 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHIELD: Secure Hypernetworks for Incremental Expansion Learning Defense
Jun 09, 2025



Traditional deep neural networks suffer from several limitations, including catastrophic forgetting. When models are adapted to new datasets, they tend to quickly forget previously learned knowledge. Another significant issue is the lack of robustness to even small perturbations in the input data. In practice, we can often easily perform adversarial attacks and change the network's predictions, adding minimal noise to the input. Dedicated architectures and training procedures can solve each of the above problems separately. Unfortunately, currently, no model can simultaneously address both catastrophic forgetting and vulnerability to adversarial attacks. We introduce SHIELD (Secure Hypernetworks for Incremental Expansion and Learning Defense), a novel approach that integrates a hypernetwork-based continual learning approach with interval arithmetic. SHIELD use the hypernetwork to transfer trainable task embedding vectors into the weights of a target model dedicated to specific data. This paradigm allows for the dynamic generation of separate networks for each subtask, while the hypernetwork aggregates and analyzes information across all tasks. The target model takes in the input a data sample with a defined interval range, and by creating a hypercube, produces a prediction for the given range. Therefore, such target models provide strict guarantees against all possible attacks for data samples within the interval range. Our approach enhances security without sacrificing network adaptability, addressing the overlooked challenge of safety in continual learning.
FeNeC: Enhancing Continual Learning via Feature Clustering with Neighbor- or Logit-Based Classification
Mar 18, 2025



The ability of deep learning models to learn continuously is essential for adapting to new data categories and evolving data distributions. In recent years, approaches leveraging frozen feature extractors after an initial learning phase have been extensively studied. Many of these methods estimate per-class covariance matrices and prototypes based on backbone-derived feature representations. Within this paradigm, we introduce FeNeC (Feature Neighborhood Classifier) and FeNeC-Log, its variant based on the log-likelihood function. Our approach generalizes the existing concept by incorporating data clustering to capture greater intra-class variability. Utilizing the Mahalanobis distance, our models classify samples either through a nearest neighbor approach or trainable logit values assigned to consecutive classes. Our proposition may be reduced to the existing approaches in a special case while extending them with the ability of more flexible adaptation to data. We demonstrate that two FeNeC variants achieve competitive performance in scenarios where task identities are unknown and establish state-of-the-art results on several benchmarks.
HyConEx: Hypernetwork classifier with counterfactual explanations
Mar 16, 2025In recent years, there has been a growing interest in explainable AI methods. We want not only to make accurate predictions using sophisticated neural networks but also to understand what the model's decision is based on. One of the fundamental levels of interpretability is to provide counterfactual examples explaining the rationale behind the decision and identifying which features, and to what extent, must be modified to alter the model's outcome. To address these requirements, we introduce HyConEx, a classification model based on deep hypernetworks specifically designed for tabular data. Owing to its unique architecture, HyConEx not only provides class predictions but also delivers local interpretations for individual data samples in the form of counterfactual examples that steer a given sample toward an alternative class. While many explainable methods generated counterfactuals for external models, there have been no interpretable classifiers simultaneously producing counterfactual samples so far. HyConEx achieves competitive performance on several metrics assessing classification accuracy and fulfilling the criteria of a proper counterfactual attack. This makes HyConEx a distinctive deep learning model, which combines predictions and explainers as an all-in-one neural network. The code is available at https://github.com/gmum/HyConEx.
SEMU: Singular Value Decomposition for Efficient Machine Unlearning
Feb 11, 2025



While the capabilities of generative foundational models have advanced rapidly in recent years, methods to prevent harmful and unsafe behaviors remain underdeveloped. Among the pressing challenges in AI safety, machine unlearning (MU) has become increasingly critical to meet upcoming safety regulations. Most existing MU approaches focus on altering the most significant parameters of the model. However, these methods often require fine-tuning substantial portions of the model, resulting in high computational costs and training instabilities, which are typically mitigated by access to the original training dataset. In this work, we address these limitations by leveraging Singular Value Decomposition (SVD) to create a compact, low-dimensional projection that enables the selective forgetting of specific data points. We propose Singular Value Decomposition for Efficient Machine Unlearning (SEMU), a novel approach designed to optimize MU in two key aspects. First, SEMU minimizes the number of model parameters that need to be modified, effectively removing unwanted knowledge while making only minimal changes to the model's weights. Second, SEMU eliminates the dependency on the original training dataset, preserving the model's previously acquired knowledge without additional data requirements. Extensive experiments demonstrate that SEMU achieves competitive performance while significantly improving efficiency in terms of both data usage and the number of modified parameters.
HyperInterval: Hypernetwork approach to training weight interval regions in continual learning
May 27, 2024Recently, a new Continual Learning (CL) paradigm was presented to control catastrophic forgetting, called Interval Continual Learning (InterContiNet), which relies on enforcing interval constraints on the neural network parameter space. Unfortunately, InterContiNet training is challenging due to the high dimensionality of the weight space, making intervals difficult to manage. To address this issue, we introduce HyperInterval, a technique that employs interval arithmetic within the embedding space and utilizes a hypernetwork to map these intervals to the target network parameter space. We train interval embeddings for consecutive tasks and train a hypernetwork to transform these embeddings into weights of the target network. An embedding for a given task is trained along with the hypernetwork, preserving the response of the target network for the previous task embeddings. Interval arithmetic works with a more manageable, lower-dimensional embedding space rather than directly preparing intervals in a high-dimensional weight space. Our model allows faster and more efficient training. Furthermore, HyperInterval maintains the guarantee of not forgetting. At the end of training, we can choose one universal embedding to produce a single network dedicated to all tasks. In such a framework, hypernetwork is used only for training and can be seen as a meta-trainer. HyperInterval obtains significantly better results than InterContiNet and gives SOTA results on several benchmarks.
HyperMask: Adaptive Hypernetwork-based Masks for Continual Learning
Oct 11, 2023



Artificial neural networks suffer from catastrophic forgetting when they are sequentially trained on multiple tasks. To overcome this problem, there exist many continual learning strategies. One of the most effective is the hypernetwork-based approach. The hypernetwork generates the weights of a target model based on the task's identity. The model's main limitation is that hypernetwork can produce completely different nests for each task. Consequently, each task is solved separately. The model does not use information from the network dedicated to previous tasks and practically produces new architectures when it learns the subsequent tasks. To solve such a problem, we use the lottery ticket hypothesis, which postulates the existence of sparse subnetworks, named winning tickets, that preserve the performance of a full network. In the paper, we propose a method called HyperMask, which trains a single network for all tasks. Hypernetwork produces semi-binary masks to obtain target subnetworks dedicated to new tasks. This solution inherits the ability of the hypernetwork to adapt to new tasks with minimal forgetting. Moreover, due to the lottery ticket hypothesis, we can use a single network with weighted subnets dedicated to each task.
Stable training of autoencoders for hyperspectral unmixing
Sep 28, 2021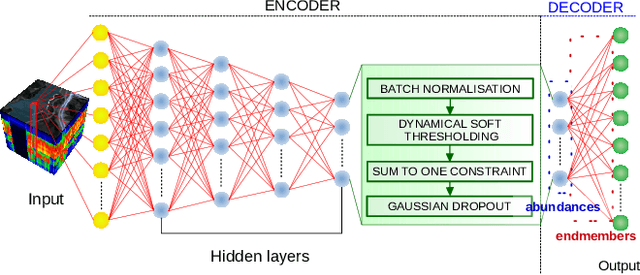

Neural networks, autoencoders in particular, are one of the most promising solutions for unmixing hyperspectral data, i.e. reconstructing the spectra of observed substances (endmembers) and their relative mixing fractions (abundances). Unmixing is needed for effective hyperspectral analysis and classification. However, as we show in this paper, the training of autoencoders for unmixing is highly dependent on weights initialisation. Some sets of weights lead to degenerate or low performance solutions, introducing negative bias in expected performance. In this work we present the results of experiments investigating autoencoders' stability, verifying the dependence of reconstruction error on initial weights and exploring conditions needed for successful optimisation of autoencoder parameters.
Hard hat wearing detection based on head keypoint localization
Jun 21, 2021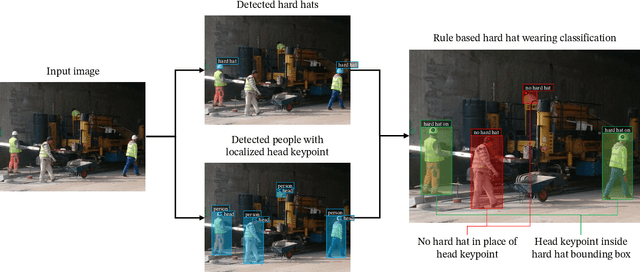
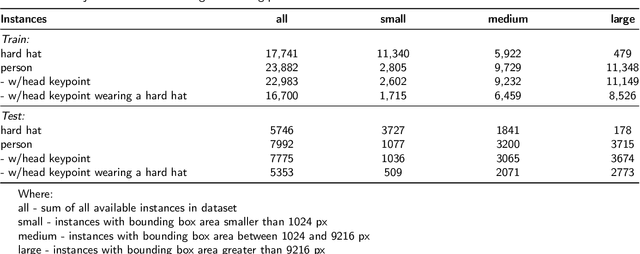
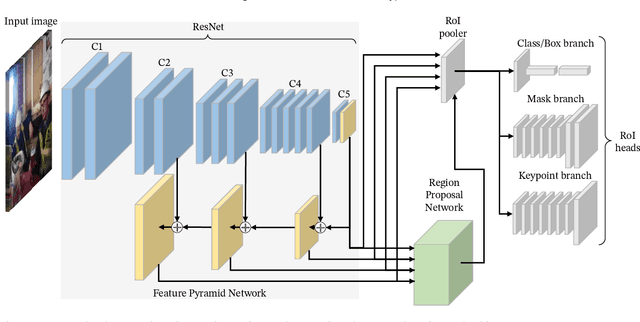
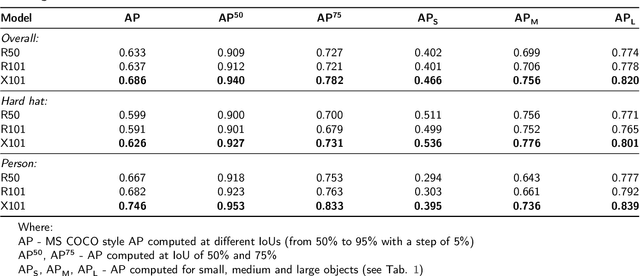
In recent years, a lot of attention is paid to deep learning methods in the context of vision-based construction site safety systems, especially regarding personal protective equipment. However, despite all this attention, there is still no reliable way to establish the relationship between workers and their hard hats. To answer this problem a combination of deep learning, object detection and head keypoint localization, with simple rule-based reasoning is proposed in this article. In tests, this solution surpassed the previous methods based on the relative bounding box position of different instances, as well as direct detection of hard hat wearers and non-wearers. The results show that the conjunction of novel deep learning methods with humanly-interpretable rule-based systems can result in a solution that is both reliable and can successfully mimic manual, on-site supervision. This work is the next step in the development of fully autonomous construction site safety systems and shows that there is still room for improvement in this area.
Hyperspectral classification of blood-like substances using machine learning methods combined with genetic algorithms in transductive and inductive scenarios
Nov 04, 2020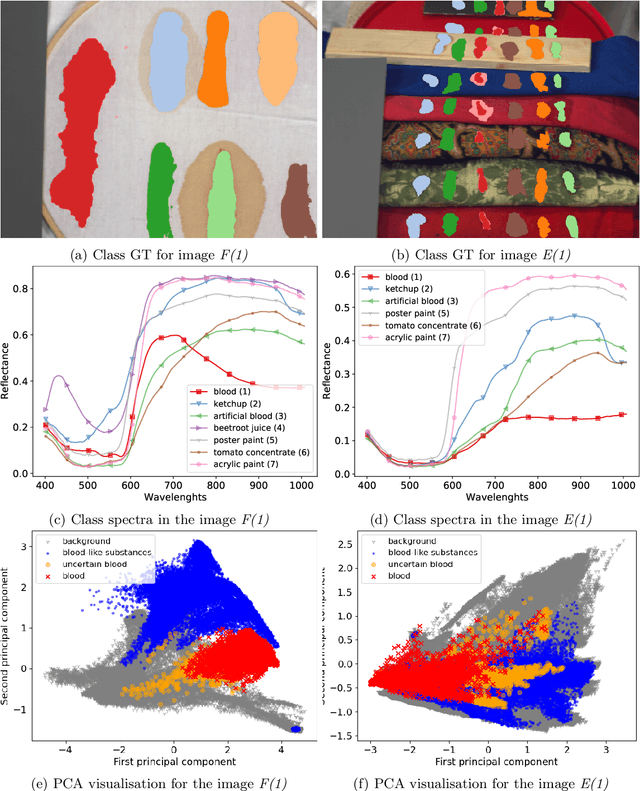

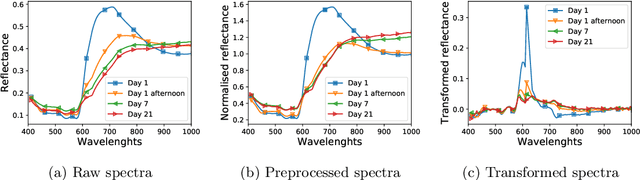
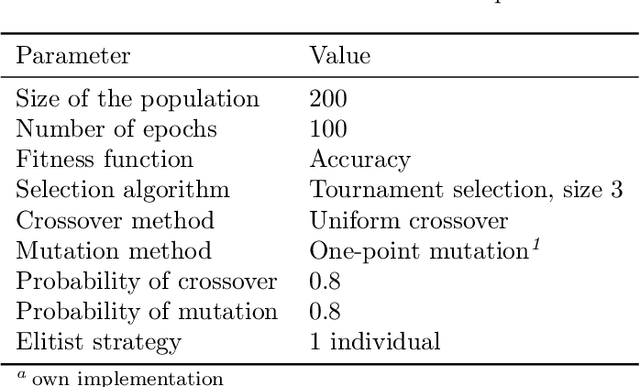
This study is focused on applying genetic algorithms (GA) to model and band selection in hyperspectral image classification. We use a forensic-inspired data set of seven hyperspectral images with blood and five visually similar substances to test GA-optimised classifiers in two scenarios: when the training and test data come from the same image and when they come from different images, which is a more challenging task due to significant spectra differences. In our experiments we compare GA with a classic model optimisation through grid search. Our results show that GA-based model optimisation can reduce the number of bands and create an accurate classifier that outperforms the GS-based reference models, provided that during model optimisation it has access to examples similar to test data. We illustrate this with experiment highlighting the importance of a validation set.