 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLag Operator SSMs: A Geometric Framework for Structured State Space Modeling
Dec 22, 2025



Structured State Space Models (SSMs), which are at the heart of the recently popular Mamba architecture, are powerful tools for sequence modeling. However, their theoretical foundation relies on a complex, multi-stage process of continuous-time modeling and subsequent discretization, which can obscure intuition. We introduce a direct, first-principles framework for constructing discrete-time SSMs that is both flexible and modular. Our approach is based on a novel lag operator, which geometrically derives the discrete-time recurrence by measuring how the system's basis functions "slide" and change from one timestep to the next. The resulting state matrices are computed via a single inner product involving this operator, offering a modular design space for creating novel SSMs by flexibly combining different basis functions and time-warping schemes. To validate our approach, we demonstrate that a specific instance exactly recovers the recurrence of the influential HiPPO model. Numerical simulations confirm our derivation, providing new theoretical tools for designing flexible and robust sequence models.
Curiosity-Driven Co-Development of Action and Language in Robots Through Self-Exploration
Oct 06, 2025Human infants acquire language and action co-developmentally, achieving remarkable generalization capabilities from only a minimal number of learning examples. In contrast, recent large language models require exposure to billions of training tokens to achieve such generalization. What mechanisms underlie such efficient developmental learning in humans? This study addresses this question through simulation experiments in which robots learn to perform various actions corresponding to imperative sentences (e.g., \textit{push red cube}) via trials of self-guided exploration. Our approach integrates the active inference framework with reinforcement learning, enabling curiosity-driven developmental learning. The simulations yielded several nontrivial findings: i) Curiosity-driven exploration combined with motor noise substantially outperforms learning without curiosity. ii) Simpler, prerequisite-like actions emerge earlier in development, while more complex actions involving these prerequisites develop later. iii) Rote pairing of sentences and actions occurs before the emergence of compositional generalization. iv) Generalization is drastically improved as the number of compositional elements increases. These results shed light into possible mechanisms underlying efficient co-developmental learning in infants and provide computational parallels to findings in developmental psychology.
Estimating Exoplanet Mass using Machine Learning on Incomplete Datasets
Oct 09, 2024



The exoplanet archive is an incredible resource of information on the properties of discovered extrasolar planets, but statistical analysis has been limited by the number of missing values. One of the most informative bulk properties is planet mass, which is particularly challenging to measure with more than 70\% of discovered planets with no measured value. We compare the capabilities of five different machine learning algorithms that can utilize multidimensional incomplete datasets to estimate missing properties for imputing planet mass. The results are compared when using a partial subset of the archive with a complete set of six planet properties, and where all planet discoveries are leveraged in an incomplete set of six and eight planet properties. We find that imputation results improve with more data even when the additional data is incomplete, and allows a mass prediction for any planet regardless of which properties are known. Our favored algorithm is the newly developed $k$NN$\times$KDE, which can return a probability distribution for the imputed properties. The shape of this distribution can indicate the algorithm's level of confidence, and also inform on the underlying demographics of the exoplanet population. We demonstrate how the distributions can be interpreted with a series of examples for planets where the discovery was made with either the transit method, or radial velocity method. Finally, we test the generative capability of the $k$NN$\times$KDE to create a large synthetic population of planets based on the archive, and identify potential categories of planets from groups of properties in the multidimensional space. All codes are Open Source.
Evolution of Rewards for Food and Motor Action by Simulating Birth and Death
Jun 21, 2024



The reward system is one of the fundamental drivers of animal behaviors and is critical for survival and reproduction. Despite its importance, the problem of how the reward system has evolved is underexplored. In this paper, we try to replicate the evolution of biologically plausible reward functions and investigate how environmental conditions affect evolved rewards' shape. For this purpose, we developed a population-based decentralized evolutionary simulation framework, where agents maintain their energy level to live longer and produce more children. Each agent inherits its reward function from its parent subject to mutation and learns to get rewards via reinforcement learning throughout its lifetime. Our results show that biologically reasonable positive rewards for food acquisition and negative rewards for motor action can evolve from randomly initialized ones. However, we also find that the rewards for motor action diverge into two modes: largely positive and slightly negative. The emergence of positive motor action rewards is surprising because it can make agents too active and inefficient in foraging. In environments with poor and poisonous foods, the evolution of rewards for less important foods tends to be unstable, while rewards for normal foods are still stable. These results demonstrate the usefulness of our simulation environment and energy-dependent birth and death model for further studies of the origin of reward systems.
Intrinsic Rewards for Exploration without Harm from Observational Noise: A Simulation Study Based on the Free Energy Principle
May 13, 2024In Reinforcement Learning (RL), artificial agents are trained to maximize numerical rewards by performing tasks. Exploration is essential in RL because agents must discover information before exploiting it. Two rewards encouraging efficient exploration are the entropy of action policy and curiosity for information gain. Entropy is well-established in literature, promoting randomized action selection. Curiosity is defined in a broad variety of ways in literature, promoting discovery of novel experiences. One example, prediction error curiosity, rewards agents for discovering observations they cannot accurately predict. However, such agents may be distracted by unpredictable observational noises known as curiosity traps. Based on the Free Energy Principle (FEP), this paper proposes hidden state curiosity, which rewards agents by the KL divergence between the predictive prior and posterior probabilities of latent variables. We trained six types of agents to navigate mazes: baseline agents without rewards for entropy or curiosity, and agents rewarded for entropy and/or either prediction error curiosity or hidden state curiosity. We find entropy and curiosity result in efficient exploration, especially both employed together. Notably, agents with hidden state curiosity demonstrate resilience against curiosity traps, which hinder agents with prediction error curiosity. This suggests implementing the FEP may enhance the robustness and generalization of RL models, potentially aligning the learning processes of artificial and biological agents.
Numerical Data Imputation for Multimodal Data Sets: A Probabilistic Nearest-Neighbor Kernel Density Approach
Jul 10, 2023Numerical data imputation algorithms replace missing values by estimates to leverage incomplete data sets. Current imputation methods seek to minimize the error between the unobserved ground truth and the imputed values. But this strategy can create artifacts leading to poor imputation in the presence of multimodal or complex distributions. To tackle this problem, we introduce the $k$NN$\times$KDE algorithm: a data imputation method combining nearest neighbor estimation ($k$NN) and density estimation with Gaussian kernels (KDE). We compare our method with previous data imputation methods using artificial and real-world data with different data missing scenarios and various data missing rates, and show that our method can cope with complex original data structure, yields lower data imputation errors, and provides probabilistic estimates with higher likelihood than current methods. We release the code in open-source for the community: https://github.com/DeltaFloflo/knnxkde
* 30 pages, 8 figures, accepted in TMLR (Reproducibility certification)
Habits and goals in synergy: a variational Bayesian framework for behavior
Apr 11, 2023How to behave efficiently and flexibly is a central problem for understanding biological agents and creating intelligent embodied AI. It has been well known that behavior can be classified as two types: reward-maximizing habitual behavior, which is fast while inflexible; and goal-directed behavior, which is flexible while slow. Conventionally, habitual and goal-directed behaviors are considered handled by two distinct systems in the brain. Here, we propose to bridge the gap between the two behaviors, drawing on the principles of variational Bayesian theory. We incorporate both behaviors in one framework by introducing a Bayesian latent variable called "intention". The habitual behavior is generated by using prior distribution of intention, which is goal-less; and the goal-directed behavior is generated by the posterior distribution of intention, which is conditioned on the goal. Building on this idea, we present a novel Bayesian framework for modeling behaviors. Our proposed framework enables skill sharing between the two kinds of behaviors, and by leveraging the idea of predictive coding, it enables an agent to seamlessly generalize from habitual to goal-directed behavior without requiring additional training. The proposed framework suggests a fresh perspective for cognitive science and embodied AI, highlighting the potential for greater integration between habitual and goal-directed behaviors.
Goal-Directed Planning by Reinforcement Learning and Active Inference
Jun 22, 2021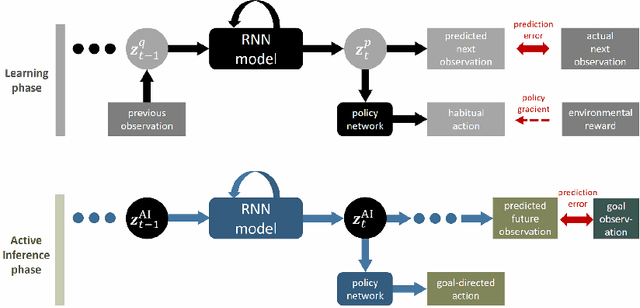
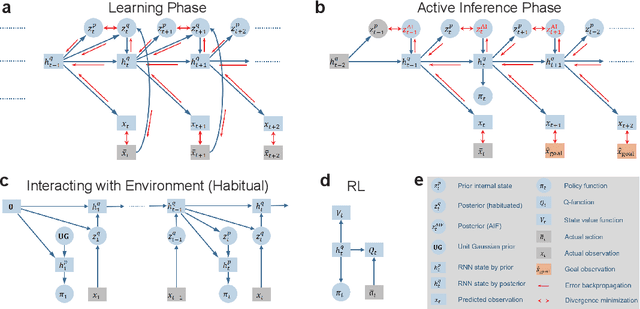
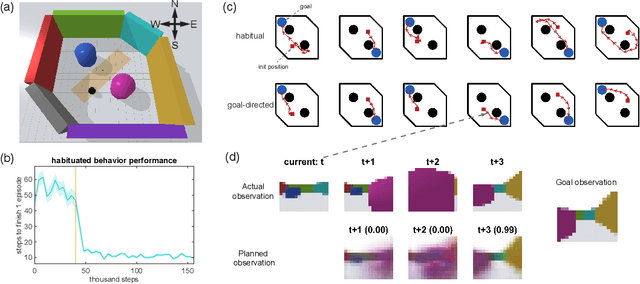
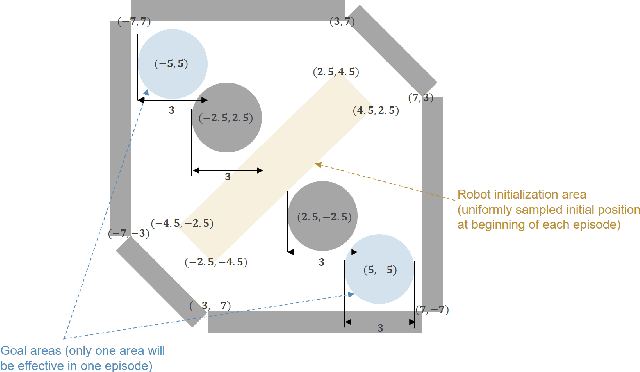
What is the difference between goal-directed and habitual behavior? We propose a novel computational framework of decision making with Bayesian inference, in which everything is integrated as an entire neural network model. The model learns to predict environmental state transitions by self-exploration and generating motor actions by sampling stochastic internal states ${z}$. Habitual behavior, which is obtained from the prior distribution of ${z}$, is acquired by reinforcement learning. Goal-directed behavior is determined from the posterior distribution of ${z}$ by planning, using active inference which optimizes the past, current and future ${z}$ by minimizing the variational free energy for the desired future observation constrained by the observed sensory sequence. We demonstrate the effectiveness of the proposed framework by experiments in a sensorimotor navigation task with camera observations and continuous motor actions.
Whole brain Probabilistic Generative Model toward Realizing Cognitive Architecture for Developmental Robots
Mar 15, 2021Building a humanlike integrative artificial cognitive system, that is, an artificial general intelligence, is one of the goals in artificial intelligence and developmental robotics. Furthermore, a computational model that enables an artificial cognitive system to achieve cognitive development will be an excellent reference for brain and cognitive science. This paper describes the development of a cognitive architecture using probabilistic generative models (PGMs) to fully mirror the human cognitive system. The integrative model is called a whole-brain PGM (WB-PGM). It is both brain-inspired and PGMbased. In this paper, the process of building the WB-PGM and learning from the human brain to build cognitive architectures is described.
Imitation learning based on entropy-regularized forward and inverse reinforcement learning
Aug 17, 2020
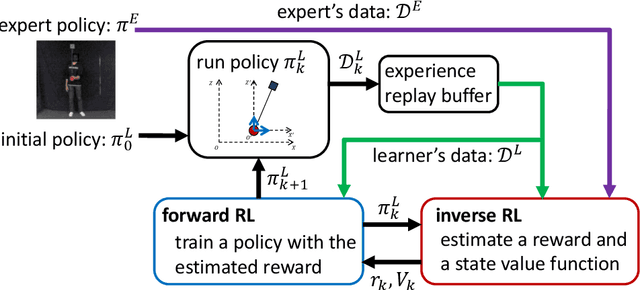

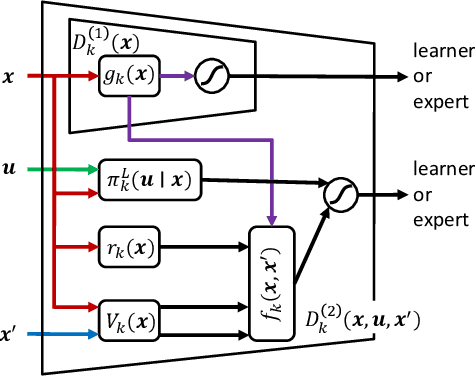
This paper proposes Entropy-Regularized Imitation Learning (ERIL), which is a combination of forward and inverse reinforcement learning under the framework of the entropy-regularized Markov decision process. ERIL minimizes the reverse Kullback-Leibler (KL) divergence between two probability distributions induced by a learner and an expert. Inverse reinforcement learning (RL) in ERIL evaluates the log-ratio between two distributions using the density ratio trick, which is widely used in generative adversarial networks. More specifically, the log-ratio is estimated by building two binary discriminators. The first discriminator is a state-only function, and it tries to distinguish the state generated by the forward RL step from the expert's state. The second discriminator is a function of current state, action, and transitioned state, and it distinguishes the generated experiences from the ones provided by the expert. Since the second discriminator has the same hyperparameters of the forward RL step, it can be used to control the discriminator's ability. The forward RL minimizes the reverse KL estimated by the inverse RL. We show that minimizing the reverse KL divergence is equivalent to finding an optimal policy under entropy regularization. Consequently, a new policy is derived from an algorithm that resembles Dynamic Policy Programming and Soft Actor-Critic. Our experimental results on MuJoCo-simulated environments show that ERIL is more sample-efficient than such previous methods. We further apply the method to human behaviors in performing a pole-balancing task and show that the estimated reward functions show how every subject achieves the goal.