 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan contrastive learning avoid shortcut solutions?
Jun 21, 2021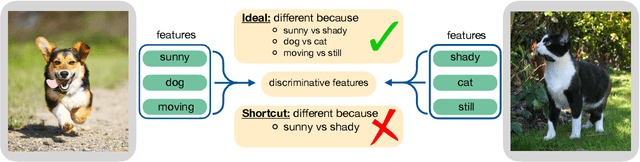
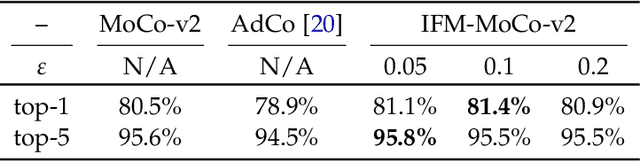
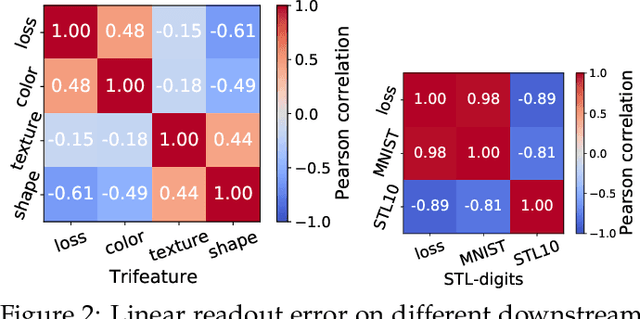
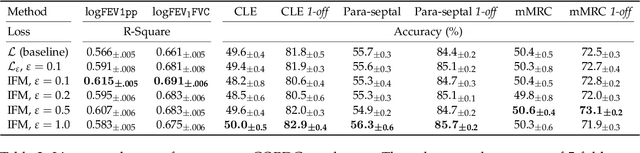
The generalization of representations learned via contrastive learning depends crucially on what features of the data are extracted. However, we observe that the contrastive loss does not always sufficiently guide which features are extracted, a behavior that can negatively impact the performance on downstream tasks via "shortcuts", i.e., by inadvertently suppressing important predictive features. We find that feature extraction is influenced by the difficulty of the so-called instance discrimination task (i.e., the task of discriminating pairs of similar points from pairs of dissimilar ones). Although harder pairs improve the representation of some features, the improvement comes at the cost of suppressing previously well represented features. In response, we propose implicit feature modification (IFM), a method for altering positive and negative samples in order to guide contrastive models towards capturing a wider variety of predictive features. Empirically, we observe that IFM reduces feature suppression, and as a result improves performance on vision and medical imaging tasks. The code is available at: \url{https://github.com/joshr17/IFM}.
Self-Supervised Vessel Enhancement Using Flow-Based Consistencies
Jan 13, 2021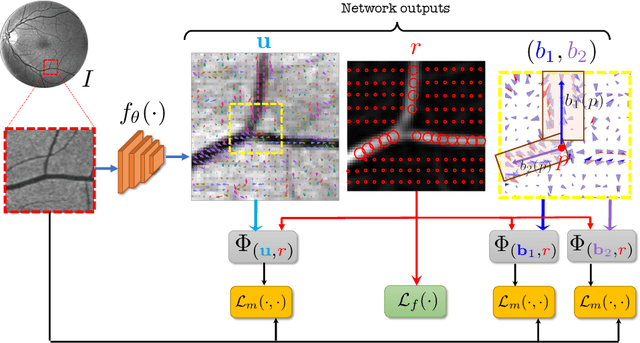
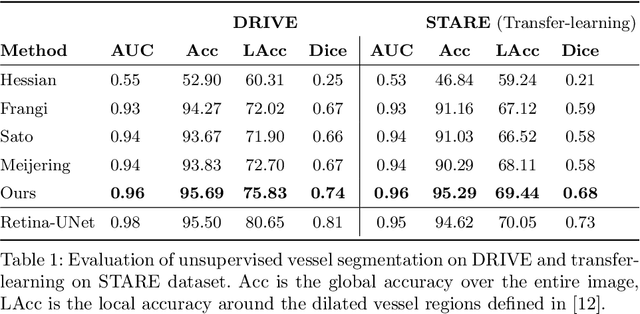
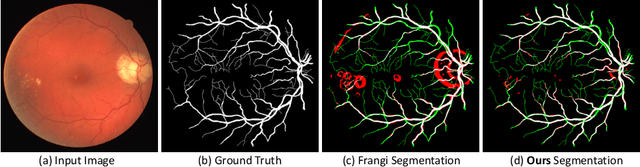
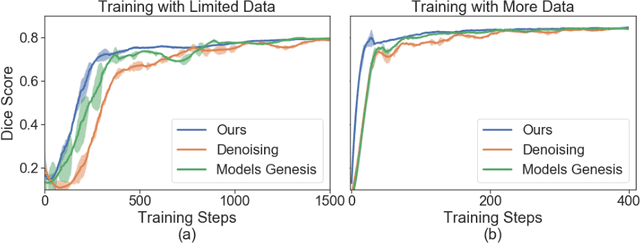
Vessel segmenting is an essential task in many clinical applications. Although supervised methods have achieved state-of-art performance, acquiring expert annotation is laborious and mostly limited for two-dimensional datasets with a small sample size. On the contrary, unsupervised methods rely on handcrafted features to detect tube-like structures such as vessels. However, those methods require complex pipelines involving several hyper-parameters and design choices rendering the procedure sensitive, dataset-specific, and not generalizable. Also, unsupervised methods usually underperform supervised methods. We propose a self-supervised method with a limited number of hyper-parameters that is generalizable. Our method uses tube-like structure properties, such as connectivity, profile consistency, and bifurcation, to introduce inductive bias into a learning algorithm. To model those properties, we generate a vector field that we refer to as a flow. Our experiments on various datasets in 2D and 3D show that our method reduces the gap between supervised and unsupervised methods. Unlike generic self-supervised methods, the learned features are transferable for supervised approaches, which is essential when the number of annotated data is limited.
Explaining the Black-box Smoothly- A Counterfactual Approach
Jan 11, 2021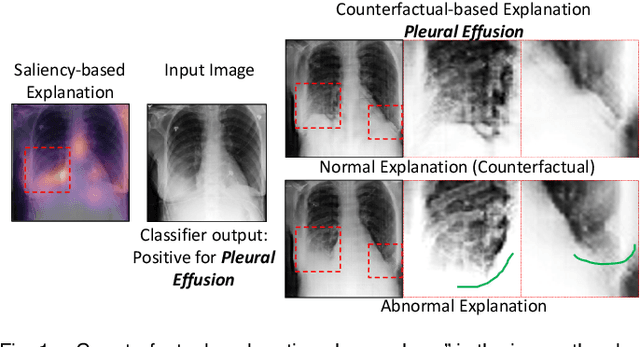
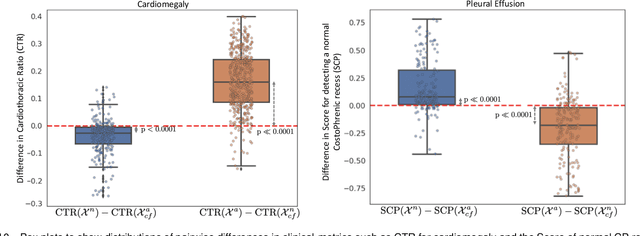
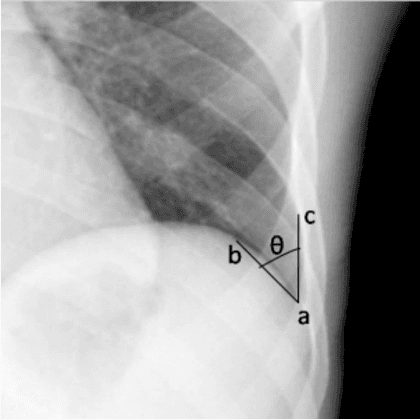
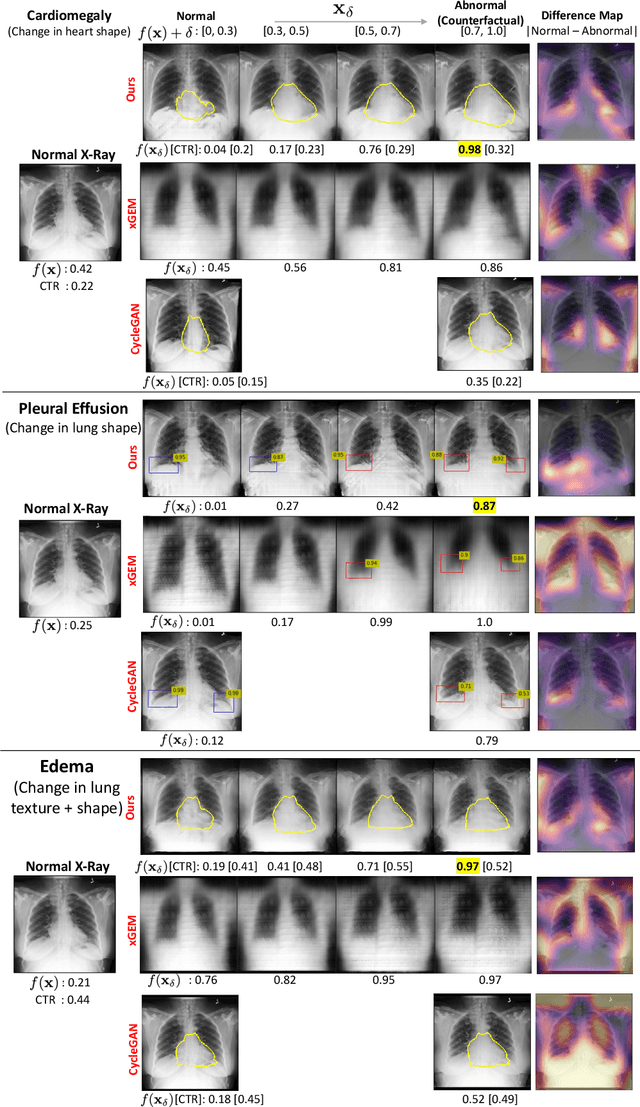
We propose a BlackBox \emph{Counterfactual Explainer} that is explicitly developed for medical imaging applications. Classical approaches (e.g. saliency maps) assessing feature importance do not explain \emph{how} and \emph{why} variations in a particular anatomical region is relevant to the outcome, which is crucial for transparent decision making in healthcare application. Our framework explains the outcome by gradually \emph{exaggerating} the semantic effect of the given outcome label. Given a query input to a classifier, Generative Adversarial Networks produce a progressive set of perturbations to the query image that gradually changes the posterior probability from its original class to its negation. We design the loss function to ensure that essential and potentially relevant details, such as support devices, are preserved in the counterfactually generated images. We provide an extensive evaluation of different classification tasks on the chest X-Ray images. Our experiments show that a counterfactually generated visual explanation is consistent with the disease's clinical relevant measurements, both quantitatively and qualitatively.
Context Matters: Graph-based Self-supervised Representation Learning for Medical Images
Dec 11, 2020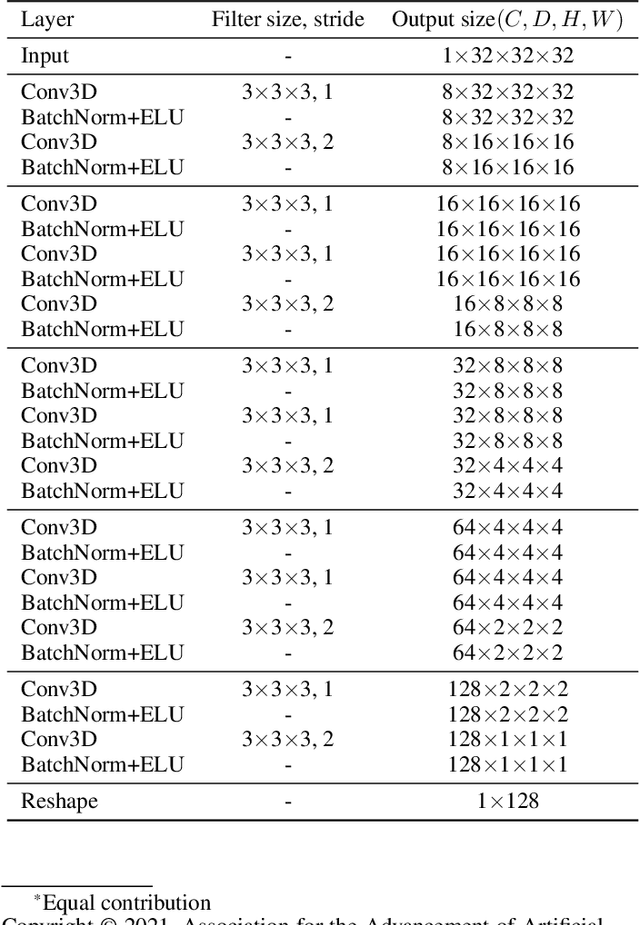
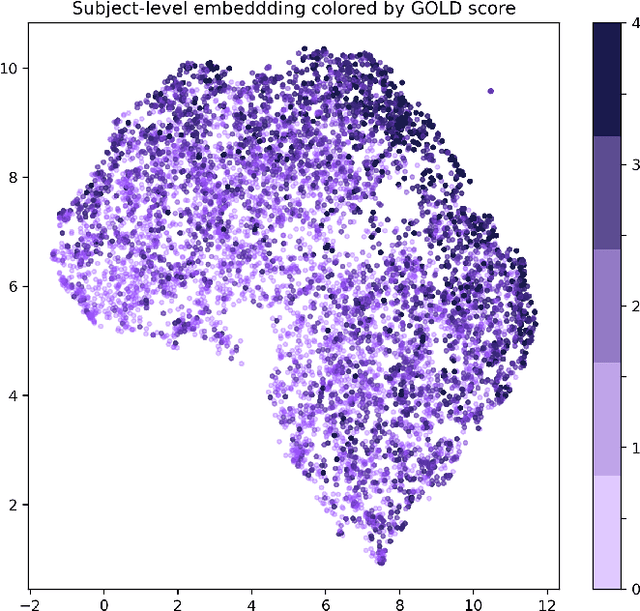
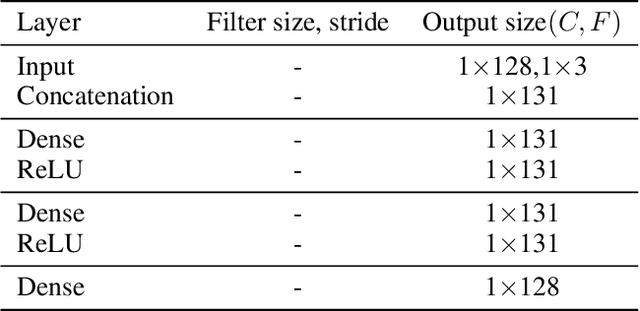
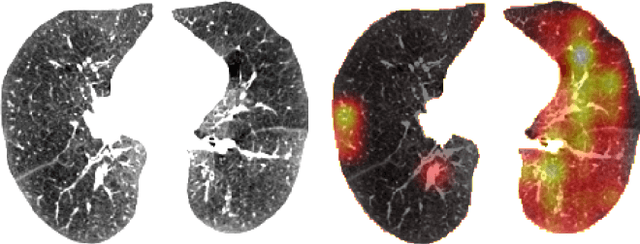
Supervised learning method requires a large volume of annotated datasets. Collecting such datasets is time-consuming and expensive. Until now, very few annotated COVID-19 imaging datasets are available. Although self-supervised learning enables us to bootstrap the training by exploiting unlabeled data, the generic self-supervised methods for natural images do not sufficiently incorporate the context. For medical images, a desirable method should be sensitive enough to detect deviation from normal-appearing tissue of each anatomical region; here, anatomy is the context. We introduce a novel approach with two levels of self-supervised representation learning objectives: one on the regional anatomical level and another on the patient-level. We use graph neural networks to incorporate the relationship between different anatomical regions. The structure of the graph is informed by anatomical correspondences between each patient and an anatomical atlas. In addition, the graph representation has the advantage of handling any arbitrarily sized image in full resolution. Experiments on large-scale Computer Tomography (CT) datasets of lung images show that our approach compares favorably to baseline methods that do not account for the context. We use the learnt embedding to quantify the clinical progression of COVID-19 and show that our method generalizes well to COVID-19 patients from different hospitals. Qualitative results suggest that our model can identify clinically relevant regions in the images.
Hierarchical Amortized Training for Memory-efficient High Resolution 3D GAN
Aug 05, 2020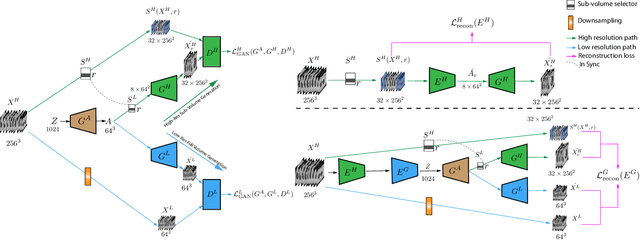
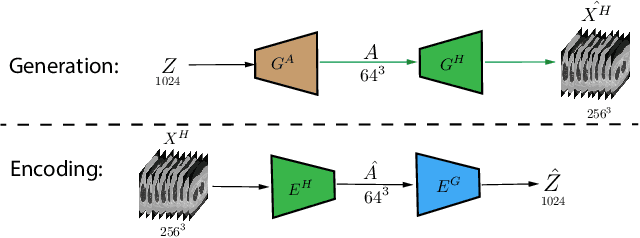
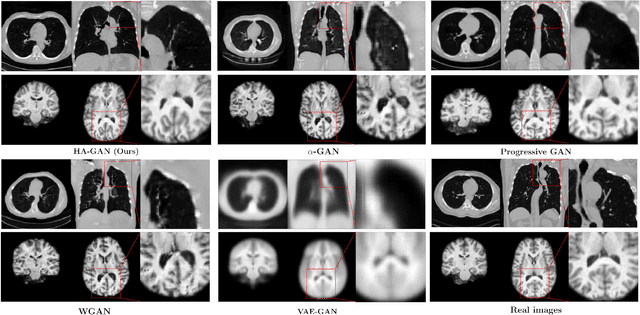
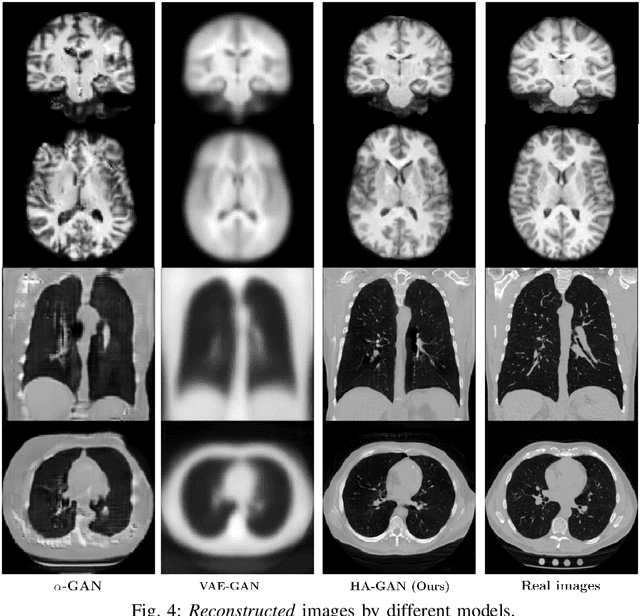
Generative Adversarial Networks (GAN) have many potential medical imaging applications, including data augmentation, domain adaptation, and model explanation. Due to the limited embedded memory of Graphical Processing Units (GPUs), most current 3D GAN models are trained on low-resolution medical images. In this work, we propose a novel end-to-end GAN architecture that can generate high-resolution 3D images. We achieve this goal by separating training and inference. During training, we adopt a hierarchical structure that simultaneously generates a low-resolution version of the image and a randomly selected sub-volume of the high-resolution image. The hierarchical design has two advantages: First, the memory demand for training on high-resolution images is amortized among subvolumes. Furthermore, anchoring the high-resolution subvolumes to a single low-resolution image ensures anatomical consistency between subvolumes. During inference, our model can directly generate full high-resolution images. We also incorporate an encoder with a similar hierarchical structure into the model to extract features from the images. Experiments on 3D thorax CT and brain MRI demonstrate that our approach outperforms state of the art in image generation, image reconstruction, and clinical-relevant variables prediction.
Semi-Supervised Hierarchical Drug Embedding in Hyperbolic Space
Jun 01, 2020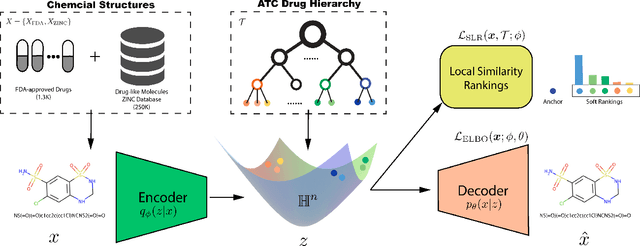
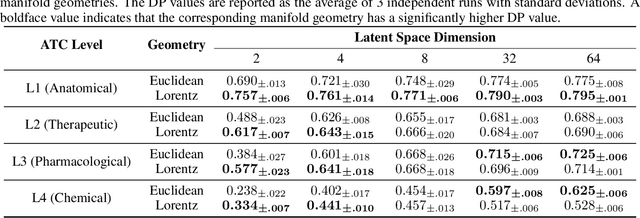
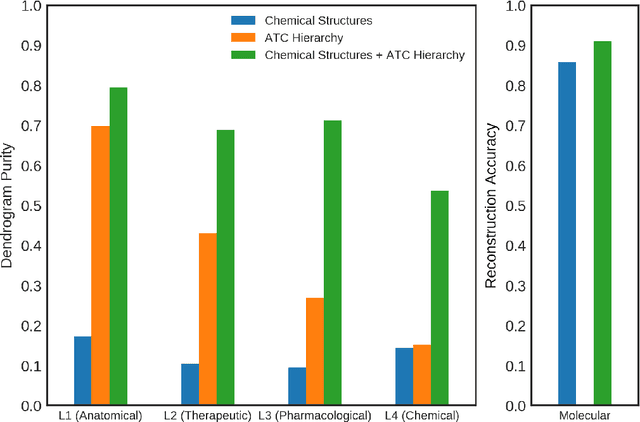

Learning accurate drug representation is essential for tasks such as computational drug repositioning and prediction of drug side-effects. A drug hierarchy is a valuable source that encodes human knowledge of drug relations in a tree-like structure where drugs that act on the same organs, treat the same disease, or bind to the same biological target are grouped together. However, its utility in learning drug representations has not yet been explored, and currently described drug representations cannot place novel molecules in a drug hierarchy. Here, we develop a semi-supervised drug embedding that incorporates two sources of information: (1) underlying chemical grammar that is inferred from molecular structures of drugs and drug-like molecules (unsupervised), and (2) hierarchical relations that are encoded in an expert-crafted hierarchy of approved drugs (supervised). We use the Variational Auto-Encoder (VAE) framework to encode the chemical structures of molecules and use the knowledge-based drug-drug similarity to induce the clustering of drugs in hyperbolic space. The hyperbolic space is amenable for encoding hierarchical concepts. Both quantitative and qualitative results support that the learned drug embedding can accurately reproduce the chemical structure and induce the hierarchical relations among drugs. Furthermore, our approach can infer the pharmacological properties of novel molecules by retrieving similar drugs from the embedding space. We demonstrate that the learned drug embedding can be used to find new uses for existing drugs and to discover side-effects. We show that it significantly outperforms baselines in both tasks.
Explanation by Progressive Exaggeration
Nov 05, 2019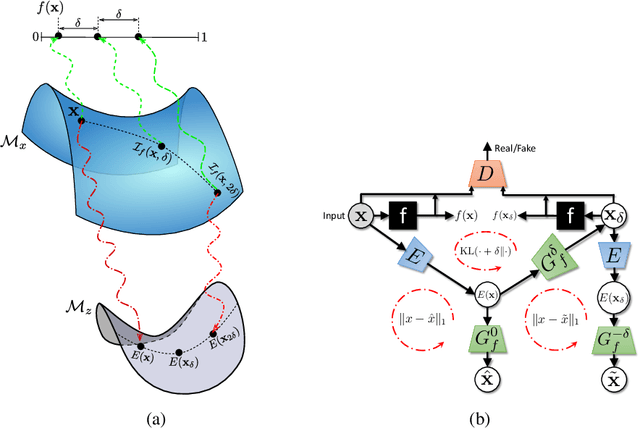

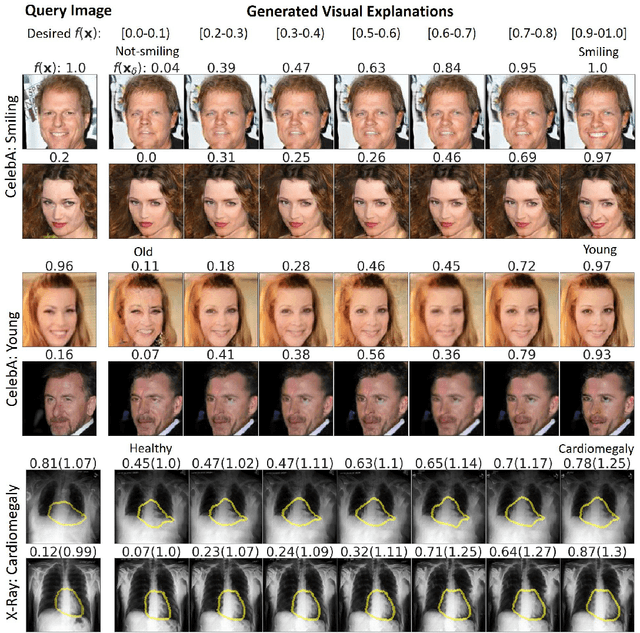

As machine learning methods see greater adoption and implementation in high stakes applications such as medical image diagnosis, the need for model interpretability and explanation has become more critical. Classical approaches that assess feature importance (e.g. saliency maps) do not explain how and why a particular region of an image is relevant to the prediction. We propose a method that explains the outcome of a classification black-box by gradually exaggerating the semantic effect of a given class. Given a query input to a classifier, our method produces a progressive set of plausible variations of that query, which gradually changes the posterior probability from its original class to its negation. These counter-factually generated samples preserve features unrelated to the classification decision, such that a user can employ our method as a "tuning knob" to traverse a data manifold while crossing the decision boundary. Our method is model agnostic and only requires the output value and gradient of the predictor with respect to its input.
Robust Ordinal VAE: Employing Noisy Pairwise Comparisons for Disentanglement
Oct 14, 2019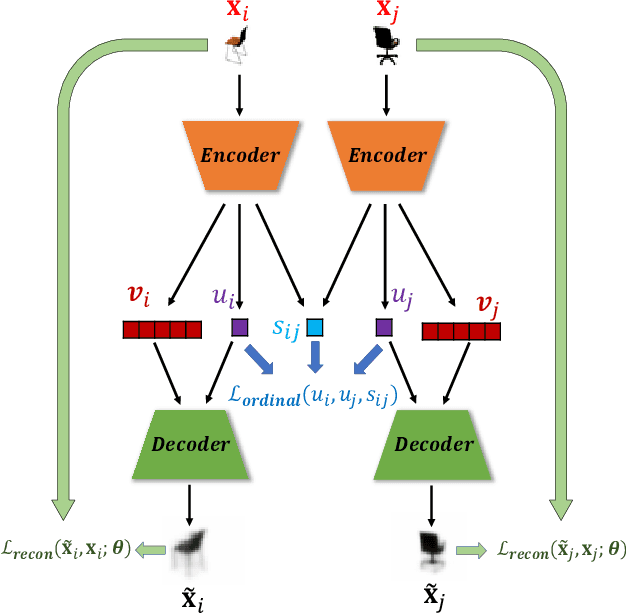

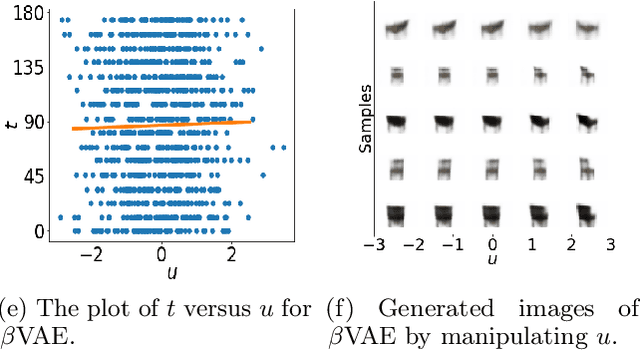

Recent work by Locatello et al. (2018) has shown that an inductive bias is required to disentangle factors of interest in Variational Autoencoder (VAE). Motivated by a real-world problem, we propose a setting where such bias is introduced by providing pairwise ordinal comparisons between instances, based on the desired factor to be disentangled. For example, a doctor compares pairs of patients based on the level of severity of their illnesses, and the desired factor is a quantitive level of the disease severity. In a real-world application, the pairwise comparisons are usually noisy. Our method, Robust Ordinal VAE (ROVAE), incorporates the noisy pairwise ordinal comparisons in the disentanglement task. We introduce non-negative random variables in ROVAE, such that it can automatically determine whether each pairwise ordinal comparison is trustworthy and ignore the noisy comparisons. Experimental results demonstrate that ROVAE outperforms existing methods and is more robust to noisy pairwise comparisons in both benchmark datasets and a real-world application.
Twin Auxiliary Classifiers GAN
Jul 30, 2019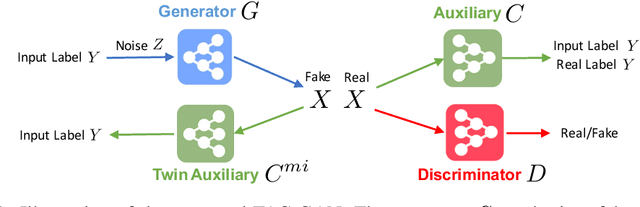
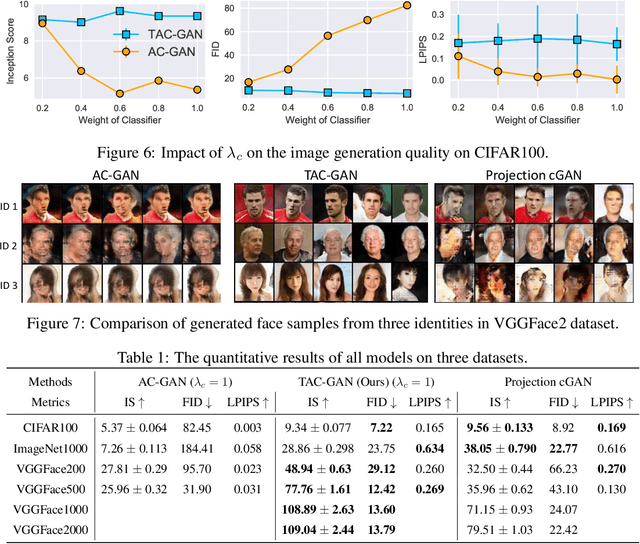
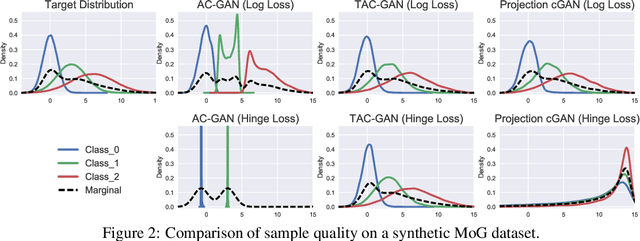
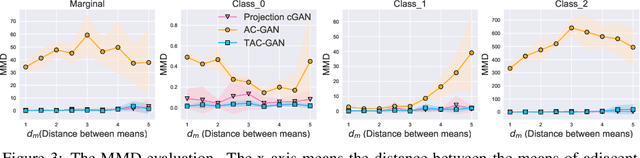
Conditional generative models enjoy remarkable progress over the past few years. One of the popular conditional models is Auxiliary Classifier GAN (AC-GAN), which generates highly discriminative images by extending the loss function of GAN with an auxiliary classifier. However, the diversity of the generated samples by AC-GAN tends to decrease as the number of classes increases, hence limiting its power on large-scale data. In this paper, we identify the source of the low diversity issue theoretically and propose a practical solution to solve the problem. We show that the auxiliary classifier in AC-GAN imposes perfect separability, which is disadvantageous when the supports of the class distributions have significant overlap. To address the issue, we propose Twin Auxiliary Classifiers Generative Adversarial Net (TAC-GAN) that further benefits from a new player that interacts with other players (the generator and the discriminator) in GAN. Theoretically, we demonstrate that TAC-GAN can effectively minimize the divergence between the generated and real-data distributions. Extensive experimental results show that our TAC-GAN can successfully replicate the true data distributions on simulated data, and significantly improves the diversity of class-conditional image generation on real datasets.
Learning Depth from Monocular Videos Using Synthetic Data: A Temporally-Consistent Domain Adaptation Approach
Jul 16, 2019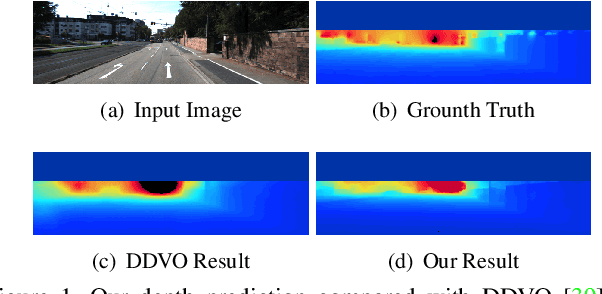
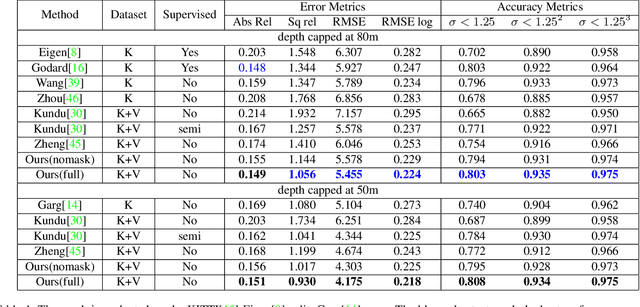
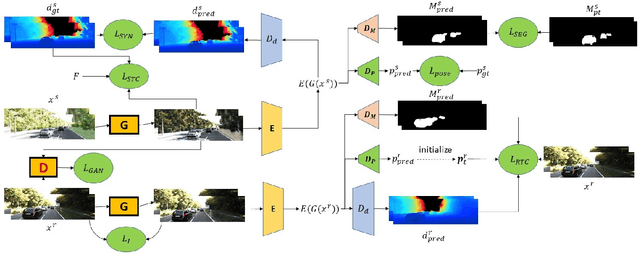
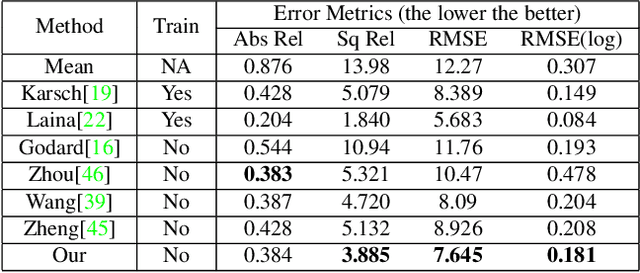
Majority of state-of-the-art monocular depth estimation methods are supervised learning approaches. The success of such approaches heavily depends on the high-quality depth labels which are expensive to obtain. Recent methods try to learn depth networks by exploring unsupervised cues from monocular videos which are easier to acquire but less reliable. In this paper, we propose to resolve this dilemma by transferring knowledge from synthetic videos with easily obtainable ground truth depth labels. Due to the stylish difference between synthetic and real images, we propose a temporally-consistent domain adaptation (TCDA) approach that simultaneously explores labels in the synthetic domain and temporal constraints in the videos to improve style transfer and depth prediction. Furthermore, we make use of the ground truth optical flow and pose information in the synthetic data to learn moving mask and pose prediction networks. The learned moving masks can filter out moving regions that produces erroneous temporal constraints and the estimated poses provide better initializations for estimating temporal constraints. The experimental results demonstrate the effectiveness of our method and comparable performance against state-of-the-art.