 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollage Diffusion
Mar 01, 2023



Text-conditional diffusion models generate high-quality, diverse images. However, text is often an ambiguous specification for a desired target image, creating the need for additional user-friendly controls for diffusion-based image generation. We focus on having precise control over image output for scenes with several objects. Users control image generation by defining a collage: a text prompt paired with an ordered sequence of layers, where each layer is an RGBA image and a corresponding text prompt. We introduce Collage Diffusion, a collage-conditional diffusion algorithm that allows users to control both the spatial arrangement and visual attributes of objects in the scene, and also enables users to edit individual components of generated images. To ensure that different parts of the input text correspond to the various locations specified in the input collage layers, Collage Diffusion modifies text-image cross-attention with the layers' alpha masks. To maintain characteristics of individual collage layers that are not specified in text, Collage Diffusion learns specialized text representations per layer. Collage input also enables layer-based controls that provide fine-grained control over the final output: users can control image harmonization on a layer-by-layer basis, and they can edit individual objects in generated images while keeping other objects fixed. Collage-conditional image generation requires harmonizing the input collage to make objects fit together--the key challenge involves minimizing changes in the positions and key visual attributes of objects in the input collage while allowing other attributes of the collage to change in the harmonization process. By leveraging the rich information present in layer input, Collage Diffusion generates globally harmonized images that maintain desired object locations and visual characteristics better than prior approaches.
Spotting Temporally Precise, Fine-Grained Events in Video
Jul 20, 2022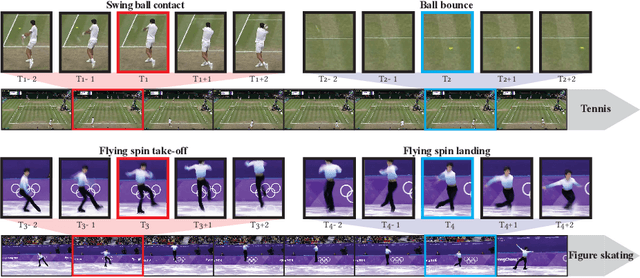
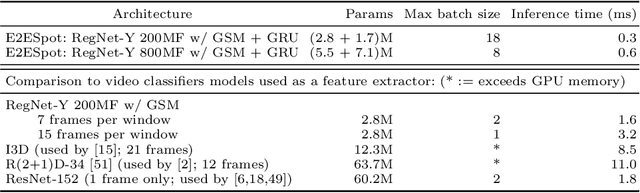
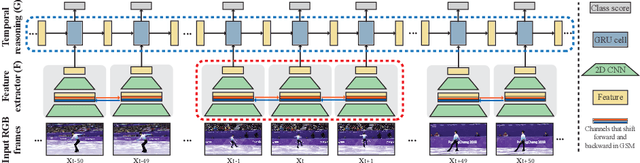
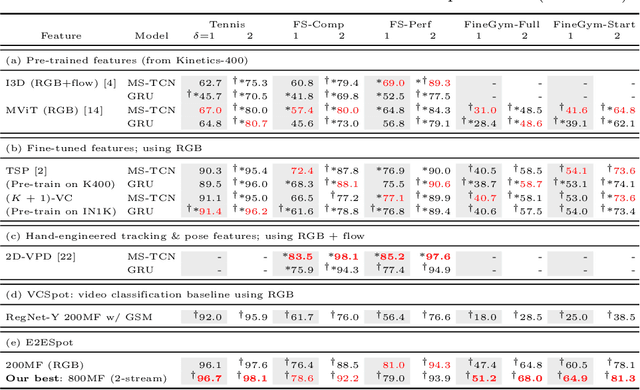
We introduce the task of spotting temporally precise, fine-grained events in video (detecting the precise moment in time events occur). Precise spotting requires models to reason globally about the full-time scale of actions and locally to identify subtle frame-to-frame appearance and motion differences that identify events during these actions. Surprisingly, we find that top performing solutions to prior video understanding tasks such as action detection and segmentation do not simultaneously meet both requirements. In response, we propose E2E-Spot, a compact, end-to-end model that performs well on the precise spotting task and can be trained quickly on a single GPU. We demonstrate that E2E-Spot significantly outperforms recent baselines adapted from the video action detection, segmentation, and spotting literature to the precise spotting task. Finally, we contribute new annotations and splits to several fine-grained sports action datasets to make these datasets suitable for future work on precise spotting.
Perfectly Balanced: Improving Transfer and Robustness of Supervised Contrastive Learning
Apr 15, 2022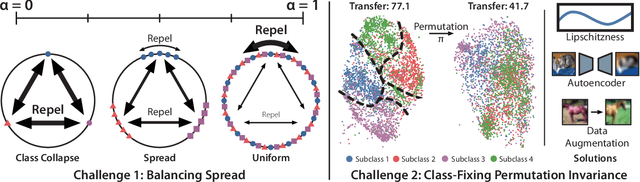

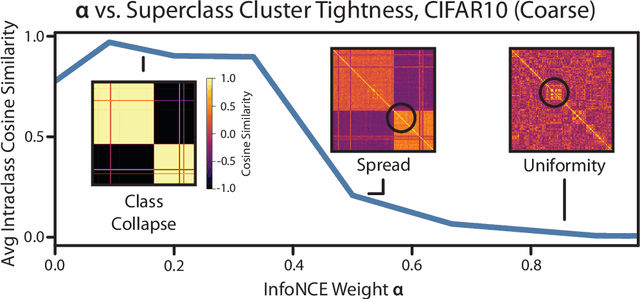
An ideal learned representation should display transferability and robustness. Supervised contrastive learning (SupCon) is a promising method for training accurate models, but produces representations that do not capture these properties due to class collapse -- when all points in a class map to the same representation. Recent work suggests that "spreading out" these representations improves them, but the precise mechanism is poorly understood. We argue that creating spread alone is insufficient for better representations, since spread is invariant to permutations within classes. Instead, both the correct degree of spread and a mechanism for breaking this invariance are necessary. We first prove that adding a weighted class-conditional InfoNCE loss to SupCon controls the degree of spread. Next, we study three mechanisms to break permutation invariance: using a constrained encoder, adding a class-conditional autoencoder, and using data augmentation. We show that the latter two encourage clustering of latent subclasses under more realistic conditions than the former. Using these insights, we show that adding a properly-weighted class-conditional InfoNCE loss and a class-conditional autoencoder to SupCon achieves 11.1 points of lift on coarse-to-fine transfer across 5 standard datasets and 4.7 points on worst-group robustness on 3 datasets, setting state-of-the-art on CelebA by 11.5 points.
Shoring Up the Foundations: Fusing Model Embeddings and Weak Supervision
Mar 24, 2022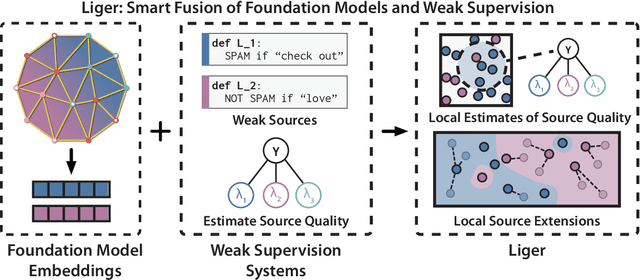
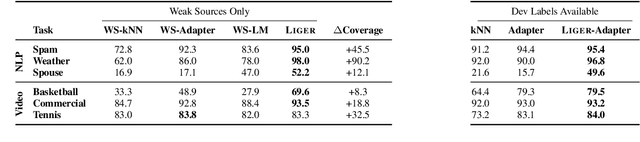
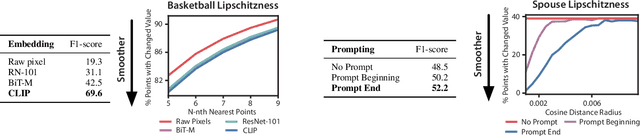
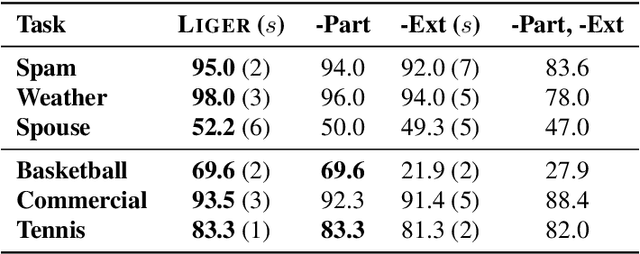
Foundation models offer an exciting new paradigm for constructing models with out-of-the-box embeddings and a few labeled examples. However, it is not clear how to best apply foundation models without labeled data. A potential approach is to fuse foundation models with weak supervision frameworks, which use weak label sources -- pre-trained models, heuristics, crowd-workers -- to construct pseudolabels. The challenge is building a combination that best exploits the signal available in both foundation models and weak sources. We propose Liger, a combination that uses foundation model embeddings to improve two crucial elements of existing weak supervision techniques. First, we produce finer estimates of weak source quality by partitioning the embedding space and learning per-part source accuracies. Second, we improve source coverage by extending source votes in embedding space. Despite the black-box nature of foundation models, we prove results characterizing how our approach improves performance and show that lift scales with the smoothness of label distributions in embedding space. On six benchmark NLP and video tasks, Liger outperforms vanilla weak supervision by 14.1 points, weakly-supervised kNN and adapters by 11.8 points, and kNN and adapters supervised by traditional hand labels by 7.2 points.
Low-Shot Validation: Active Importance Sampling for Estimating Classifier Performance on Rare Categories
Sep 13, 2021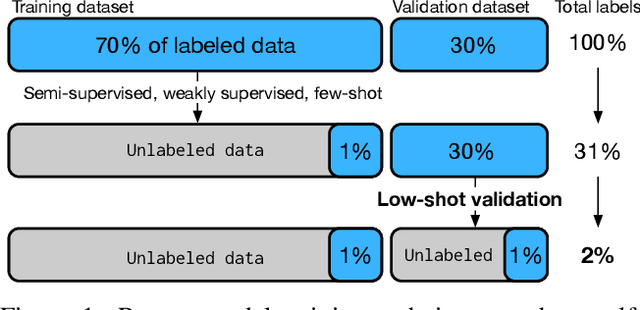
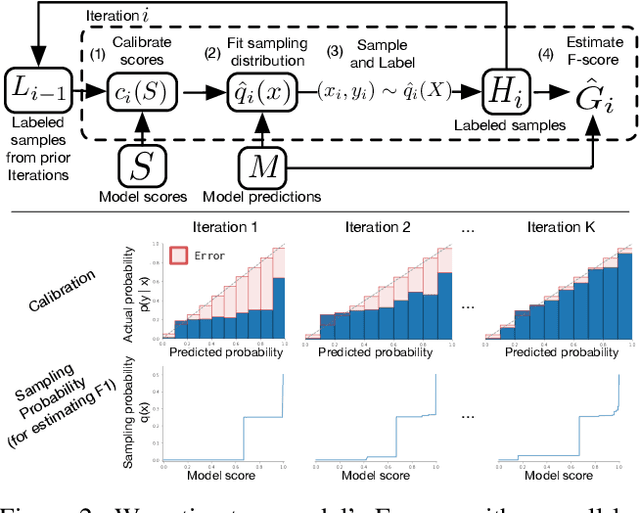
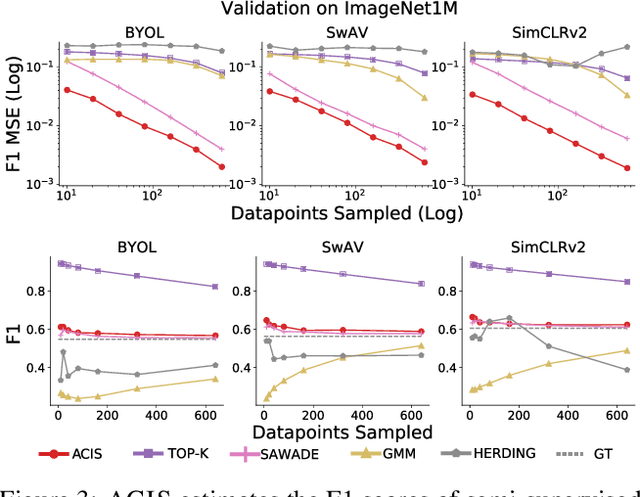
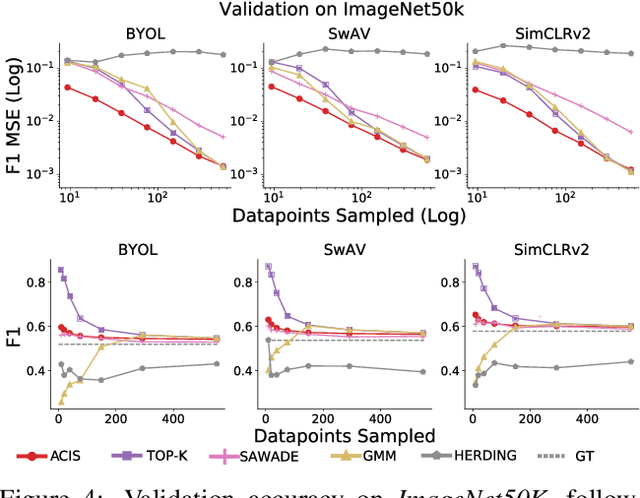
For machine learning models trained with limited labeled training data, validation stands to become the main bottleneck to reducing overall annotation costs. We propose a statistical validation algorithm that accurately estimates the F-score of binary classifiers for rare categories, where finding relevant examples to evaluate on is particularly challenging. Our key insight is that simultaneous calibration and importance sampling enables accurate estimates even in the low-sample regime (< 300 samples). Critically, we also derive an accurate single-trial estimator of the variance of our method and demonstrate that this estimator is empirically accurate at low sample counts, enabling a practitioner to know how well they can trust a given low-sample estimate. When validating state-of-the-art semi-supervised models on ImageNet and iNaturalist2017, our method achieves the same estimates of model performance with up to 10x fewer labels than competing approaches. In particular, we can estimate model F1 scores with a variance of 0.005 using as few as 100 labels.
Video Pose Distillation for Few-Shot, Fine-Grained Sports Action Recognition
Sep 03, 2021
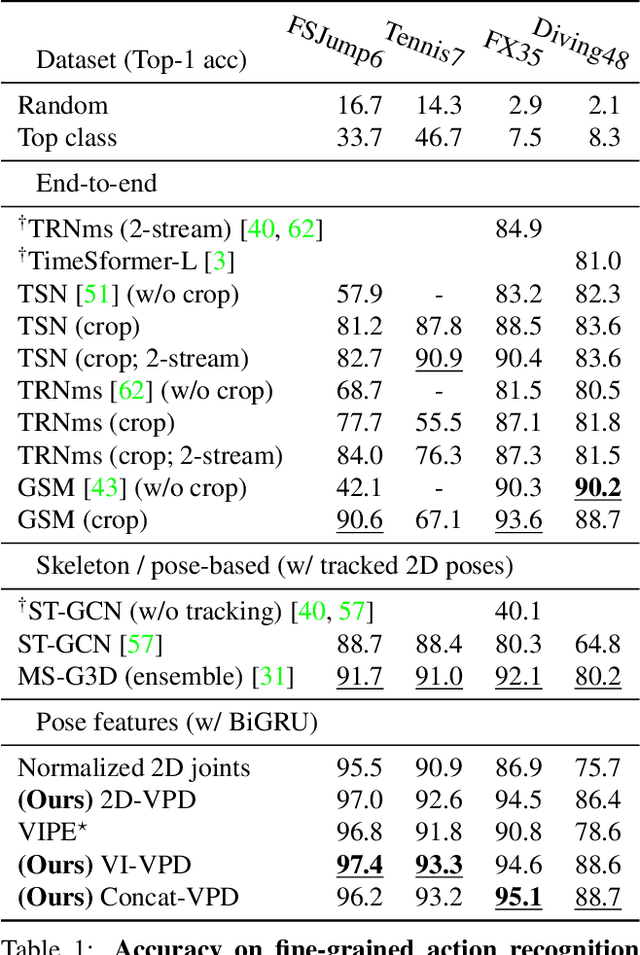
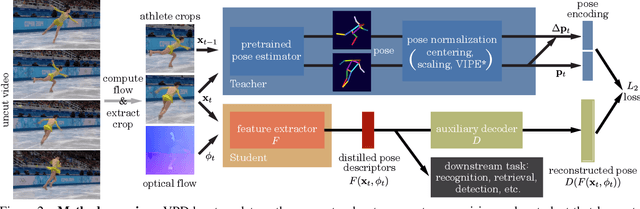
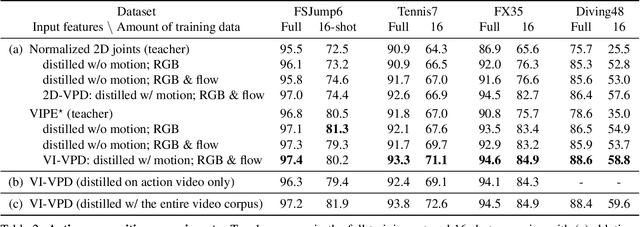
Human pose is a useful feature for fine-grained sports action understanding. However, pose estimators are often unreliable when run on sports video due to domain shift and factors such as motion blur and occlusions. This leads to poor accuracy when downstream tasks, such as action recognition, depend on pose. End-to-end learning circumvents pose, but requires more labels to generalize. We introduce Video Pose Distillation (VPD), a weakly-supervised technique to learn features for new video domains, such as individual sports that challenge pose estimation. Under VPD, a student network learns to extract robust pose features from RGB frames in the sports video, such that, whenever pose is considered reliable, the features match the output of a pretrained teacher pose detector. Our strategy retains the best of both pose and end-to-end worlds, exploiting the rich visual patterns in raw video frames, while learning features that agree with the athletes' pose and motion in the target video domain to avoid over-fitting to patterns unrelated to athletes' motion. VPD features improve performance on few-shot, fine-grained action recognition, retrieval, and detection tasks in four real-world sports video datasets, without requiring additional ground-truth pose annotations.
Mandoline: Model Evaluation under Distribution Shift
Jul 01, 2021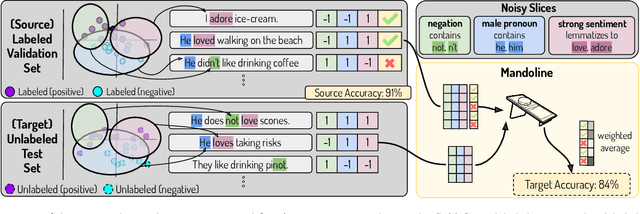
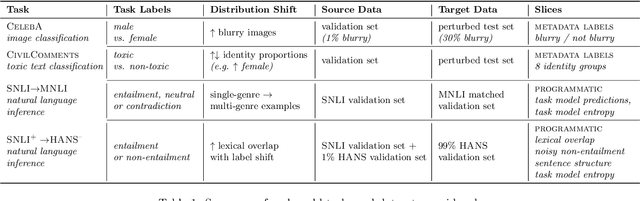
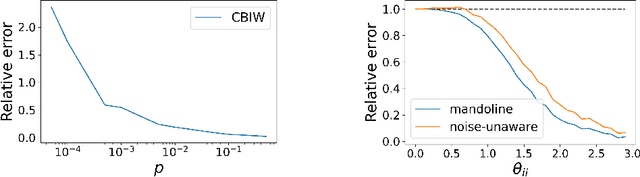
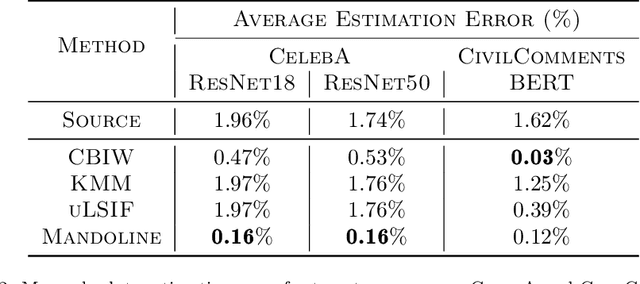
Machine learning models are often deployed in different settings than they were trained and validated on, posing a challenge to practitioners who wish to predict how well the deployed model will perform on a target distribution. If an unlabeled sample from the target distribution is available, along with a labeled sample from a possibly different source distribution, standard approaches such as importance weighting can be applied to estimate performance on the target. However, importance weighting struggles when the source and target distributions have non-overlapping support or are high-dimensional. Taking inspiration from fields such as epidemiology and polling, we develop Mandoline, a new evaluation framework that mitigates these issues. Our key insight is that practitioners may have prior knowledge about the ways in which the distribution shifts, which we can use to better guide the importance weighting procedure. Specifically, users write simple "slicing functions" - noisy, potentially correlated binary functions intended to capture possible axes of distribution shift - to compute reweighted performance estimates. We further describe a density ratio estimation framework for the slices and show how its estimation error scales with slice quality and dataset size. Empirical validation on NLP and vision tasks shows that \name can estimate performance on the target distribution up to $3\times$ more accurately compared to standard baselines.
Large Batch Simulation for Deep Reinforcement Learning
Mar 12, 2021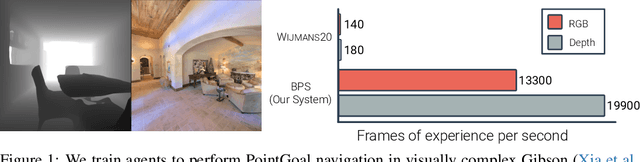
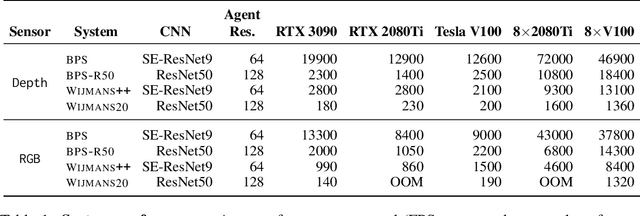
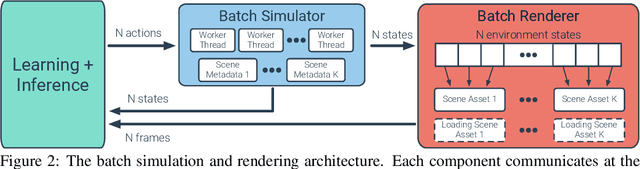
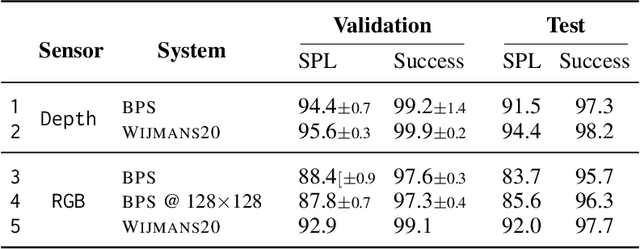
We accelerate deep reinforcement learning-based training in visually complex 3D environments by two orders of magnitude over prior work, realizing end-to-end training speeds of over 19,000 frames of experience per second on a single GPU and up to 72,000 frames per second on a single eight-GPU machine. The key idea of our approach is to design a 3D renderer and embodied navigation simulator around the principle of "batch simulation": accepting and executing large batches of requests simultaneously. Beyond exposing large amounts of work at once, batch simulation allows implementations to amortize in-memory storage of scene assets, rendering work, data loading, and synchronization costs across many simulation requests, dramatically improving the number of simulated agents per GPU and overall simulation throughput. To balance DNN inference and training costs with faster simulation, we also build a computationally efficient policy DNN that maintains high task performance, and modify training algorithms to maintain sample efficiency when training with large mini-batches. By combining batch simulation and DNN performance optimizations, we demonstrate that PointGoal navigation agents can be trained in complex 3D environments on a single GPU in 1.5 days to 97% of the accuracy of agents trained on a prior state-of-the-art system using a 64-GPU cluster over three days. We provide open-source reference implementations of our batch 3D renderer and simulator to facilitate incorporation of these ideas into RL systems.
Iterative Text-based Editing of Talking-heads Using Neural Retargeting
Nov 21, 2020
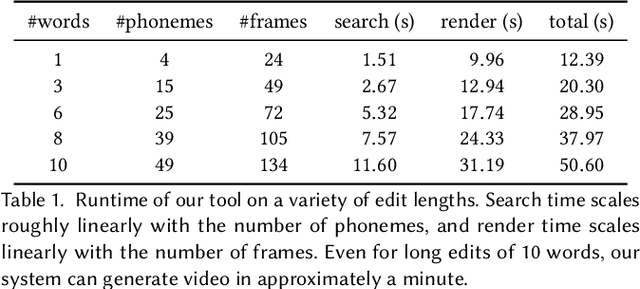
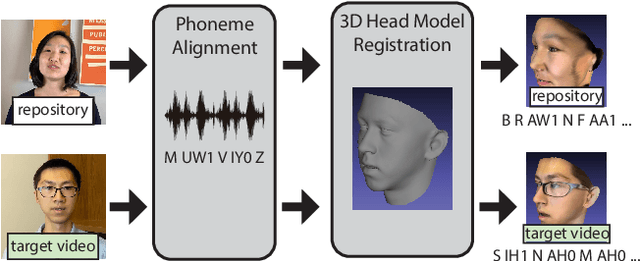
We present a text-based tool for editing talking-head video that enables an iterative editing workflow. On each iteration users can edit the wording of the speech, further refine mouth motions if necessary to reduce artifacts and manipulate non-verbal aspects of the performance by inserting mouth gestures (e.g. a smile) or changing the overall performance style (e.g. energetic, mumble). Our tool requires only 2-3 minutes of the target actor video and it synthesizes the video for each iteration in about 40 seconds, allowing users to quickly explore many editing possibilities as they iterate. Our approach is based on two key ideas. (1) We develop a fast phoneme search algorithm that can quickly identify phoneme-level subsequences of the source repository video that best match a desired edit. This enables our fast iteration loop. (2) We leverage a large repository of video of a source actor and develop a new self-supervised neural retargeting technique for transferring the mouth motions of the source actor to the target actor. This allows us to work with relatively short target actor videos, making our approach applicable in many real-world editing scenarios. Finally, our refinement and performance controls give users the ability to further fine-tune the synthesized results.
Background Splitting: Finding Rare Classes in a Sea of Background
Aug 28, 2020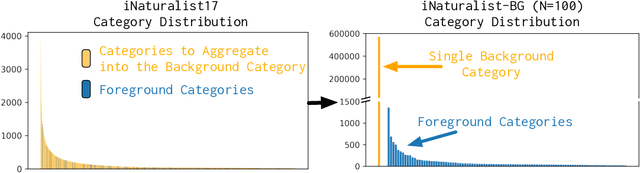
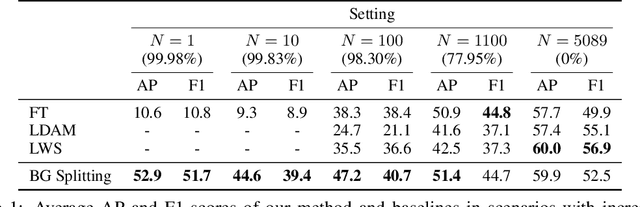
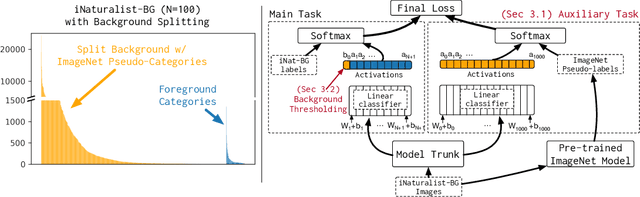

We focus on the real-world problem of training accurate deep models for image classification of a small number of rare categories. In these scenarios, almost all images belong to the background category in the dataset (>95% of the dataset is background). We demonstrate that both standard fine-tuning approaches and state-of-the-art approaches for training on imbalanced datasets do not produce accurate deep models in the presence of this extreme imbalance. Our key observation is that the extreme imbalance due to the background category can be drastically reduced by leveraging visual knowledge from an existing pre-trained model. Specifically, the background category is "split" into smaller and more coherent pseudo-categories during training using a pre-trained model. We incorporate background splitting into an image classification model by adding an auxiliary loss that learns to mimic the predictions of the existing, pre-trained image classification model. Note that this process is automatic and requires no additional manual labels. The auxiliary loss regularizes the feature representation of the shared network trunk by requiring it to discriminate between previously homogeneous background instances and reduces overfitting to the small number of rare category positives. We also show that BG splitting can be combined with other background imbalance methods to further improve performance. We evaluate our method on a modified version of the iNaturalist dataset where only a small subset of rare category labels are available during training (all other images are labeled as background). By jointly learning to recognize ImageNet categories and selected iNaturalist categories, our approach yields performance that is 42.3 mAP points higher than a fine-tuning baseline when 99.98% of the data is background, and 8.3 mAP points higher than SotA baselines when 98.30% of the data is background.