 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Cold-Start Gap: LLM-Powered Synthetic Data Generation for Natural Language Search at Airbnb
May 20, 2026Deploying natural language search systems presents a critical cold-start challenge: no real user queries to learn linguistic patterns, and no relevance labels to train ranking models. We present a framework for generating synthetic queries and labels using large language models (LLMs), powering model training and evaluation for Airbnb's natural language search. For query generation, we combine contrastive listing pairs from booking sessions with seed queries from user research to balance realism and diversity, enabling a cold-to-warm start transition as real user data becomes available. For label generation, we introduce contrastive generation that produces topicality labels by construction, and Virtual Judge (VJ) labeling for broader coverage. We compare our approach against a no-seed contrastive baseline and an InPars-style baseline. For query length, the InPars baseline produces verbose queries with KL divergence of 12.03 vs. real users; our seed-guided approach achieves 0.66, a 7.5x improvement. For attribute type distributions, our approach achieves the lowest KL divergence (0.04), outperforming even seed queries (0.09). Experiments show our approach produces harder evaluation examples than the no-seed baseline (79% vs. 97% pairwise accuracy), providing discriminative signal for model improvement. We deploy production pipelines generating synthetic examples daily for embedding-based retrieval and ranking evaluation.
High Precision Audience Expansion via Extreme Classification in a Two-Sided Marketplace
Feb 16, 2026Airbnb search must balance a worldwide, highly varied supply of homes with guests whose location, amenity, style, and price expectations differ widely. Meeting those expectations hinges on an efficient retrieval stage that surfaces only the listings a guest might realistically book, before resource intensive ranking models are applied to determine the best results. Unlike many recommendation engines, our system faces a distinctive challenge, location retrieval, that sits upstream of ranking and determines which geographic areas are queried in order to filter inventory to a candidate set. The preexisting approach employs a deep bayesian bandit based system to predict a rectangular retrieval bounds area that can be used for filtering. The purpose of this paper is to demonstrate the methodology, challenges, and impact of rearchitecting search to retrieve from the subset of most bookable high precision rectangular map cells defined by dividing the world into 25M uniform cells.
Transforming Location Retrieval at Airbnb: A Journey from Heuristics to Reinforcement Learning
Aug 23, 2024



The Airbnb search system grapples with many unique challenges as it continues to evolve. We oversee a marketplace that is nuanced by geography, diversity of homes, and guests with a variety of preferences. Crafting an efficient search system that can accommodate diverse guest needs, while showcasing relevant homes lies at the heart of Airbnb's success. Airbnb search has many challenges that parallel other recommendation and search systems but it has a unique information retrieval problem, upstream of ranking, called location retrieval. It requires defining a topological map area that is relevant to the searched query for homes listing retrieval. The purpose of this paper is to demonstrate the methodology, challenges, and impact of building a machine learning based location retrieval product from the ground up. Despite the lack of suitable, prevalent machine learning based approaches, we tackle cold start, generalization, differentiation and algorithmic bias. We detail the efficacy of heuristics, statistics, machine learning, and reinforcement learning approaches to solve these challenges, particularly for systems that are often unexplored by current literature.
Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights
Mar 16, 2018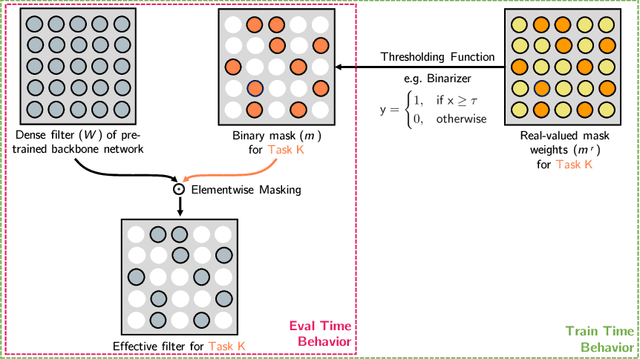
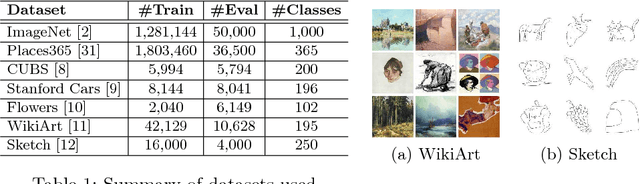
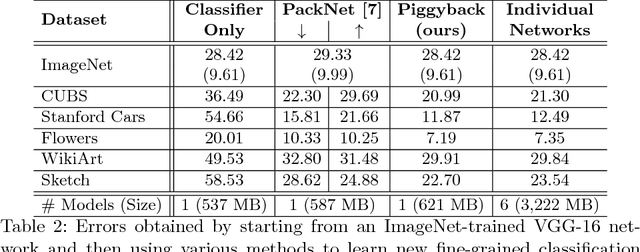
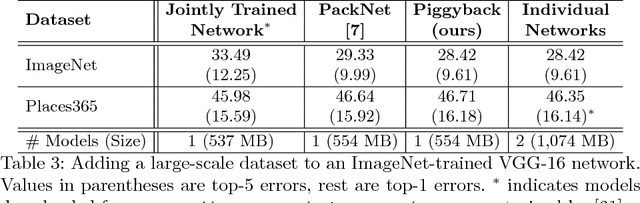
This work presents a method for adapting a single, fixed deep neural network to multiple tasks without affecting performance on already learned tasks. By building upon ideas from network quantization and pruning, we learn binary masks that piggyback on an existing network, or are applied to unmodified weights of that network to provide good performance on a new task. These masks are learned in an end-to-end differentiable fashion, and incur a low overhead of 1 bit per network parameter, per task. Even though the underlying network is fixed, the ability to mask individual weights allows for the learning of a large number of filters. We show performance comparable to dedicated fine-tuned networks for a variety of classification tasks, including those with large domain shifts from the initial task (ImageNet), and a variety of network architectures. Unlike prior work, we do not suffer from catastrophic forgetting or competition between tasks, and our performance is agnostic to task ordering. Code available at https://github.com/arunmallya/piggyback.