 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Linear Bandits with Protected Subspace
Nov 02, 2020We study a variant of the stochastic linear bandit problem wherein we optimize a linear objective function but rewards are accrued only orthogonal to an unknown subspace (which we interpret as a \textit{protected space}) given only zero-order stochastic oracle access to both the objective itself and protected subspace. In particular, at each round, the learner must choose whether to query the objective or the protected subspace alongside choosing an action. Our algorithm, derived from the OFUL principle, uses some of the queries to get an estimate of the protected space, and (in almost all rounds) plays optimistically with respect to a confidence set for this space. We provide a $\tilde{O}(sd\sqrt{T})$ regret upper bound in the case where the action space is the complete unit ball in $\mathbb{R}^d$, $s < d$ is the dimension of the protected subspace, and $T$ is the time horizon. Moreover, we demonstrate that a discrete action space can lead to linear regret with an optimistic algorithm, reinforcing the sub-optimality of optimism in certain settings. We also show that protection constraints imply that for certain settings, no consistent algorithm can have a regret smaller than $\Omega(T^{3/4}).$ We finally empirically validate our results with synthetic and real datasets.
Active Structure Learning of Causal DAGs via Directed Clique Tree
Nov 01, 2020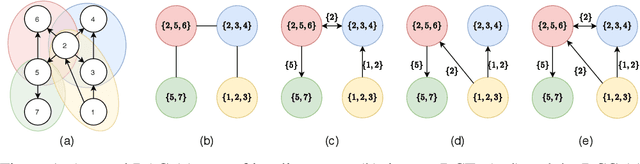
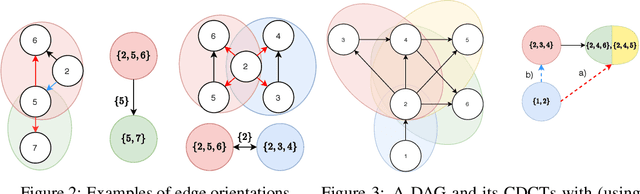
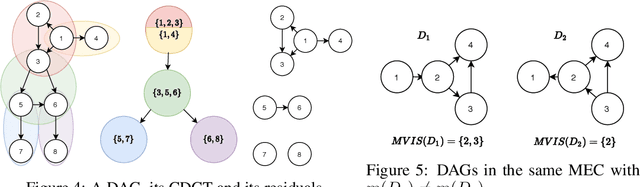
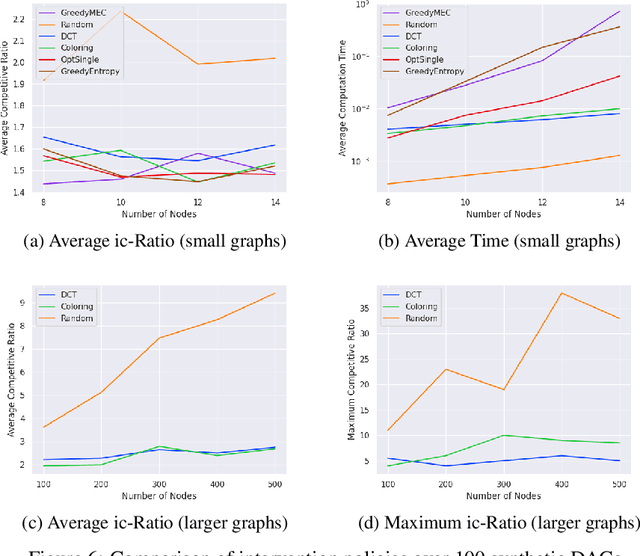
A growing body of work has begun to study intervention design for efficient structure learning of causal directed acyclic graphs (DAGs). A typical setting is a causally sufficient setting, i.e. a system with no latent confounders, selection bias, or feedback, when the essential graph of the observational equivalence class (EC) is given as an input and interventions are assumed to be noiseless. Most existing works focus on worst-case or average-case lower bounds for the number of interventions required to orient a DAG. These worst-case lower bounds only establish that the largest clique in the essential graph could make it difficult to learn the true DAG. In this work, we develop a universal lower bound for single-node interventions that establishes that the largest clique is always a fundamental impediment to structure learning. Specifically, we present a decomposition of a DAG into independently orientable components through directed clique trees and use it to prove that the number of single-node interventions necessary to orient any DAG in an EC is at least the sum of half the size of the largest cliques in each chain component of the essential graph. Moreover, we present a two-phase intervention design algorithm that, under certain conditions on the chordal skeleton, matches the optimal number of interventions up to a multiplicative logarithmic factor in the number of maximal cliques. We show via synthetic experiments that our algorithm can scale to much larger graphs than most of the related work and achieves better worst-case performance than other scalable approaches. A code base to recreate these results can be found at https://github.com/csquires/dct-policy
Empirical or Invariant Risk Minimization? A Sample Complexity Perspective
Oct 30, 2020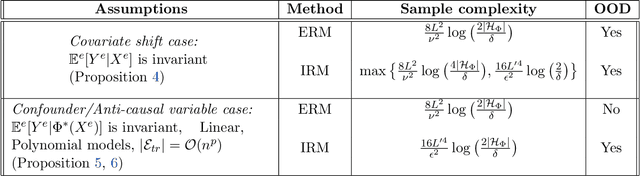
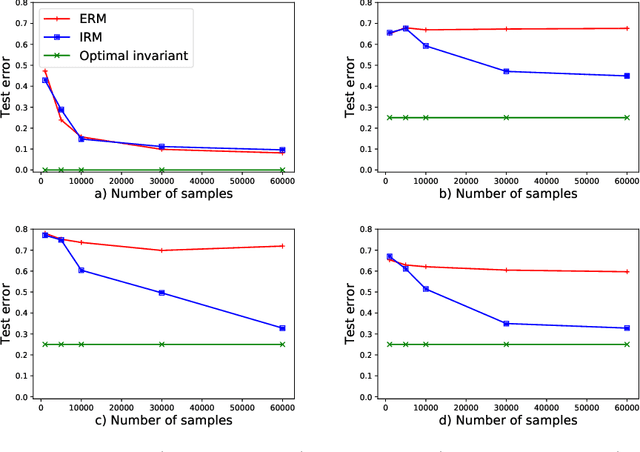
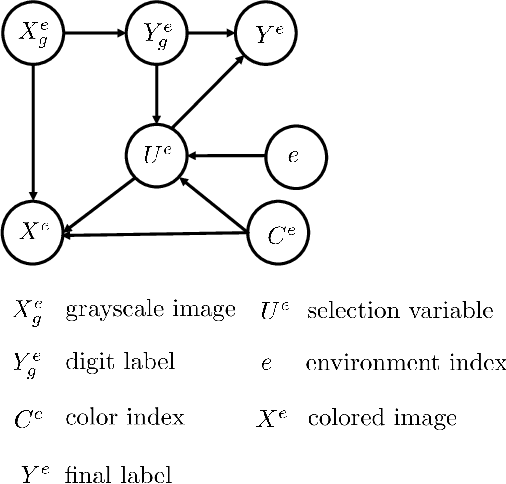
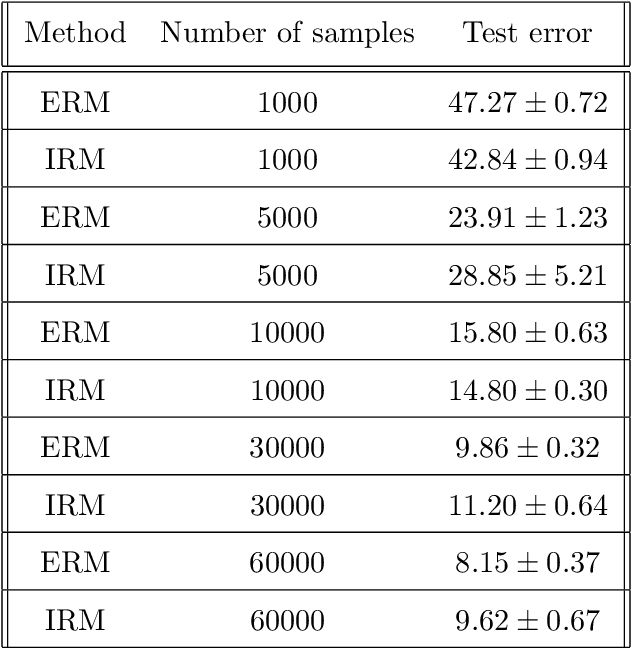
Recently, invariant risk minimization (IRM) was proposed as a promising solution to address out-of-distribution (OOD) generalization. However, it is unclear when IRM should be preferred over the widely-employed empirical risk minimization (ERM) framework. In this work, we analyze both these frameworks from the perspective of sample complexity, thus taking a firm step towards answering this important question. We find that depending on the type of data generation mechanism, the two approaches might have very different finite sample and asymptotic behavior. For example, in the covariate shift setting we see that the two approaches not only arrive at the same asymptotic solution, but also have similar finite sample behavior with no clear winner. For other distribution shifts such as those involving confounders or anti-causal variables, however, the two approaches arrive at different asymptotic solutions where IRM is guaranteed to be close to the desired OOD solutions in the finite sample regime, while ERM is biased even asymptotically. We further investigate how different factors -- the number of environments, complexity of the model, and IRM penalty weight -- impact the sample complexity of IRM in relation to its distance from the OOD solutions
Linear Regression Games: Convergence Guarantees to Approximate Out-of-Distribution Solutions
Oct 28, 2020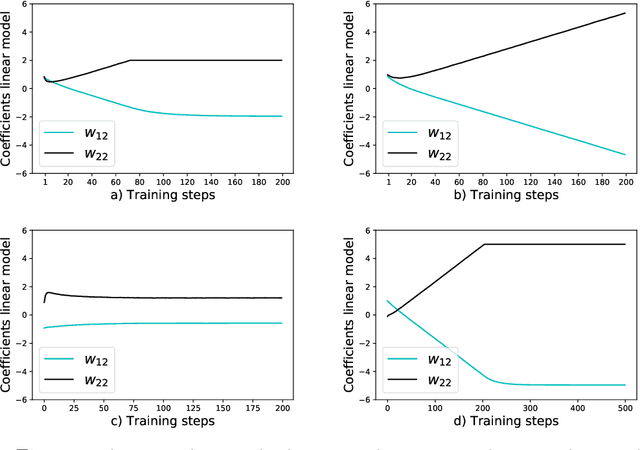
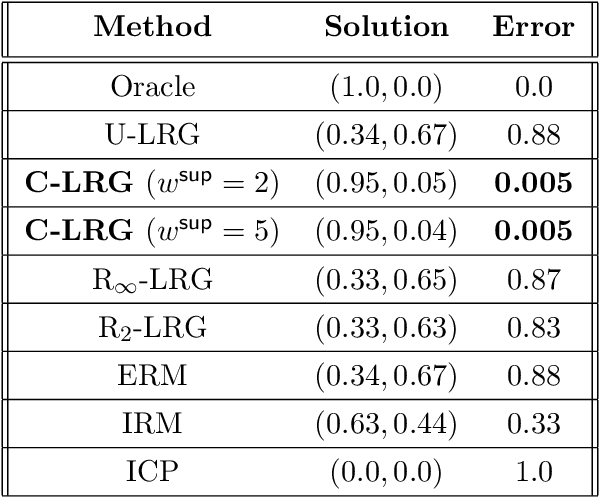
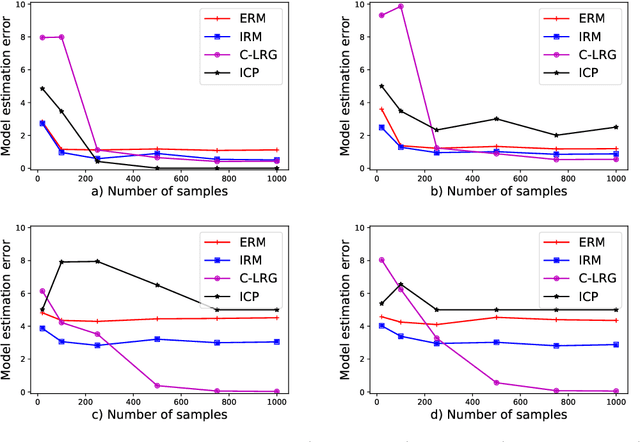
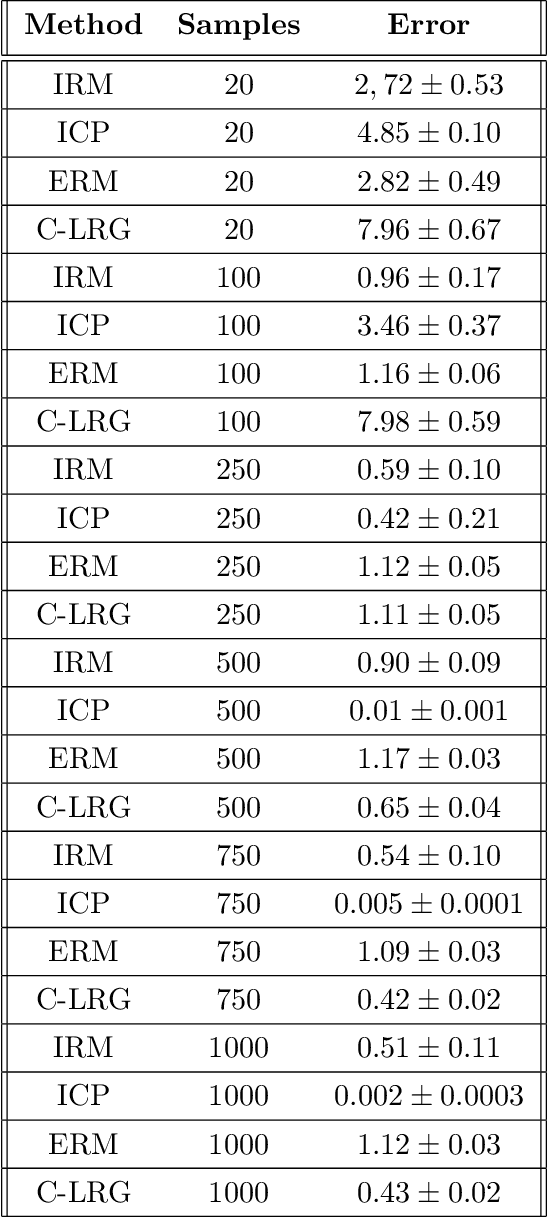
Recently, invariant risk minimization (IRM) (Arjovsky et al.) was proposed as a promising solution to address out-of-distribution (OOD) generalization. In Ahuja et al., it was shown that solving for the Nash equilibria of a new class of "ensemble-games" is equivalent to solving IRM. In this work, we extend the framework in Ahuja et al. for linear regressions by projecting the ensemble-game on an $\ell_{\infty}$ ball. We show that such projections help achieve non-trivial OOD guarantees despite not achieving perfect invariance. For linear models with confounders, we prove that Nash equilibria of these games are closer to the ideal OOD solutions than the standard empirical risk minimization (ERM) and we also provide learning algorithms that provably converge to these Nash Equilibria. Empirical comparisons of the proposed approach with the state-of-the-art show consistent gains in achieving OOD solutions in several settings involving anti-causal variables and confounders.
Fair Data Integration
Jun 10, 2020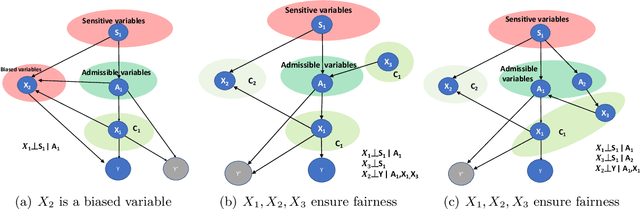
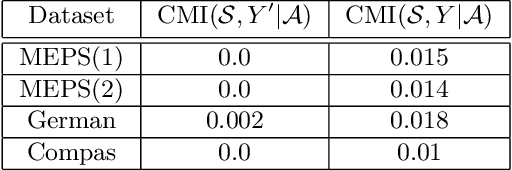
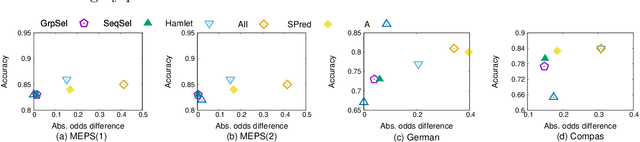
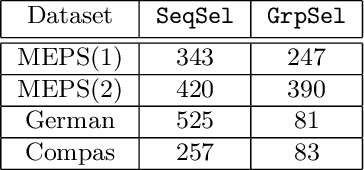
The use of machine learning (ML) in high-stakes societal decisions has encouraged the consideration of fairness throughout the ML lifecycle. Although data integration is one of the primary steps to generate high quality training data, most of the fairness literature ignores this stage. In this work, we consider fairness in the integration component of data management, aiming to identify features that improve prediction without adding any bias to the dataset. We work under the causal interventional fairness paradigm. Without requiring the underlying structural causal model a priori, we propose an approach to identify a sub-collection of features that ensure the fairness of the dataset by performing conditional independence tests between different subsets of features. We use group testing to improve the complexity of the approach. We theoretically prove the correctness of the proposed algorithm to identify features that ensure interventional fairness and show that sub-linear conditional independence tests are sufficient to identify these variables. A detailed empirical evaluation is performed on real-world datasets to demonstrate the efficacy and efficiency of our technique.
Combinatorial Black-Box Optimization with Expert Advice
Jun 06, 2020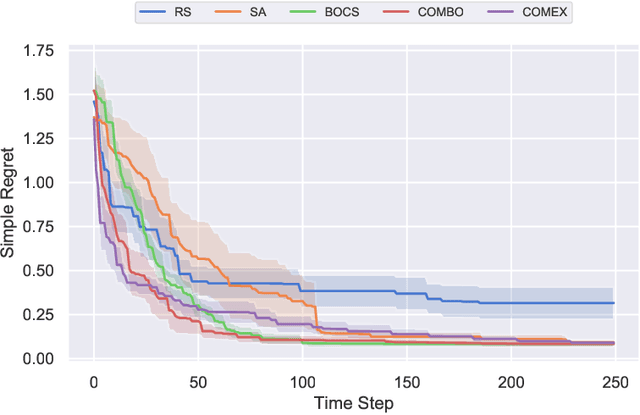
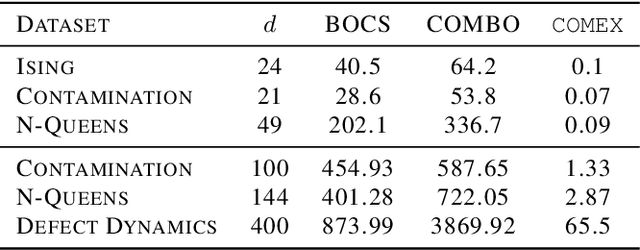
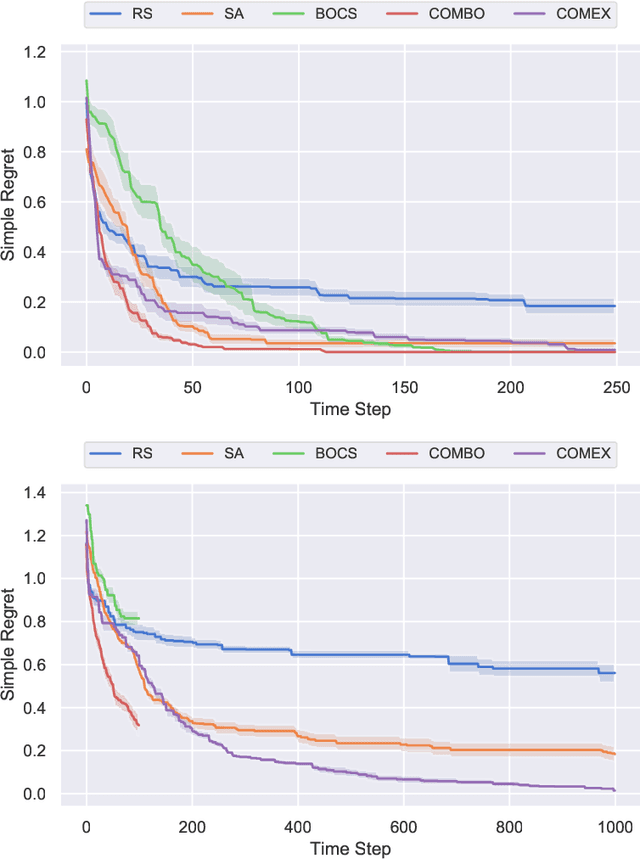
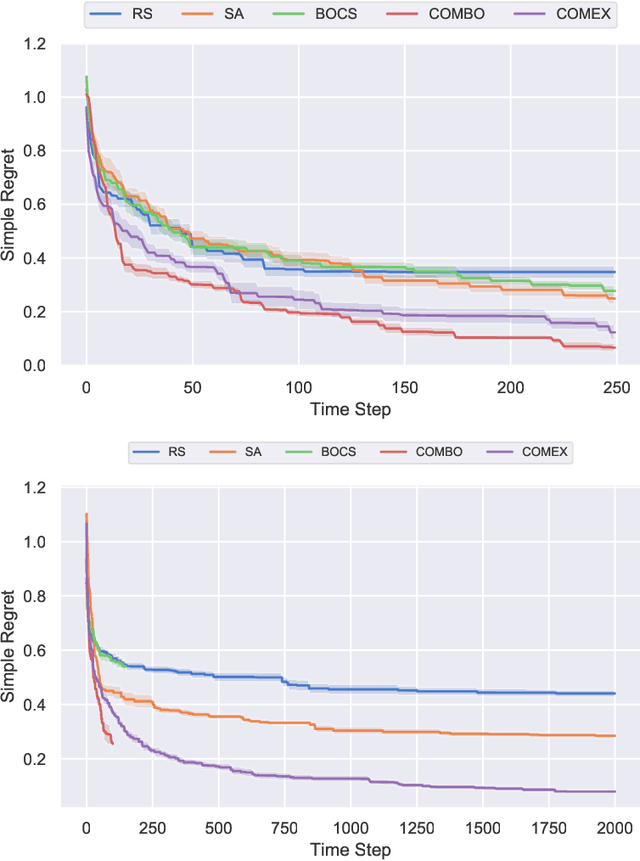
We consider the problem of black-box function optimization over the boolean hypercube. Despite the vast literature on black-box function optimization over continuous domains, not much attention has been paid to learning models for optimization over combinatorial domains until recently. However, the computational complexity of the recently devised algorithms are prohibitive even for moderate numbers of variables; drawing one sample using the existing algorithms is more expensive than a function evaluation for many black-box functions of interest. To address this problem, we propose a computationally efficient model learning algorithm based on multilinear polynomials and exponential weight updates. In the proposed algorithm, we alternate between simulated annealing with respect to the current polynomial representation and updating the weights using monomial experts' advice. Numerical experiments on various datasets in both unconstrained and sum-constrained boolean optimization indicate the competitive performance of the proposed algorithm, while improving the computational time up to several orders of magnitude compared to state-of-the-art algorithms in the literature.
Invariant Risk Minimization Games
Mar 18, 2020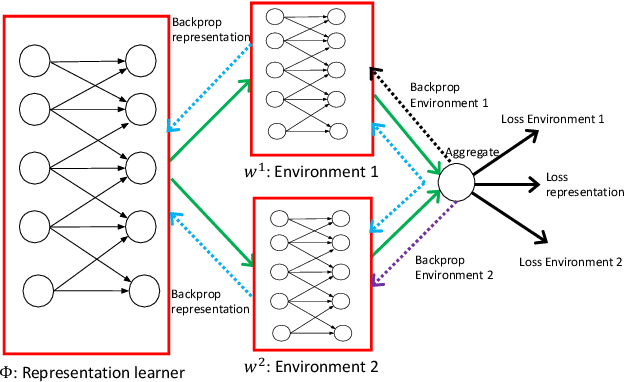
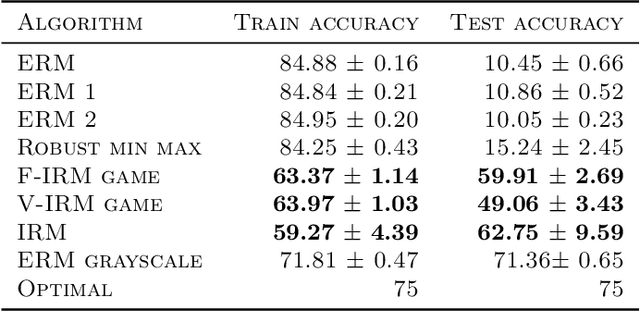
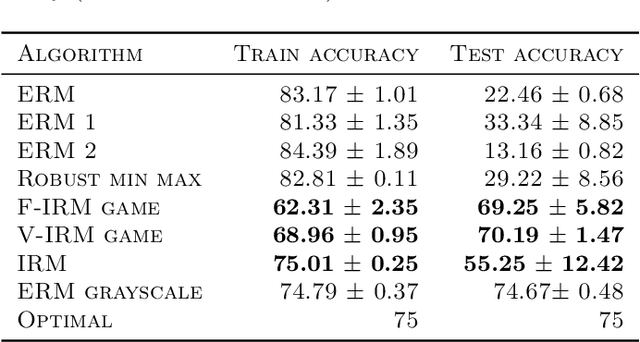
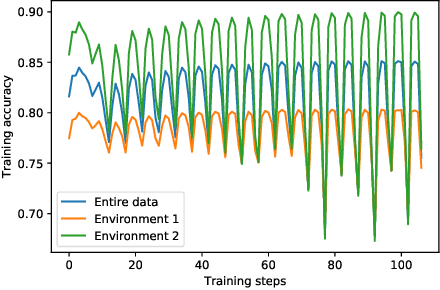
The standard risk minimization paradigm of machine learning is brittle when operating in environments whose test distributions are different from the training distribution due to spurious correlations. Training on data from many environments and finding invariant predictors reduces the effect of spurious features by concentrating models on features that have a causal relationship with the outcome. In this work, we pose such invariant risk minimization as finding the Nash equilibrium of an ensemble game among several environments. By doing so, we develop a simple training algorithm that uses best response dynamics and, in our experiments, yields similar or better empirical accuracy with much lower variance than the challenging bi-level optimization problem of Arjovsky et al. (2019). One key theoretical contribution is showing that the set of Nash equilibria for the proposed game are equivalent to the set of invariant predictors for any finite number of environments, even with nonlinear classifiers and transformations. As a result, our method also retains the generalization guarantees to a large set of environments shown in Arjovsky et al. (2019). The proposed algorithm adds to the collection of successful game-theoretic machine learning algorithms such as generative adversarial networks.
A Multi-Channel Neural Graphical Event Model with Negative Evidence
Feb 21, 2020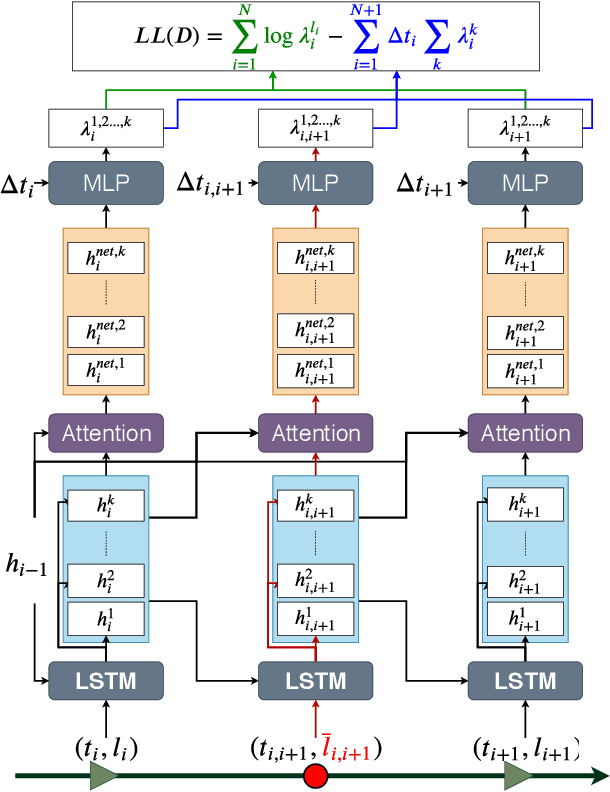
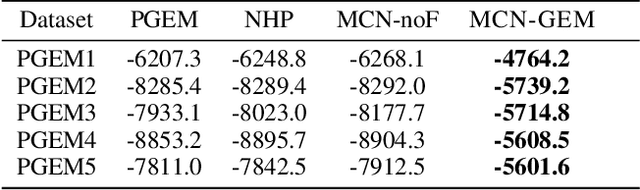
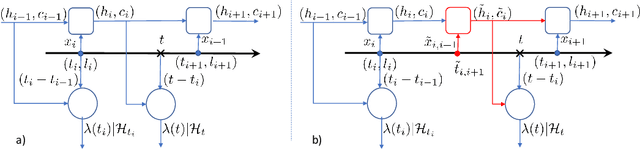
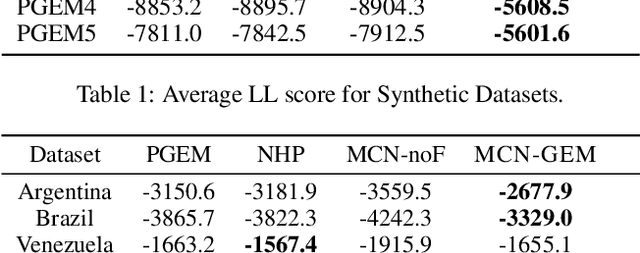
Event datasets are sequences of events of various types occurring irregularly over the time-line, and they are increasingly prevalent in numerous domains. Existing work for modeling events using conditional intensities rely on either using some underlying parametric form to capture historical dependencies, or on non-parametric models that focus primarily on tasks such as prediction. We propose a non-parametric deep neural network approach in order to estimate the underlying intensity functions. We use a novel multi-channel RNN that optimally reinforces the negative evidence of no observable events with the introduction of fake event epochs within each consecutive inter-event interval. We evaluate our method against state-of-the-art baselines on model fitting tasks as gauged by log-likelihood. Through experiments on both synthetic and real-world datasets, we find that our proposed approach outperforms existing baselines on most of the datasets studied.
Warm Starting Bandits with Side Information from Confounded Data
Feb 19, 2020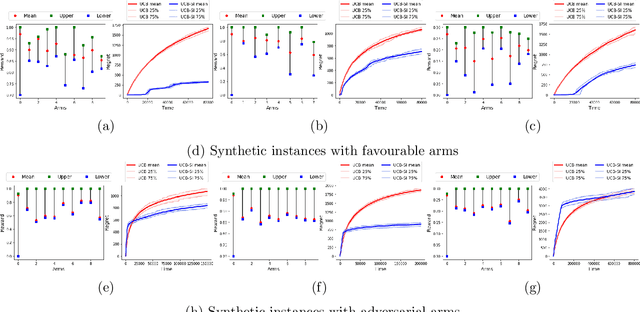
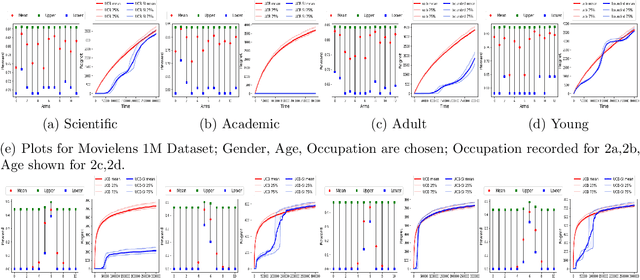
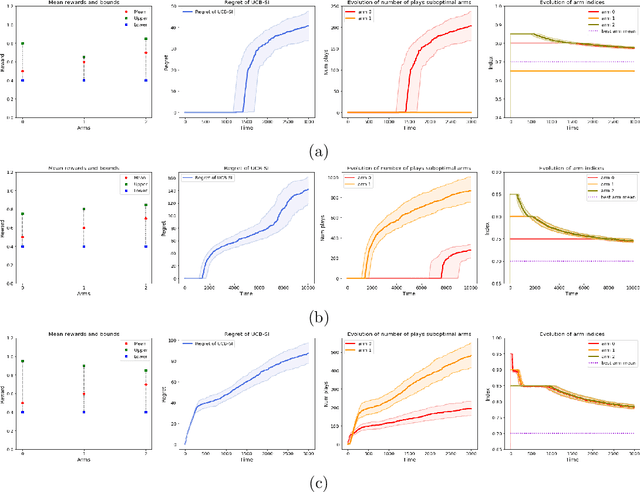
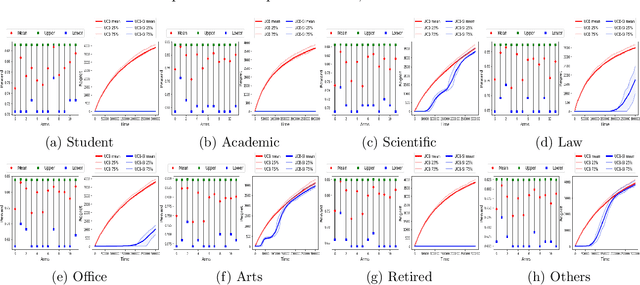
We study a variant of the multi-armed bandit problem where side information in the form of bounds on the mean of each arm is provided. We describe how these bounds on the means can be used efficiently for warm starting bandits. Specifically, we propose the novel UCB-SI algorithm, and illustrate improvements in cumulative regret over the standard UCB algorithm, both theoretically and empirically, in the presence of non-trivial side information. As noted in (Zhang & Bareinboim, 2017), such information arises, for instance, when we have prior logged data on the arms, but this data has been collected under a policy whose choice of arms is based on latent variables to which access is no longer available. We further provide a novel approach for obtaining such bounds from prior partially confounded data under some mild assumptions. We validate our findings through semi-synthetic experiments on data derived from real datasets.
Learning Global Transparent Models from Local Contrastive Explanations
Feb 19, 2020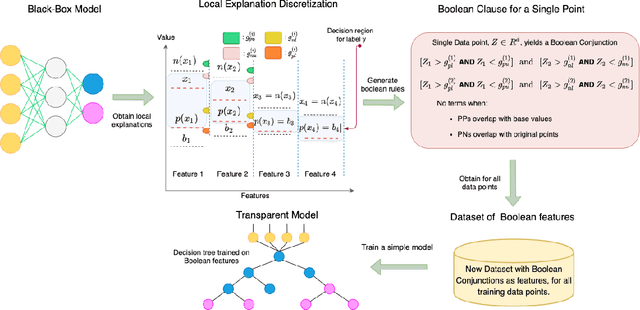
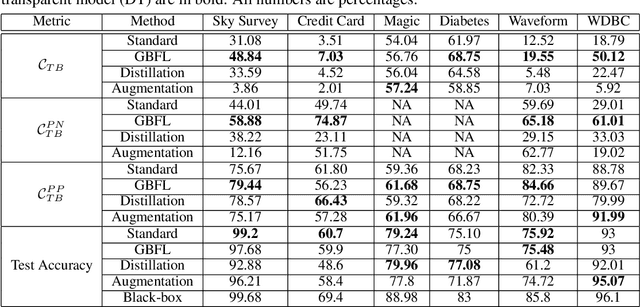
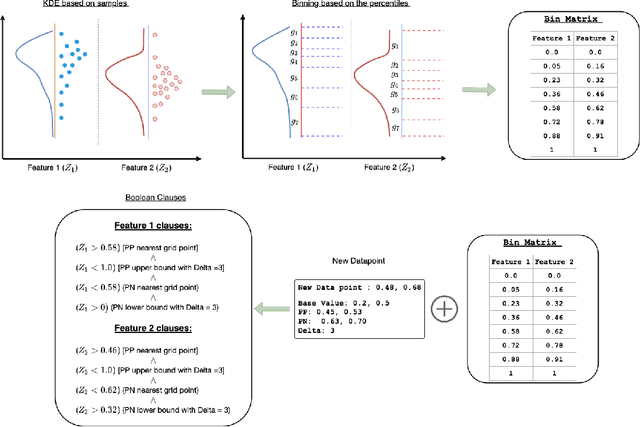
There is a rich and growing literature on producing local point wise contrastive/counterfactual explanations for complex models. These methods highlight what is important to justify the classification and/or produce a contrast point that alters the final classification. Other works try to build globally interpretable models like decision trees and rule lists directly by efficient model search using the data or by transferring information from a complex model using distillation-like methods. Although these interpretable global models can be useful, they may not be consistent with local explanations from a specific complex model of choice. In this work, we explore the question: Can we produce a transparent global model that is consistent with/derivable from local explanations? Based on a key insight we provide a novel method where every local contrastive/counterfactual explanation can be turned into a Boolean feature. These Boolean features are sparse conjunctions of binarized features. The dataset thus constructed is consistent with local explanations by design and one can train an interpretable model like a decision tree on it. We note that this approach strictly loses information due to reliance only on sparse local explanations, nonetheless, we demonstrate empirically that in many cases it can still be competitive with respect to the complex model's performance and also other methods that learn directly from the original dataset. Our approach also provides an avenue to benchmark local explanation methods in a quantitative manner.