 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarmth and competence in human-agent cooperation
Jan 31, 2022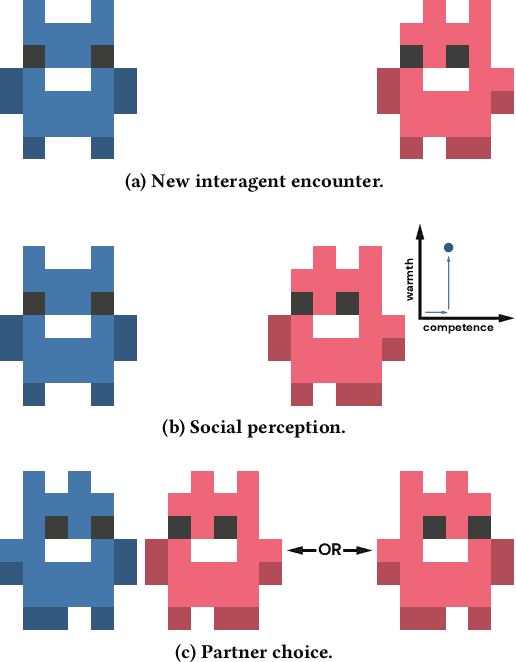

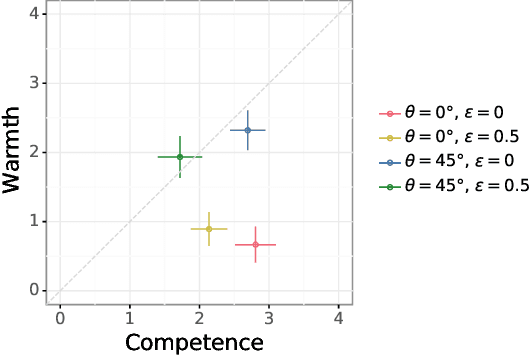
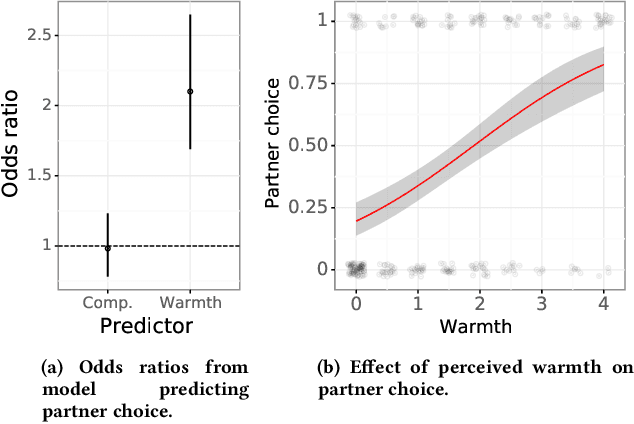
Interaction and cooperation with humans are overarching aspirations of artificial intelligence (AI) research. Recent studies demonstrate that AI agents trained with deep reinforcement learning are capable of collaborating with humans. These studies primarily evaluate human compatibility through "objective" metrics such as task performance, obscuring potential variation in the levels of trust and subjective preference that different agents garner. To better understand the factors shaping subjective preferences in human-agent cooperation, we train deep reinforcement learning agents in Coins, a two-player social dilemma. We recruit participants for a human-agent cooperation study and measure their impressions of the agents they encounter. Participants' perceptions of warmth and competence predict their stated preferences for different agents, above and beyond objective performance metrics. Drawing inspiration from social science and biology research, we subsequently implement a new "partner choice" framework to elicit revealed preferences: after playing an episode with an agent, participants are asked whether they would like to play the next round with the same agent or to play alone. As with stated preferences, social perception better predicts participants' revealed preferences than does objective performance. Given these results, we recommend human-agent interaction researchers routinely incorporate the measurement of social perception and subjective preferences into their studies.
Hidden Agenda: a Social Deduction Game with Diverse Learned Equilibria
Jan 05, 2022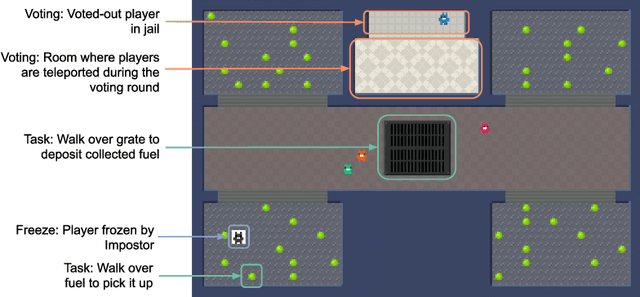

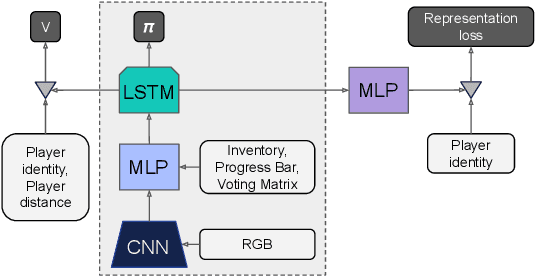
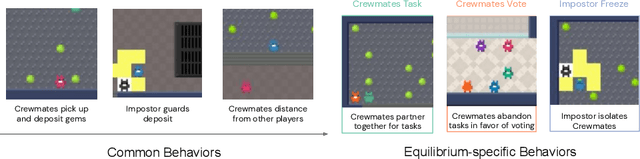
A key challenge in the study of multiagent cooperation is the need for individual agents not only to cooperate effectively, but to decide with whom to cooperate. This is particularly critical in situations when other agents have hidden, possibly misaligned motivations and goals. Social deduction games offer an avenue to study how individuals might learn to synthesize potentially unreliable information about others, and elucidate their true motivations. In this work, we present Hidden Agenda, a two-team social deduction game that provides a 2D environment for studying learning agents in scenarios of unknown team alignment. The environment admits a rich set of strategies for both teams. Reinforcement learning agents trained in Hidden Agenda show that agents can learn a variety of behaviors, including partnering and voting without need for communication in natural language.
Statistical discrimination in learning agents
Oct 21, 2021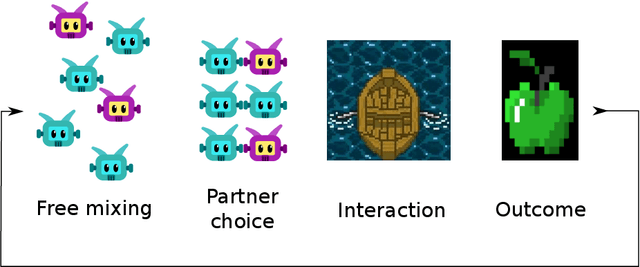
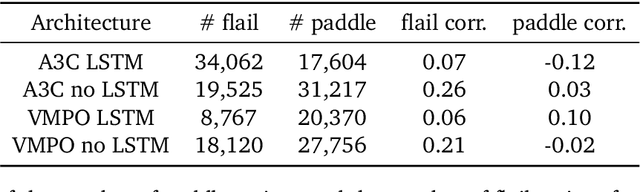
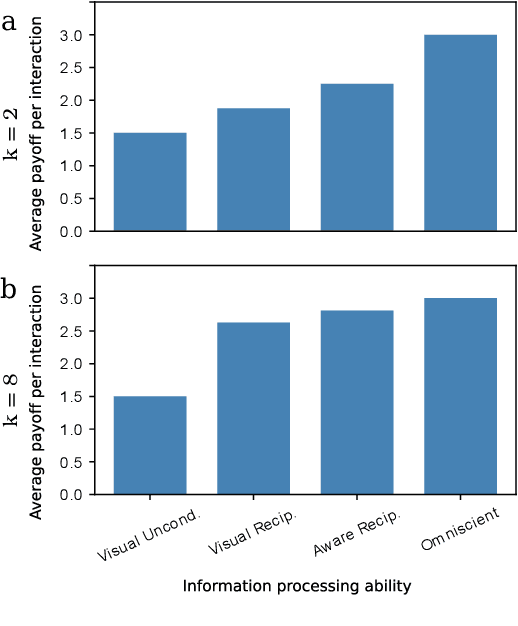
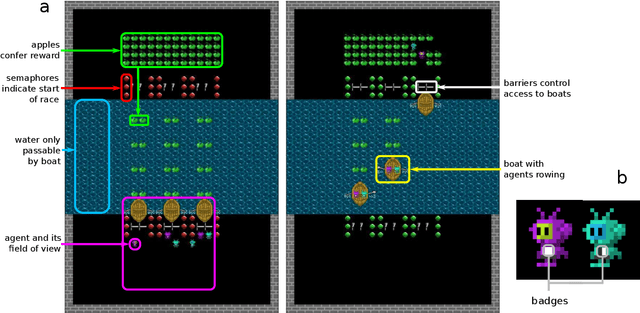
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.
Collaborating with Humans without Human Data
Oct 15, 2021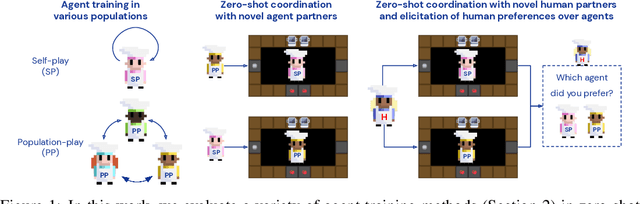

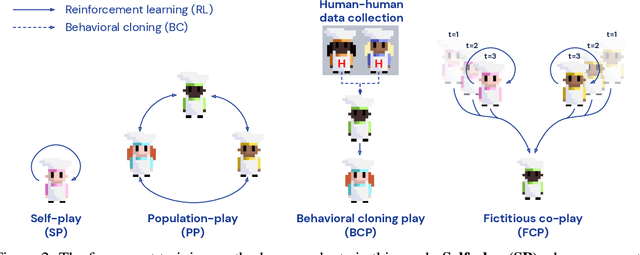
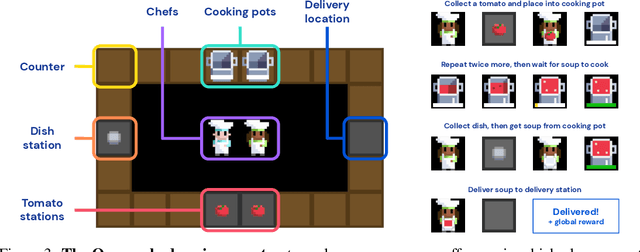
Collaborating with humans requires rapidly adapting to their individual strengths, weaknesses, and preferences. Unfortunately, most standard multi-agent reinforcement learning techniques, such as self-play (SP) or population play (PP), produce agents that overfit to their training partners and do not generalize well to humans. Alternatively, researchers can collect human data, train a human model using behavioral cloning, and then use that model to train "human-aware" agents ("behavioral cloning play", or BCP). While such an approach can improve the generalization of agents to new human co-players, it involves the onerous and expensive step of collecting large amounts of human data first. Here, we study the problem of how to train agents that collaborate well with human partners without using human data. We argue that the crux of the problem is to produce a diverse set of training partners. Drawing inspiration from successful multi-agent approaches in competitive domains, we find that a surprisingly simple approach is highly effective. We train our agent partner as the best response to a population of self-play agents and their past checkpoints taken throughout training, a method we call Fictitious Co-Play (FCP). Our experiments focus on a two-player collaborative cooking simulator that has recently been proposed as a challenge problem for coordination with humans. We find that FCP agents score significantly higher than SP, PP, and BCP when paired with novel agent and human partners. Furthermore, humans also report a strong subjective preference to partnering with FCP agents over all baselines.
Deep reinforcement learning models the emergent dynamics of human cooperation
Mar 08, 2021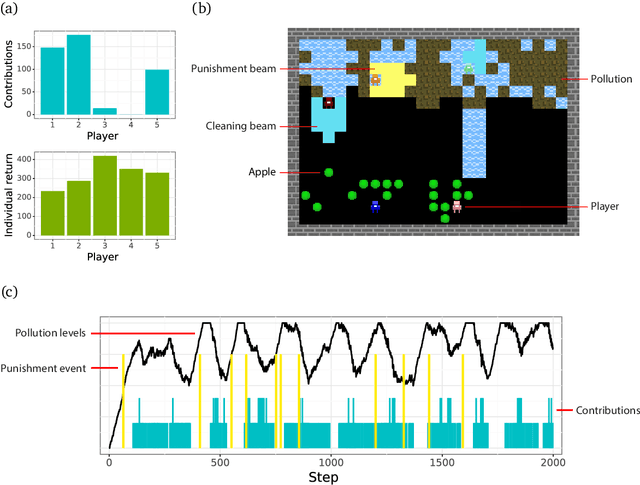
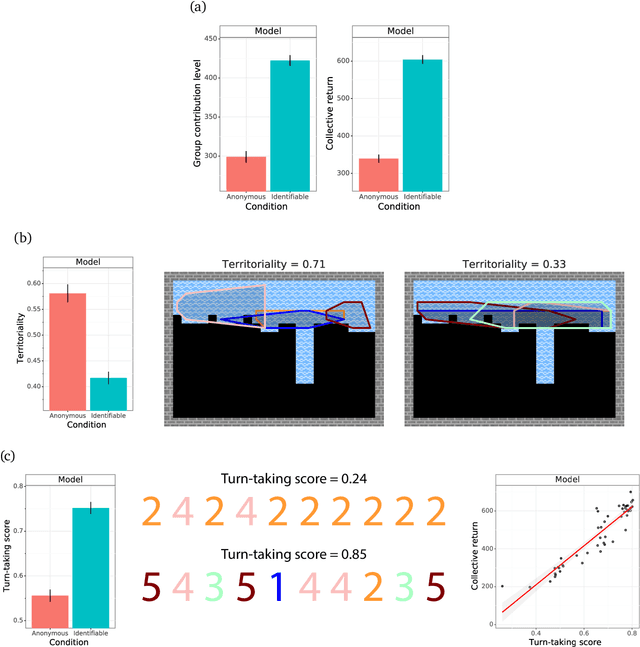
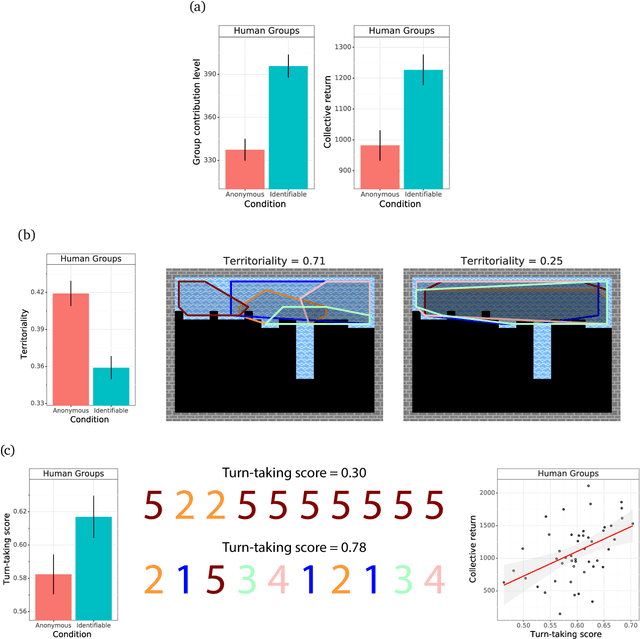
Collective action demands that individuals efficiently coordinate how much, where, and when to cooperate. Laboratory experiments have extensively explored the first part of this process, demonstrating that a variety of social-cognitive mechanisms influence how much individuals choose to invest in group efforts. However, experimental research has been unable to shed light on how social cognitive mechanisms contribute to the where and when of collective action. We leverage multi-agent deep reinforcement learning to model how a social-cognitive mechanism--specifically, the intrinsic motivation to achieve a good reputation--steers group behavior toward specific spatial and temporal strategies for collective action in a social dilemma. We also collect behavioral data from groups of human participants challenged with the same dilemma. The model accurately predicts spatial and temporal patterns of group behavior: in this public goods dilemma, the intrinsic motivation for reputation catalyzes the development of a non-territorial, turn-taking strategy to coordinate collective action.
Quantifying environment and population diversity in multi-agent reinforcement learning
Feb 16, 2021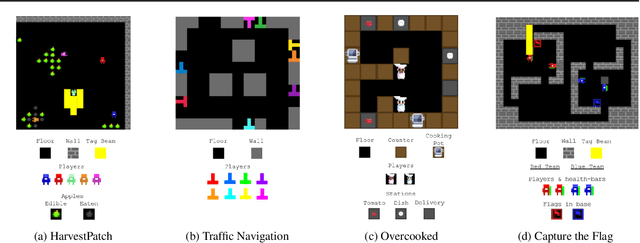

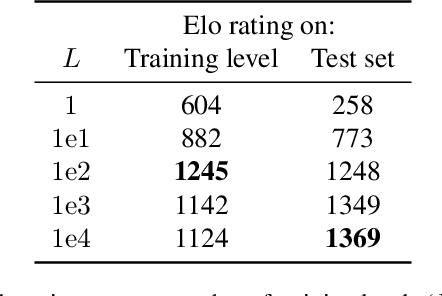
Generalization is a major challenge for multi-agent reinforcement learning. How well does an agent perform when placed in novel environments and in interactions with new co-players? In this paper, we investigate and quantify the relationship between generalization and diversity in the multi-agent domain. Across the range of multi-agent environments considered here, procedurally generating training levels significantly improves agent performance on held-out levels. However, agent performance on the specific levels used in training sometimes declines as a result. To better understand the effects of co-player variation, our experiments introduce a new environment-agnostic measure of behavioral diversity. Results demonstrate that population size and intrinsic motivation are both effective methods of generating greater population diversity. In turn, training with a diverse set of co-players strengthens agent performance in some (but not all) cases.
Fairness for Unobserved Characteristics: Insights from Technological Impacts on Queer Communities
Feb 09, 2021Advances in algorithmic fairness have largely omitted sexual orientation and gender identity. We explore queer concerns in privacy, censorship, language, online safety, health, and employment to study the positive and negative effects of artificial intelligence on queer communities. These issues underscore the need for new directions in fairness research that take into account a multiplicity of considerations, from privacy preservation, context sensitivity and process fairness, to an awareness of sociotechnical impact and the increasingly important role of inclusive and participatory research processes. Most current approaches for algorithmic fairness assume that the target characteristics for fairness--frequently, race and legal gender--can be observed or recorded. Sexual orientation and gender identity are prototypical instances of unobserved characteristics, which are frequently missing, unknown or fundamentally unmeasurable. This paper highlights the importance of developing new approaches for algorithmic fairness that break away from the prevailing assumption of observed characteristics.
Neural Recursive Belief States in Multi-Agent Reinforcement Learning
Feb 03, 2021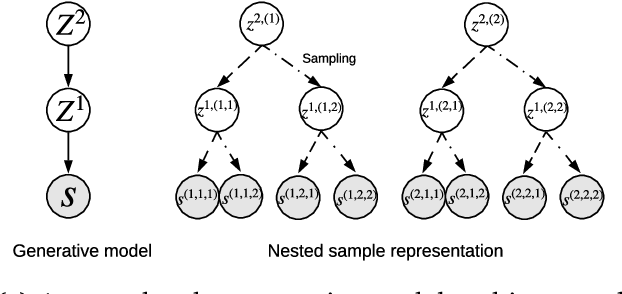
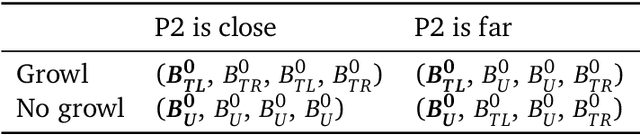
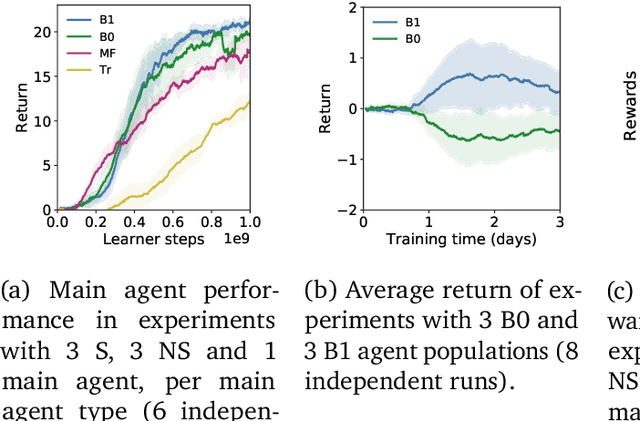
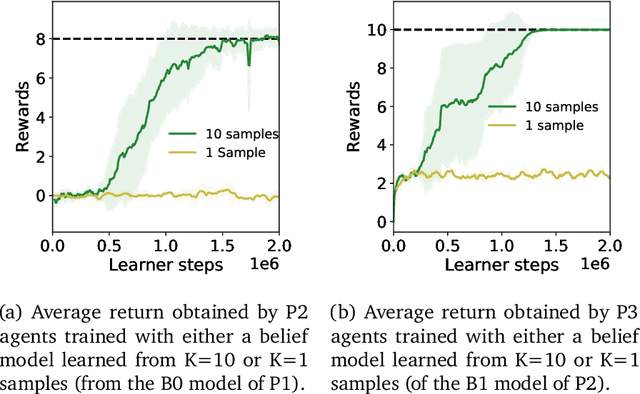
In multi-agent reinforcement learning, the problem of learning to act is particularly difficult because the policies of co-players may be heavily conditioned on information only observed by them. On the other hand, humans readily form beliefs about the knowledge possessed by their peers and leverage beliefs to inform decision-making. Such abilities underlie individual success in a wide range of Markov games, from bluffing in Poker to conditional cooperation in the Prisoner's Dilemma, to convention-building in Bridge. Classical methods are usually not applicable to complex domains due to the intractable nature of hierarchical beliefs (i.e. beliefs of other agents' beliefs). We propose a scalable method to approximate these belief structures using recursive deep generative models, and to use the belief models to obtain representations useful to acting in complex tasks. Our agents trained with belief models outperform model-free baselines with equivalent representational capacity using common training paradigms. We also show that higher-order belief models outperform agents with lower-order models.
Open Problems in Cooperative AI
Dec 15, 2020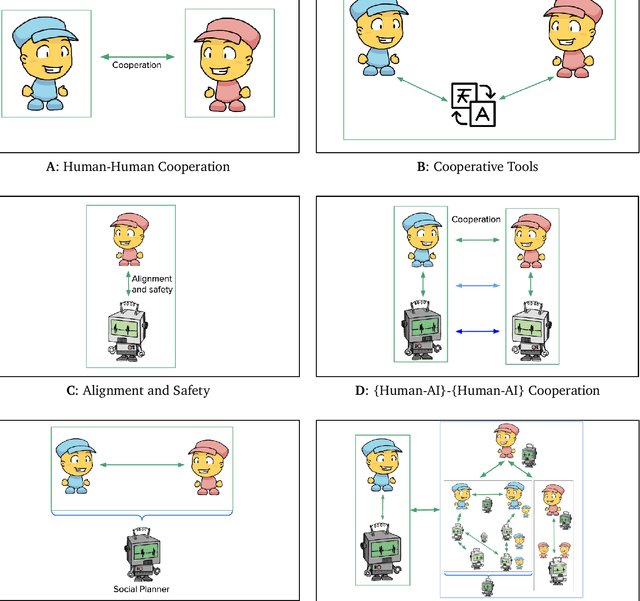
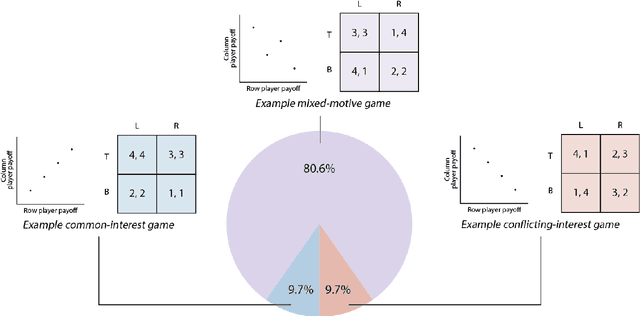

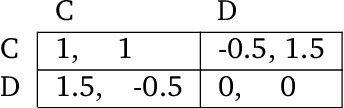
Problems of cooperation--in which agents seek ways to jointly improve their welfare--are ubiquitous and important. They can be found at scales ranging from our daily routines--such as driving on highways, scheduling meetings, and working collaboratively--to our global challenges--such as peace, commerce, and pandemic preparedness. Arguably, the success of the human species is rooted in our ability to cooperate. Since machines powered by artificial intelligence are playing an ever greater role in our lives, it will be important to equip them with the capabilities necessary to cooperate and to foster cooperation. We see an opportunity for the field of artificial intelligence to explicitly focus effort on this class of problems, which we term Cooperative AI. The objective of this research would be to study the many aspects of the problems of cooperation and to innovate in AI to contribute to solving these problems. Central goals include building machine agents with the capabilities needed for cooperation, building tools to foster cooperation in populations of (machine and/or human) agents, and otherwise conducting AI research for insight relevant to problems of cooperation. This research integrates ongoing work on multi-agent systems, game theory and social choice, human-machine interaction and alignment, natural-language processing, and the construction of social tools and platforms. However, Cooperative AI is not the union of these existing areas, but rather an independent bet about the productivity of specific kinds of conversations that involve these and other areas. We see opportunity to more explicitly focus on the problem of cooperation, to construct unified theory and vocabulary, and to build bridges with adjacent communities working on cooperation, including in the natural, social, and behavioural sciences.
Social diversity and social preferences in mixed-motive reinforcement learning
Feb 12, 2020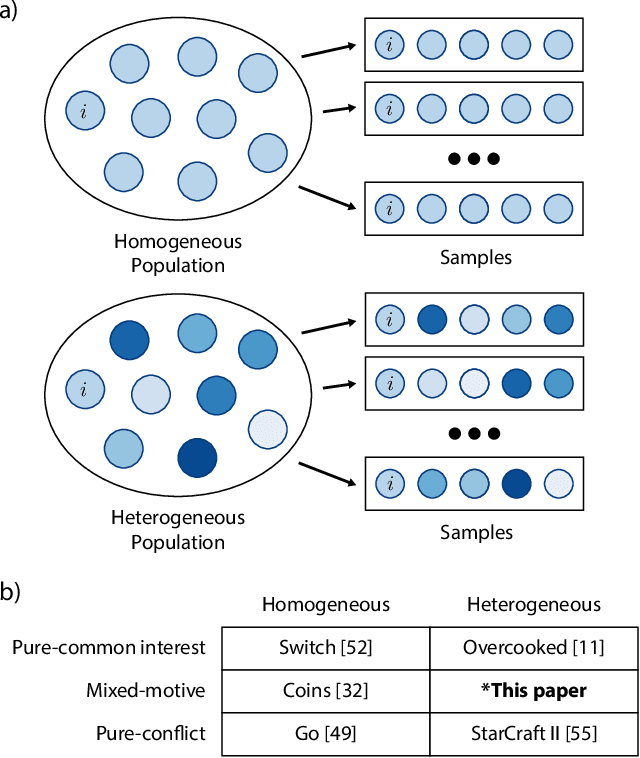
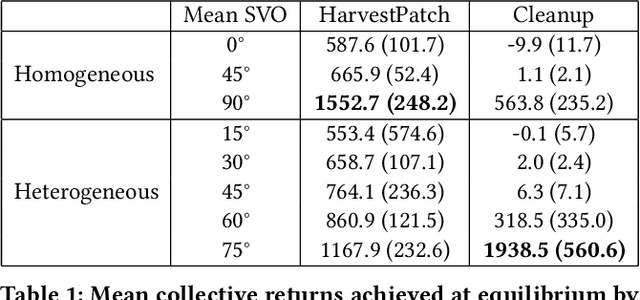
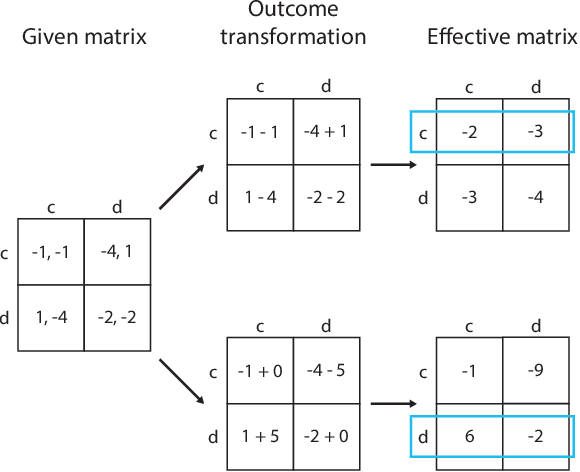
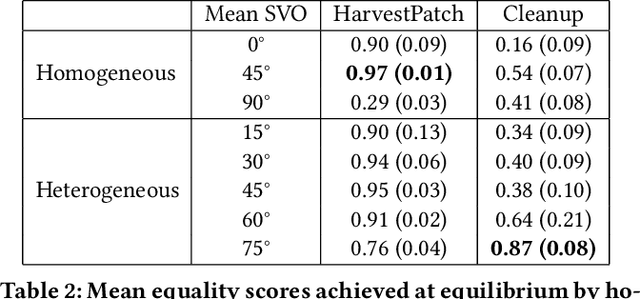
Recent research on reinforcement learning in pure-conflict and pure-common interest games has emphasized the importance of population heterogeneity. In contrast, studies of reinforcement learning in mixed-motive games have primarily leveraged homogeneous approaches. Given the defining characteristic of mixed-motive games--the imperfect correlation of incentives between group members--we study the effect of population heterogeneity on mixed-motive reinforcement learning. We draw on interdependence theory from social psychology and imbue reinforcement learning agents with Social Value Orientation (SVO), a flexible formalization of preferences over group outcome distributions. We subsequently explore the effects of diversity in SVO on populations of reinforcement learning agents in two mixed-motive Markov games. We demonstrate that heterogeneity in SVO generates meaningful and complex behavioral variation among agents similar to that suggested by interdependence theory. Empirical results in these mixed-motive dilemmas suggest agents trained in heterogeneous populations develop particularly generalized, high-performing policies relative to those trained in homogeneous populations.