 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Stochastic Spectral Preconditioning Converges for Nonconvex Objectives
May 12, 2026In this work, we develop proximal preconditioned gradient methods with a focus on spectral gradient methods providing a proximal extension to the Muon and Scion optimizers. We introduce a family of stochastic algorithms that can handle a wide variety of convex and nonconvex constraints and study its convergence under heavy-tailed noise, through a novel analysis tailored to the geometry of the proposed methods. We further propose a variance-reduced version, which achieves faster convergence under standard noise assumptions. Finally, we show that the polynomial iterations used in Muon are more accurately captured by a nonlinear preconditioner than by the ideal matrix sign, leading to a convergence analysis that more faithfully reflects practical implementations.
Training Neural Networks at Any Scale
Nov 14, 2025This article reviews modern optimization methods for training neural networks with an emphasis on efficiency and scale. We present state-of-the-art optimization algorithms under a unified algorithmic template that highlights the importance of adapting to the structures in the problem. We then cover how to make these algorithms agnostic to the scale of the problem. Our exposition is intended as an introduction for both practitioners and researchers who wish to be involved in these exciting new developments.
Layer-wise Quantization for Quantized Optimistic Dual Averaging
May 20, 2025



Modern deep neural networks exhibit heterogeneity across numerous layers of various types such as residuals, multi-head attention, etc., due to varying structures (dimensions, activation functions, etc.), distinct representation characteristics, which impact predictions. We develop a general layer-wise quantization framework with tight variance and code-length bounds, adapting to the heterogeneities over the course of training. We then apply a new layer-wise quantization technique within distributed variational inequalities (VIs), proposing a novel Quantized Optimistic Dual Averaging (QODA) algorithm with adaptive learning rates, which achieves competitive convergence rates for monotone VIs. We empirically show that QODA achieves up to a $150\%$ speedup over the baselines in end-to-end training time for training Wasserstein GAN on $12+$ GPUs.
Multi-Step Alignment as Markov Games: An Optimistic Online Gradient Descent Approach with Convergence Guarantees
Feb 18, 2025



Reinforcement Learning from Human Feedback (RLHF) has been highly successful in aligning large language models with human preferences. While prevalent methods like DPO have demonstrated strong performance, they frame interactions with the language model as a bandit problem, which limits their applicability in real-world scenarios where multi-turn conversations are common. Additionally, DPO relies on the Bradley-Terry model assumption, which does not adequately capture the non-transitive nature of human preferences. In this paper, we address these challenges by modeling the alignment problem as a two-player constant-sum Markov game, where each player seeks to maximize their winning rate against the other across all steps of the conversation. Our approach Multi-step Preference Optimization (MPO) is built upon the natural actor-critic framework~\citep{peters2008natural}. We further develop OMPO based on the optimistic online gradient descent algorithm~\citep{rakhlin2013online,joulani17a}. Theoretically, we provide a rigorous analysis for both algorithms on convergence and show that OMPO requires $\mathcal{O}(\epsilon^{-1})$ policy updates to converge to an $\epsilon$-approximate Nash equilibrium. We also validate the effectiveness of our method on multi-turn conversations dataset and math reasoning dataset.
Training Deep Learning Models with Norm-Constrained LMOs
Feb 11, 2025In this work, we study optimization methods that leverage the linear minimization oracle (LMO) over a norm-ball. We propose a new stochastic family of algorithms that uses the LMO to adapt to the geometry of the problem and, perhaps surprisingly, show that they can be applied to unconstrained problems. The resulting update rule unifies several existing optimization methods under a single framework. Furthermore, we propose an explicit choice of norm for deep architectures, which, as a side benefit, leads to the transferability of hyperparameters across model sizes. Experimentally, we demonstrate significant speedups on nanoGPT training without any reliance on Adam. The proposed method is memory-efficient, requiring only one set of model weights and one set of gradients, which can be stored in half-precision.
Improving SAM Requires Rethinking its Optimization Formulation
Jul 17, 2024



This paper rethinks Sharpness-Aware Minimization (SAM), which is originally formulated as a zero-sum game where the weights of a network and a bounded perturbation try to minimize/maximize, respectively, the same differentiable loss. To fundamentally improve this design, we argue that SAM should instead be reformulated using the 0-1 loss. As a continuous relaxation, we follow the simple conventional approach where the minimizing (maximizing) player uses an upper bound (lower bound) surrogate to the 0-1 loss. This leads to a novel formulation of SAM as a bilevel optimization problem, dubbed as BiSAM. BiSAM with newly designed lower-bound surrogate loss indeed constructs stronger perturbation. Through numerical evidence, we show that BiSAM consistently results in improved performance when compared to the original SAM and variants, while enjoying similar computational complexity. Our code is available at https://github.com/LIONS-EPFL/BiSAM.
Distributed Extra-gradient with Optimal Complexity and Communication Guarantees
Aug 17, 2023



We consider monotone variational inequality (VI) problems in multi-GPU settings where multiple processors/workers/clients have access to local stochastic dual vectors. This setting includes a broad range of important problems from distributed convex minimization to min-max and games. Extra-gradient, which is a de facto algorithm for monotone VI problems, has not been designed to be communication-efficient. To this end, we propose a quantized generalized extra-gradient (Q-GenX), which is an unbiased and adaptive compression method tailored to solve VIs. We provide an adaptive step-size rule, which adapts to the respective noise profiles at hand and achieve a fast rate of ${\mathcal O}(1/T)$ under relative noise, and an order-optimal ${\mathcal O}(1/\sqrt{T})$ under absolute noise and show distributed training accelerates convergence. Finally, we validate our theoretical results by providing real-world experiments and training generative adversarial networks on multiple GPUs.
Adaptive Stochastic Variance Reduction for Non-convex Finite-Sum Minimization
Nov 03, 2022



We propose an adaptive variance-reduction method, called AdaSpider, for minimization of $L$-smooth, non-convex functions with a finite-sum structure. In essence, AdaSpider combines an AdaGrad-inspired [Duchi et al., 2011, McMahan & Streeter, 2010], but a fairly distinct, adaptive step-size schedule with the recursive stochastic path integrated estimator proposed in [Fang et al., 2018]. To our knowledge, Adaspider is the first parameter-free non-convex variance-reduction method in the sense that it does not require the knowledge of problem-dependent parameters, such as smoothness constant $L$, target accuracy $\epsilon$ or any bound on gradient norms. In doing so, we are able to compute an $\epsilon$-stationary point with $\tilde{O}\left(n + \sqrt{n}/\epsilon^2\right)$ oracle-calls, which matches the respective lower bound up to logarithmic factors.
Extra-Newton: A First Approach to Noise-Adaptive Accelerated Second-Order Methods
Nov 03, 2022



This work proposes a universal and adaptive second-order method for minimizing second-order smooth, convex functions. Our algorithm achieves $O(\sigma / \sqrt{T})$ convergence when the oracle feedback is stochastic with variance $\sigma^2$, and improves its convergence to $O( 1 / T^3)$ with deterministic oracles, where $T$ is the number of iterations. Our method also interpolates these rates without knowing the nature of the oracle apriori, which is enabled by a parameter-free adaptive step-size that is oblivious to the knowledge of smoothness modulus, variance bounds and the diameter of the constrained set. To our knowledge, this is the first universal algorithm with such global guarantees within the second-order optimization literature.
No-Regret Learning in Games with Noisy Feedback: Faster Rates and Adaptivity via Learning Rate Separation
Jun 13, 2022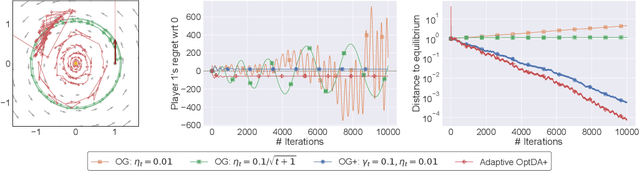

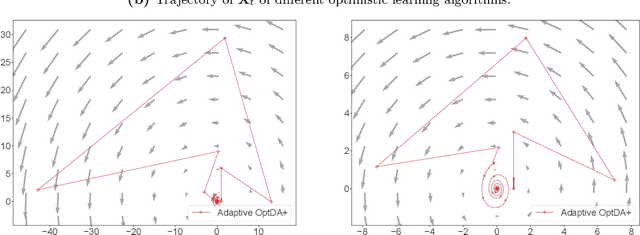
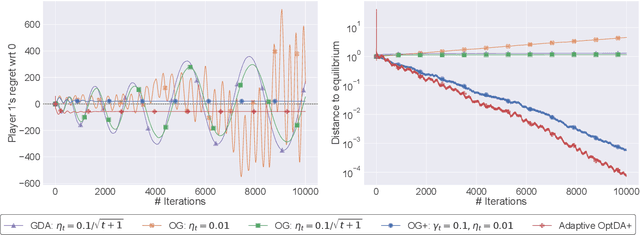
We examine the problem of regret minimization when the learner is involved in a continuous game with other optimizing agents: in this case, if all players follow a no-regret algorithm, it is possible to achieve significantly lower regret relative to fully adversarial environments. We study this problem in the context of variationally stable games (a class of continuous games which includes all convex-concave and monotone games), and when the players only have access to noisy estimates of their individual payoff gradients. If the noise is additive, the game-theoretic and purely adversarial settings enjoy similar regret guarantees; however, if the noise is multiplicative, we show that the learners can, in fact, achieve constant regret. We achieve this faster rate via an optimistic gradient scheme with learning rate separation -- that is, the method's extrapolation and update steps are tuned to different schedules, depending on the noise profile. Subsequently, to eliminate the need for delicate hyperparameter tuning, we propose a fully adaptive method that smoothly interpolates between worst- and best-case regret guarantees.