 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic: Unlocking Long-Context Inference for Diffusion LLMs via Global Memory Planning and Dynamic Peak Taming
Jan 10, 2026Diffusion-based large language models (dLLMs) have emerged as a promising paradigm, utilizing simultaneous denoising to enable global planning and iterative refinement. While these capabilities are particularly advantageous for long-context generation, deploying such models faces a prohibitive memory capacity barrier stemming from severe system inefficiencies. We identify that existing inference systems are ill-suited for this paradigm: unlike autoregressive models constrained by the cumulative KV-cache, dLLMs are bottlenecked by transient activations recomputed at every step. Furthermore, general-purpose memory reuse mechanisms lack the global visibility to adapt to dLLMs' dynamic memory peaks, which toggle between logits and FFNs. To address these mismatches, we propose Mosaic, a memory-efficient inference system that shifts from local, static management to a global, dynamic paradigm. Mosaic integrates a mask-only logits kernel to eliminate redundancy, a lazy chunking optimizer driven by an online heuristic search to adaptively mitigate dynamic peaks, and a global memory manager to resolve fragmentation via virtual addressing. Extensive evaluations demonstrate that Mosaic achieves an average 2.71$\times$ reduction in the memory peak-to-average ratio and increases the maximum inference sequence length supportable on identical hardware by 15.89-32.98$\times$. This scalability is achieved without compromising accuracy and speed, and in fact reducing latency by 4.12%-23.26%.
RAGPulse: An Open-Source RAG Workload Trace to Optimize RAG Serving Systems
Nov 17, 2025Retrieval-Augmented Generation (RAG) is a critical paradigm for building reliable, knowledge-intensive Large Language Model (LLM) applications. However, the multi-stage pipeline (retrieve, generate) and unique workload characteristics (e.g., knowledge dependency) of RAG systems pose significant challenges for serving performance optimization. Existing generic LLM inference traces fail to capture these RAG-specific dynamics, creating a significant performance gap between academic research and real-world deployment. To bridge this gap, this paper introduces RAGPulse, an open-source RAG workload trace dataset. This dataset was collected from an university-wide Q&A system serving that has served more than 40,000 students and faculties since April 2024. We detail RAGPulse's system architecture, its privacy-preserving hash-based data format, and provide an in-depth statistical analysis. Our analysis reveals that real-world RAG workloads exhibit significant temporal locality and a highly skewed hot document access pattern. RAGPulse provides a high-fidelity foundation for researchers to develop and validate novel optimization strategies for RAG systems, such as content-aware batching and retrieval caching, ultimately enhancing the efficiency and reliability of RAG services. The code is available at https://github.com/flashserve/RAGPulse.
A Comprehensive Study on Learning-Based PE Malware Family Classification Methods
Oct 29, 2021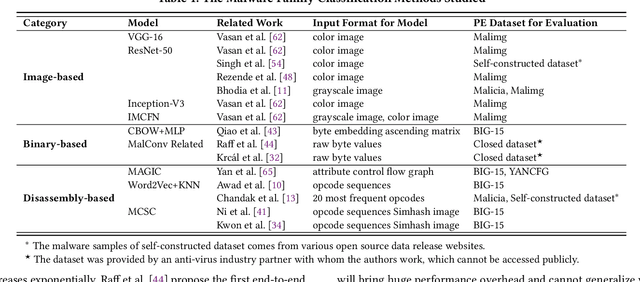
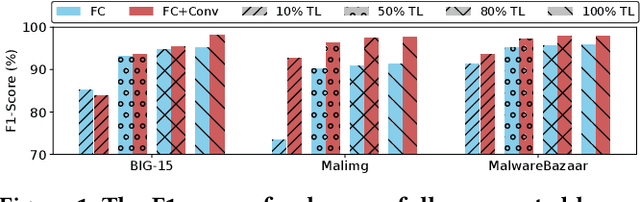
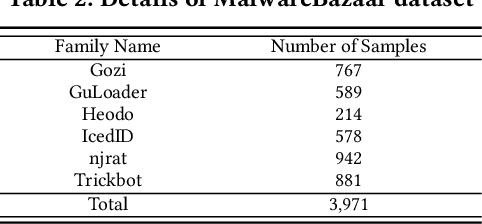
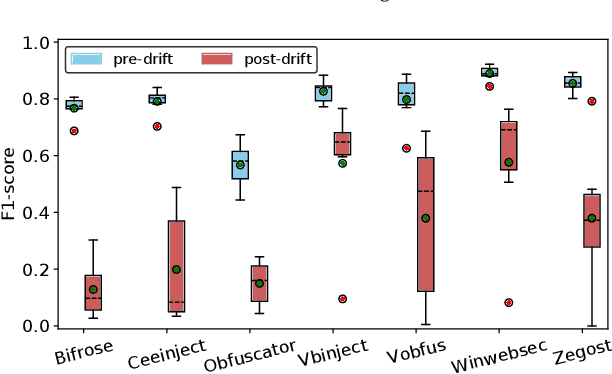
Driven by the high profit, Portable Executable (PE) malware has been consistently evolving in terms of both volume and sophistication. PE malware family classification has gained great attention and a large number of approaches have been proposed. With the rapid development of machine learning techniques and the exciting results they achieved on various tasks, machine learning algorithms have also gained popularity in the PE malware family classification task. Three mainstream approaches that use learning based algorithms, as categorized by the input format the methods take, are image-based, binary-based and disassembly-based approaches. Although a large number of approaches are published, there is no consistent comparisons on those approaches, especially from the practical industry adoption perspective. Moreover, there is no comparison in the scenario of concept drift, which is a fact for the malware classification task due to the fast evolving nature of malware. In this work, we conduct a thorough empirical study on learning-based PE malware classification approaches on 4 different datasets and consistent experiment settings. Based on the experiment results and an interview with our industry partners, we find that (1) there is no individual class of methods that significantly outperforms the others; (2) All classes of methods show performance degradation on concept drift (by an average F1-score of 32.23%); and (3) the prediction time and high memory consumption hinder existing approaches from being adopted for industry usage.
Federated Learning in Smart Cities: A Comprehensive Survey
Feb 02, 2021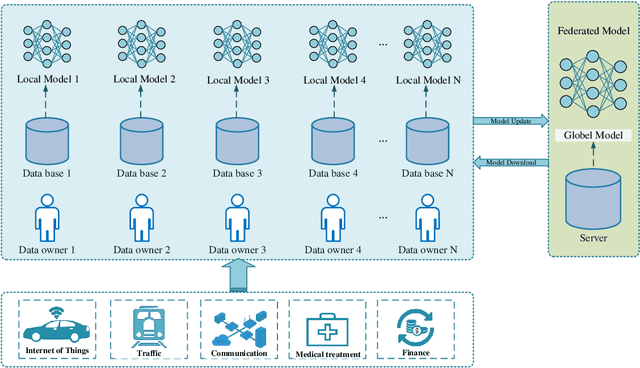
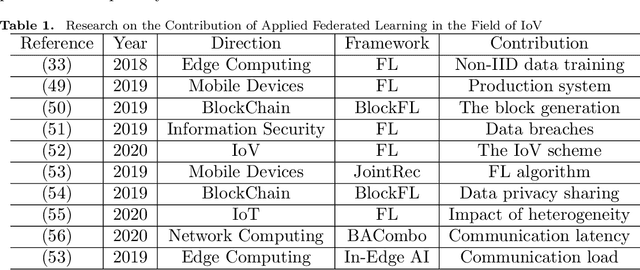
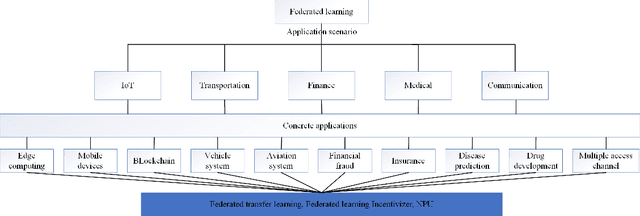
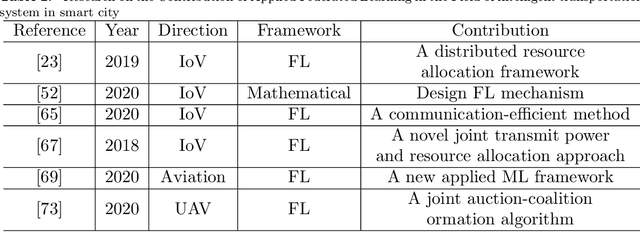
Federated learning plays an important role in the process of smart cities. With the development of big data and artificial intelligence, there is a problem of data privacy protection in this process. Federated learning is capable of solving this problem. This paper starts with the current developments of federated learning and its applications in various fields. We conduct a comprehensive investigation. This paper summarize the latest research on the application of federated learning in various fields of smart cities. In-depth understanding of the current development of federated learning from the Internet of Things, transportation, communications, finance, medical and other fields. Before that, we introduce the background, definition and key technologies of federated learning. Further more, we review the key technologies and the latest results. Finally, we discuss the future applications and research directions of federated learning in smart cities.