 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Tutoring for Developmental Motor Learning in Robots: Co-Developed Interaction Dynamics Support Stable Learning
Jun 18, 2026Infants are well known to develop their motor skills through dense interaction with caregivers. Although such social interaction is crucial for human development, motor-skill learning in robots is often treated as a unidirectional process in which robots passively receive demonstrations from tutors. This overlooks a key property of social interaction: it is inherently bidirectional, with tutor and learner dynamically adapting to each other. In such interactions, the robot's past experiences may function as prior constraints that shape the dynamics of their co-developed trajectories. We hypothesize that bidirectional tutoring allows such constraints to guide the formation of consistent behavioral patterns that preserve behavioral coherence and support generalization, whereas unidirectional interaction lacks such constraints and leads to broader, less consistent behavioral patterns. To examine this hypothesis, we conducted two experiments with a physical humanoid robot performing an object manipulation task: one involving human-robot interaction and another employing an AI tutor interacting with the real robot through an adaptive intervention mechanism designed to examine whether similar effects would emerge under more controlled conditions. We implement the developmental learning framework using a free-energy-principle-based neural network extended with generative replay, which supports stable sequence-by-sequence learning from single tutored episodes. Across both settings, bidirectional tutoring fostered consistent behaviors and stage-wise generalization, while the robot gradually required less tutor guidance. These results suggest that bidirectional tutoring, as an embodied and socially grounded approach, provides an effective scaffold for developmental motor learning in robots.
Curiosity-Driven Co-Development of Action and Language in Robots Through Self-Exploration
Oct 06, 2025Human infants acquire language and action co-developmentally, achieving remarkable generalization capabilities from only a minimal number of learning examples. In contrast, recent large language models require exposure to billions of training tokens to achieve such generalization. What mechanisms underlie such efficient developmental learning in humans? This study addresses this question through simulation experiments in which robots learn to perform various actions corresponding to imperative sentences (e.g., \textit{push red cube}) via trials of self-guided exploration. Our approach integrates the active inference framework with reinforcement learning, enabling curiosity-driven developmental learning. The simulations yielded several nontrivial findings: i) Curiosity-driven exploration combined with motor noise substantially outperforms learning without curiosity. ii) Simpler, prerequisite-like actions emerge earlier in development, while more complex actions involving these prerequisites develop later. iii) Rote pairing of sentences and actions occurs before the emergence of compositional generalization. iv) Generalization is drastically improved as the number of compositional elements increases. These results shed light into possible mechanisms underlying efficient co-developmental learning in infants and provide computational parallels to findings in developmental psychology.
Modeling Autonomous Shifts Between Focus State and Mind-Wandering Using a Predictive-Coding-Inspired Variational RNN Model
Dec 20, 2024The current study investigates possible neural mechanisms underling autonomous shifts between focus state and mind-wandering by conducting model simulation experiments. On this purpose, we modeled perception processes of continuous sensory sequences using our previous proposed variational RNN model which was developed based on the free energy principle. The current study extended this model by introducing an adaptation mechanism of a meta-level parameter, referred to as the meta-prior $\mathbf{w}$, which regulates the complexity term in the free energy. Our simulation experiments demonstrated that autonomous shifts between focused perception and mind-wandering take place when $\mathbf{w}$ switches between low and high values associated with decrease and increase of the average reconstruction error over the past window. In particular, high $\mathbf{w}$ prioritized top-down predictions while low $\mathbf{w}$ emphasized bottom-up sensations. This paper explores how our experiment results align with existing studies and highlights their potential for future research.
Life, uh, Finds a Way: Systematic Neural Search
Oct 02, 2024



We tackle the challenge of rapidly adapting an agent's behavior to solve spatiotemporally continuous problems in novel settings. Animals exhibit extraordinary abilities to adapt to new contexts, a capacity unmatched by artificial systems. Instead of focusing on generalization through deep reinforcement learning, we propose viewing behavior as the physical manifestation of a search procedure, where robust problem-solving emerges from an exhaustive search across all possible behaviors. Surprisingly, this can be done efficiently using online modification of a cognitive graph that guides action, challenging the predominant view that exhaustive search in continuous spaces is impractical. We describe an algorithm that implicitly enumerates behaviors by regulating the tight feedback loop between execution of behaviors and mutation of the graph, and provide a neural implementation based on Hebbian learning and a novel high-dimensional harmonic representation inspired by entorhinal cortex. By framing behavior as search, we provide a mathematically simple and biologically plausible model for real-time behavioral adaptation, successfully solving a variety of continuous state-space navigation problems. This framework not only offers a flexible neural substrate for other applications but also presents a powerful paradigm for understanding adaptive behavior. Our results suggest potential advancements in developmental learning and unsupervised skill acquisition, paving the way for autonomous robots to master complex skills in data-sparse environments demanding flexibility.
Intrinsic Rewards for Exploration without Harm from Observational Noise: A Simulation Study Based on the Free Energy Principle
May 13, 2024In Reinforcement Learning (RL), artificial agents are trained to maximize numerical rewards by performing tasks. Exploration is essential in RL because agents must discover information before exploiting it. Two rewards encouraging efficient exploration are the entropy of action policy and curiosity for information gain. Entropy is well-established in literature, promoting randomized action selection. Curiosity is defined in a broad variety of ways in literature, promoting discovery of novel experiences. One example, prediction error curiosity, rewards agents for discovering observations they cannot accurately predict. However, such agents may be distracted by unpredictable observational noises known as curiosity traps. Based on the Free Energy Principle (FEP), this paper proposes hidden state curiosity, which rewards agents by the KL divergence between the predictive prior and posterior probabilities of latent variables. We trained six types of agents to navigate mazes: baseline agents without rewards for entropy or curiosity, and agents rewarded for entropy and/or either prediction error curiosity or hidden state curiosity. We find entropy and curiosity result in efficient exploration, especially both employed together. Notably, agents with hidden state curiosity demonstrate resilience against curiosity traps, which hinder agents with prediction error curiosity. This suggests implementing the FEP may enhance the robustness and generalization of RL models, potentially aligning the learning processes of artificial and biological agents.
Development of Compositionality and Generalization through Interactive Learning of Language and Action of Robots
Mar 29, 2024



Humans excel at applying learned behavior to unlearned situations. A crucial component of this generalization behavior is our ability to compose/decompose a whole into reusable parts, an attribute known as compositionality. One of the fundamental questions in robotics concerns this characteristic. "How can linguistic compositionality be developed concomitantly with sensorimotor skills through associative learning, particularly when individuals only learn partial linguistic compositions and their corresponding sensorimotor patterns?" To address this question, we propose a brain-inspired neural network model that integrates vision, proprioception, and language into a framework of predictive coding and active inference, based on the free-energy principle. The effectiveness and capabilities of this model were assessed through various simulation experiments conducted with a robot arm. Our results show that generalization in learning to unlearned verb-noun compositions, is significantly enhanced when training variations of task composition are increased. We attribute this to self-organized compositional structures in linguistic latent state space being influenced significantly by sensorimotor learning. Ablation studies show that visual attention and working memory are essential to accurately generate visuo-motor sequences to achieve linguistically represented goals. These insights advance our understanding of mechanisms underlying development of compositionality through interactions of linguistic and sensorimotor experience.
Comparing Generalization in Learning with Limited Numbers of Exemplars: Transformer vs. RNN in Attractor Dynamics
Nov 15, 2023



ChatGPT, a widely-recognized large language model (LLM), has recently gained substantial attention for its performance scaling, attributed to the billions of web-sourced natural language sentences used for training. Its underlying architecture, Transformer, has found applications across diverse fields, including video, audio signals, and robotic movement. %The crucial question this raises concerns the Transformer's generalization-in-learning (GIL) capacity. However, this raises a crucial question about Transformer's generalization in learning (GIL) capacity. Is ChatGPT's success chiefly due to the vast dataset used for training, or is there more to the story? To investigate this, we compared Transformer's GIL capabilities with those of a traditional Recurrent Neural Network (RNN) in tasks involving attractor dynamics learning. For performance evaluation, the Dynamic Time Warping (DTW) method has been employed. Our simulation results suggest that under conditions of limited data availability, Transformer's GIL abilities are markedly inferior to those of RNN.
Habits and goals in synergy: a variational Bayesian framework for behavior
Apr 11, 2023How to behave efficiently and flexibly is a central problem for understanding biological agents and creating intelligent embodied AI. It has been well known that behavior can be classified as two types: reward-maximizing habitual behavior, which is fast while inflexible; and goal-directed behavior, which is flexible while slow. Conventionally, habitual and goal-directed behaviors are considered handled by two distinct systems in the brain. Here, we propose to bridge the gap between the two behaviors, drawing on the principles of variational Bayesian theory. We incorporate both behaviors in one framework by introducing a Bayesian latent variable called "intention". The habitual behavior is generated by using prior distribution of intention, which is goal-less; and the goal-directed behavior is generated by the posterior distribution of intention, which is conditioned on the goal. Building on this idea, we present a novel Bayesian framework for modeling behaviors. Our proposed framework enables skill sharing between the two kinds of behaviors, and by leveraging the idea of predictive coding, it enables an agent to seamlessly generalize from habitual to goal-directed behavior without requiring additional training. The proposed framework suggests a fresh perspective for cognitive science and embodied AI, highlighting the potential for greater integration between habitual and goal-directed behaviors.
Human-Robot Kinaesthetic Interaction Based on Free Energy Principle
Mar 27, 2023The current study investigated possible human-robot kinaesthetic interaction using a variational recurrent neural network model, called PV-RNN, which is based on the free energy principle. Our prior robotic studies using PV-RNN showed that the nature of interactions between top-down expectation and bottom-up inference is strongly affected by a parameter, called the meta-prior, which regulates the complexity term in free energy.The study also compares the counter force generated when trained transitions are induced by a human experimenter and when untrained transitions are induced. Our experimental results indicated that (1) the human experimenter needs more/less force to induce trained transitions when $w$ is set with larger/smaller values, (2) the human experimenter needs more force to act on the robot when he attempts to induce untrained as opposed to trained movement pattern transitions. Our analysis of time development of essential variables and values in PV-RNN during bodily interaction clarified the mechanism by which gaps in actional intentions between the human experimenter and the robot can be manifested as reaction forces between them.
Morphological Wobbling Can Help Robots Learn
May 05, 2022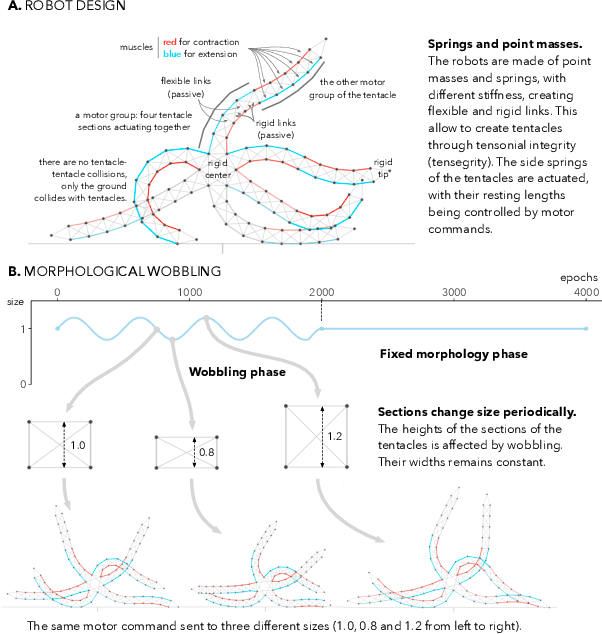
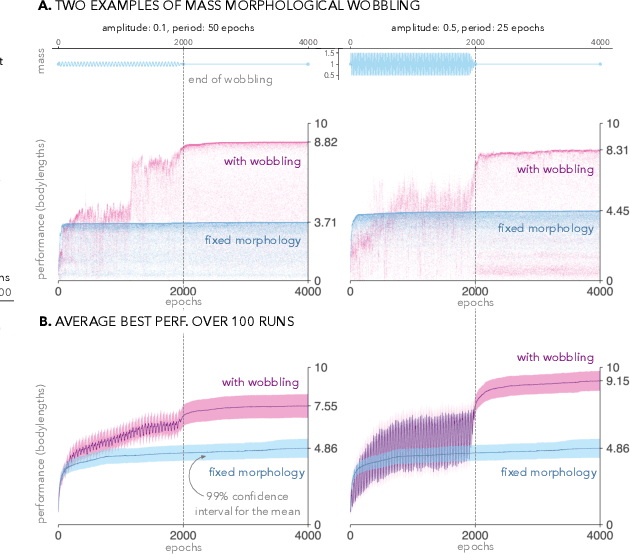
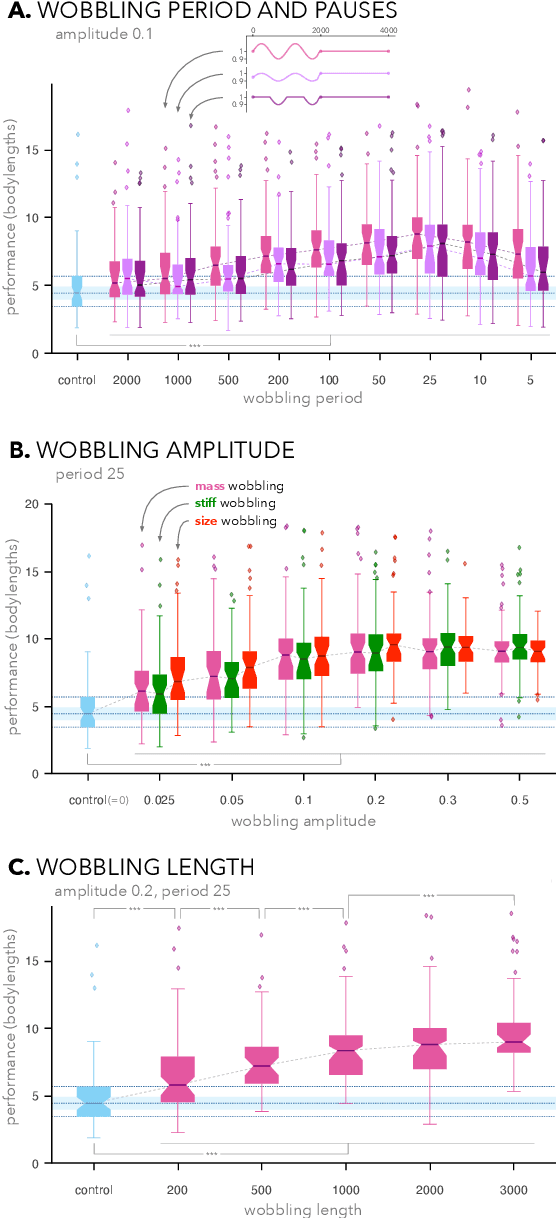
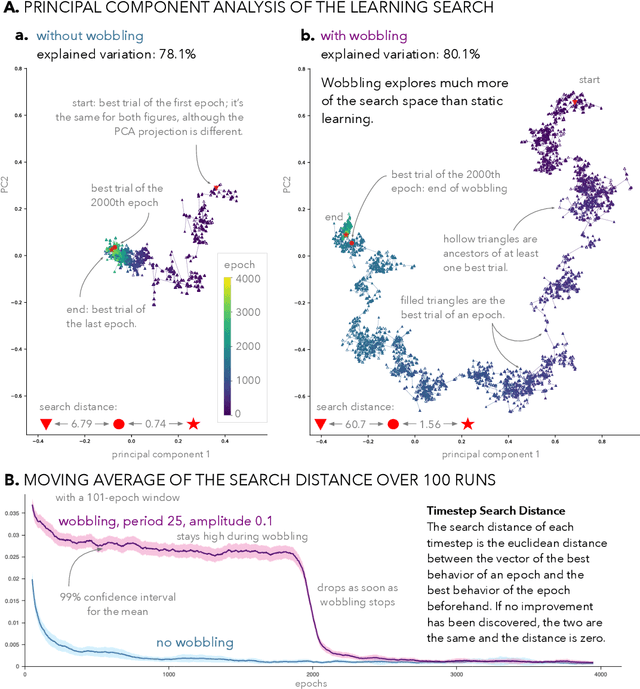
We propose to make the physical characteristics of a robot oscillate while it learns to improve its behavioral performance. We consider quantities such as mass, actuator strength, and size that are usually fixed in a robot, and show that when those quantities oscillate at the beginning of the learning process on a simulated 2D soft robot, the performance on a locomotion task can be significantly improved. We investigate the dynamics of the phenomenon and conclude that in our case, surprisingly, a high-frequency oscillation with a large amplitude for a large portion of the learning duration leads to the highest performance benefits. Furthermore, we show that morphological wobbling significantly increases exploration of the search space.