 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Content Time-Series Popularity Prediction with Multiple-Model Transformers in MEC Networks
Oct 12, 2022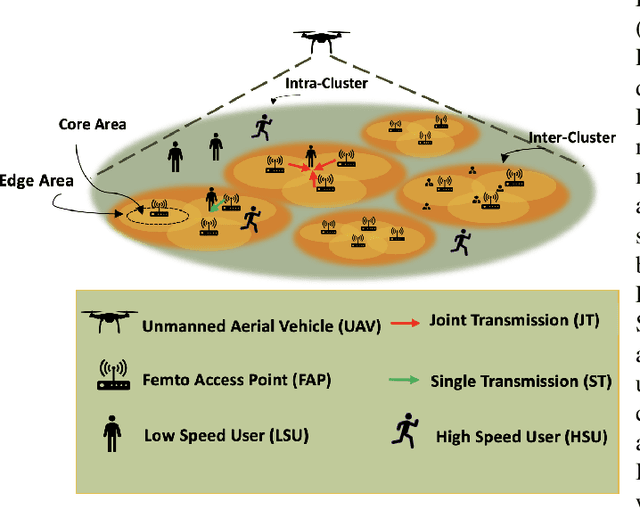
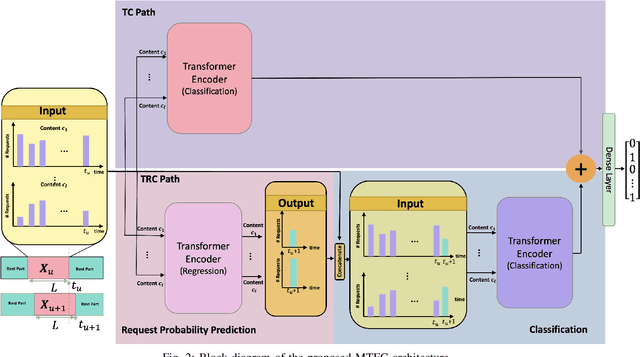
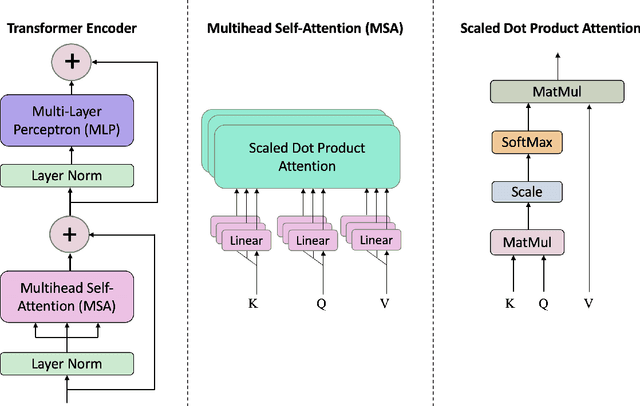
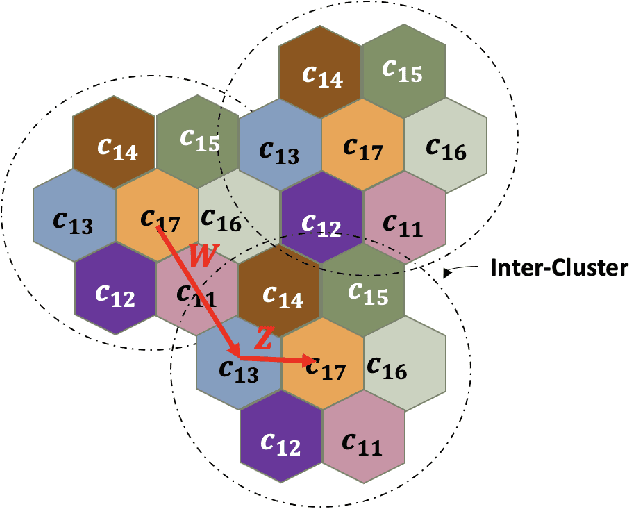
Coded/uncoded content placement in Mobile Edge Caching (MEC) has evolved as an efficient solution to meet the significant growth of global mobile data traffic by boosting the content diversity in the storage of caching nodes. To meet the dynamic nature of the historical request pattern of multimedia contents, the main focus of recent researches has been shifted to develop data-driven and real-time caching schemes. In this regard and with the assumption that users' preferences remain unchanged over a short horizon, the Top-K popular contents are identified as the output of the learning model. Most existing datadriven popularity prediction models, however, are not suitable for the coded/uncoded content placement frameworks. On the one hand, in coded/uncoded content placement, in addition to classifying contents into two groups, i.e., popular and nonpopular, the probability of content request is required to identify which content should be stored partially/completely, where this information is not provided by existing data-driven popularity prediction models. On the other hand, the assumption that users' preferences remain unchanged over a short horizon only works for content with a smooth request pattern. To tackle these challenges, we develop a Multiple-model (hybrid) Transformer-based Edge Caching (MTEC) framework with higher generalization ability, suitable for various types of content with different time-varying behavior, that can be adapted with coded/uncoded content placement frameworks. Simulation results corroborate the effectiveness of the proposed MTEC caching framework in comparison to its counterparts in terms of the cache-hit ratio, classification accuracy, and the transferred byte volume.
Subclass Knowledge Distillation with Known Subclass Labels
Jul 17, 2022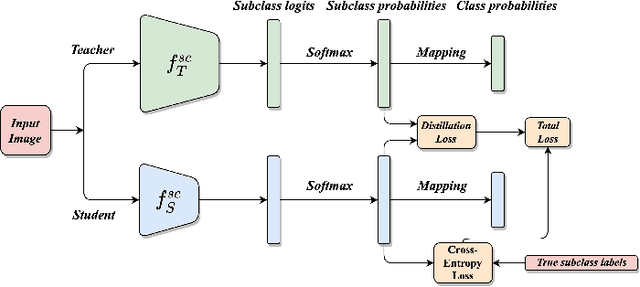
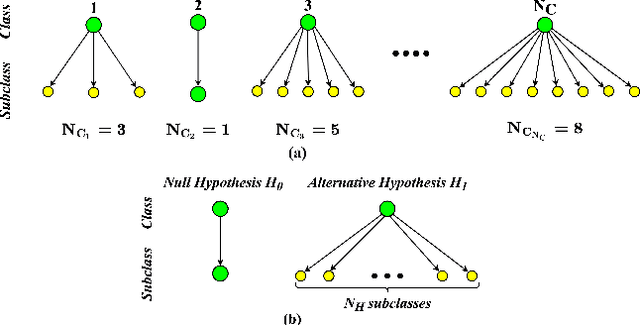
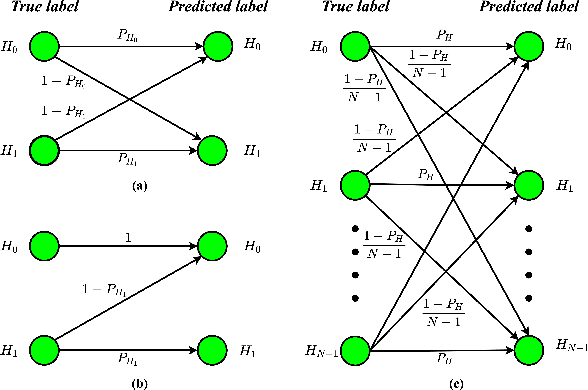
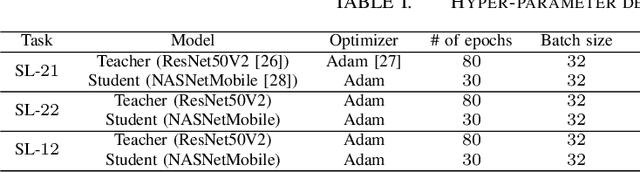
This work introduces a novel knowledge distillation framework for classification tasks where information on existing subclasses is available and taken into consideration. In classification tasks with a small number of classes or binary detection, the amount of information transferred from the teacher to the student is restricted, thus limiting the utility of knowledge distillation. Performance can be improved by leveraging information of possible subclasses within the classes. To that end, we propose the so-called Subclass Knowledge Distillation (SKD), a process of transferring the knowledge of predicted subclasses from a teacher to a smaller student. Meaningful information that is not in the teacher's class logits but exists in subclass logits (e.g., similarities within classes) will be conveyed to the student through the SKD, which will then boost the student's performance. Analytically, we measure how much extra information the teacher can provide the student via the SKD to demonstrate the efficacy of our work. The framework developed is evaluated in clinical application, namely colorectal polyp binary classification. It is a practical problem with two classes and a number of subclasses per class. In this application, clinician-provided annotations are used to define subclasses based on the annotation label's variability in a curriculum style of learning. A lightweight, low-complexity student trained with the SKD framework achieves an F1-score of 85.05%, an improvement of 1.47%, and a 2.10% gain over the student that is trained with and without conventional knowledge distillation, respectively. The 2.10% F1-score gap between students trained with and without the SKD can be explained by the extra subclass knowledge, i.e., the extra 0.4656 label bits per sample that the teacher can transfer in our experiment.
A Kernel Method to Nonlinear Location Estimation with RSS-based Fingerprint
Apr 07, 2022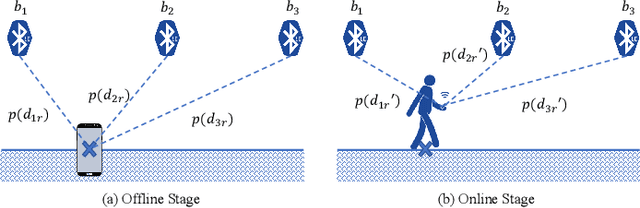

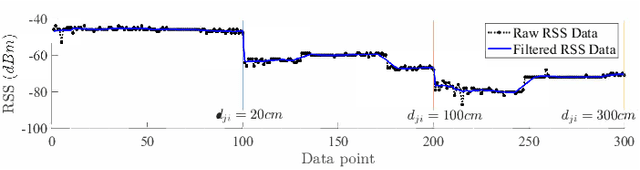
This paper presents a nonlinear location estimation to infer the position of a user holding a smartphone. We consider a large location with $M$ number of grid points, each grid point is labeled with a unique fingerprint consisting of the received signal strength (RSS) values measured from $N$ number of Bluetooth Low Energy (BLE) beacons. Given the fingerprint observed by the smartphone, the user's current location can be estimated by finding the top-k similar fingerprints from the list of fingerprints registered in the database. Besides the environmental factors, the dynamicity in holding the smartphone is another source to the variation in fingerprint measurements, yet there are not many studies addressing the fingerprint variability due to dynamic smartphone positions held by human hands during online detection. To this end, we propose a nonlinear location estimation using the kernel method. Specifically, our proposed method comprises of two steps: 1) a beacon selection strategy to select a subset of beacons that is insensitive to the subtle change of holding positions, and 2) a kernel method to compute the similarity between this subset of observed signals and all the fingerprints registered in the database. The experimental results based on large-scale data collected in a complex building indicate a substantial performance gain of our proposed approach in comparison to state-of-the-art methods. The dataset consisting of the signal information collected from the beacons is available online.
AKF-SR: Adaptive Kalman Filtering-based Successor Representation
Mar 31, 2022

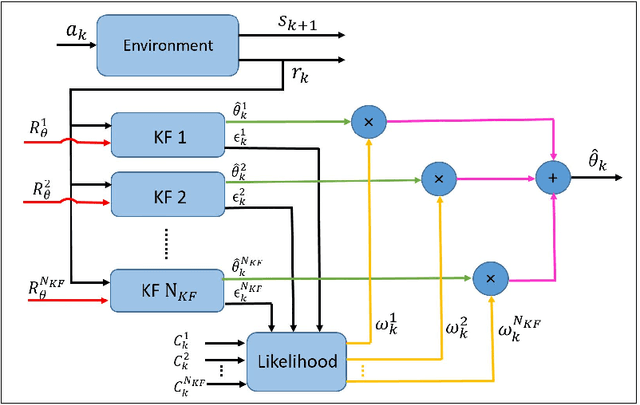
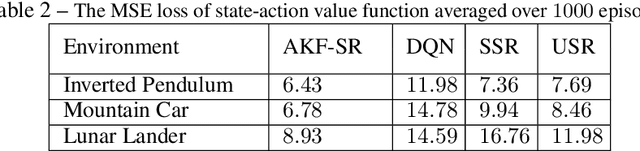
Recent studies in neuroscience suggest that Successor Representation (SR)-based models provide adaptation to changes in the goal locations or reward function faster than model-free algorithms, together with lower computational cost compared to that of model-based algorithms. However, it is not known how such representation might help animals to manage uncertainty in their decision-making. Existing methods for SR learning do not capture uncertainty about the estimated SR. In order to address this issue, the paper presents a Kalman filter-based SR framework, referred to as Adaptive Kalman Filtering-based Successor Representation (AKF-SR). First, Kalman temporal difference approach, which is a combination of the Kalman filter and the temporal difference method, is used within the AKF-SR framework to cast the SR learning procedure into a filtering problem to benefit from the uncertainty estimation of the SR, and also decreases in memory requirement and sensitivity to model's parameters in comparison to deep neural network-based algorithms. An adaptive Kalman filtering approach is then applied within the proposed AKF-SR framework in order to tune the measurement noise covariance and measurement mapping function of Kalman filter as the most important parameters affecting the filter's performance. Moreover, an active learning method that exploits the estimated uncertainty of the SR to form the behaviour policy leading to more visits to less certain values is proposed to improve the overall performance of an agent in terms of received rewards while interacting with its environment.
Exploiting Explainable Metrics for Augmented SGD
Mar 31, 2022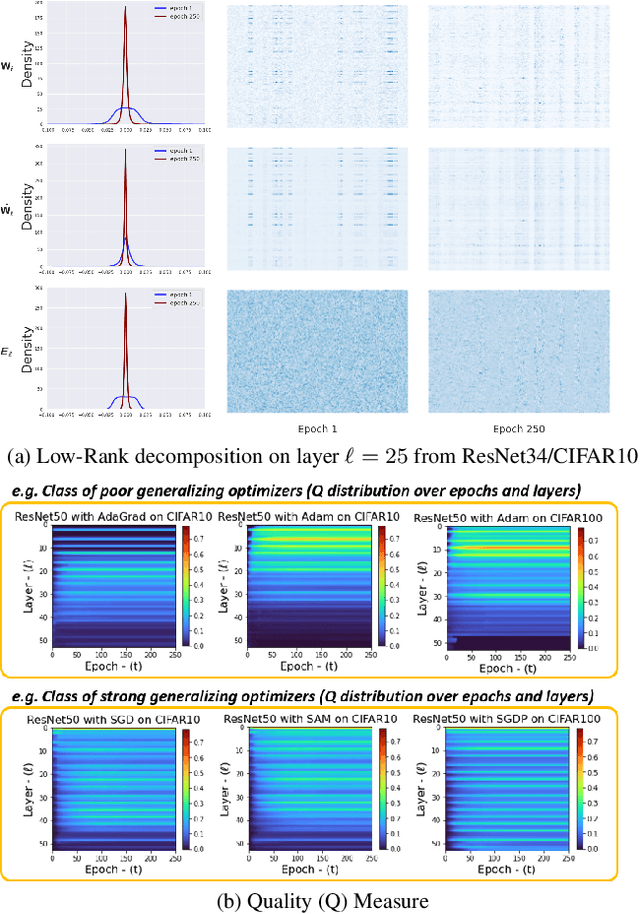
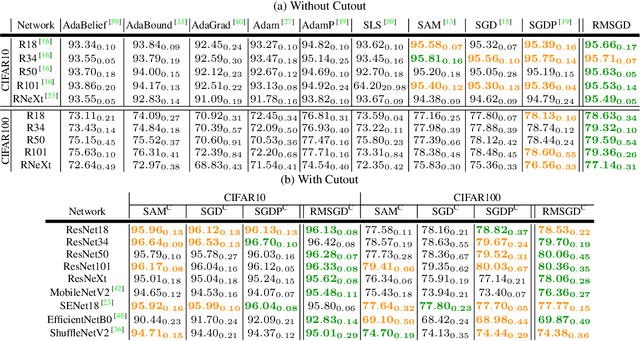
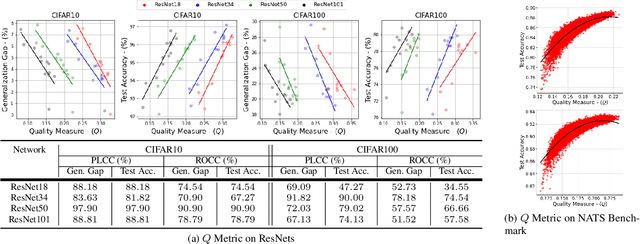
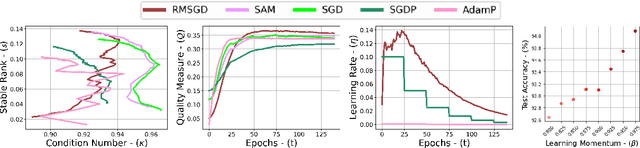
Explaining the generalization characteristics of deep learning is an emerging topic in advanced machine learning. There are several unanswered questions about how learning under stochastic optimization really works and why certain strategies are better than others. In this paper, we address the following question: \textit{can we probe intermediate layers of a deep neural network to identify and quantify the learning quality of each layer?} With this question in mind, we propose new explainability metrics that measure the redundant information in a network's layers using a low-rank factorization framework and quantify a complexity measure that is highly correlated with the generalization performance of a given optimizer, network, and dataset. We subsequently exploit these metrics to augment the Stochastic Gradient Descent (SGD) optimizer by adaptively adjusting the learning rate in each layer to improve in generalization performance. Our augmented SGD -- dubbed RMSGD -- introduces minimal computational overhead compared to SOTA methods and outperforms them by exhibiting strong generalization characteristics across application, architecture, and dataset.
HistoKT: Cross Knowledge Transfer in Computational Pathology
Jan 27, 2022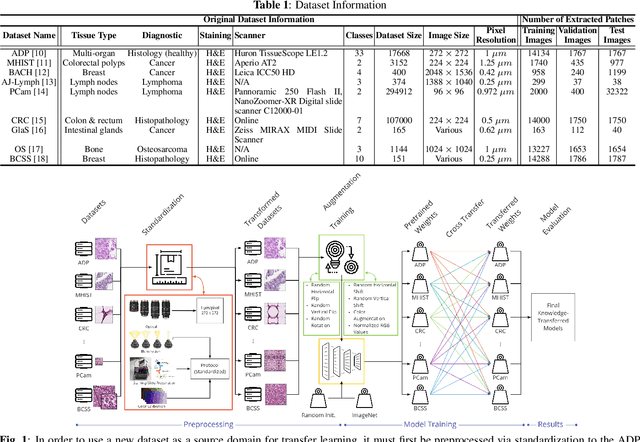
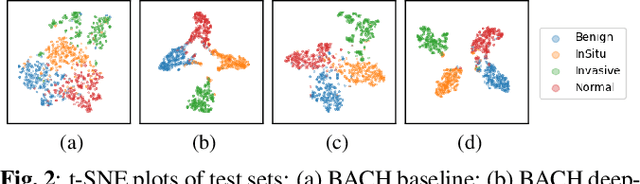
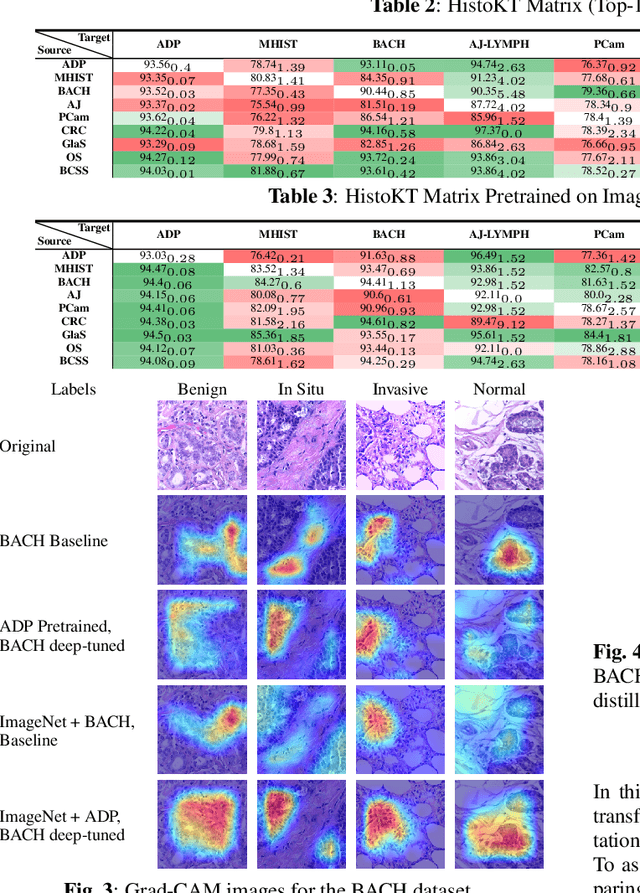
The lack of well-annotated datasets in computational pathology (CPath) obstructs the application of deep learning techniques for classifying medical images. %Since pathologist time is expensive, dataset curation is intrinsically difficult. Many CPath workflows involve transferring learned knowledge between various image domains through transfer learning. Currently, most transfer learning research follows a model-centric approach, tuning network parameters to improve transfer results over few datasets. In this paper, we take a data-centric approach to the transfer learning problem and examine the existence of generalizable knowledge between histopathological datasets. First, we create a standardization workflow for aggregating existing histopathological data. We then measure inter-domain knowledge by training ResNet18 models across multiple histopathological datasets, and cross-transferring between them to determine the quantity and quality of innate shared knowledge. Additionally, we use weight distillation to share knowledge between models without additional training. We find that hard to learn, multi-class datasets benefit most from pretraining, and a two stage learning framework incorporating a large source domain such as ImageNet allows for better utilization of smaller datasets. Furthermore, we find that weight distillation enables models trained on purely histopathological features to outperform models using external natural image data.
Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark
Jan 03, 2022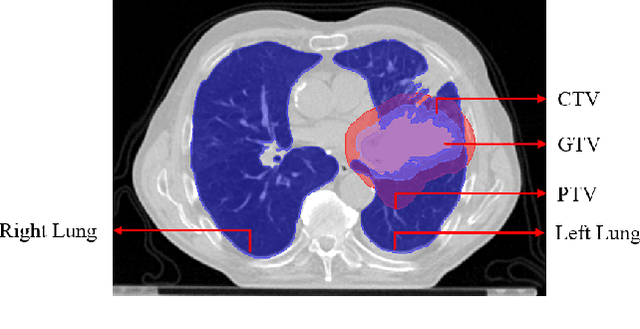
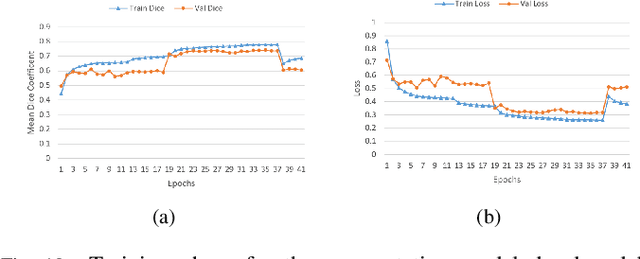
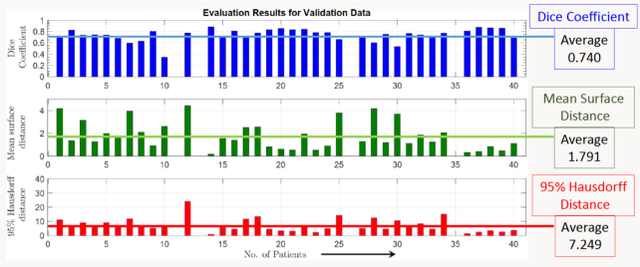
Lung cancer is one of the deadliest cancers, and in part its effective diagnosis and treatment depend on the accurate delineation of the tumor. Human-centered segmentation, which is currently the most common approach, is subject to inter-observer variability, and is also time-consuming, considering the fact that only experts are capable of providing annotations. Automatic and semi-automatic tumor segmentation methods have recently shown promising results. However, as different researchers have validated their algorithms using various datasets and performance metrics, reliably evaluating these methods is still an open challenge. The goal of the Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark created through 2018 IEEE Video and Image Processing (VIP) Cup competition, is to provide a unique dataset and pre-defined metrics, so that different researchers can develop and evaluate their methods in a unified fashion. The 2018 VIP Cup started with a global engagement from 42 countries to access the competition data. At the registration stage, there were 129 members clustered into 28 teams from 10 countries, out of which 9 teams made it to the final stage and 6 teams successfully completed all the required tasks. In a nutshell, all the algorithms proposed during the competition, are based on deep learning models combined with a false positive reduction technique. Methods developed by the three finalists show promising results in tumor segmentation, however, more effort should be put into reducing the false positive rate. This competition manuscript presents an overview of the VIP-Cup challenge, along with the proposed algorithms and results.
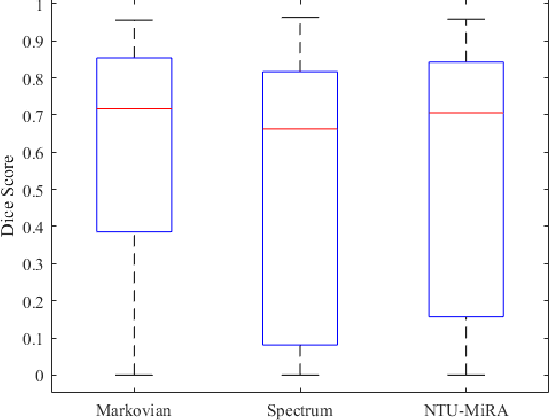
Multi-Agent Reinforcement Learning via Adaptive Kalman Temporal Difference and Successor Representation
Dec 30, 2021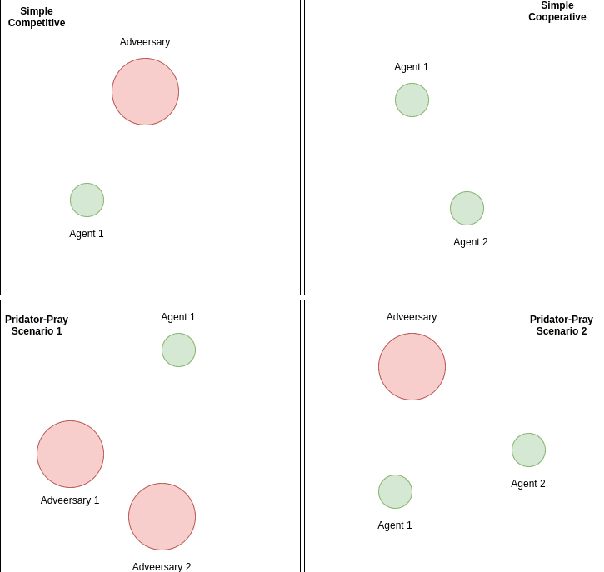
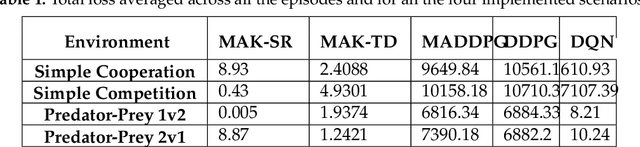
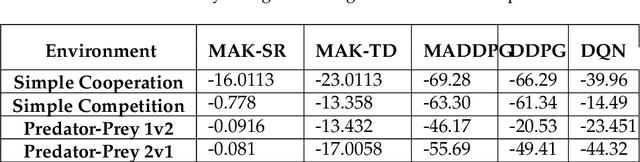
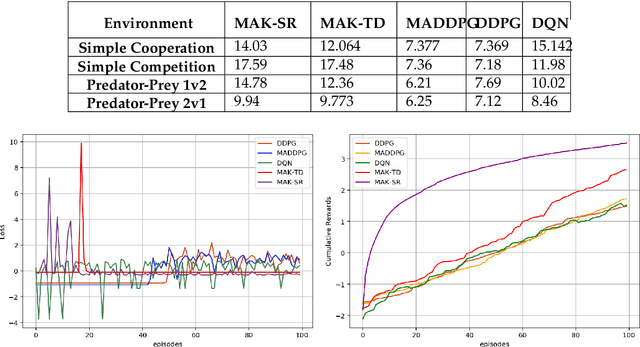
Distributed Multi-Agent Reinforcement Learning (MARL) algorithms has attracted a surge of interest lately mainly due to the recent advancements of Deep Neural Networks (DNNs). Conventional Model-Based (MB) or Model-Free (MF) RL algorithms are not directly applicable to the MARL problems due to utilization of a fixed reward model for learning the underlying value function. While DNN-based solutions perform utterly well when a single agent is involved, such methods fail to fully generalize to the complexities of MARL problems. In other words, although recently developed approaches based on DNNs for multi-agent environments have achieved superior performance, they are still prone to overfiting, high sensitivity to parameter selection, and sample inefficiency. The paper proposes the Multi-Agent Adaptive Kalman Temporal Difference (MAK-TD) framework and its Successor Representation-based variant, referred to as the MAK-SR. Intuitively speaking, the main objective is to capitalize on unique characteristics of Kalman Filtering (KF) such as uncertainty modeling and online second order learning. The proposed MAK-TD/SR frameworks consider the continuous nature of the action-space that is associated with high dimensional multi-agent environments and exploit Kalman Temporal Difference (KTD) to address the parameter uncertainty. By leveraging the KTD framework, SR learning procedure is modeled into a filtering problem, where Radial Basis Function (RBF) estimators are used to encode the continuous space into feature vectors. On the other hand, for learning localized reward functions, we resort to Multiple Model Adaptive Estimation (MMAE), to deal with the lack of prior knowledge on the observation noise covariance and observation mapping function. The proposed MAK-TD/SR frameworks are evaluated via several experiments, which are implemented through the OpenAI Gym MARL benchmarks.
Towards Robust and Automatic Hyper-Parameter Tunning
Dec 12, 2021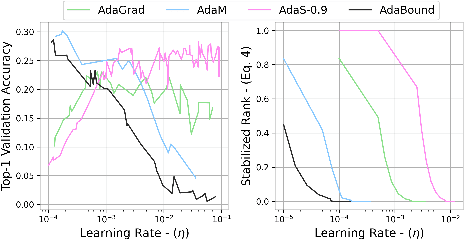
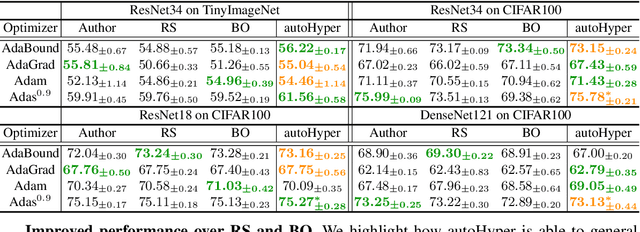
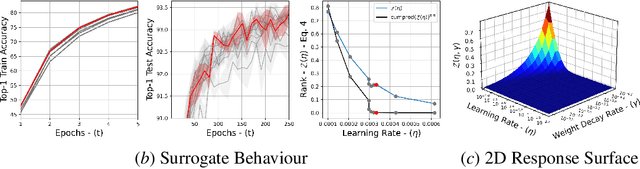

The task of hyper-parameter optimization (HPO) is burdened with heavy computational costs due to the intractability of optimizing both a model's weights and its hyper-parameters simultaneously. In this work, we introduce a new class of HPO method and explore how the low-rank factorization of the convolutional weights of intermediate layers of a convolutional neural network can be used to define an analytical response surface for optimizing hyper-parameters, using only training data. We quantify how this surface behaves as a surrogate to model performance and can be solved using a trust-region search algorithm, which we call autoHyper. The algorithm outperforms state-of-the-art such as Bayesian Optimization and generalizes across model, optimizer, and dataset selection. Our code can be found at \url{https://github.com/MathieuTuli/autoHyper}.
TEDGE-Caching: Transformer-based Edge Caching Towards 6G Networks
Dec 01, 2021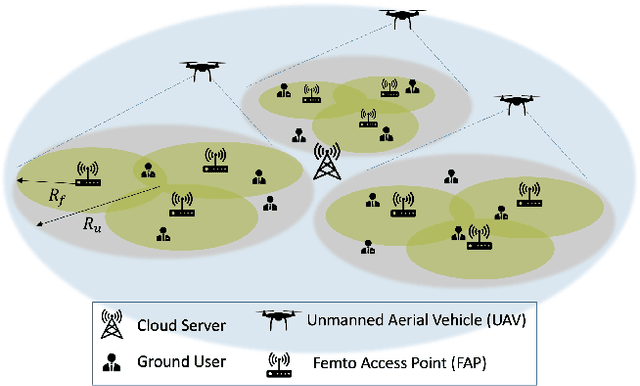
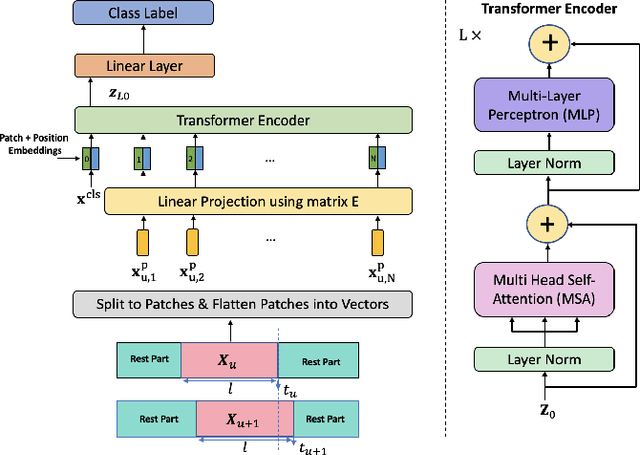
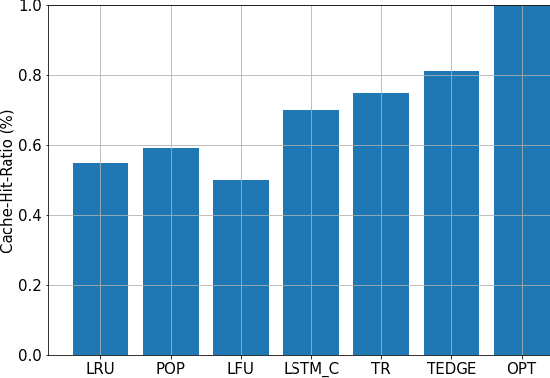
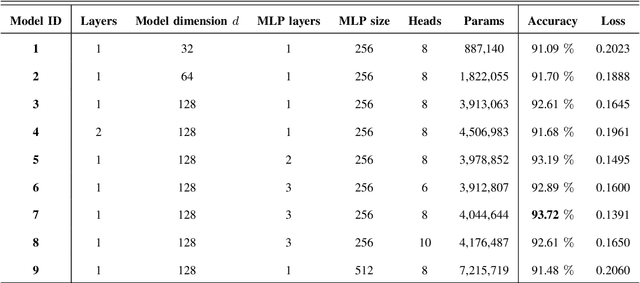
As a consequence of the COVID-19 pandemic, the demand for telecommunication for remote learning/working and telemedicine has significantly increased. Mobile Edge Caching (MEC) in the 6G networks has been evolved as an efficient solution to meet the phenomenal growth of the global mobile data traffic by bringing multimedia content closer to the users. Although massive connectivity enabled by MEC networks will significantly increase the quality of communications, there are several key challenges ahead. The limited storage of edge nodes, the large size of multimedia content, and the time-variant users' preferences make it critical to efficiently and dynamically predict the popularity of content to store the most upcoming requested ones before being requested. Recent advancements in Deep Neural Networks (DNNs) have drawn much research attention to predict the content popularity in proactive caching schemes. Existing DNN models in this context, however, suffer from longterm dependencies, computational complexity, and unsuitability for parallel computing. To tackle these challenges, we propose an edge caching framework incorporated with the attention-based Vision Transformer (ViT) neural network, referred to as the Transformer-based Edge (TEDGE) caching, which to the best of our knowledge, is being studied for the first time. Moreover, the TEDGE caching framework requires no data pre-processing and additional contextual information. Simulation results corroborate the effectiveness of the proposed TEDGE caching framework in comparison to its counterparts.