 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn Morphological Inflection for Resource-Poor Languages
Apr 28, 2020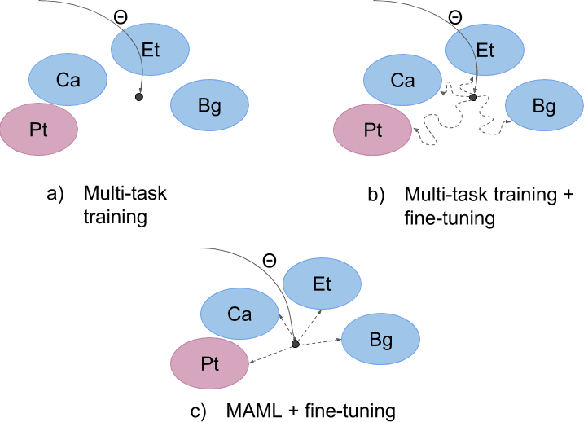
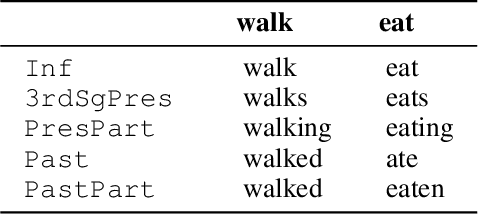
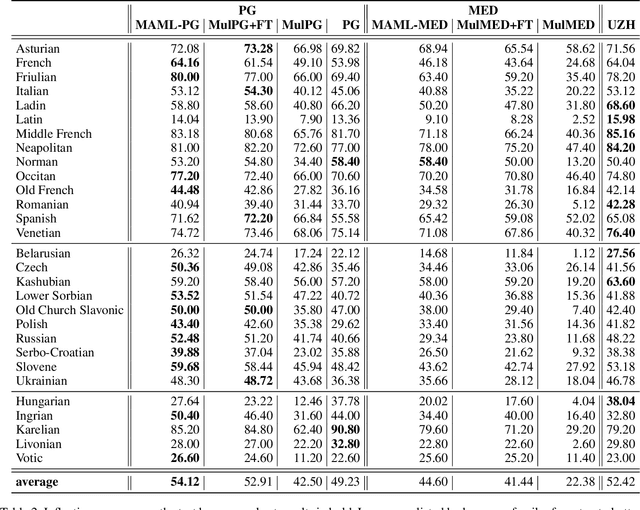
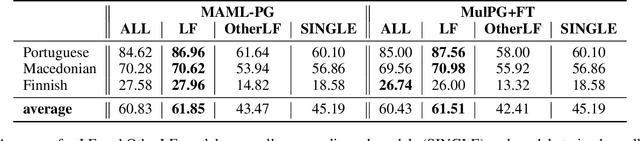
We propose to cast the task of morphological inflection - mapping a lemma to an indicated inflected form - for resource-poor languages as a meta-learning problem. Treating each language as a separate task, we use data from high-resource source languages to learn a set of model parameters that can serve as a strong initialization point for fine-tuning on a resource-poor target language. Experiments with two model architectures on 29 target languages from 3 families show that our suggested approach outperforms all baselines. In particular, it obtains a 31.7% higher absolute accuracy than a previously proposed cross-lingual transfer model and outperforms the previous state of the art by 1.7% absolute accuracy on average over languages.
Grammatical Gender, Neo-Whorfianism, and Word Embeddings: A Data-Driven Approach to Linguistic Relativity
Oct 22, 2019


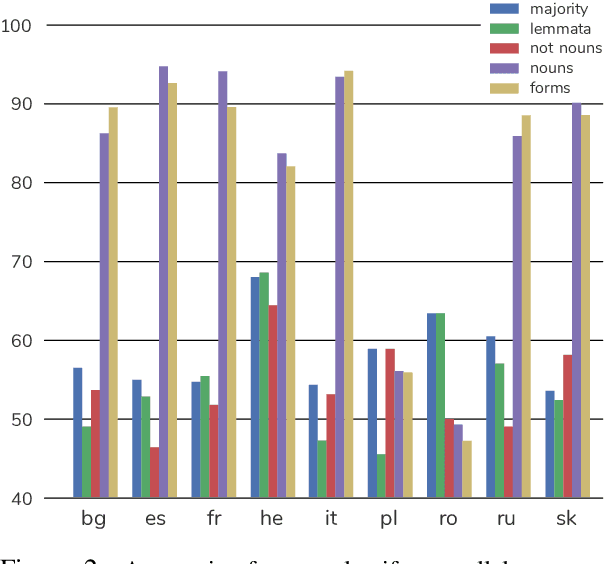
The relation between language and thought has occupied linguists for at least a century. Neo-Whorfianism, a weak version of the controversial Sapir-Whorf hypothesis, holds that our thoughts are subtly influenced by the grammatical structures of our native language. One area of investigation in this vein focuses on how the grammatical gender of nouns affects the way we perceive the corresponding objects. For instance, does the fact that key is masculine in German (der Schl\"ussel), but feminine in Spanish (la llave) change the speakers' views of those objects? Psycholinguistic evidence presented by Boroditsky et al. (2003, {\S}4) suggested the answer might be yes: When asked to produce adjectives that best described a key, German and Spanish speakers named more stereotypically masculine and feminine ones, respectively. However, recent attempts to replicate those experiments have failed (Mickan et al., 2014). In this work, we offer a computational analogue of Boroditsky et al. (2003, {\S}4)'s experimental design on 9 languages, finding evidence against neo-Whorfianism.
Acquisition of Inflectional Morphology in Artificial Neural Networks With Prior Knowledge
Oct 12, 2019
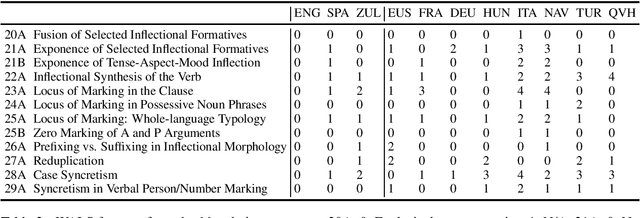
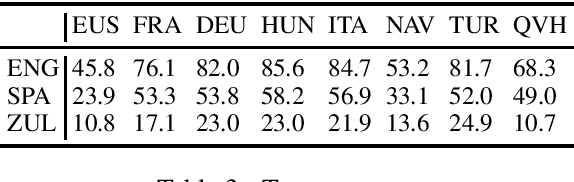

How does knowledge of one language's morphology influence learning of inflection rules in a second one? In order to investigate this question in artificial neural network models, we perform experiments with a sequence-to-sequence architecture, which we train on different combinations of eight source and three target languages. A detailed analysis of the model outputs suggests the following conclusions: (i) if source and target language are closely related, acquisition of the target language's inflectional morphology constitutes an easier task for the model; (ii) knowledge of a prefixing (resp. suffixing) language makes acquisition of a suffixing (resp. prefixing) language's morphology more challenging; and (iii) surprisingly, a source language which exhibits an agglutinative morphology simplifies learning of a second language's inflectional morphology, independent of their relatedness.
Towards Realistic Practices In Low-Resource Natural Language Processing: The Development Set
Sep 15, 2019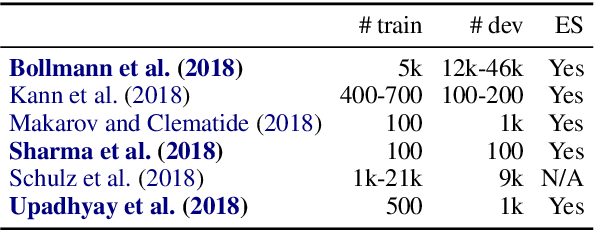
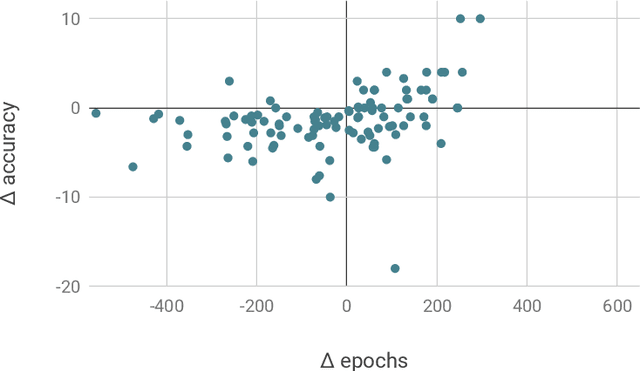
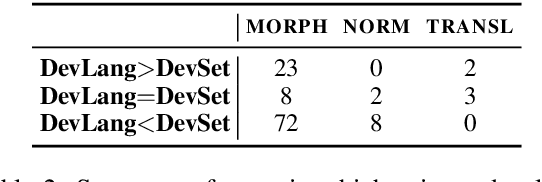
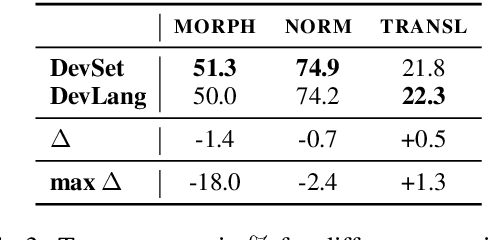
Development sets are impractical to obtain for real low-resource languages, since using all available data for training is often more effective. However, development sets are widely used in research papers that purport to deal with low-resource natural language processing (NLP). Here, we aim to answer the following questions: Does using a development set for early stopping in the low-resource setting influence results as compared to a more realistic alternative, where the number of training epochs is tuned on development languages? And does it lead to overestimation or underestimation of performance? We repeat multiple experiments from recent work on neural models for low-resource NLP and compare results for models obtained by training with and without development sets. On average over languages, absolute accuracy differs by up to 1.4%. However, for some languages and tasks, differences are as big as 18.0% accuracy. Our results highlight the importance of realistic experimental setups in the publication of low-resource NLP research results.
Transductive Auxiliary Task Self-Training for Neural Multi-Task Models
Aug 16, 2019
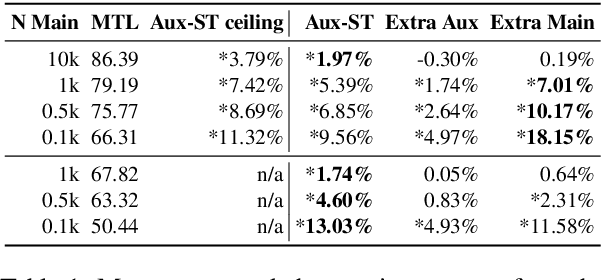
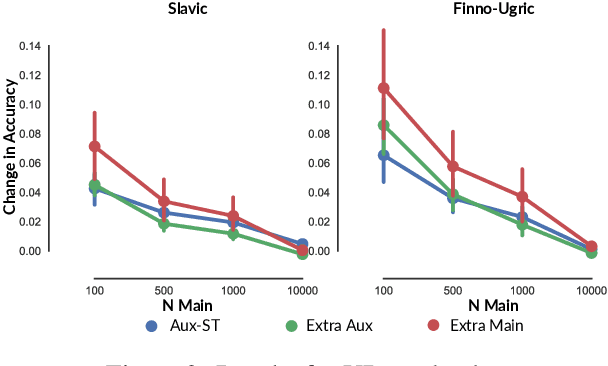
Multi-task learning and self-training are two common ways to improve a machine learning model's performance in settings with limited training data. Drawing heavily on ideas from those two approaches, we suggest transductive auxiliary task self-training: training a multi-task model on (i) a combination of main and auxiliary task training data, and (ii) test instances with auxiliary task labels which a single-task version of the model has previously generated. We perform extensive experiments on 86 combinations of languages and tasks. Our results are that, on average, transductive auxiliary task self-training improves absolute accuracy by up to 9.56% over the pure multi-task model for dependency relation tagging and by up to 13.03% for semantic tagging.
Probing for Semantic Classes: Diagnosing the Meaning Content of Word Embeddings
Jun 09, 2019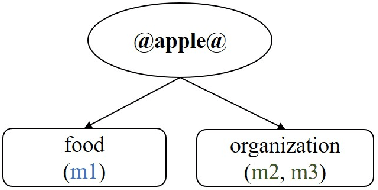

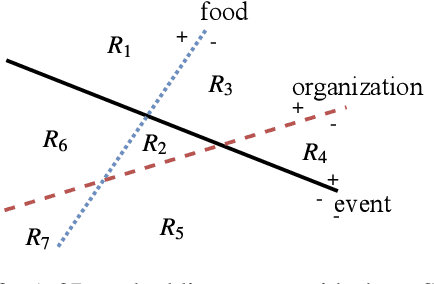
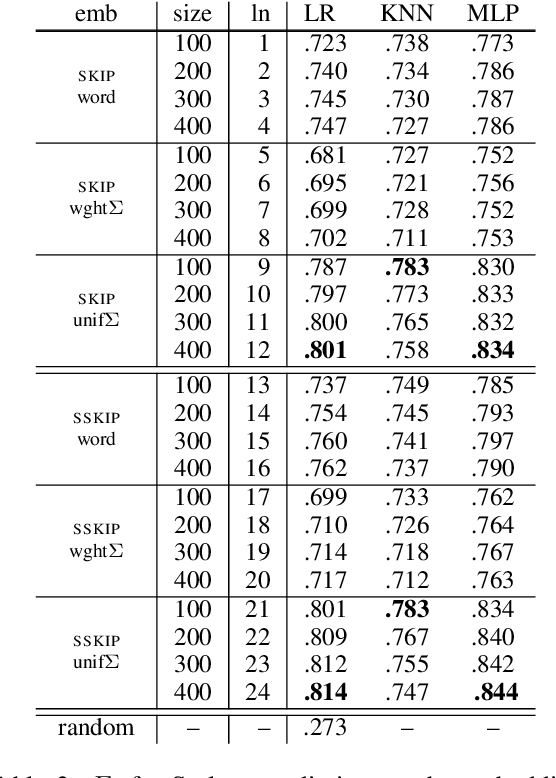
Word embeddings typically represent different meanings of a word in a single conflated vector. Empirical analysis of embeddings of ambiguous words is currently limited by the small size of manually annotated resources and by the fact that word senses are treated as unrelated individual concepts. We present a large dataset based on manual Wikipedia annotations and word senses, where word senses from different words are related by semantic classes. This is the basis for novel diagnostic tests for an embedding's content: we probe word embeddings for semantic classes and analyze the embedding space by classifying embeddings into semantic classes. Our main findings are: (i) Information about a sense is generally represented well in a single-vector embedding - if the sense is frequent. (ii) A classifier can accurately predict whether a word is single-sense or multi-sense, based only on its embedding. (iii) Although rare senses are not well represented in single-vector embeddings, this does not have negative impact on an NLP application whose performance depends on frequent senses.
Subword-Level Language Identification for Intra-Word Code-Switching
Apr 03, 2019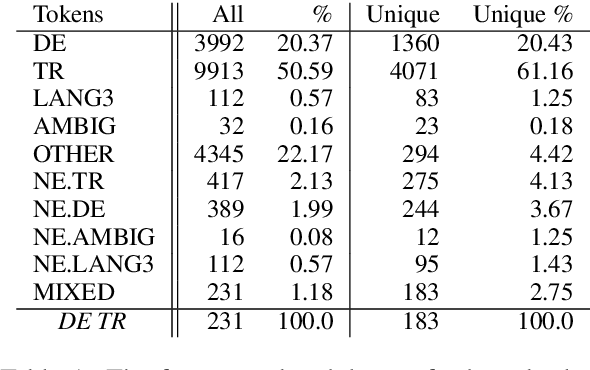

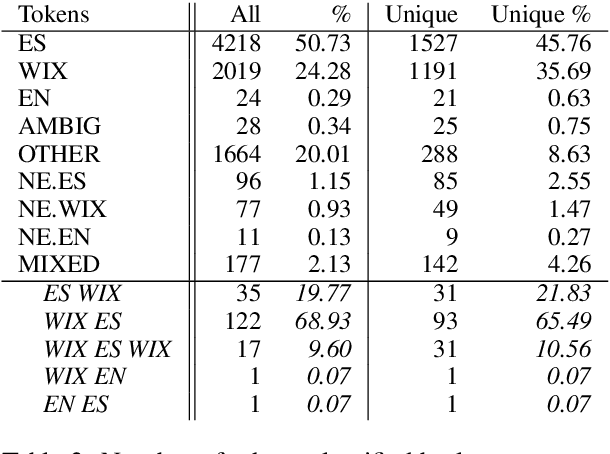
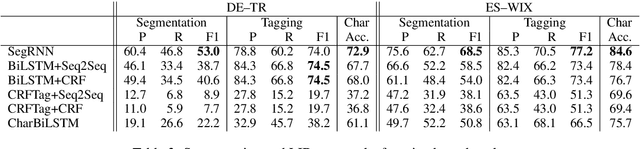
Language identification for code-switching (CS), the phenomenon of alternating between two or more languages in conversations, has traditionally been approached under the assumption of a single language per token. However, if at least one language is morphologically rich, a large number of words can be composed of morphemes from more than one language (intra-word CS). In this paper, we extend the language identification task to the subword-level, such that it includes splitting mixed words while tagging each part with a language ID. We further propose a model for this task, which is based on a segmental recurrent neural network. In experiments on a new Spanish--Wixarika dataset and on an adapted German--Turkish dataset, our proposed model performs slightly better than or roughly on par with our best baseline, respectively. Considering only mixed words, however, it strongly outperforms all baselines.
Verb Argument Structure Alternations in Word and Sentence Embeddings
Nov 27, 2018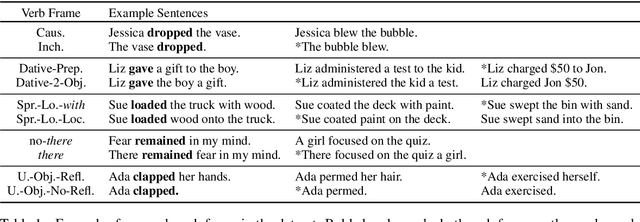
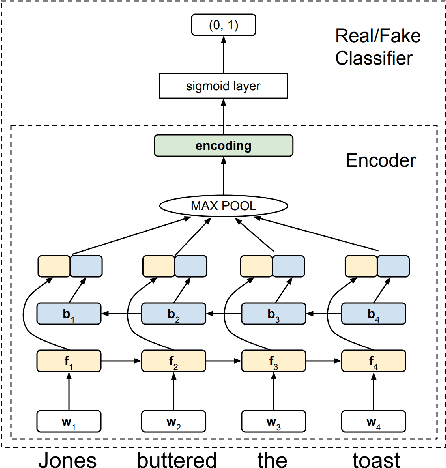

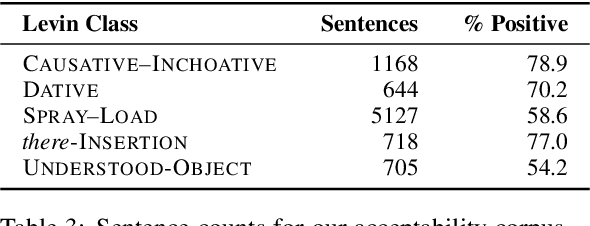
Verbs occur in different syntactic environments, or frames. We investigate whether artificial neural networks encode grammatical distinctions necessary for inferring the idiosyncratic frame-selectional properties of verbs. We introduce five datasets, collectively called FAVA, containing in aggregate nearly 10k sentences labeled for grammatical acceptability, illustrating different verbal argument structure alternations. We then test whether models can distinguish acceptable English verb-frame combinations from unacceptable ones using a sentence embedding alone. For converging evidence, we further construct LaVA, a corresponding word-level dataset, and investigate whether the same syntactic features can be extracted from word embeddings. Our models perform reliable classifications for some verbal alternations but not others, suggesting that while these representations do encode fine-grained lexical information, it is incomplete or can be hard to extract. Further, differences between the word- and sentence-level models show that some information present in word embeddings is not passed on to the down-stream sentence embeddings.
The CoNLL--SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection
Oct 18, 2018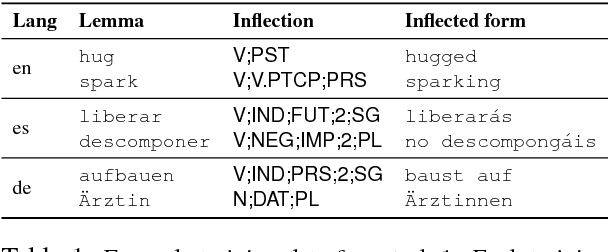
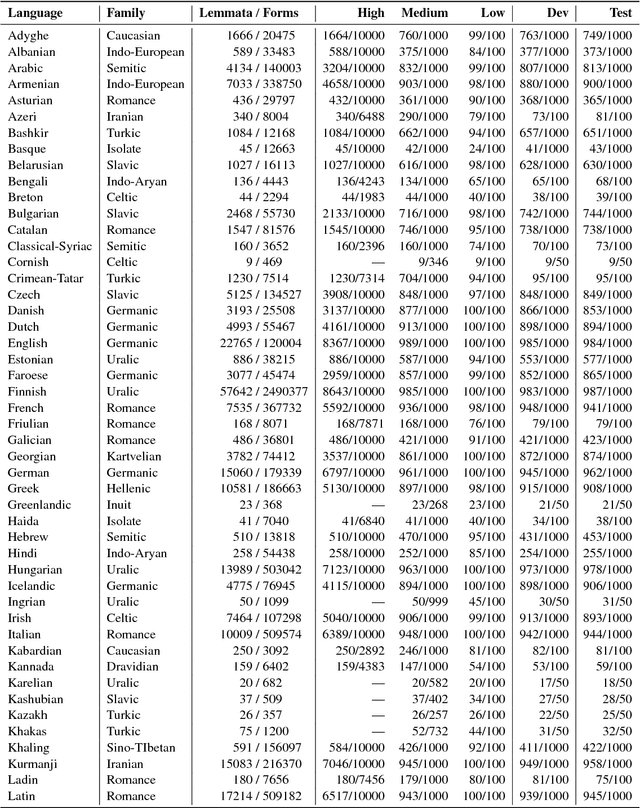
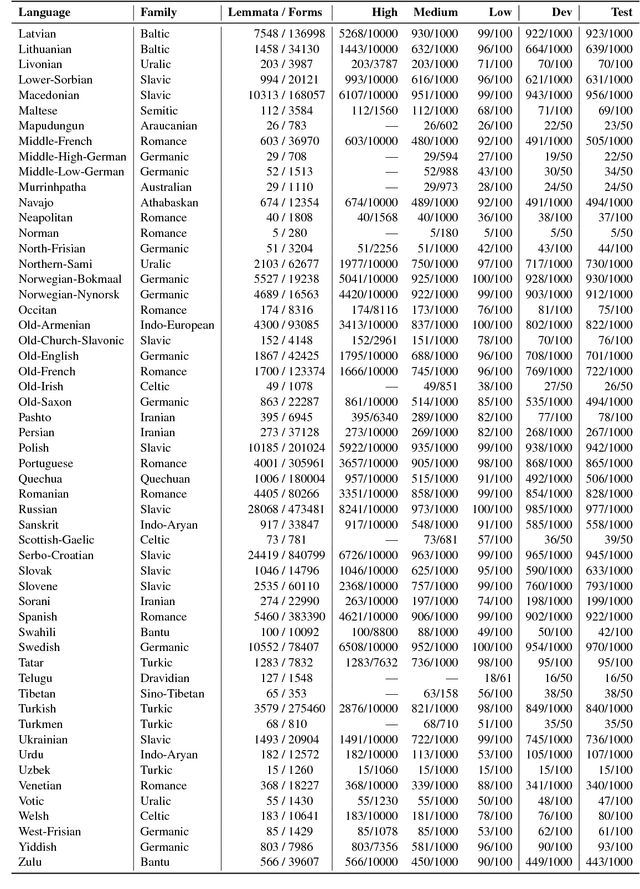

The CoNLL--SIGMORPHON 2018 shared task on supervised learning of morphological generation featured data sets from 103 typologically diverse languages. Apart from extending the number of languages involved in earlier supervised tasks of generating inflected forms, this year the shared task also featured a new second task which asked participants to inflect words in sentential context, similar to a cloze task. This second task featured seven languages. Task 1 received 27 submissions and task 2 received 6 submissions. Both tasks featured a low, medium, and high data condition. Nearly all submissions featured a neural component and built on highly-ranked systems from the earlier 2017 shared task. In the inflection task (task 1), 41 of the 52 languages present in last year's inflection task showed improvement by the best systems in the low-resource setting. The cloze task (task 2) proved to be difficult, and few submissions managed to consistently improve upon both a simple neural baseline system and a lemma-repeating baseline.
Neural Transductive Learning and Beyond: Morphological Generation in the Minimal-Resource Setting
Sep 24, 2018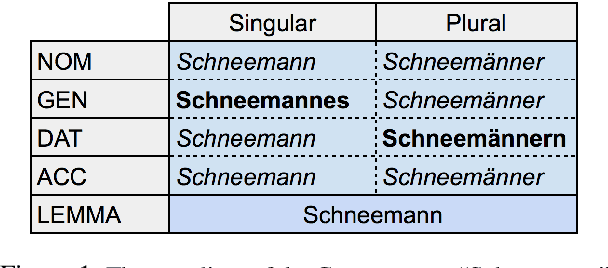
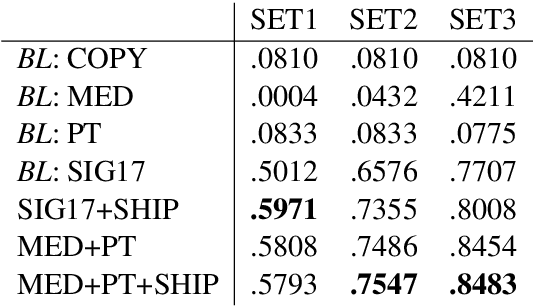

Neural state-of-the-art sequence-to-sequence (seq2seq) models often do not perform well for small training sets. We address paradigm completion, the morphological task of, given a partial paradigm, generating all missing forms. We propose two new methods for the minimal-resource setting: (i) Paradigm transduction: Since we assume only few paradigms available for training, neural seq2seq models are able to capture relationships between paradigm cells, but are tied to the idiosyncracies of the training set. Paradigm transduction mitigates this problem by exploiting the input subset of inflected forms at test time. (ii) Source selection with high precision (SHIP): Multi-source models which learn to automatically select one or multiple sources to predict a target inflection do not perform well in the minimal-resource setting. SHIP is an alternative to identify a reliable source if training data is limited. On a 52-language benchmark dataset, we outperform the previous state of the art by up to 9.71% absolute accuracy.