frontiers capturing two types of errors in generative modeling. We explore four approaches to statistically estimate these scores: vector quantization, non-parametric estimation, classifier-based estimation, and parametric Gaussian approximations. We provide statistical bounds for the vector quantization approach. Empirically, we find that the proposed scores paired with a range of $f$-divergences and statistical estimation methods can quantify the gaps between the distributions of human-written text and those of modern neural language models by correlating with human judgments and identifying known properties of the generated texts. We conclude the paper by demonstrating its applications to other AI domains and discussing practical recommendations.
Stochastic Optimization for Spectral Risk Measures
Dec 10, 2022



Spectral risk objectives - also called $L$-risks - allow for learning systems to interpolate between optimizing average-case performance (as in empirical risk minimization) and worst-case performance on a task. We develop stochastic algorithms to optimize these quantities by characterizing their subdifferential and addressing challenges such as biasedness of subgradient estimates and non-smoothness of the objective. We show theoretically and experimentally that out-of-the-box approaches such as stochastic subgradient and dual averaging are hindered by bias and that our approach outperforms them.
Statistical and Computational Guarantees for Influence Diagnostics
Dec 08, 2022



Influence diagnostics such as influence functions and approximate maximum influence perturbations are popular in machine learning and in AI domain applications. Influence diagnostics are powerful statistical tools to identify influential datapoints or subsets of datapoints. We establish finite-sample statistical bounds, as well as computational complexity bounds, for influence functions and approximate maximum influence perturbations using efficient inverse-Hessian-vector product implementations. We illustrate our results with generalized linear models and large attention based models on synthetic and real data.
Federated Learning with Partial Model Personalization
Apr 08, 2022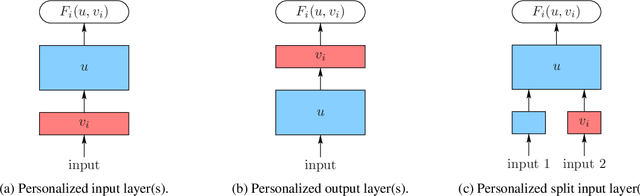

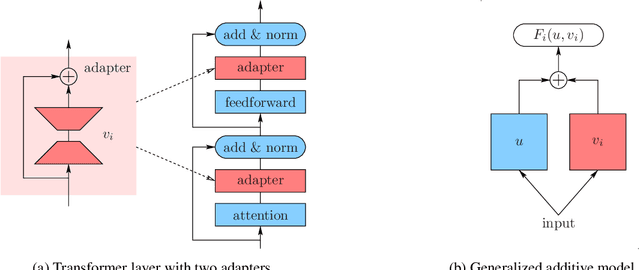

We consider two federated learning algorithms for training partially personalized models, where the shared and personal parameters are updated either simultaneously or alternately on the devices. Both algorithms have been proposed in the literature, but their convergence properties are not fully understood, especially for the alternating variant. We provide convergence analyses of both algorithms in the general nonconvex setting with partial participation and delineate the regime where one dominates the other. Our experiments on real-world image, text, and speech datasets demonstrate that (a) partial personalization can obtain most of the benefits of full model personalization with a small fraction of personal parameters, and, (b) the alternating update algorithm often outperforms the simultaneous update algorithm.
Federated Learning with Heterogeneous Data: A Superquantile Optimization Approach
Dec 17, 2021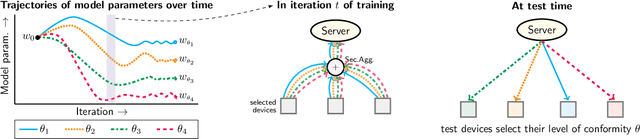

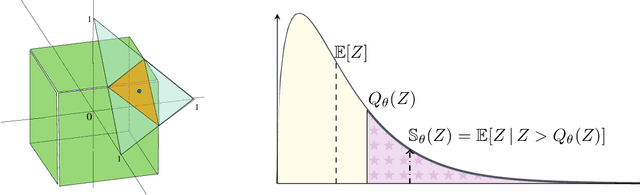
We present a federated learning framework that is designed to robustly deliver good predictive performance across individual clients with heterogeneous data. The proposed approach hinges upon a superquantile-based learning objective that captures the tail statistics of the error distribution over heterogeneous clients. We present a stochastic training algorithm which interleaves differentially private client reweighting steps with federated averaging steps. The proposed algorithm is supported with finite time convergence guarantees that cover both convex and non-convex settings. Experimental results on benchmark datasets for federated learning demonstrate that our approach is competitive with classical ones in terms of average error and outperforms them in terms of tail statistics of the error.
Divergence Frontiers for Generative Models: Sample Complexity, Quantization Level, and Frontier Integral
Jun 15, 2021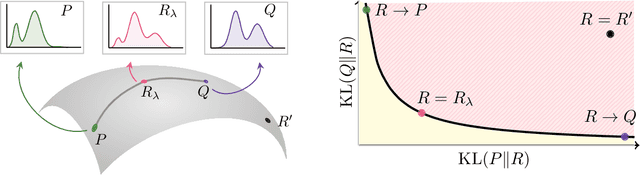
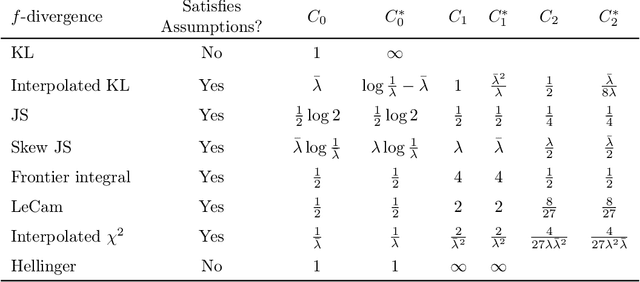
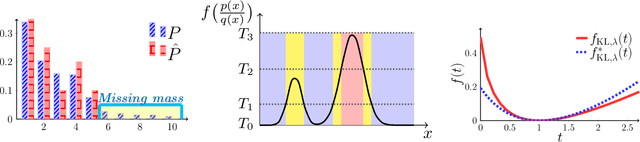
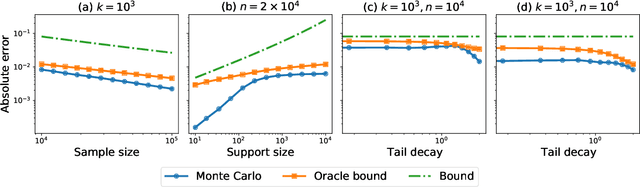
The spectacular success of deep generative models calls for quantitative tools to measure their statistical performance. Divergence frontiers have recently been proposed as an evaluation framework for generative models, due to their ability to measure the quality-diversity trade-off inherent to deep generative modeling. However, the statistical behavior of divergence frontiers estimated from data remains unknown to this day. In this paper, we establish non-asymptotic bounds on the sample complexity of the plug-in estimator of divergence frontiers. Along the way, we introduce a novel integral summary of divergence frontiers. We derive the corresponding non-asymptotic bounds and discuss the choice of the quantization level by balancing the two types of approximation errors arisen from its computation. We also augment the divergence frontier framework by investigating the statistical performance of smoothed distribution estimators such as the Good-Turing estimator. We illustrate the theoretical results with numerical examples from natural language processing and computer vision.
LLC: Accurate, Multi-purpose Learnt Low-dimensional Binary Codes
Jun 02, 2021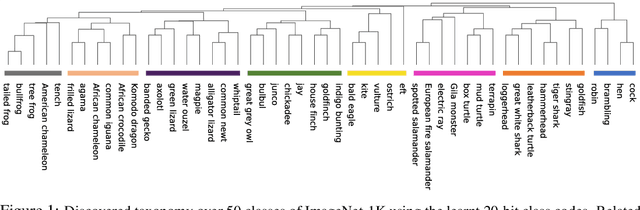

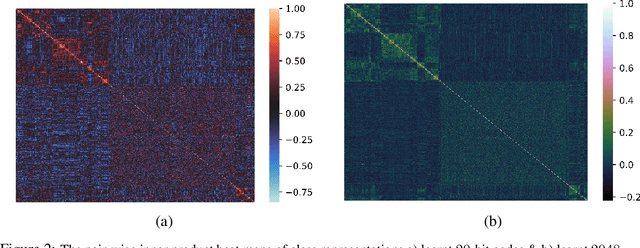

Learning binary representations of instances and classes is a classical problem with several high potential applications. In modern settings, the compression of high-dimensional neural representations to low-dimensional binary codes is a challenging task and often require large bit-codes to be accurate. In this work, we propose a novel method for Learning Low-dimensional binary Codes (LLC) for instances as well as classes. Our method does not require any side-information, like annotated attributes or label meta-data, and learns extremely low-dimensional binary codes (~20 bits for ImageNet-1K). The learnt codes are super-efficient while still ensuring nearly optimal classification accuracy for ResNet50 on ImageNet-1K. We demonstrate that the learnt codes capture intrinsically important features in the data, by discovering an intuitive taxonomy over classes. We further quantitatively measure the quality of our codes by applying it to the efficient image retrieval as well as out-of-distribution (OOD) detection problems. For ImageNet-100 retrieval problem, our learnt binary codes outperform 16 bit HashNet using only 10 bits and also are as accurate as 10 dimensional real representations. Finally, our learnt binary codes can perform OOD detection, out-of-the-box, as accurately as a baseline that needs ~3000 samples to tune its threshold, while we require none. Code and pre-trained models are available at https://github.com/RAIVNLab/LLC.
MAUVE: Human-Machine Divergence Curves for Evaluating Open-Ended Text Generation
Feb 02, 2021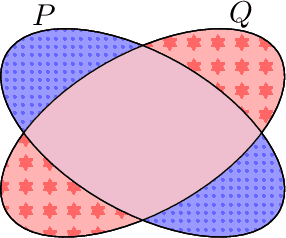
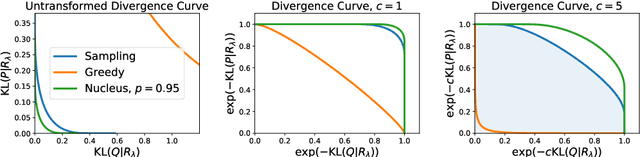
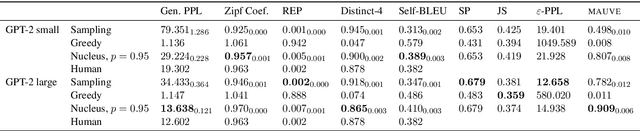
Despite major advances in open-ended text generation, there has been limited progress in designing evaluation metrics for this task. We propose MAUVE -- a metric for open-ended text generation, which directly compares the distribution of machine-generated text to that of human language. MAUVE measures the mean area under the divergence curve for the two distributions, exploring the trade-off between two types of errors: those arising from parts of the human distribution that the model distribution approximates well, and those it does not. We present experiments across two open-ended generation tasks in the web text domain and the story domain, and a variety of decoding algorithms and model sizes. Our results show that evaluation under MAUVE indeed reflects the more natural behavior with respect to model size, compared to prior metrics. MAUVE's ordering of the decoding algorithms also agrees with that of generation perplexity, the most widely used metric in open-ended text generation; however, MAUVE presents a more principled evaluation metric for the task as it considers both model and human text.
Device Heterogeneity in Federated Learning: A Superquantile Approach
Feb 25, 2020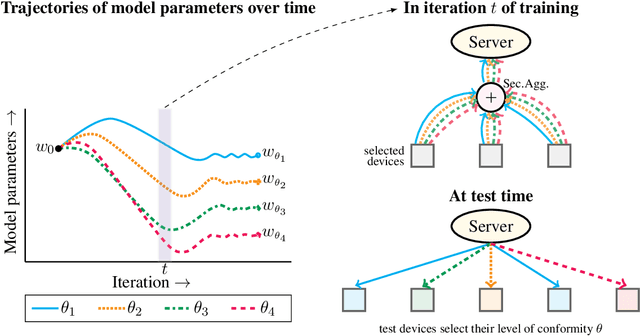

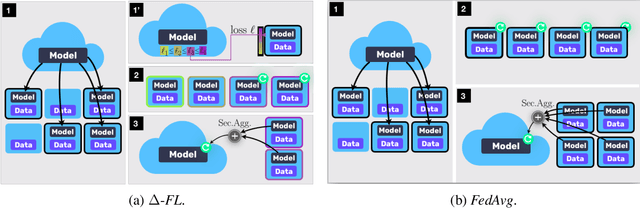

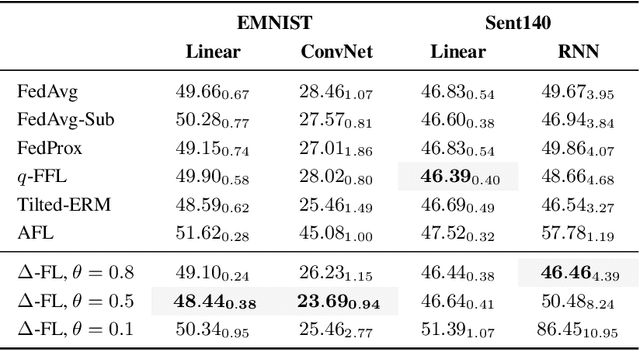
We propose a federated learning framework to handle heterogeneous client devices which do not conform to the population data distribution. The approach hinges upon a parameterized superquantile-based objective, where the parameter ranges over levels of conformity. We present an optimization algorithm and establish its convergence to a stationary point. We show how to practically implement it using secure aggregation by interleaving iterations of the usual federated averaging method with device filtering. We conclude with numerical experiments on neural networks as well as linear models on tasks from computer vision and natural language processing.
Robust Aggregation for Federated Learning
Dec 31, 2019

We present a robust aggregation approach to make federated learning robust to settings when a fraction of the devices may be sending corrupted updates to the server. The proposed approach relies on a robust secure aggregation oracle based on the geometric median, which returns a robust aggregate using a constant number of calls to a regular non-robust secure average oracle. The robust aggregation oracle is privacy-preserving, similar to the secure average oracle it builds upon. We provide experimental results of the proposed approach with linear models and deep networks for two tasks in computer vision and natural language processing. The robust aggregation approach is agnostic to the level of corruption; it outperforms the classical aggregation approach in terms of robustness when the level of corruption is high, while being competitive in the regime of low corruption.