 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour fairness may vary: Group fairness of pretrained language models in toxic text classification
Aug 03, 2021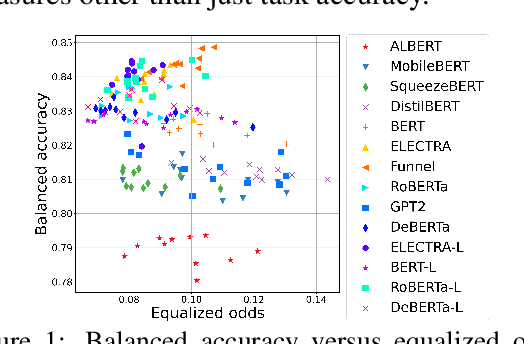
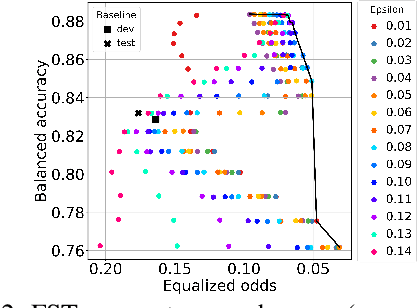
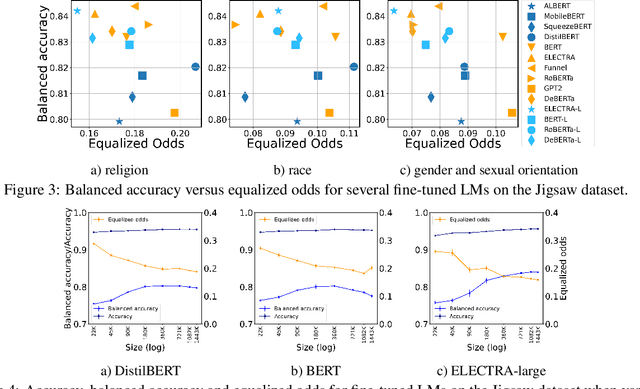
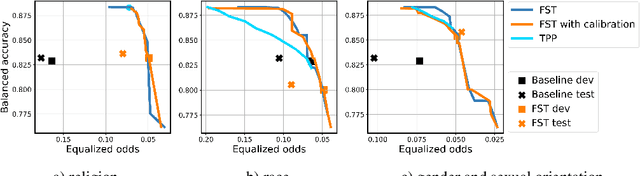
We study the performance-fairness trade-off in more than a dozen fine-tuned LMs for toxic text classification. We empirically show that no blanket statement can be made with respect to the bias of large versus regular versus compressed models. Moreover, we find that focusing on fairness-agnostic performance metrics can lead to models with varied fairness characteristics.
Augmenting Molecular Deep Generative Models with Topological Data Analysis Representations
Jun 08, 2021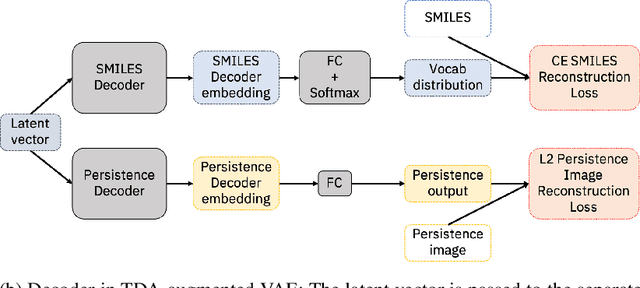


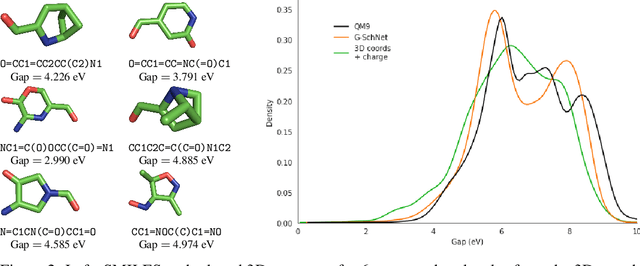
Deep generative models have emerged as a powerful tool for learning informative molecular representations and designing novel molecules with desired properties, with applications in drug discovery and material design. Deep generative auto-encoders defined over molecular SMILES strings have been a popular choice for that purpose. However, capturing salient molecular properties like quantum-chemical energies remains challenging and requires sophisticated neural net models of molecular graphs or geometry-based information. As a simpler and more efficient alternative, we present a SMILES Variational Auto-Encoder (VAE) augmented with topological data analysis (TDA) representations of molecules, known as persistence images. Our experiments show that this TDA augmentation enables a SMILES VAE to capture the complex relation between 3D geometry and electronic properties, and allows generation of novel, diverse, and valid molecules with geometric features consistent with the training data, which exhibit a varying range of global electronic structural properties, such as a small HOMO-LUMO gap - a critical property for designing organic solar cells. We demonstrate that our TDA augmentation yields better success in downstream tasks compared to models trained without these representations and can assist in targeted molecule discovery.
Uncertainty Quantification 360: A Holistic Toolkit for Quantifying and Communicating the Uncertainty of AI
Jun 04, 2021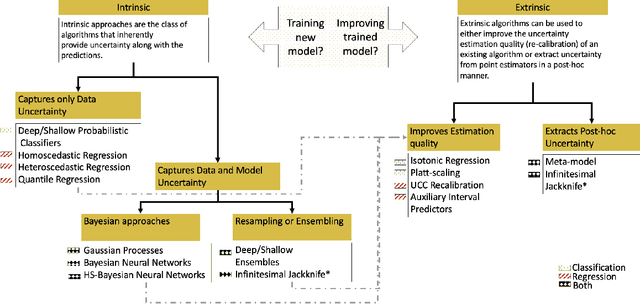
In this paper, we describe an open source Python toolkit named Uncertainty Quantification 360 (UQ360) for the uncertainty quantification of AI models. The goal of this toolkit is twofold: first, to provide a broad range of capabilities to streamline as well as foster the common practices of quantifying, evaluating, improving, and communicating uncertainty in the AI application development lifecycle; second, to encourage further exploration of UQ's connections to other pillars of trustworthy AI such as fairness and transparency through the dissemination of latest research and education materials. Beyond the Python package (\url{https://github.com/IBM/UQ360}), we have developed an interactive experience (\url{http://uq360.mybluemix.net}) and guidance materials as educational tools to aid researchers and developers in producing and communicating high-quality uncertainties in an effective manner.
Finding the Homology of Decision Boundaries with Active Learning
Nov 19, 2020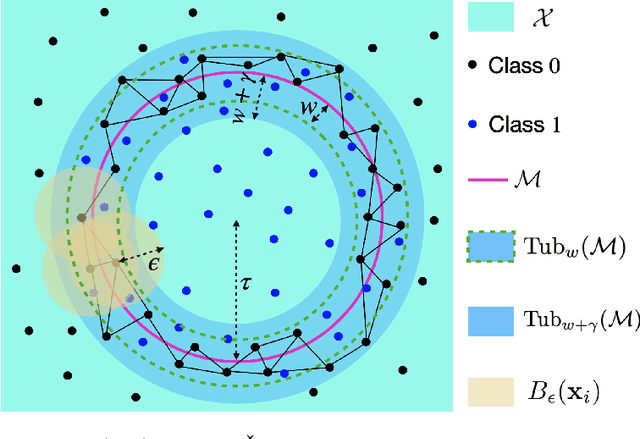
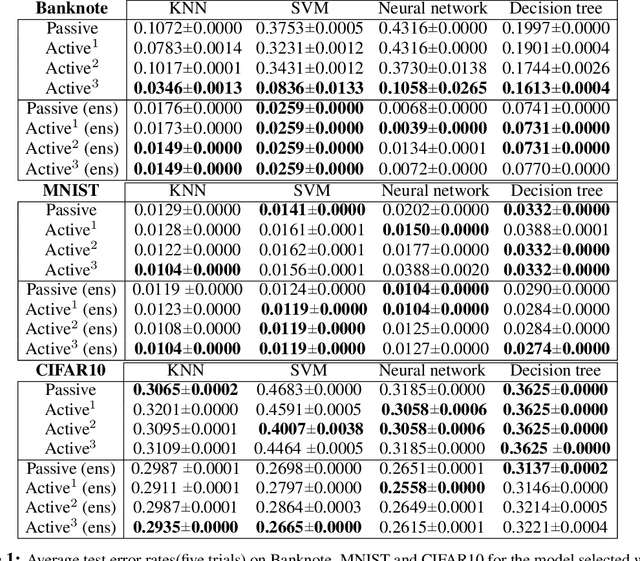

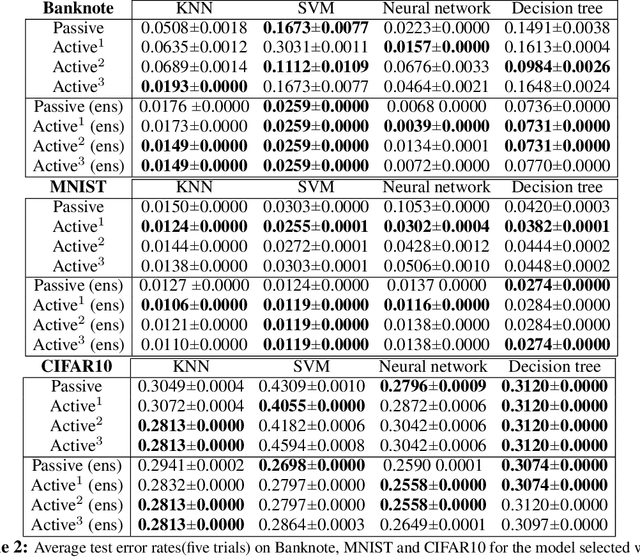
Accurately and efficiently characterizing the decision boundary of classifiers is important for problems related to model selection and meta-learning. Inspired by topological data analysis, the characterization of decision boundaries using their homology has recently emerged as a general and powerful tool. In this paper, we propose an active learning algorithm to recover the homology of decision boundaries. Our algorithm sequentially and adaptively selects which samples it requires the labels of. We theoretically analyze the proposed framework and show that the query complexity of our active learning algorithm depends naturally on the intrinsic complexity of the underlying manifold. We demonstrate the effectiveness of our framework in selecting best-performing machine learning models for datasets just using their respective homological summaries. Experiments on several standard datasets show the sample complexity improvement in recovering the homology and demonstrate the practical utility of the framework for model selection. Source code for our algorithms and experimental results is available at https://github.com/wayne0908/Active-Learning-Homology.
Characterizing the Latent Space of Molecular Deep Generative Models with Persistent Homology Metrics
Oct 18, 2020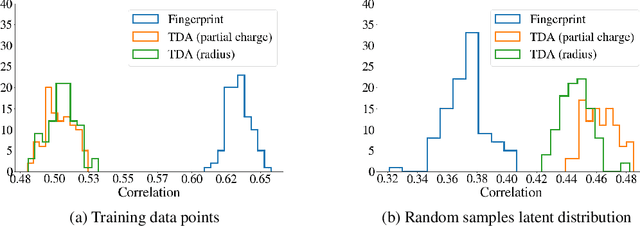
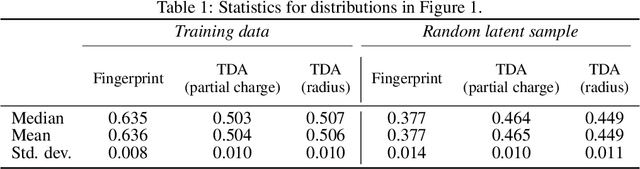
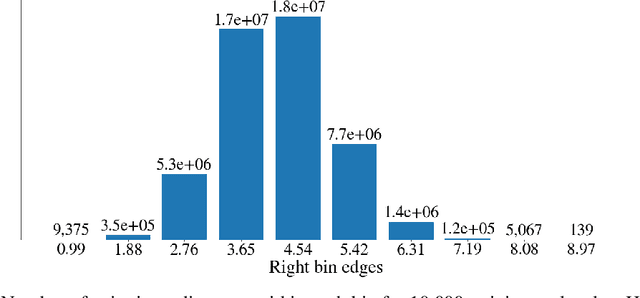
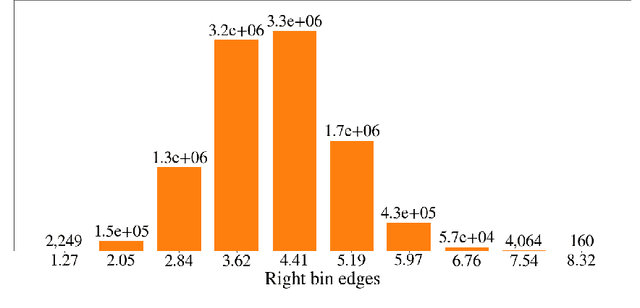
Deep generative models are increasingly becoming integral parts of the in silico molecule design pipeline and have dual goals of learning the chemical and structural features that render candidate molecules viable while also being flexible enough to generate novel designs. Specifically, Variational Auto Encoders (VAEs) are generative models in which encoder-decoder network pairs are trained to reconstruct training data distributions in such a way that the latent space of the encoder network is smooth. Therefore, novel candidates can be found by sampling from this latent space. However, the scope of architectures and hyperparameters is vast and choosing the best combination for in silico discovery has important implications for downstream success. Therefore, it is important to develop a principled methodology for distinguishing how well a given generative model is able to learn salient molecular features. In this work, we propose a method for measuring how well the latent space of deep generative models is able to encode structural and chemical features of molecular datasets by correlating latent space metrics with metrics from the field of topological data analysis (TDA). We apply our evaluation methodology to a VAE trained on SMILES strings and show that 3D topology information is consistently encoded throughout the latent space of the model.
Bridging Mode Connectivity in Loss Landscapes and Adversarial Robustness
Apr 30, 2020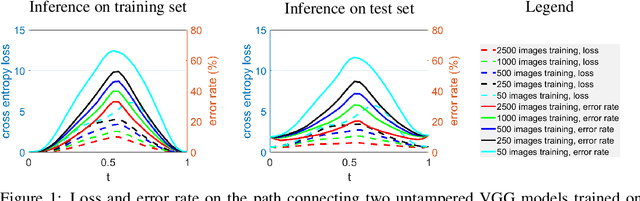

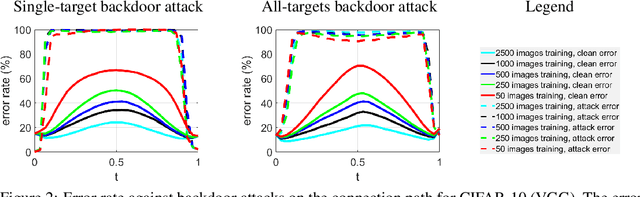
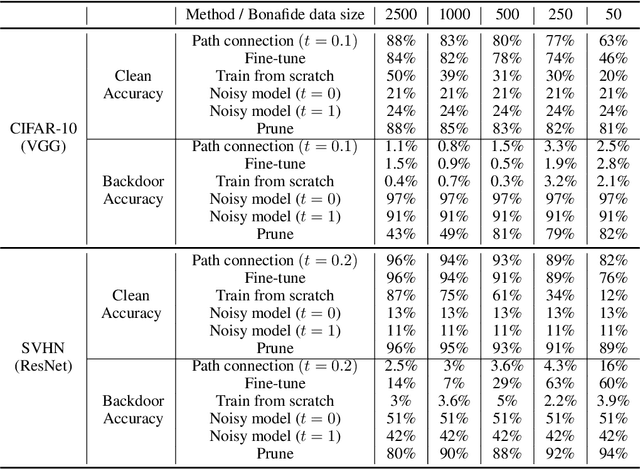
Mode connectivity provides novel geometric insights on analyzing loss landscapes and enables building high-accuracy pathways between well-trained neural networks. In this work, we propose to employ mode connectivity in loss landscapes to study the adversarial robustness of deep neural networks, and provide novel methods for improving this robustness. Our experiments cover various types of adversarial attacks applied to different network architectures and datasets. When network models are tampered with backdoor or error-injection attacks, our results demonstrate that the path connection learned using limited amount of bonafide data can effectively mitigate adversarial effects while maintaining the original accuracy on clean data. Therefore, mode connectivity provides users with the power to repair backdoored or error-injected models. We also use mode connectivity to investigate the loss landscapes of regular and robust models against evasion attacks. Experiments show that there exists a barrier in adversarial robustness loss on the path connecting regular and adversarially-trained models. A high correlation is observed between the adversarial robustness loss and the largest eigenvalue of the input Hessian matrix, for which theoretical justifications are provided. Our results suggest that mode connectivity offers a holistic tool and practical means for evaluating and improving adversarial robustness.
Model Agnostic Multilevel Explanations
Mar 12, 2020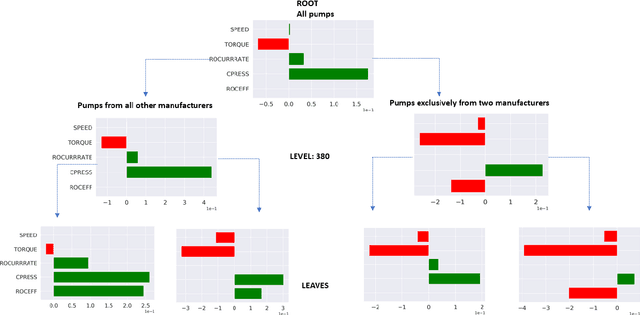
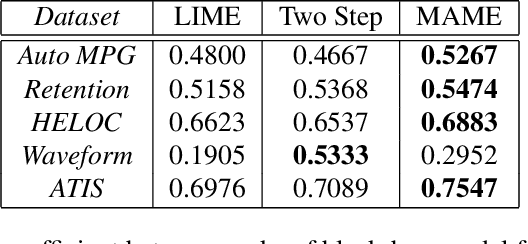
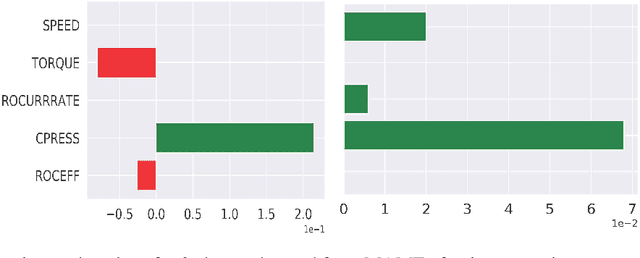
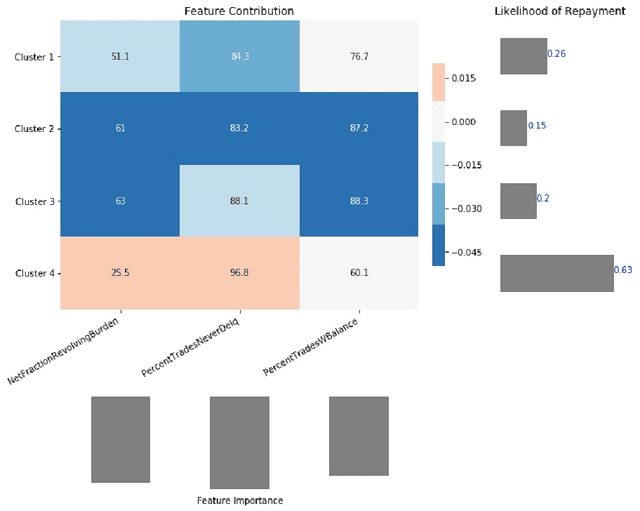
In recent years, post-hoc local instance-level and global dataset-level explainability of black-box models has received a lot of attention. Much less attention has been given to obtaining insights at intermediate or group levels, which is a need outlined in recent works that study the challenges in realizing the guidelines in the General Data Protection Regulation (GDPR). In this paper, we propose a meta-method that, given a typical local explainability method, can build a multilevel explanation tree. The leaves of this tree correspond to the local explanations, the root corresponds to the global explanation, and intermediate levels correspond to explanations for groups of data points that it automatically clusters. The method can also leverage side information, where users can specify points for which they may want the explanations to be similar. We argue that such a multilevel structure can also be an effective form of communication, where one could obtain few explanations that characterize the entire dataset by considering an appropriate level in our explanation tree. Explanations for novel test points can be cost-efficiently obtained by associating them with the closest training points. When the local explainability technique is generalized additive (viz. LIME, GAMs), we develop a fast approximate algorithm for building the multilevel tree and study its convergence behavior. We validate the effectiveness of the proposed technique based on two human studies -- one with experts and the other with non-expert users -- on real world datasets, and show that we produce high fidelity sparse explanations on several other public datasets.
Drug Repurposing for Cancer: An NLP Approach to Identify Low-Cost Therapies
Dec 05, 2019
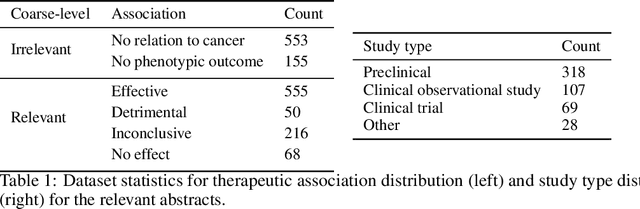
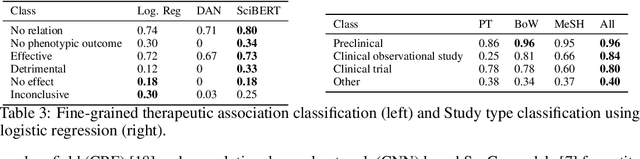
More than 200 generic drugs approved by the U.S. Food and Drug Administration for non-cancer indications have shown promise for treating cancer. Due to their long history of safe patient use, low cost, and widespread availability, repurposing of generic drugs represents a major opportunity to rapidly improve outcomes for cancer patients and reduce healthcare costs worldwide. Evidence on the efficacy of non-cancer generic drugs being tested for cancer exists in scientific publications, but trying to manually identify and extract such evidence is intractable. In this paper, we introduce a system to automate this evidence extraction from PubMed abstracts. Our primary contribution is to define the natural language processing pipeline required to obtain such evidence, comprising the following modules: querying, filtering, cancer type entity extraction, therapeutic association classification, and study type classification. Using the subject matter expertise on our team, we create our own datasets for these specialized domain-specific tasks. We obtain promising performance in each of the modules by utilizing modern language modeling techniques and plan to treat them as baseline approaches for future improvement of individual components.
Understanding racial bias in health using the Medical Expenditure Panel Survey data
Nov 04, 2019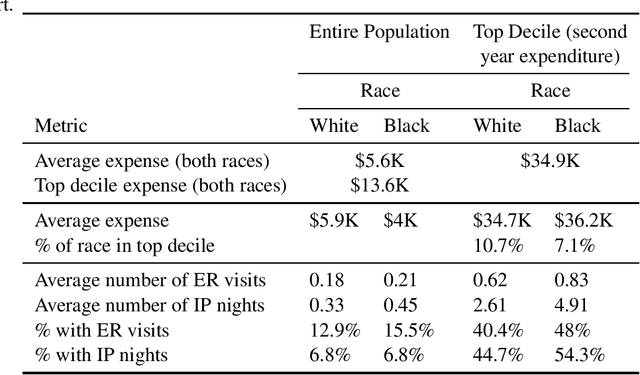
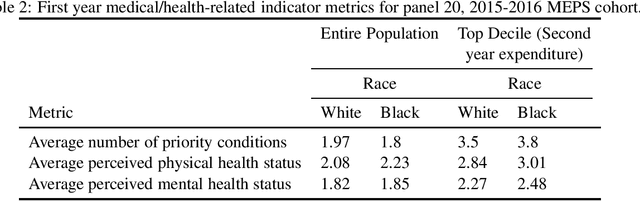
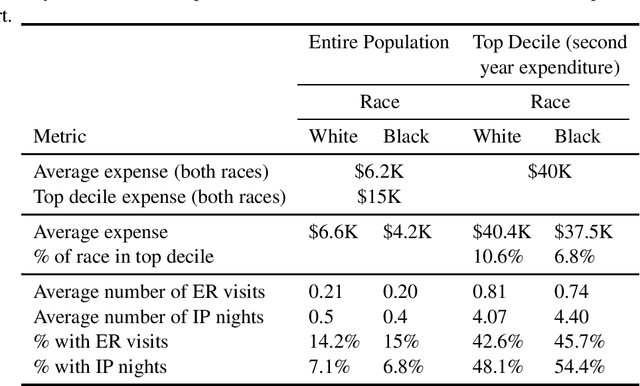
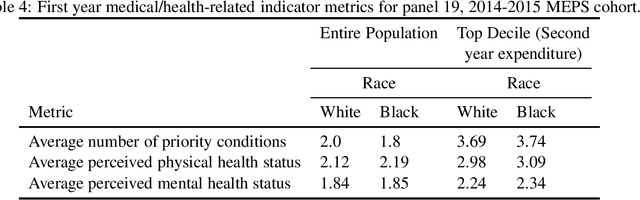
Over the years, several studies have demonstrated that there exist significant disparities in health indicators in the United States population across various groups. Healthcare expense is used as a proxy for health in algorithms that drive healthcare systems and this exacerbates the existing bias. In this work, we focus on the presence of racial bias in health indicators in the publicly available, and nationally representative Medical Expenditure Panel Survey (MEPS) data. We show that predictive models for care management trained using this data inherit this bias. Finally, we demonstrate that this inherited bias can be reduced significantly using simple mitigation techniques.
Teaching AI to Explain its Decisions Using Embeddings and Multi-Task Learning
Jun 05, 2019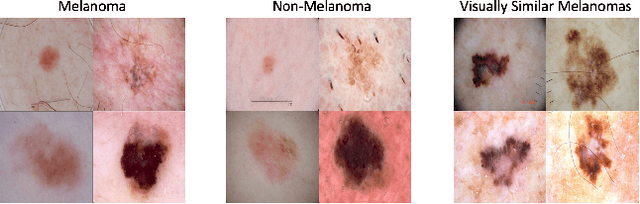
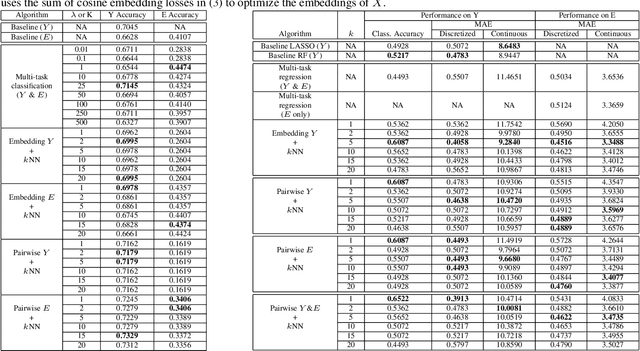
Using machine learning in high-stakes applications often requires predictions to be accompanied by explanations comprehensible to the domain user, who has ultimate responsibility for decisions and outcomes. Recently, a new framework for providing explanations, called TED, has been proposed to provide meaningful explanations for predictions. This framework augments training data to include explanations elicited from domain users, in addition to features and labels. This approach ensures that explanations for predictions are tailored to the complexity expectations and domain knowledge of the consumer. In this paper, we build on this foundational work, by exploring more sophisticated instantiations of the TED framework and empirically evaluate their effectiveness in two diverse domains, chemical odor and skin cancer prediction. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, improving modeling accuracy.