 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluent: An AI Augmented Writing Tool for People who Stutter
Aug 23, 2021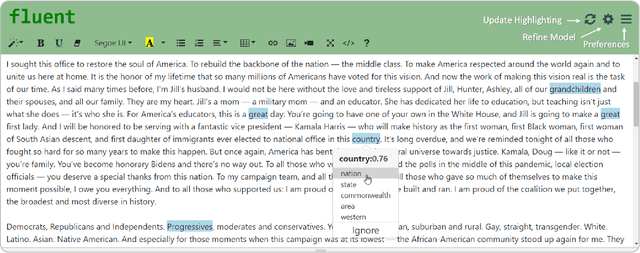
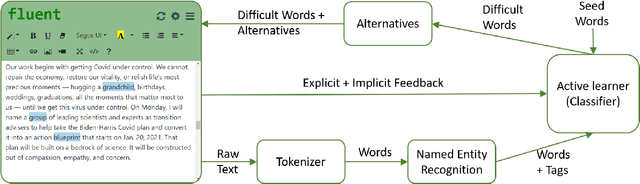
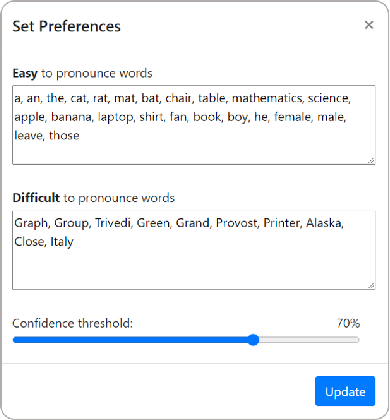
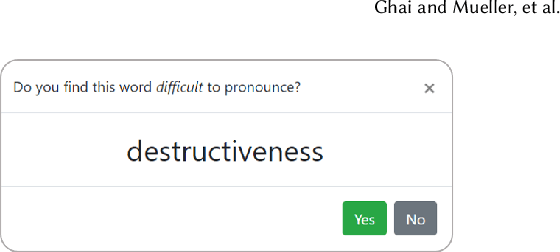
Stuttering is a speech disorder which impacts the personal and professional lives of millions of people worldwide. To save themselves from stigma and discrimination, people who stutter (PWS) may adopt different strategies to conceal their stuttering. One of the common strategies is word substitution where an individual avoids saying a word they might stutter on and use an alternative instead. This process itself can cause stress and add more burden. In this work, we present Fluent, an AI augmented writing tool which assists PWS in writing scripts which they can speak more fluently. Fluent embodies a novel active learning based method of identifying words an individual might struggle pronouncing. Such words are highlighted in the interface. On hovering over any such word, Fluent presents a set of alternative words which have similar meaning but are easier to speak. The user is free to accept or ignore these suggestions. Based on such user interaction (feedback), Fluent continuously evolves its classifier to better suit the personalized needs of each user. We evaluated our tool by measuring its ability to identify difficult words for 10 simulated users. We found that our tool can identify difficult words with a mean accuracy of over 80% in under 20 interactions and it keeps improving with more feedback. Our tool can be beneficial for certain important life situations like giving a talk, presentation, etc. The source code for this tool has been made publicly accessible at github.com/bhavyaghai/Fluent.
Transforming the Latent Space of StyleGAN for Real Face Editing
May 29, 2021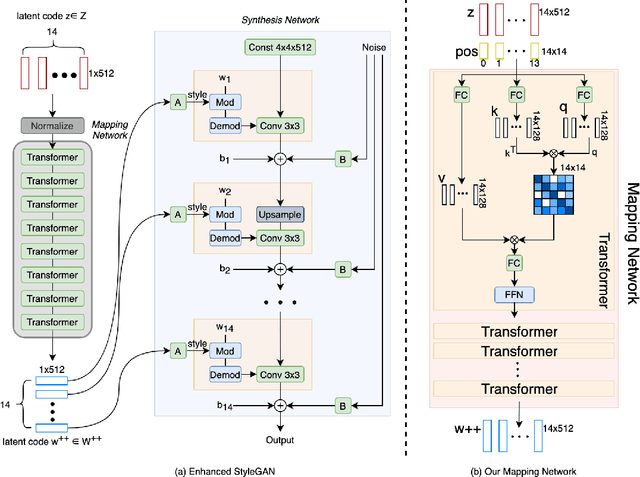

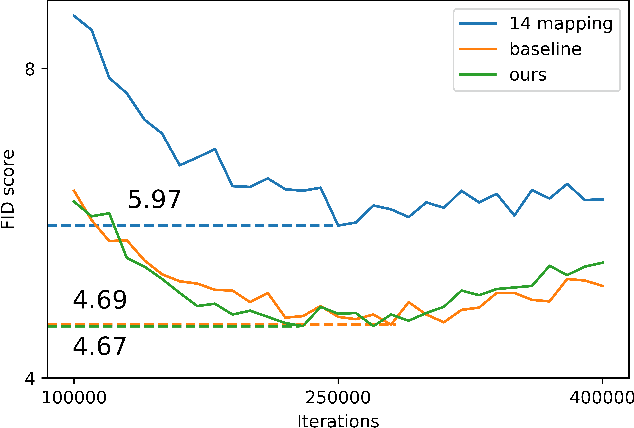

Despite recent advances in semantic manipulation using StyleGAN, semantic editing of real faces remains challenging. The gap between the $W$ space and the $W$+ space demands an undesirable trade-off between reconstruction quality and editing quality. To solve this problem, we propose to expand the latent space by replacing fully-connected layers in the StyleGAN's mapping network with attention-based transformers. This simple and effective technique integrates the aforementioned two spaces and transforms them into one new latent space called $W$++. Our modified StyleGAN maintains the state-of-the-art generation quality of the original StyleGAN with moderately better diversity. But more importantly, the proposed $W$++ space achieves superior performance in both reconstruction quality and editing quality. Despite these significant advantages, our $W$++ space supports existing inversion algorithms and editing methods with only negligible modifications thanks to its structural similarity with the $W/W$+ space. Extensive experiments on the FFHQ dataset prove that our proposed $W$++ space is evidently more preferable than the previous $W/W$+ space for real face editing. The code is publicly available for research purposes at https://github.com/AnonSubm2021/TransStyleGAN.
Image Synthesis for Data Augmentation in Medical CT using Deep Reinforcement Learning
Mar 22, 2021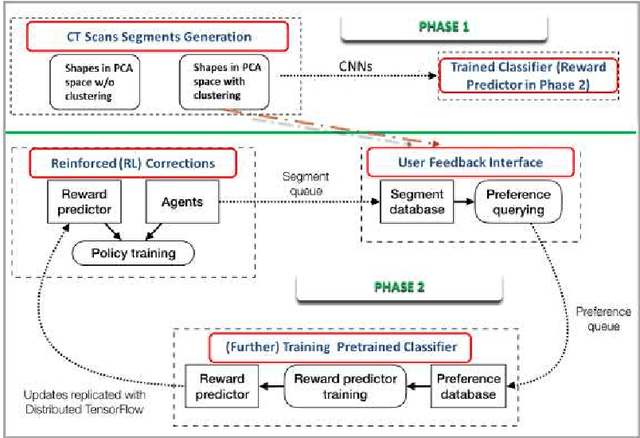
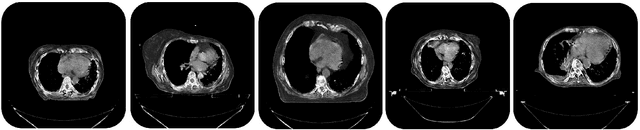
Deep learning has shown great promise for CT image reconstruction, in particular to enable low dose imaging and integrated diagnostics. These merits, however, stand at great odds with the low availability of diverse image data which are needed to train these neural networks. We propose to overcome this bottleneck via a deep reinforcement learning (DRL) approach that is integrated with a style-transfer (ST) methodology, where the DRL generates the anatomical shapes and the ST synthesizes the texture detail. We show that our method bears high promise for generating novel and anatomically accurate high resolution CT images at large and diverse quantities. Our approach is specifically designed to work with even small image datasets which is desirable given the often low amount of image data many researchers have available to them.
WordBias: An Interactive Visual Tool for Discovering Intersectional Biases Encoded in Word Embeddings
Mar 05, 2021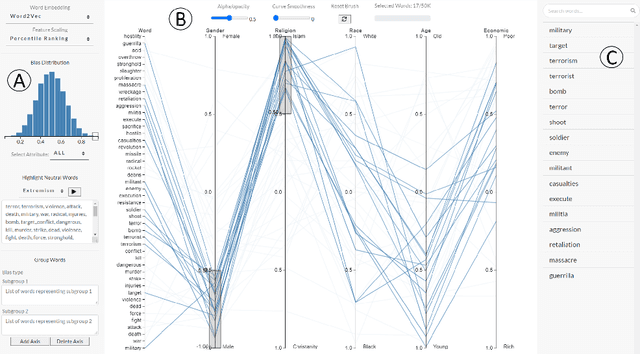
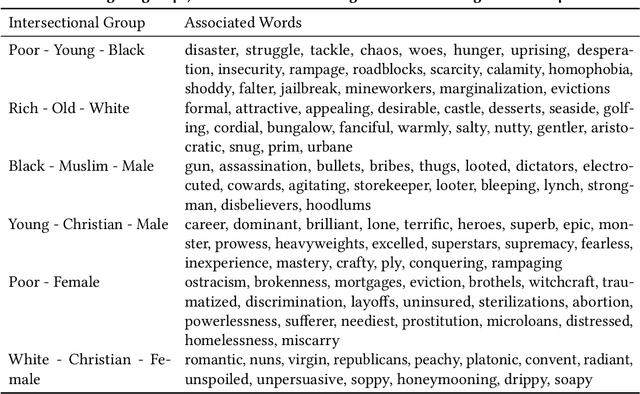
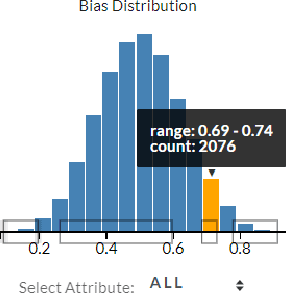
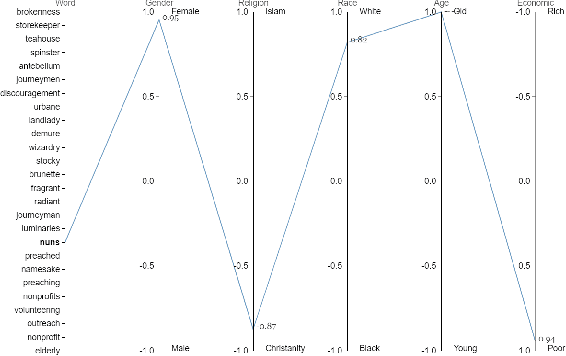
Intersectional bias is a bias caused by an overlap of multiple social factors like gender, sexuality, race, disability, religion, etc. A recent study has shown that word embedding models can be laden with biases against intersectional groups like African American females, etc. The first step towards tackling such intersectional biases is to identify them. However, discovering biases against different intersectional groups remains a challenging task. In this work, we present WordBias, an interactive visual tool designed to explore biases against intersectional groups encoded in static word embeddings. Given a pretrained static word embedding, WordBias computes the association of each word along different groups based on race, age, etc. and then visualizes them using a novel interactive interface. Using a case study, we demonstrate how WordBias can help uncover biases against intersectional groups like Black Muslim Males, Poor Females, etc. encoded in word embedding. In addition, we also evaluate our tool using qualitative feedback from expert interviews. The source code for this tool can be publicly accessed for reproducibility at github.com/bhavyaghai/WordBias.
Noise Entangled GAN For Low-Dose CT Simulation
Feb 18, 2021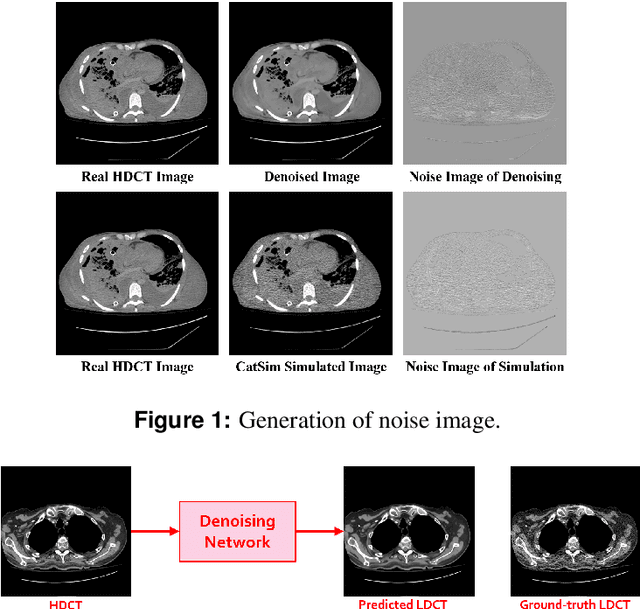
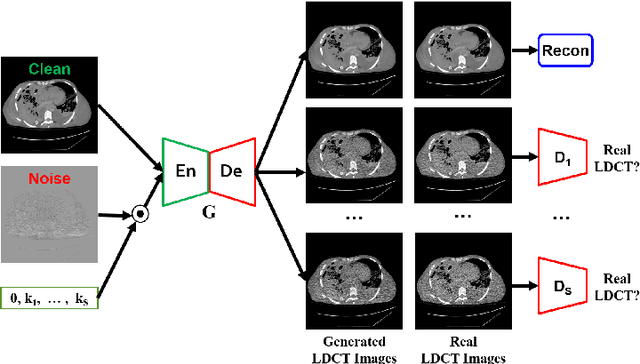
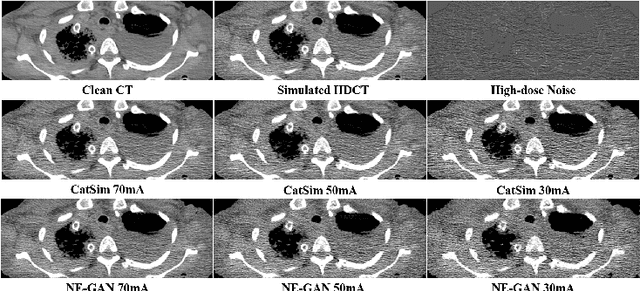
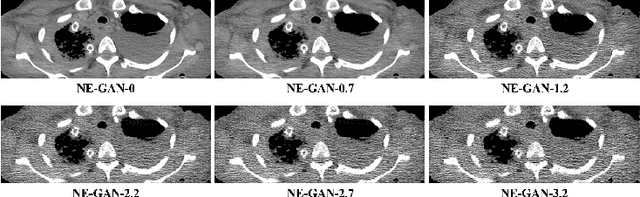
We propose a Noise Entangled GAN (NE-GAN) for simulating low-dose computed tomography (CT) images from a higher dose CT image. First, we present two schemes to generate a clean CT image and a noise image from the high-dose CT image. Then, given these generated images, an NE-GAN is proposed to simulate different levels of low-dose CT images, where the level of generated noise can be continuously controlled by a noise factor. NE-GAN consists of a generator and a set of discriminators, and the number of discriminators is determined by the number of noise levels during training. Compared with the traditional methods based on the projection data that are usually unavailable in real applications, NE-GAN can directly learn from the real and/or simulated CT images and may create low-dose CT images quickly without the need of raw data or other proprietary CT scanner information. The experimental results show that the proposed method has the potential to simulate realistic low-dose CT images.
Visual Steering for One-Shot Deep Neural Network Synthesis
Sep 28, 2020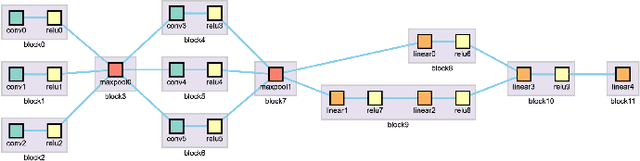
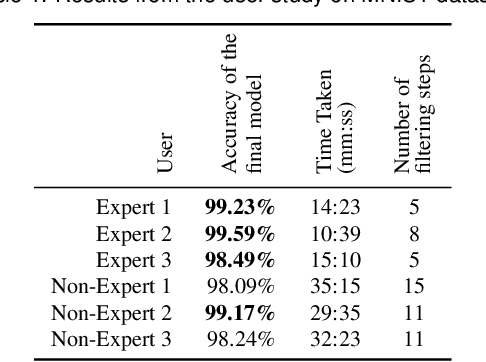
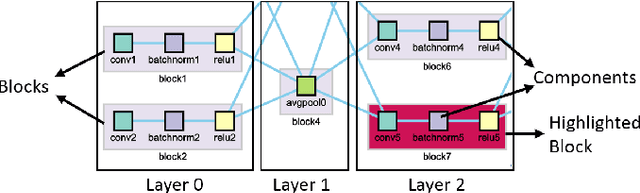

Recent advancements in the area of deep learning have shown the effectiveness of very large neural networks in several applications. However, as these deep neural networks continue to grow in size, it becomes more and more difficult to configure their many parameters to obtain good results. Presently, analysts must experiment with many different configurations and parameter settings, which is labor-intensive and time-consuming. On the other hand, the capacity of fully automated techniques for neural network architecture search is limited without the domain knowledge of human experts. To deal with the problem, we formulate the task of neural network architecture optimization as a graph space exploration, based on the one-shot architecture search technique. In this approach, a super-graph of all candidate architectures is trained in one-shot and the optimal neural network is identified as a sub-graph. In this paper, we present a framework that allows analysts to effectively build the solution sub-graph space and guide the network search by injecting their domain knowledge. Starting with the network architecture space composed of basic neural network components, analysts are empowered to effectively select the most promising components via our one-shot search scheme. Applying this technique in an iterative manner allows analysts to converge to the best performing neural network architecture for a given application. During the exploration, analysts can use their domain knowledge aided by cues provided from a scatterplot visualization of the search space to edit different components and guide the search for faster convergence. We designed our interface in collaboration with several deep learning researchers and its final effectiveness is evaluated with a user study and two case studies.
Active Learning++: Incorporating Annotator's Rationale using Local Model Explanation
Sep 06, 2020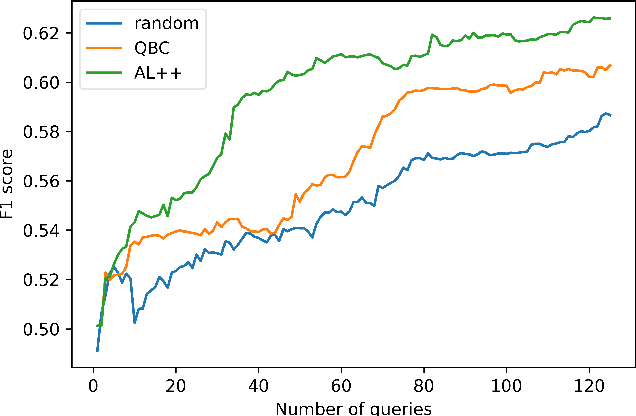
We propose a new active learning (AL) framework, Active Learning++, which can utilize an annotator's labels as well as its rationale. Annotators can provide their rationale for choosing a label by ranking input features based on their importance for a given query. To incorporate this additional input, we modified the disagreement measure for a bagging-based Query by Committee (QBC) sampling strategy. Instead of weighing all committee models equally to select the next instance, we assign higher weight to the committee model with higher agreement with the annotator's ranking. Specifically, we generated a feature importance-based local explanation for each committee model. The similarity score between feature rankings provided by the annotator and the local model explanation is used to assign a weight to each corresponding committee model. This approach is applicable to any kind of ML model using model-agnostic techniques to generate local explanation such as LIME. With a simulation study, we show that our framework significantly outperforms a QBC based vanilla AL framework.
Measuring Social Biases of Crowd Workers using Counterfactual Queries
Apr 04, 2020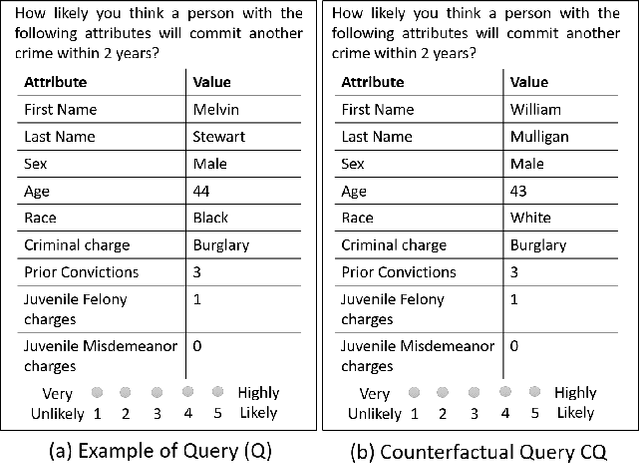
Social biases based on gender, race, etc. have been shown to pollute machine learning (ML) pipeline predominantly via biased training datasets. Crowdsourcing, a popular cost-effective measure to gather labeled training datasets, is not immune to the inherent social biases of crowd workers. To ensure such social biases aren't passed onto the curated datasets, it's important to know how biased each crowd worker is. In this work, we propose a new method based on counterfactual fairness to quantify the degree of inherent social bias in each crowd worker. This extra information can be leveraged together with individual worker responses to curate a less biased dataset.
Explainable Active Learning (XAL): An Empirical Study of How Local Explanations Impact Annotator Experience
Jan 31, 2020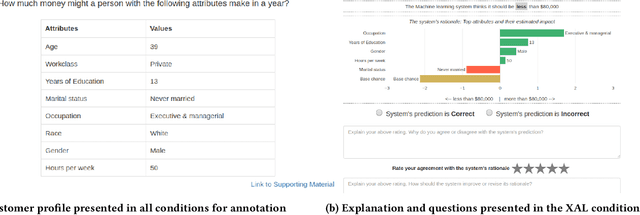
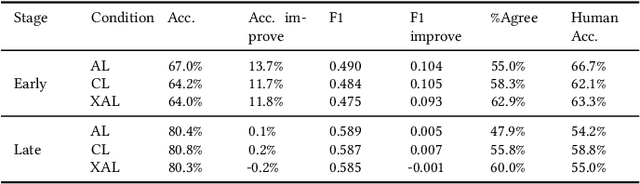
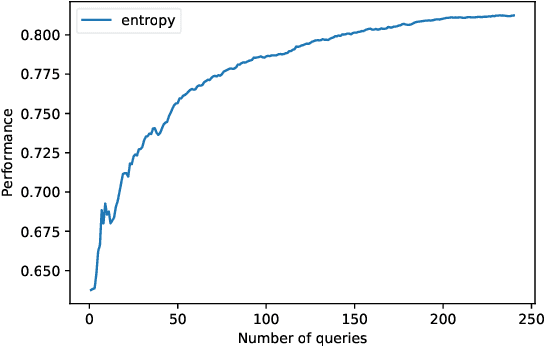
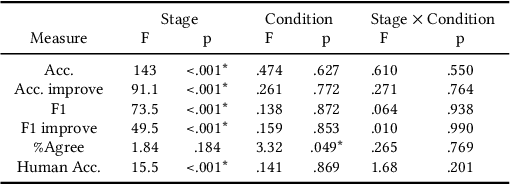
Active Learning (AL) is a human-in-the-loop Machine Learning paradigm favored for its ability to learn with fewer labeled instances, but the model's states and progress remain opaque to the annotators. Meanwhile, many recognize the benefits of model transparency for people interacting with ML models, as reflected by the surge of explainable AI (XAI) as a research field. However, explaining an evolving model introduces many open questions regarding its impact on the annotation quality and the annotator's experience. In this paper, we propose a novel paradigm of explainable active learning (XAL), by explaining the learning algorithm's prediction for the instance it wants to learn from and soliciting feedback from the annotator. We conduct an empirical study comparing the model learning outcome, human feedback content and the annotator experience with XAL, to that of traditional AL and coactive learning (providing the model's prediction without the explanation). Our study reveals benefits--supporting trust calibration and enabling additional forms of human feedback, and potential drawbacks--anchoring effect and frustration from transparent model limitations--of providing local explanations in AL. We conclude by suggesting directions for developing explanations that better support annotator experience in AL and interactive ML settings.
Interpreting Galaxy Deblender GAN from the Discriminator's Perspective
Jan 17, 2020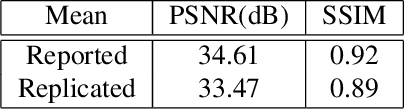


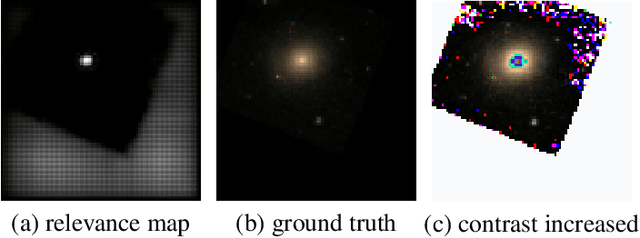
Generative adversarial networks (GANs) are well known for their unsupervised learning capabilities. A recent success in the field of astronomy is deblending two overlapping galaxy images via a branched GAN model. However, it remains a significant challenge to comprehend how the network works, which is particularly difficult for non-expert users. This research focuses on behaviors of one of the network's major components, the Discriminator, which plays a vital role but is often overlooked, Specifically, we enhance the Layer-wise Relevance Propagation (LRP) scheme to generate a heatmap-based visualization. We call this technique Polarized-LRP and it consists of two parts i.e. positive contribution heatmaps for ground truth images and negative contribution heatmaps for generated images. Using the Galaxy Zoo dataset we demonstrate that our method clearly reveals attention areas of the Discriminator when differentiating generated galaxy images from ground truth images. To connect the Discriminator's impact on the Generator, we visualize the gradual changes of the Generator across the training process. An interesting result we have achieved there is the detection of a problematic data augmentation procedure that would else have remained hidden. We find that our proposed method serves as a useful visual analytical tool for a deeper understanding of GAN models.