 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Calibrated Membership Inference Attacks on Medical Image Diffusion Models
Jun 17, 2025The increasing use of diffusion models for image generation, especially in sensitive areas like medical imaging, has raised significant privacy concerns. Membership Inference Attack (MIA) has emerged as a potential approach to determine if a specific image was used to train a diffusion model, thus quantifying privacy risks. Existing MIA methods often rely on diffusion reconstruction errors, where member images are expected to have lower reconstruction errors than non-member images. However, applying these methods directly to medical images faces challenges. Reconstruction error is influenced by inherent image difficulty, and diffusion models struggle with high-frequency detail reconstruction. To address these issues, we propose a Frequency-Calibrated Reconstruction Error (FCRE) method for MIAs on medical image diffusion models. By focusing on reconstruction errors within a specific mid-frequency range and excluding both high-frequency (difficult to reconstruct) and low-frequency (less informative) regions, our frequency-selective approach mitigates the confounding factor of inherent image difficulty. Specifically, we analyze the reverse diffusion process, obtain the mid-frequency reconstruction error, and compute the structural similarity index score between the reconstructed and original images. Membership is determined by comparing this score to a threshold. Experiments on several medical image datasets demonstrate that our FCRE method outperforms existing MIA methods.
Stabilizing Reasoning in Medical LLMs with Continued Pretraining and Reasoning Preference Optimization
Apr 25, 2025



Large Language Models (LLMs) show potential in medicine, yet clinical adoption is hindered by concerns over factual accuracy, language-specific limitations (e.g., Japanese), and critically, their reliability when required to generate reasoning explanations -- a prerequisite for trust. This paper introduces Preferred-MedLLM-Qwen-72B, a 72B-parameter model optimized for the Japanese medical domain to achieve both high accuracy and stable reasoning. We employ a two-stage fine-tuning process on the Qwen2.5-72B base model: first, Continued Pretraining (CPT) on a comprehensive Japanese medical corpus instills deep domain knowledge. Second, Reasoning Preference Optimization (RPO), a preference-based method, enhances the generation of reliable reasoning pathways while preserving high answer accuracy. Evaluations on the Japanese Medical Licensing Exam benchmark (IgakuQA) show Preferred-MedLLM-Qwen-72B achieves state-of-the-art performance (0.868 accuracy), surpassing strong proprietary models like GPT-4o (0.866). Crucially, unlike baseline or CPT-only models which exhibit significant accuracy degradation (up to 11.5\% and 3.8\% respectively on IgakuQA) when prompted for explanations, our model maintains its high accuracy (0.868) under such conditions. This highlights RPO's effectiveness in stabilizing reasoning generation. This work underscores the importance of optimizing for reliable explanations alongside accuracy. We release the Preferred-MedLLM-Qwen-72B model weights to foster research into trustworthy LLMs for specialized, high-stakes applications.
Label-Efficient Multi-Task Segmentation using Contrastive Learning
Sep 23, 2020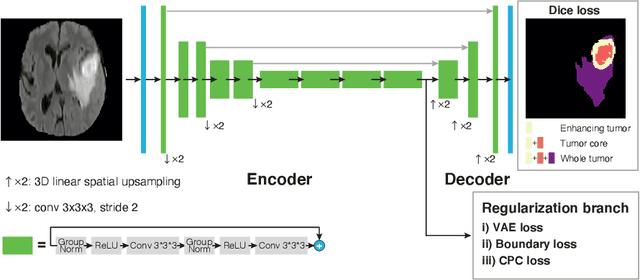
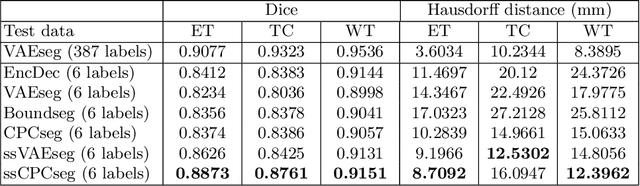
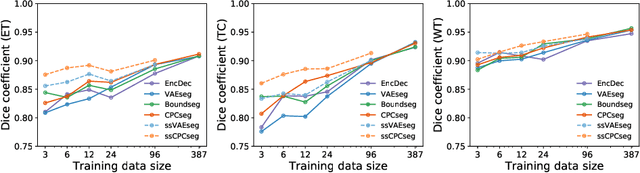
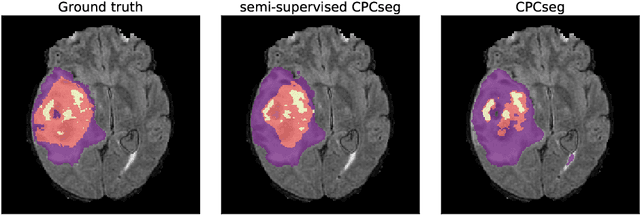
Obtaining annotations for 3D medical images is expensive and time-consuming, despite its importance for automating segmentation tasks. Although multi-task learning is considered an effective method for training segmentation models using small amounts of annotated data, a systematic understanding of various subtasks is still lacking. In this study, we propose a multi-task segmentation model with a contrastive learning based subtask and compare its performance with other multi-task models, varying the number of labeled data for training. We further extend our model so that it can utilize unlabeled data through the regularization branch in a semi-supervised manner. We experimentally show that our proposed method outperforms other multi-task methods including the state-of-the-art fully supervised model when the amount of annotated data is limited.