 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocalLens: Visualizing Narratives through Focalization
Apr 15, 2026Visualizing narratives is useful to writers to reflect on unfinished drafts and identify unintentional biases and inconsistencies. Literary scholars can use the visualizations to identify nuanced patterns and literary styles from written text. Current narrative visualization is limited to representing character and location co-occurrences in a timeline, omitting important and complex narrative components such as focalization, causality, and speech. This paper aims to capture and visualize underexplored, complex narrative components as a basis for narrative visualization. As a starting point, we propose a new narrative visualization, named FocalLens, that uses focalization, the component that establishes who sees or perceives the events in a narrative, for representing the narrative. We provide the theoretical foundation of focalization and describe various types and facets of focalization. The details are incorporated in the novel visualization that captures how different characters perceive an event, who directly participate in an event, who indirectly observe the event, and who narrate the event. We also developed a tool that provides fluid interaction between the text and the proposed visualization. The tool was evaluated with four writers and scholars in a qualitative study, where writers analyzed their draft stories and scholars analyzed well-known stories. The findings suggest the tool added a new dimension to the workflow for writers and scholars, an analytical lens that is not available otherwise. We conclude by identifying design implications and future directions.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024



In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
Dataopsy: Scalable and Fluid Visual Exploration using Aggregate Query Sculpting
Aug 05, 2023



We present aggregate query sculpting (AQS), a faceted visual query technique for large-scale multidimensional data. As a "born scalable" query technique, AQS starts visualization with a single visual mark representing an aggregation of the entire dataset. The user can then progressively explore the dataset through a sequence of operations abbreviated as P6: pivot (facet an aggregate based on an attribute), partition (lay out a facet in space), peek (see inside a subset using an aggregate visual representation), pile (merge two or more subsets), project (extracting a subset into a new substrate), and prune (discard an aggregate not currently of interest). We validate AQS with Dataopsy, a prototype implementation of AQS that has been designed for fluid interaction on desktop and touch-based mobile devices. We demonstrate AQS and Dataopsy using two case studies and three application examples.
WordBias: An Interactive Visual Tool for Discovering Intersectional Biases Encoded in Word Embeddings
Mar 05, 2021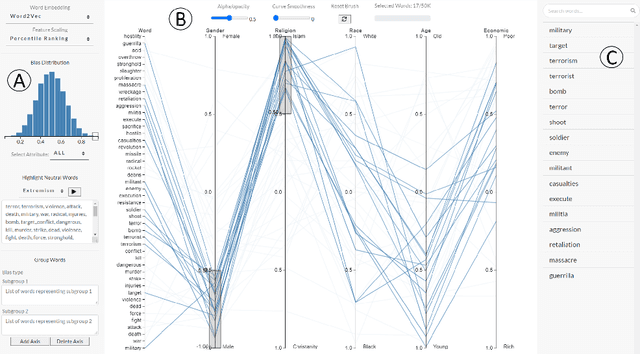
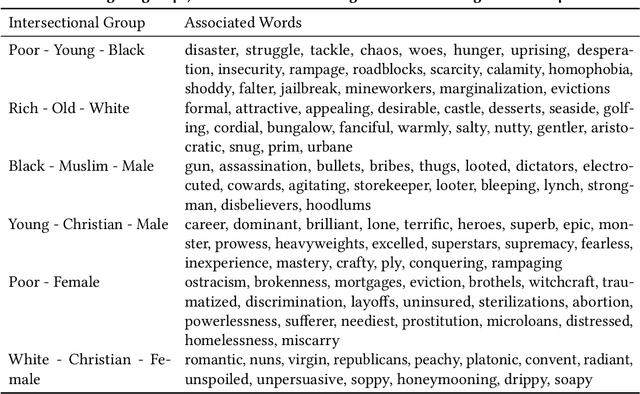
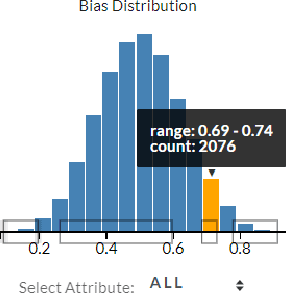
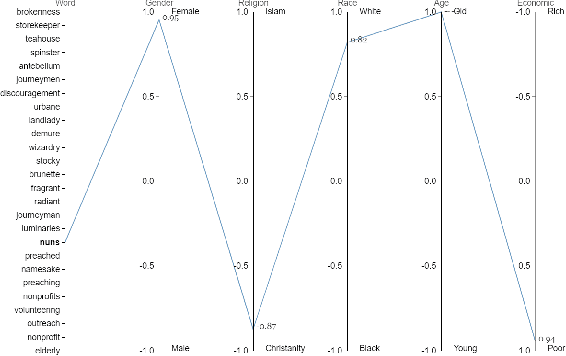
Intersectional bias is a bias caused by an overlap of multiple social factors like gender, sexuality, race, disability, religion, etc. A recent study has shown that word embedding models can be laden with biases against intersectional groups like African American females, etc. The first step towards tackling such intersectional biases is to identify them. However, discovering biases against different intersectional groups remains a challenging task. In this work, we present WordBias, an interactive visual tool designed to explore biases against intersectional groups encoded in static word embeddings. Given a pretrained static word embedding, WordBias computes the association of each word along different groups based on race, age, etc. and then visualizes them using a novel interactive interface. Using a case study, we demonstrate how WordBias can help uncover biases against intersectional groups like Black Muslim Males, Poor Females, etc. encoded in word embedding. In addition, we also evaluate our tool using qualitative feedback from expert interviews. The source code for this tool can be publicly accessed for reproducibility at github.com/bhavyaghai/WordBias.