 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Should the System Do Next?: Operative Action Captioning for Estimating System Actions
Oct 06, 2022
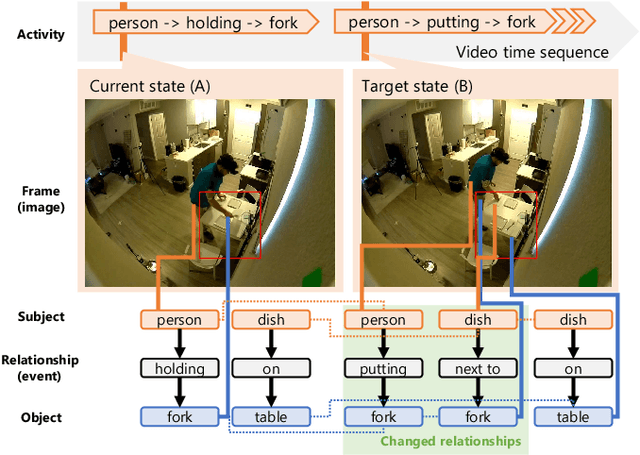
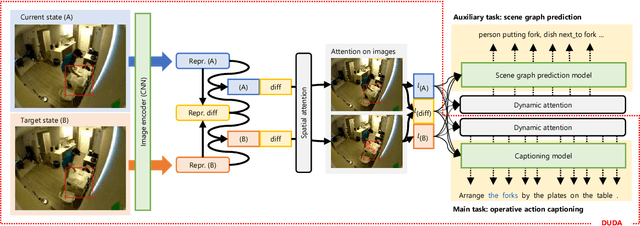
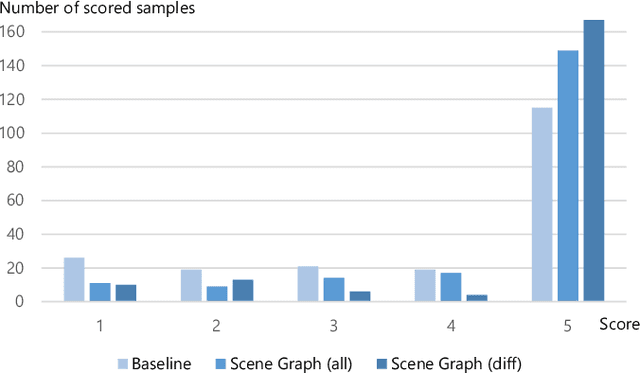
Such human-assisting systems as robots need to correctly understand the surrounding situation based on observations and output the required support actions for humans. Language is one of the important channels to communicate with humans, and the robots are required to have the ability to express their understanding and action planning results. In this study, we propose a new task of operative action captioning that estimates and verbalizes the actions to be taken by the system in a human-assisting domain. We constructed a system that outputs a verbal description of a possible operative action that changes the current state to the given target state. We collected a dataset consisting of two images as observations, which express the current state and the state changed by actions, and a caption that describes the actions that change the current state to the target state, by crowdsourcing in daily life situations. Then we constructed a system that estimates operative action by a caption. Since the operative action's caption is expected to contain some state-changing actions, we use scene-graph prediction as an auxiliary task because the events written in the scene graphs correspond to the state changes. Experimental results showed that our system successfully described the operative actions that should be conducted between the current and target states. The auxiliary tasks that predict the scene graphs improved the quality of the estimation results.
ARTA: Collection and Classification of Ambiguous Requests and Thoughtful Actions
Jun 15, 2021


Human-assisting systems such as dialogue systems must take thoughtful, appropriate actions not only for clear and unambiguous user requests, but also for ambiguous user requests, even if the users themselves are not aware of their potential requirements. To construct such a dialogue agent, we collected a corpus and developed a model that classifies ambiguous user requests into corresponding system actions. In order to collect a high-quality corpus, we asked workers to input antecedent user requests whose pre-defined actions could be regarded as thoughtful. Although multiple actions could be identified as thoughtful for a single user request, annotating all combinations of user requests and system actions is impractical. For this reason, we fully annotated only the test data and left the annotation of the training data incomplete. In order to train the classification model on such training data, we applied the positive/unlabeled (PU) learning method, which assumes that only a part of the data is labeled with positive examples. The experimental results show that the PU learning method achieved better performance than the general positive/negative (PN) learning method to classify thoughtful actions given an ambiguous user request.
Reflection-based Word Attribute Transfer
Jul 07, 2020Word embeddings, which often represent such analogic relations as king - man + woman = queen, can be used to change a word's attribute, including its gender. For transferring king into queen in this analogy-based manner, we subtract a difference vector man - woman based on the knowledge that king is male. However, developing such knowledge is very costly for words and attributes. In this work, we propose a novel method for word attribute transfer based on reflection mappings without such an analogy operation. Experimental results show that our proposed method can transfer the word attributes of the given words without changing the words that do not have the target attributes.
Caption Generation of Robot Behaviors based on Unsupervised Learning of Action Segments
Mar 23, 2020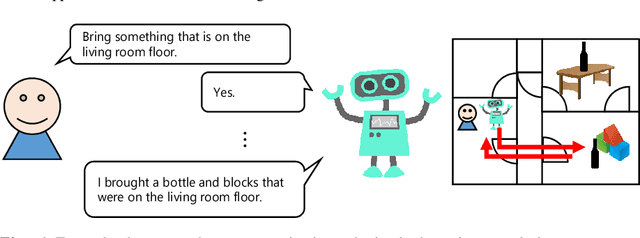
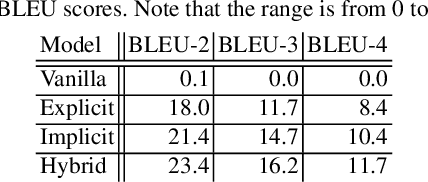

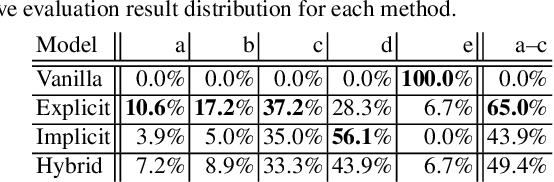
Bridging robot action sequences and their natural language captions is an important task to increase explainability of human assisting robots in their recently evolving field. In this paper, we propose a system for generating natural language captions that describe behaviors of human assisting robots. The system describes robot actions by using robot observations; histories from actuator systems and cameras, toward end-to-end bridging between robot actions and natural language captions. Two reasons make it challenging to apply existing sequence-to-sequence models to this mapping: 1) it is hard to prepare a large-scale dataset for any kind of robots and their environment, and 2) there is a gap between the number of samples obtained from robot action observations and generated word sequences of captions. We introduced unsupervised segmentation based on K-means clustering to unify typical robot observation patterns into a class. This method makes it possible for the network to learn the relationship from a small amount of data. Moreover, we utilized a chunking method based on byte-pair encoding (BPE) to fill in the gap between the number of samples of robot action observations and words in a caption. We also applied an attention mechanism to the segmentation task. Experimental results show that the proposed model based on unsupervised learning can generate better descriptions than other methods. We also show that the attention mechanism did not work well in our low-resource setting.
Conversational Response Re-ranking Based on Event Causality and Role Factored Tensor Event Embedding
Jun 24, 2019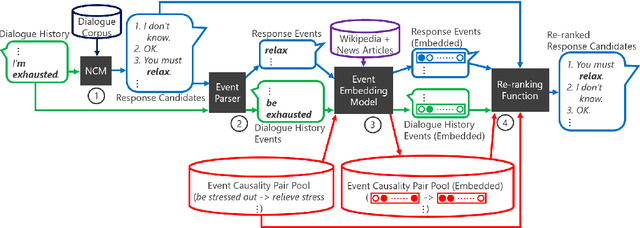

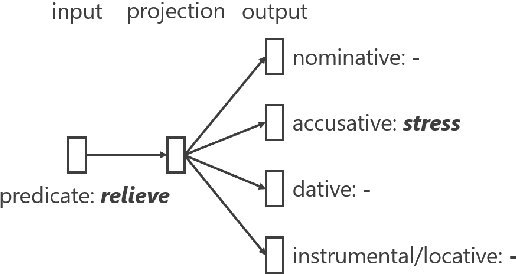
We propose a novel method for selecting coherent and diverse responses for a given dialogue context. The proposed method re-ranks response candidates generated from conversational models by using event causality relations between events in a dialogue history and response candidates (e.g., ``be stressed out'' precedes ``relieve stress''). We use distributed event representation based on the Role Factored Tensor Model for a robust matching of event causality relations due to limited event causality knowledge of the system. Experimental results showed that the proposed method improved coherency and dialogue continuity of system responses.
An Incremental Turn-Taking Model For Task-Oriented Dialog Systems
May 28, 2019
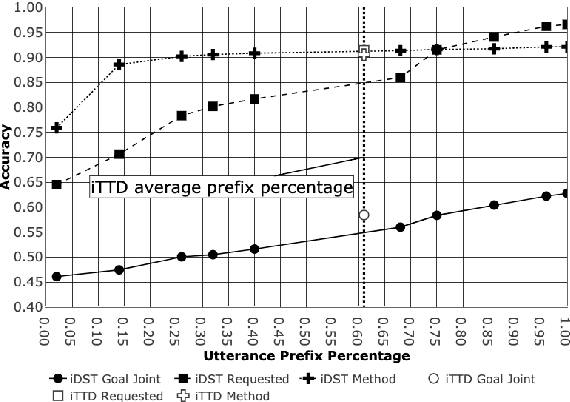

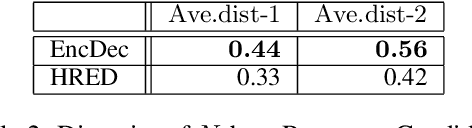
In a human-machine dialog scenario, deciding the appropriate time for the machine to take the turn is an open research problem. In contrast, humans engaged in conversations are able to timely decide when to interrupt the speaker for competitive or non-competitive reasons. In state-of-the-art turn-by-turn dialog systems the decision on the next dialog action is taken at the end of the utterance. In this paper, we propose a token-by-token prediction of the dialog state from incremental transcriptions of the user utterance. To identify the point of maximal understanding in an ongoing utterance, we a) implement an incremental Dialog State Tracker which is updated on a token basis (iDST) b) re-label the Dialog State Tracking Challenge 2 (DSTC2) dataset and c) adapt it to the incremental turn-taking experimental scenario. The re-labeling consists of assigning a binary value to each token in the user utterance that allows to identify the appropriate point for taking the turn. Finally, we implement an incremental Turn Taking Decider (iTTD) that is trained on these new labels for the turn-taking decision. We show that the proposed model can achieve a better performance compared to a deterministic handcrafted turn-taking algorithm.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
Optimization of Information-Seeking Dialogue Strategy for Argumentation-Based Dialogue System
Nov 26, 2018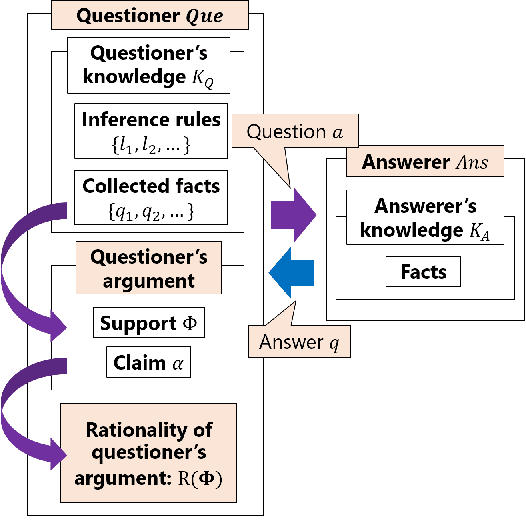
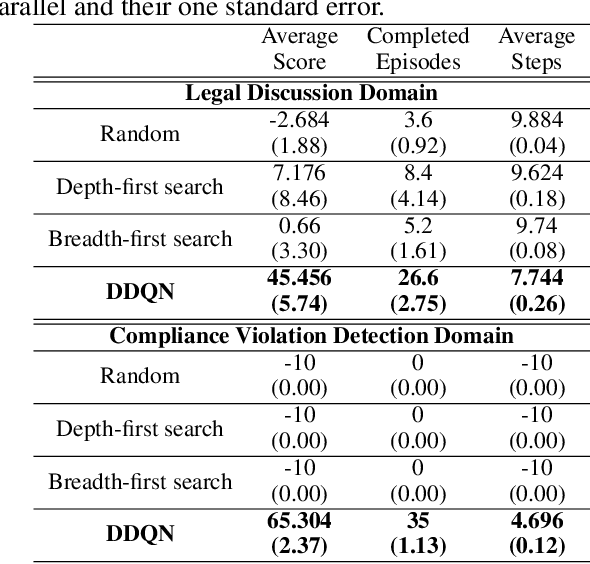
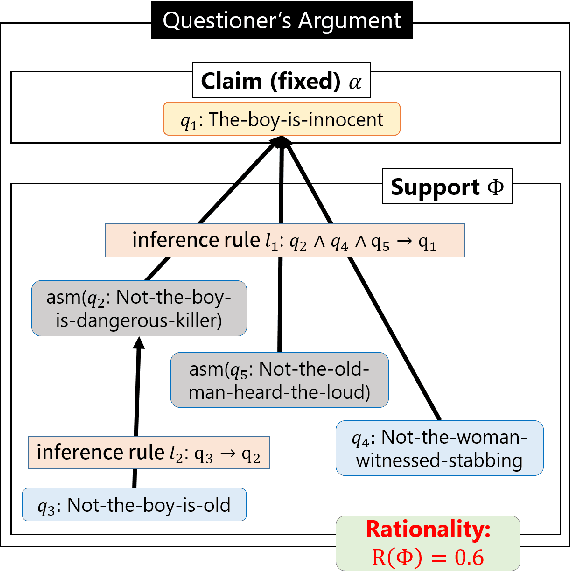

Argumentation-based dialogue systems, which can handle and exchange arguments through dialogue, have been widely researched. It is required that these systems have sufficient supporting information to argue their claims rationally; however, the systems often do not have enough of such information in realistic situations. One way to fill in the gap is acquiring such missing information from dialogue partners (information-seeking dialogue). Existing information-seeking dialogue systems are based on handcrafted dialogue strategies that exhaustively examine missing information. However, the proposed strategies are not specialized in collecting information for constructing rational arguments. Moreover, the number of system's inquiry candidates grows in accordance with the size of the argument set that the system deal with. In this paper, we formalize the process of information-seeking dialogue as Markov decision processes (MDPs) and apply deep reinforcement learning (DRL) for automatically optimizing a dialogue strategy. By utilizing DRL, our dialogue strategy can successfully minimize objective functions, the number of turns it takes for our system to collect necessary information in a dialogue. We conducted dialogue experiments using two datasets from different domains of argumentative dialogue. Experimental results show that the proposed formalization based on MDP works well, and the policy optimized by DRL outperformed existing heuristic dialogue strategies.
Another Diversity-Promoting Objective Function for Neural Dialogue Generation
Nov 21, 2018
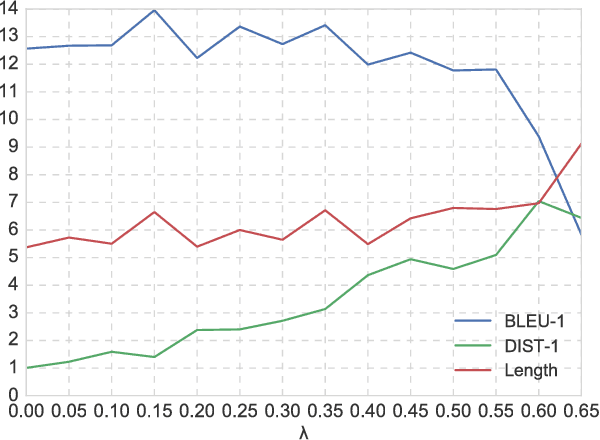
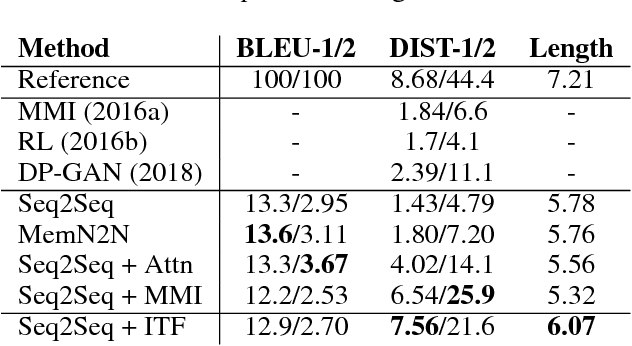
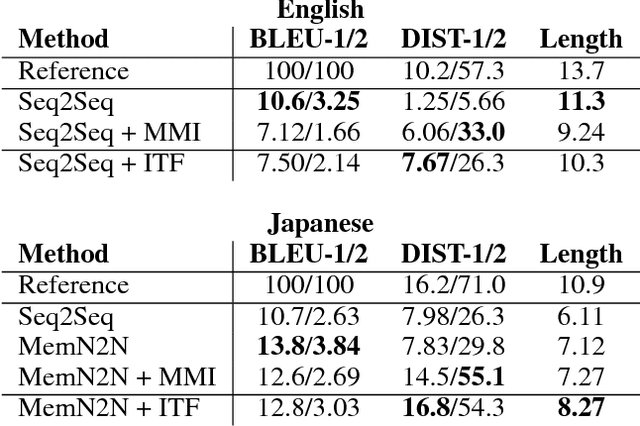
Although generation-based dialogue systems have been widely researched, the response generations by most existing systems have very low diversities. The most likely reason for this problem is Maximum Likelihood Estimation (MLE) with Softmax Cross-Entropy (SCE) loss. MLE trains models to generate the most frequent responses from enormous generation candidates, although in actual dialogues there are various responses based on the context. In this paper, we propose a new objective function called Inverse Token Frequency (ITF) loss, which individually scales smaller loss for frequent token classes and larger loss for rare token classes. This function encourages the model to generate rare tokens rather than frequent tokens. It does not complicate the model and its training is stable because we only replace the objective function. On the OpenSubtitles dialogue dataset, our loss model establishes a state-of-the-art DIST-1 of 7.56, which is the unigram diversity score, while maintaining a good BLEU-1 score. On a Japanese Twitter replies dataset, our loss model achieves a DIST-1 score comparable to the ground truth.
Interactive Image Manipulation with Natural Language Instruction Commands
Feb 23, 2018
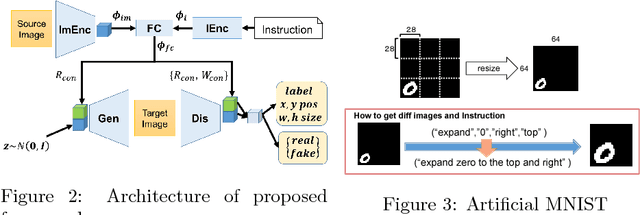

We propose an interactive image-manipulation system with natural language instruction, which can generate a target image from a source image and an instruction that describes the difference between the source and the target image. The system makes it possible to modify a generated image interactively and make natural language conditioned image generation more controllable. We construct a neural network that handles image vectors in latent space to transform the source vector to the target vector by using the vector of instruction. The experimental results indicate that the proposed framework successfully generates the target image by using a source image and an instruction on manipulation in our dataset.