 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Semi-Supervised Few-Shot Classification
Mar 02, 2018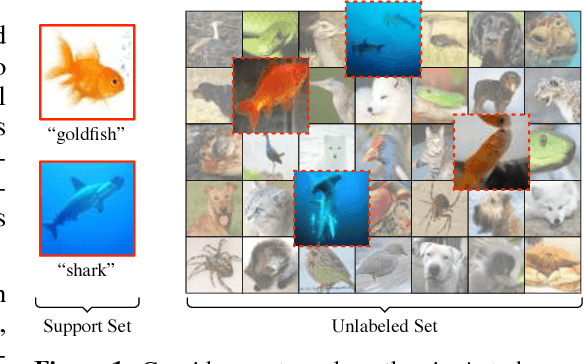
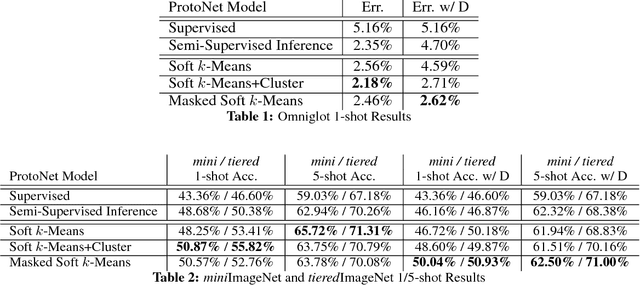
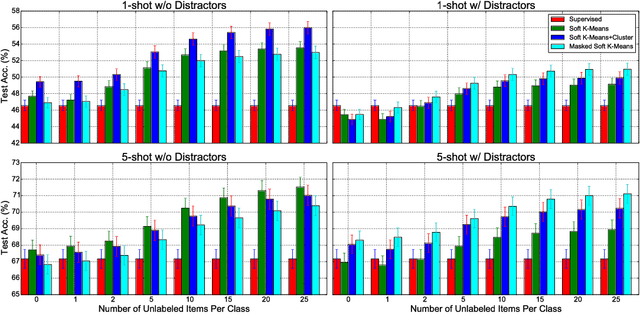
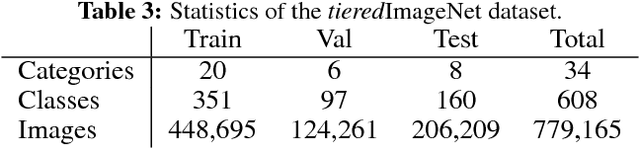
In few-shot classification, we are interested in learning algorithms that train a classifier from only a handful of labeled examples. Recent progress in few-shot classification has featured meta-learning, in which a parameterized model for a learning algorithm is defined and trained on episodes representing different classification problems, each with a small labeled training set and its corresponding test set. In this work, we advance this few-shot classification paradigm towards a scenario where unlabeled examples are also available within each episode. We consider two situations: one where all unlabeled examples are assumed to belong to the same set of classes as the labeled examples of the episode, as well as the more challenging situation where examples from other distractor classes are also provided. To address this paradigm, we propose novel extensions of Prototypical Networks (Snell et al., 2017) that are augmented with the ability to use unlabeled examples when producing prototypes. These models are trained in an end-to-end way on episodes, to learn to leverage the unlabeled examples successfully. We evaluate these methods on versions of the Omniglot and miniImageNet benchmarks, adapted to this new framework augmented with unlabeled examples. We also propose a new split of ImageNet, consisting of a large set of classes, with a hierarchical structure. Our experiments confirm that our Prototypical Networks can learn to improve their predictions due to unlabeled examples, much like a semi-supervised algorithm would.
Learning Hard Alignments with Variational Inference
Nov 01, 2017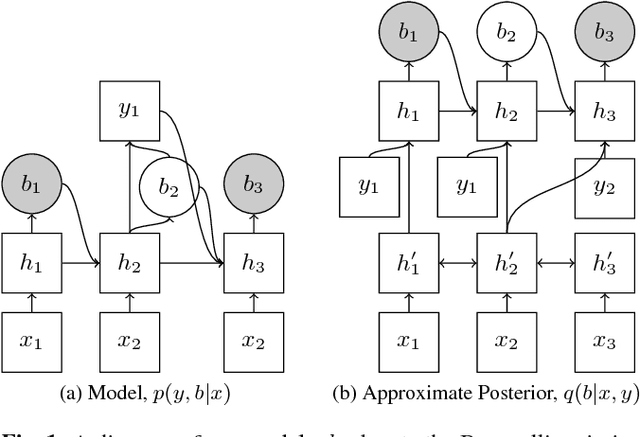
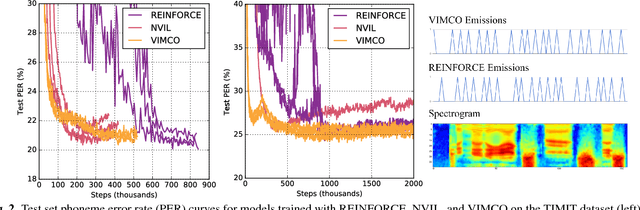
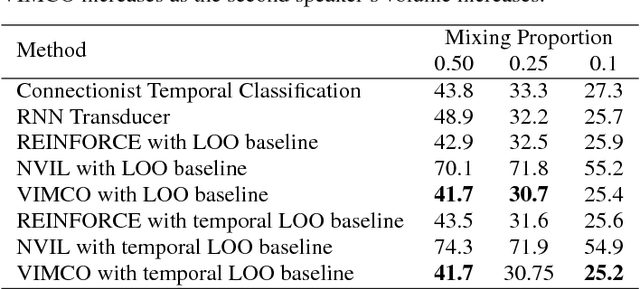
There has recently been significant interest in hard attention models for tasks such as object recognition, visual captioning and speech recognition. Hard attention can offer benefits over soft attention such as decreased computational cost, but training hard attention models can be difficult because of the discrete latent variables they introduce. Previous work used REINFORCE and Q-learning to approach these issues, but those methods can provide high-variance gradient estimates and be slow to train. In this paper, we tackle the problem of learning hard attention for a sequential task using variational inference methods, specifically the recently introduced VIMCO and NVIL. Furthermore, we propose a novel baseline that adapts VIMCO to this setting. We demonstrate our method on a phoneme recognition task in clean and noisy environments and show that our method outperforms REINFORCE, with the difference being greater for a more complicated task.
The Variational Fair Autoencoder
Aug 10, 2017
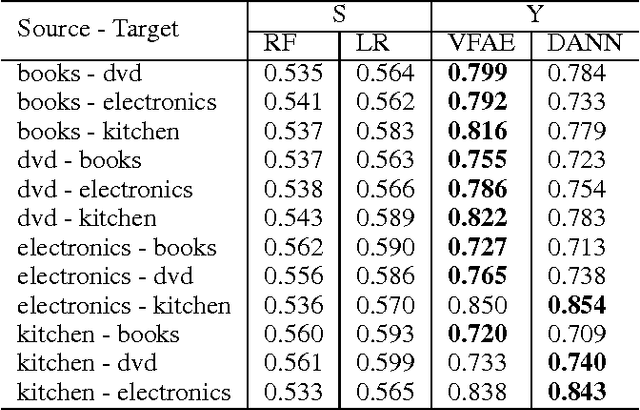
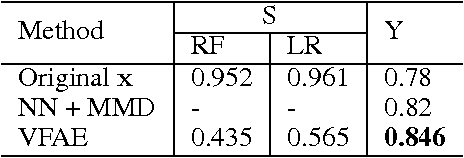
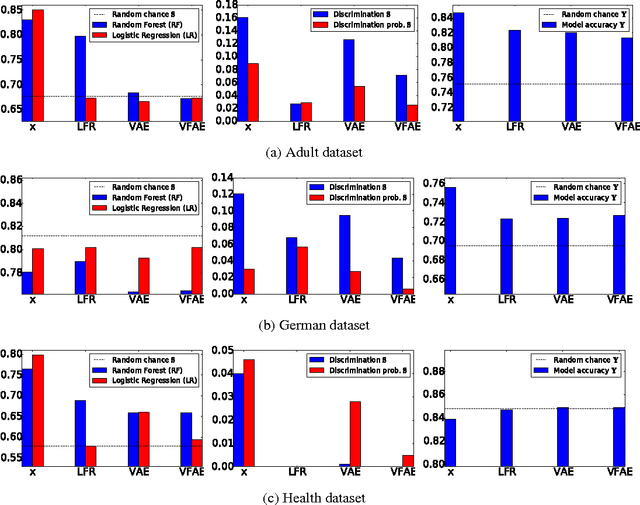
We investigate the problem of learning representations that are invariant to certain nuisance or sensitive factors of variation in the data while retaining as much of the remaining information as possible. Our model is based on a variational autoencoding architecture with priors that encourage independence between sensitive and latent factors of variation. Any subsequent processing, such as classification, can then be performed on this purged latent representation. To remove any remaining dependencies we incorporate an additional penalty term based on the "Maximum Mean Discrepancy" (MMD) measure. We discuss how these architectures can be efficiently trained on data and show in experiments that this method is more effective than previous work in removing unwanted sources of variation while maintaining informative latent representations.
Prototypical Networks for Few-shot Learning
Jun 19, 2017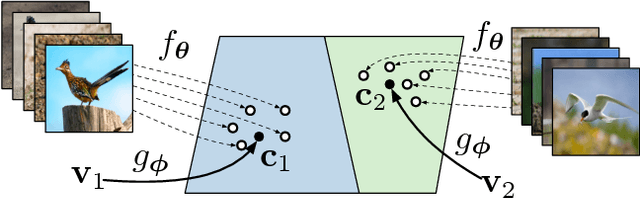

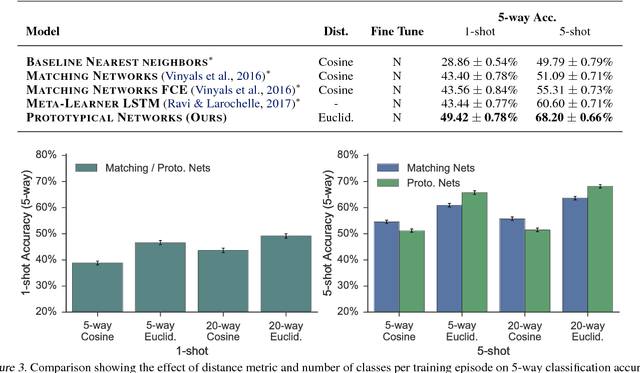
We propose prototypical networks for the problem of few-shot classification, where a classifier must generalize to new classes not seen in the training set, given only a small number of examples of each new class. Prototypical networks learn a metric space in which classification can be performed by computing distances to prototype representations of each class. Compared to recent approaches for few-shot learning, they reflect a simpler inductive bias that is beneficial in this limited-data regime, and achieve excellent results. We provide an analysis showing that some simple design decisions can yield substantial improvements over recent approaches involving complicated architectural choices and meta-learning. We further extend prototypical networks to zero-shot learning and achieve state-of-the-art results on the CU-Birds dataset.
An online sequence-to-sequence model for noisy speech recognition
Jun 16, 2017
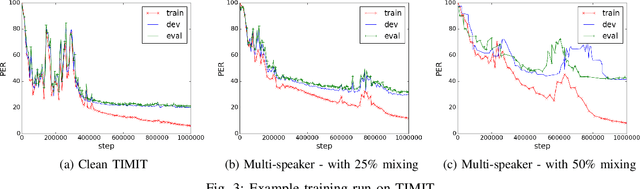
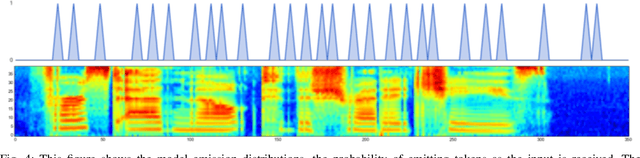
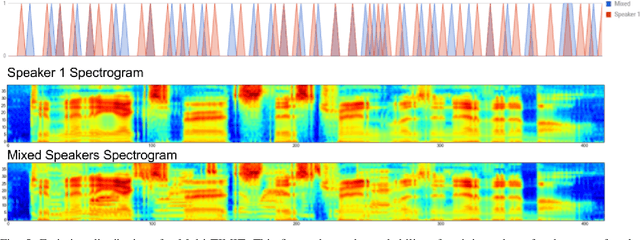
Generative models have long been the dominant approach for speech recognition. The success of these models however relies on the use of sophisticated recipes and complicated machinery that is not easily accessible to non-practitioners. Recent innovations in Deep Learning have given rise to an alternative - discriminative models called Sequence-to-Sequence models, that can almost match the accuracy of state of the art generative models. While these models are easy to train as they can be trained end-to-end in a single step, they have a practical limitation that they can only be used for offline recognition. This is because the models require that the entirety of the input sequence be available at the beginning of inference, an assumption that is not valid for instantaneous speech recognition. To address this problem, online sequence-to-sequence models were recently introduced. These models are able to start producing outputs as data arrives, and the model feels confident enough to output partial transcripts. These models, like sequence-to-sequence are causal - the output produced by the model until any time, $t$, affects the features that are computed subsequently. This makes the model inherently more powerful than generative models that are unable to change features that are computed from the data. This paper highlights two main contributions - an improvement to online sequence-to-sequence model training, and its application to noisy settings with mixed speech from two speakers.
Predicting Deep Zero-Shot Convolutional Neural Networks using Textual Descriptions
Sep 25, 2015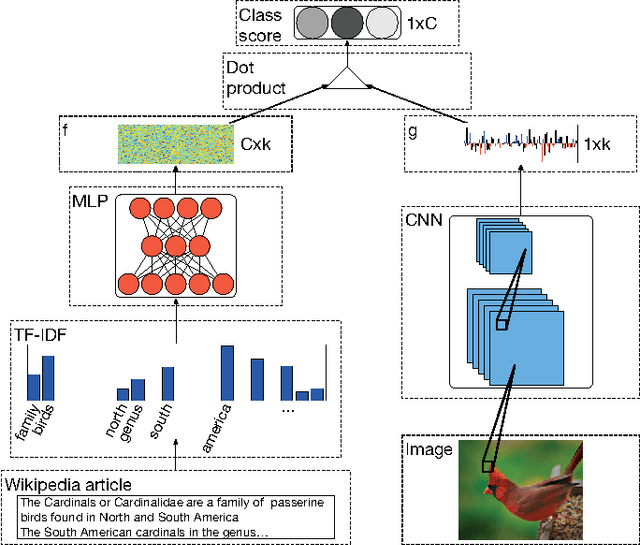
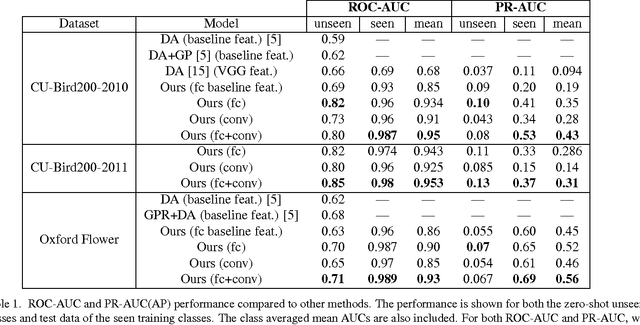

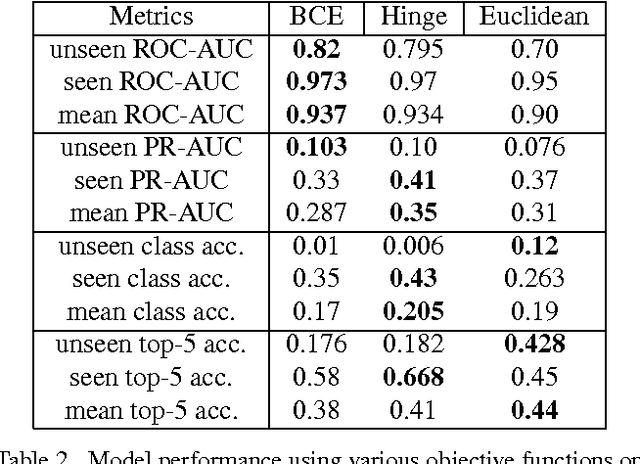
One of the main challenges in Zero-Shot Learning of visual categories is gathering semantic attributes to accompany images. Recent work has shown that learning from textual descriptions, such as Wikipedia articles, avoids the problem of having to explicitly define these attributes. We present a new model that can classify unseen categories from their textual description. Specifically, we use text features to predict the output weights of both the convolutional and the fully connected layers in a deep convolutional neural network (CNN). We take advantage of the architecture of CNNs and learn features at different layers, rather than just learning an embedding space for both modalities, as is common with existing approaches. The proposed model also allows us to automatically generate a list of pseudo- attributes for each visual category consisting of words from Wikipedia articles. We train our models end-to-end us- ing the Caltech-UCSD bird and flower datasets and evaluate both ROC and Precision-Recall curves. Our empirical results show that the proposed model significantly outperforms previous methods.
Scalable Bayesian Optimization Using Deep Neural Networks
Jul 13, 2015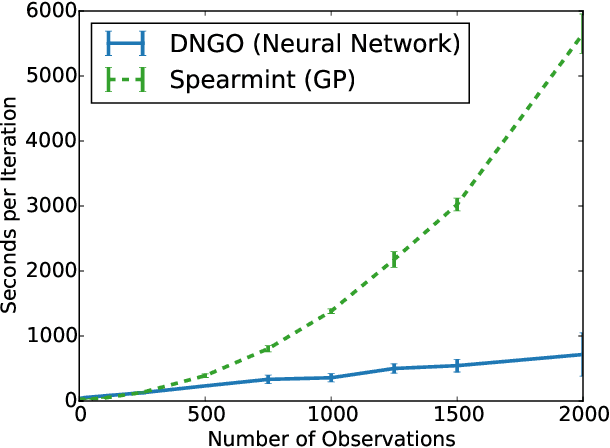
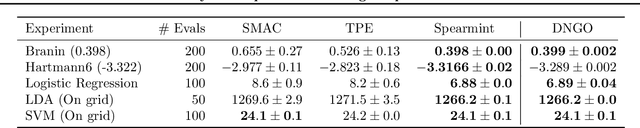
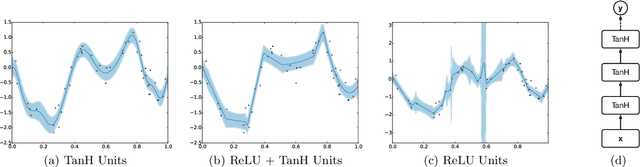

Bayesian optimization is an effective methodology for the global optimization of functions with expensive evaluations. It relies on querying a distribution over functions defined by a relatively cheap surrogate model. An accurate model for this distribution over functions is critical to the effectiveness of the approach, and is typically fit using Gaussian processes (GPs). However, since GPs scale cubically with the number of observations, it has been challenging to handle objectives whose optimization requires many evaluations, and as such, massively parallelizing the optimization. In this work, we explore the use of neural networks as an alternative to GPs to model distributions over functions. We show that performing adaptive basis function regression with a neural network as the parametric form performs competitively with state-of-the-art GP-based approaches, but scales linearly with the number of data rather than cubically. This allows us to achieve a previously intractable degree of parallelism, which we apply to large scale hyperparameter optimization, rapidly finding competitive models on benchmark object recognition tasks using convolutional networks, and image caption generation using neural language models.
Generative Moment Matching Networks
Feb 10, 2015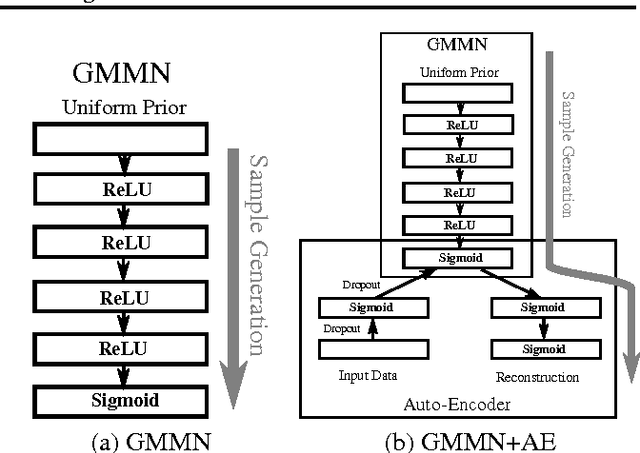
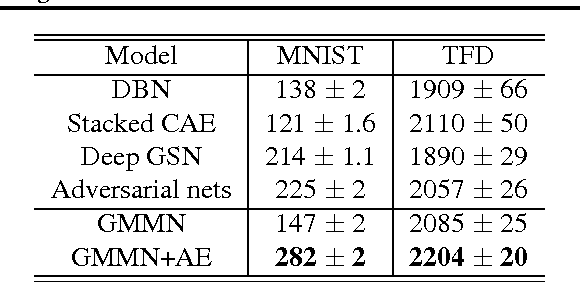


We consider the problem of learning deep generative models from data. We formulate a method that generates an independent sample via a single feedforward pass through a multilayer perceptron, as in the recently proposed generative adversarial networks (Goodfellow et al., 2014). Training a generative adversarial network, however, requires careful optimization of a difficult minimax program. Instead, we utilize a technique from statistical hypothesis testing known as maximum mean discrepancy (MMD), which leads to a simple objective that can be interpreted as matching all orders of statistics between a dataset and samples from the model, and can be trained by backpropagation. We further boost the performance of this approach by combining our generative network with an auto-encoder network, using MMD to learn to generate codes that can then be decoded to produce samples. We show that the combination of these techniques yields excellent generative models compared to baseline approaches as measured on MNIST and the Toronto Face Database.
Learning unbiased features
Dec 17, 2014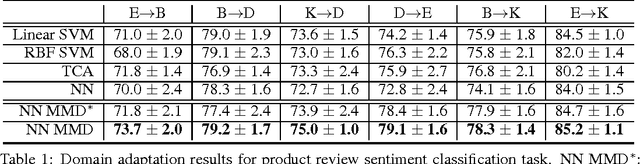



A key element in transfer learning is representation learning; if representations can be developed that expose the relevant factors underlying the data, then new tasks and domains can be learned readily based on mappings of these salient factors. We propose that an important aim for these representations are to be unbiased. Different forms of representation learning can be derived from alternative definitions of unwanted bias, e.g., bias to particular tasks, domains, or irrelevant underlying data dimensions. One very useful approach to estimating the amount of bias in a representation comes from maximum mean discrepancy (MMD) [5], a measure of distance between probability distributions. We are not the first to suggest that MMD can be a useful criterion in developing representations that apply across multiple domains or tasks [1]. However, in this paper we describe a number of novel applications of this criterion that we have devised, all based on the idea of developing unbiased representations. These formulations include: a standard domain adaptation framework; a method of learning invariant representations; an approach based on noise-insensitive autoencoders; and a novel form of generative model.
Raiders of the Lost Architecture: Kernels for Bayesian Optimization in Conditional Parameter Spaces
Sep 14, 2014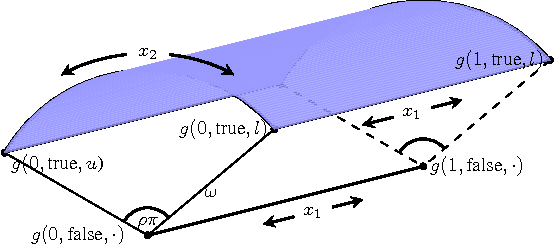

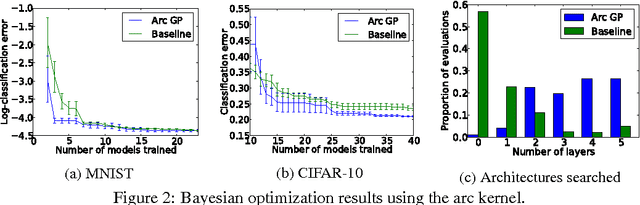
In practical Bayesian optimization, we must often search over structures with differing numbers of parameters. For instance, we may wish to search over neural network architectures with an unknown number of layers. To relate performance data gathered for different architectures, we define a new kernel for conditional parameter spaces that explicitly includes information about which parameters are relevant in a given structure. We show that this kernel improves model quality and Bayesian optimization results over several simpler baseline kernels.