 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Locomotion via Reinforcement Learning
May 05, 2022
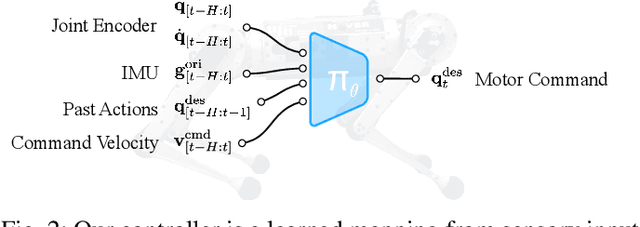
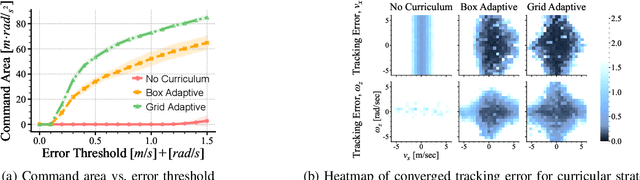
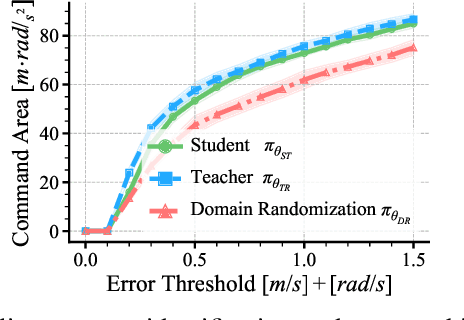
Agile maneuvers such as sprinting and high-speed turning in the wild are challenging for legged robots. We present an end-to-end learned controller that achieves record agility for the MIT Mini Cheetah, sustaining speeds up to 3.9 m/s. This system runs and turns fast on natural terrains like grass, ice, and gravel and responds robustly to disturbances. Our controller is a neural network trained in simulation via reinforcement learning and transferred to the real world. The two key components are (i) an adaptive curriculum on velocity commands and (ii) an online system identification strategy for sim-to-real transfer leveraged from prior work. Videos of the robot's behaviors are available at: https://agility.csail.mit.edu/
Learning to Jump from Pixels
Oct 28, 2021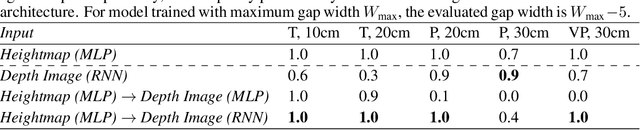
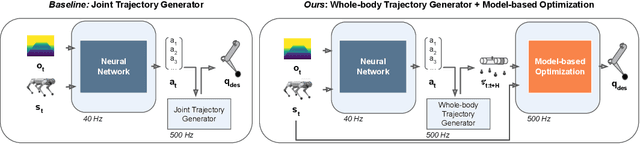
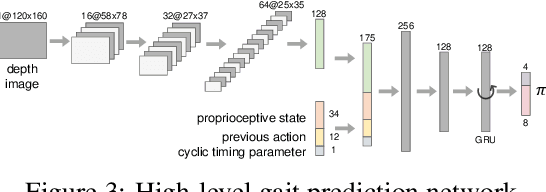
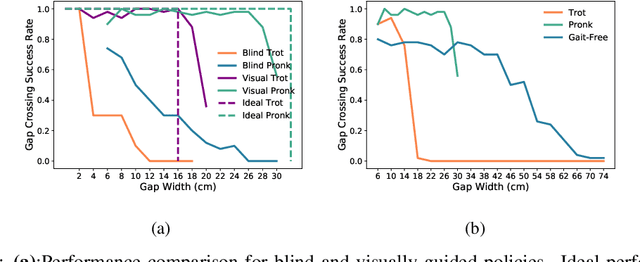
Today's robotic quadruped systems can robustly walk over a diverse range of rough but continuous terrains, where the terrain elevation varies gradually. Locomotion on discontinuous terrains, such as those with gaps or obstacles, presents a complementary set of challenges. In discontinuous settings, it becomes necessary to plan ahead using visual inputs and to execute agile behaviors beyond robust walking, such as jumps. Such dynamic motion results in significant motion of onboard sensors, which introduces a new set of challenges for real-time visual processing. The requirement for agility and terrain awareness in this setting reinforces the need for robust control. We present Depth-based Impulse Control (DIC), a method for synthesizing highly agile visually-guided locomotion behaviors. DIC affords the flexibility of model-free learning but regularizes behavior through explicit model-based optimization of ground reaction forces. We evaluate the proposed method both in simulation and in the real world.
Robust Quadrupedal Locomotion on Sloped Terrains: A Linear Policy Approach
Nov 10, 2020
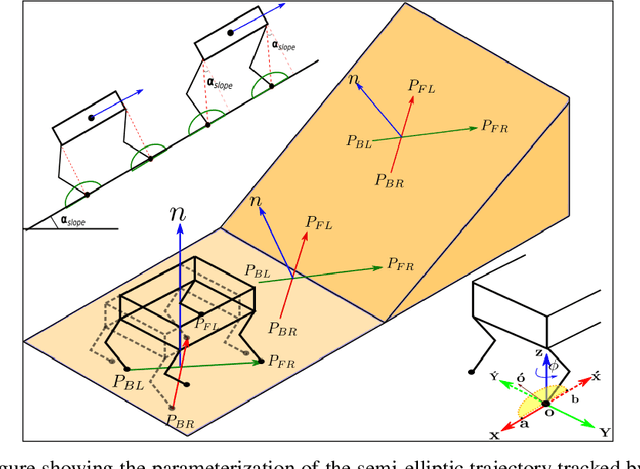
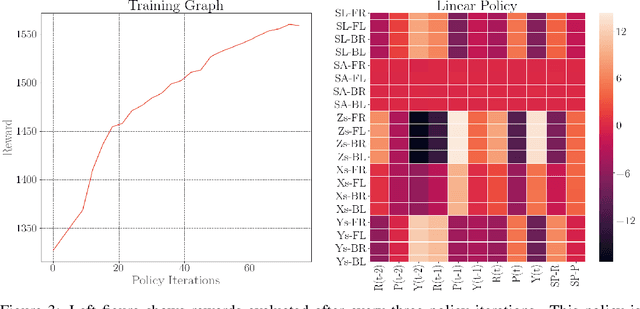
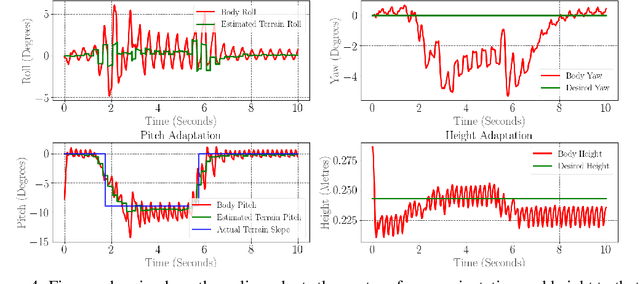
In this paper, with a view toward fast deployment of locomotion gaits in low-cost hardware, we use a linear policy for realizing end-foot trajectories in the quadruped robot, Stoch $2$. In particular, the parameters of the end-foot trajectories are shaped via a linear feedback policy that takes the torso orientation and the terrain slope as inputs. The corresponding desired joint angles are obtained via an inverse kinematics solver and tracked via a PID control law. Augmented Random Search, a model-free and a gradient-free learning algorithm is used to train this linear policy. Simulation results show that the resulting walking is robust to terrain slope variations and external pushes. This methodology is not only computationally light-weight but also uses minimal sensing and actuation capabilities in the robot, thereby justifying the approach.
Learning Stable Manoeuvres in Quadruped Robots from Expert Demonstrations
Jul 28, 2020
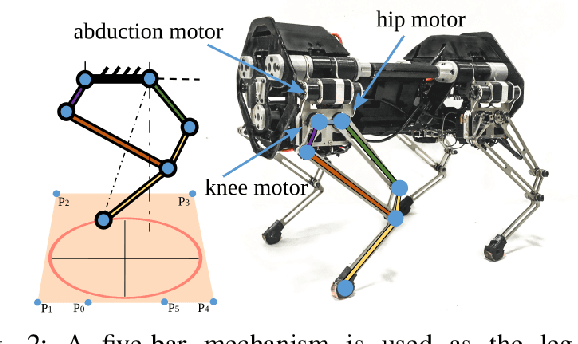
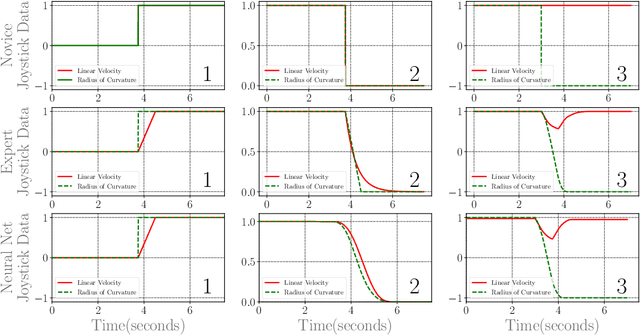
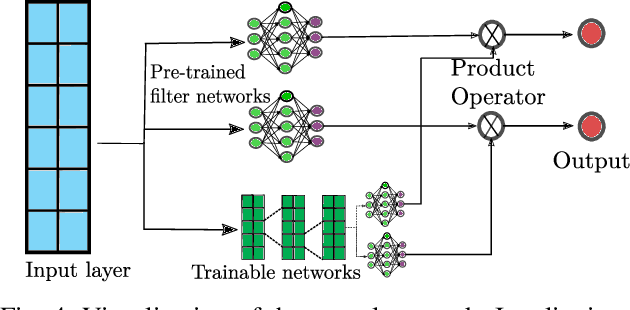
With the research into development of quadruped robots picking up pace, learning based techniques are being explored for developing locomotion controllers for such robots. A key problem is to generate leg trajectories for continuously varying target linear and angular velocities, in a stable manner. In this paper, we propose a two pronged approach to address this problem. First, multiple simpler policies are trained to generate trajectories for a discrete set of target velocities and turning radius. These policies are then augmented using a higher level neural network for handling the transition between the learned trajectories. Specifically, we develop a neural network-based filter that takes in target velocity, radius and transforms them into new commands that enable smooth transitions to the new trajectory. This transformation is achieved by learning from expert demonstrations. An application of this is the transformation of a novice user's input into an expert user's input, thereby ensuring stable manoeuvres regardless of the user's experience. Training our proposed architecture requires much less expert demonstrations compared to standard neural network architectures. Finally, we demonstrate experimentally these results in the in-house quadruped Stoch 2.
Gait Library Synthesis for Quadruped Robots via Augmented Random Search
Dec 30, 2019
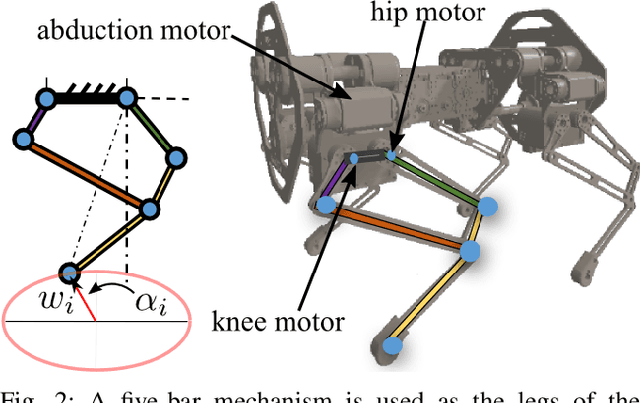
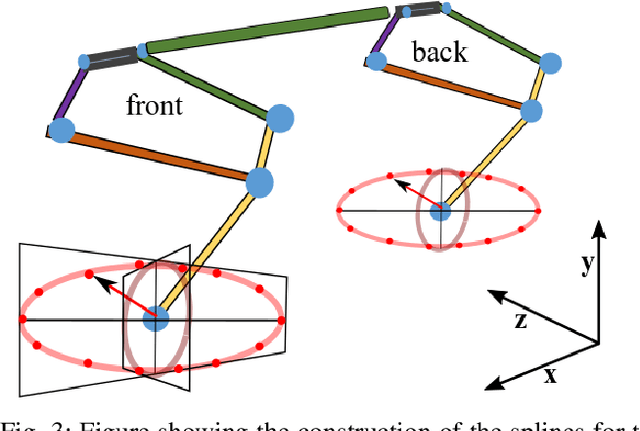
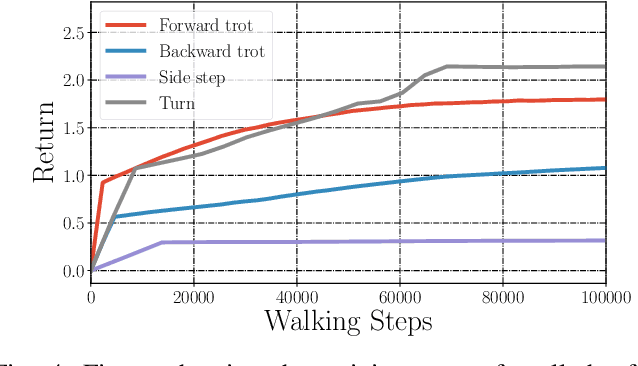
In this paper, with a view toward fast deployment of learned locomotion gaits in low-cost hardware, we generate a library of walking trajectories, namely, forward trot, backward trot, side-step, and turn in our custom-built quadruped robot, Stoch 2, using reinforcement learning. There are existing approaches that determine optimal policies for each time step, whereas we determine an optimal policy, in the form of end-foot trajectories, for each half walking step i.e., swing phase and stance phase. The way-points for the foot trajectories are obtained from a linear policy, i.e., a linear function of the states of the robot, and cubic splines are used to interpolate between these points. Augmented Random Search, a model-free and gradient-free learning algorithm is used to learn the policy in simulation. This learned policy is then deployed on hardware, yielding a trajectory in every half walking step. Different locomotion patterns are learned in simulation by enforcing a preconfigured phase shift between the trajectories of different legs. The transition from one gait to another is achieved by using a low-pass filter for the phase, and the sim-to-real transfer is improved by a linear transformation of the states obtained through regression.