 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum-aware Transformer model for state classification
Feb 28, 2025



Entanglement is a fundamental feature of quantum mechanics, playing a crucial role in quantum information processing. However, classifying entangled states, particularly in the mixed-state regime, remains a challenging problem, especially as system dimensions increase. In this work, we focus on bipartite quantum states and present a data-driven approach to entanglement classification using transformer-based neural networks. Our dataset consists of a diverse set of bipartite states, including pure separable states, Werner entangled states, general entangled states, and maximally entangled states. We pretrain the transformer in an unsupervised fashion by masking elements of vectorized Hermitian matrix representations of quantum states, allowing the model to learn structural properties of quantum density matrices. This approach enables the model to generalize entanglement characteristics across different classes of states. Once trained, our method achieves near-perfect classification accuracy, effectively distinguishing between separable and entangled states. Compared to previous Machine Learning, our method successfully adapts transformers for quantum state analysis, demonstrating their ability to systematically identify entanglement in bipartite systems. These results highlight the potential of modern machine learning techniques in automating entanglement detection and classification, bridging the gap between quantum information theory and artificial intelligence.
`Just One More Sensor is Enough' -- Iterative Water Leak Localization with Physical Simulation and a Small Number of Pressure Sensors
Jun 28, 2024In this article, we propose an approach to leak localisation in a complex water delivery grid with the use of data from physical simulation (e.g. EPANET software). This task is usually achieved by a network of multiple water pressure sensors and analysis of the so-called sensitivity matrix of pressure differences between the network's simulated data and actual data of the network affected by the leak. However, most algorithms using this approach require a significant number of pressure sensors -- a condition that is not easy to fulfil in the case of many less equipped networks. Therefore, we answer the question of whether leak localisation is possible by utilising very few sensors but having the ability to relocate one of them. Our algorithm is based on physical simulations (EPANET software) and an iterative scheme for mobile sensor relocation. The experiments show that the proposed system can equalise the low number of sensors with adjustments made for their positioning, giving a very good approximation of leak's position both in simulated cases and real-life example taken from BattLeDIM competition L-Town data.
Through the Thicket: A Study of Number-Oriented LLMs derived from Random Forest Models
Jun 07, 2024Large Language Models (LLMs) have shown exceptional performance in text processing. Notably, LLMs can synthesize information from large datasets and explain their decisions similarly to human reasoning through a chain of thought (CoT). An emerging application of LLMs is the handling and interpreting of numerical data, where fine-tuning enhances their performance over basic inference methods. This paper proposes a novel approach to training LLMs using knowledge transfer from a random forest (RF) ensemble, leveraging its efficiency and accuracy. By converting RF decision paths into natural language statements, we generate outputs for LLM fine-tuning, enhancing the model's ability to classify and explain its decisions. Our method includes verifying these rules through established classification metrics, ensuring their correctness. We also examine the impact of preprocessing techniques on the representation of numerical data and their influence on classification accuracy and rule correctness
Heuristical choice of SVM parameters
Nov 03, 2021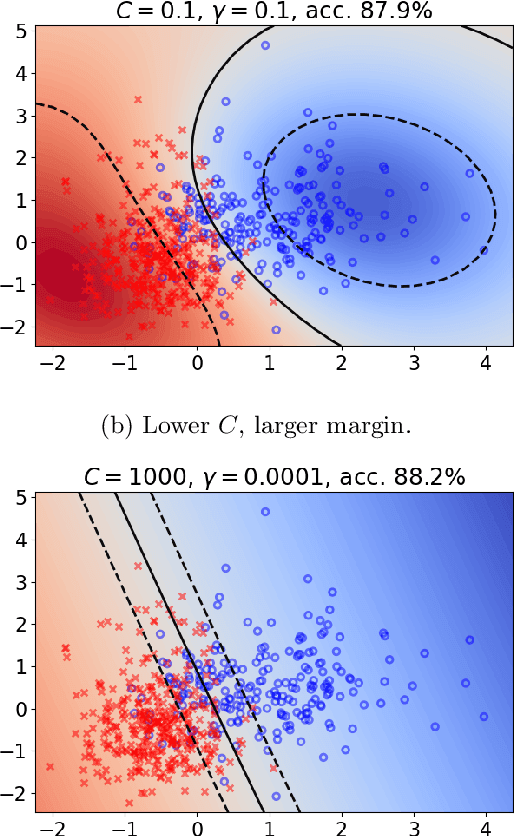
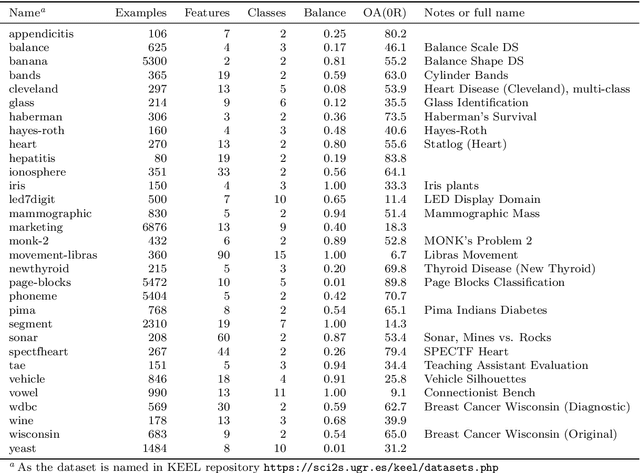
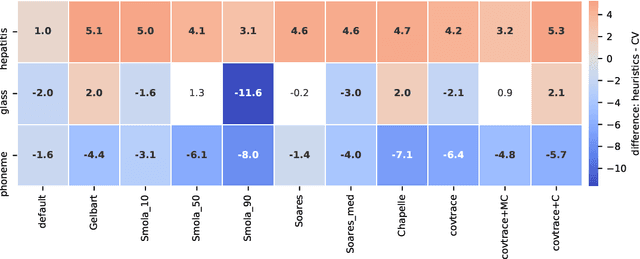
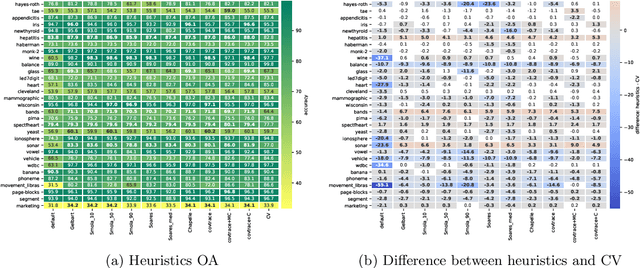
Support Vector Machine (SVM) is one of the most popular classification methods, and a de-facto reference for many Machine Learning approaches. Its performance is determined by parameter selection, which is usually achieved by a time-consuming grid search cross-validation procedure. There exist, however, several unsupervised heuristics that take advantage of the characteristics of the dataset for selecting parameters instead of using class label information. Unsupervised heuristics, while an order of magnitude faster, are scarcely used under the assumption that their results are significantly worse than those of grid search. To challenge that assumption we have conducted a wide study of various heuristics for SVM parameter selection on over thirty datasets, in both supervised and semi-supervised scenarios. In most cases, the cross-validation grid search did not achieve a significant advantage over the heuristics. In particular, heuristical parameter selection may be preferable for high dimensional and unbalanced datasets or when a small number of examples is available. Our results also show that using a heuristic to determine the starting point of further cross-validation does not yield significantly better results than the default start.
Stable training of autoencoders for hyperspectral unmixing
Sep 28, 2021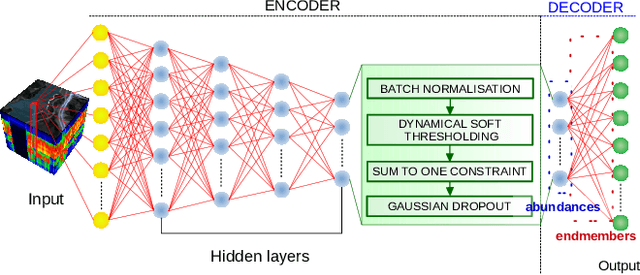
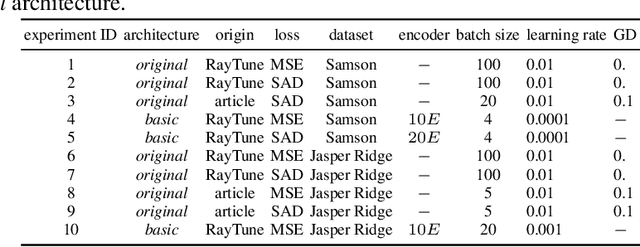
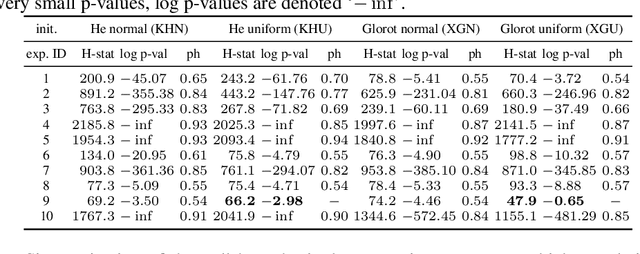

Neural networks, autoencoders in particular, are one of the most promising solutions for unmixing hyperspectral data, i.e. reconstructing the spectra of observed substances (endmembers) and their relative mixing fractions (abundances). Unmixing is needed for effective hyperspectral analysis and classification. However, as we show in this paper, the training of autoencoders for unmixing is highly dependent on weights initialisation. Some sets of weights lead to degenerate or low performance solutions, introducing negative bias in expected performance. In this work we present the results of experiments investigating autoencoders' stability, verifying the dependence of reconstruction error on initial weights and exploring conditions needed for successful optimisation of autoencoder parameters.
A Dataset for Evaluating Blood Detection in Hyperspectral Images
Aug 24, 2020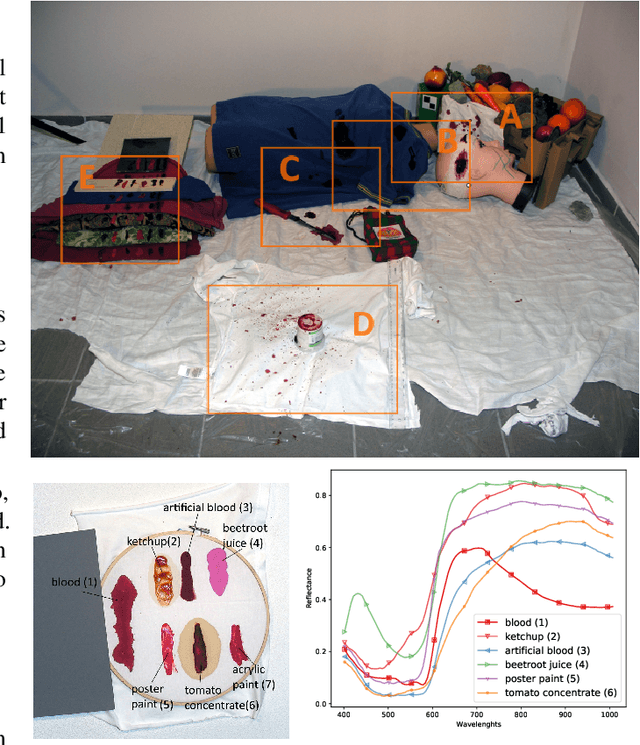

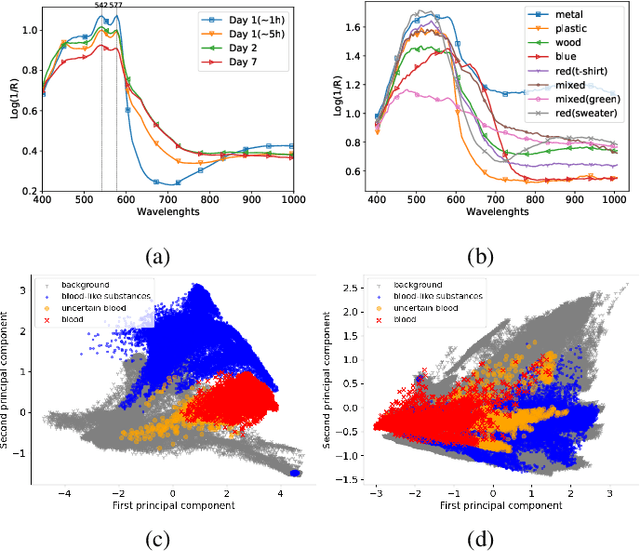
The sensitivity of imaging spectroscopy to hemoglobin derivatives makes it a promising tool for detecting blood. However, due to complexity and high dimensionality of hyperspectral images, the development of hyperspectral blood detection algorithms is challenging. To facilitate their development, we present a new hyperspectral blood detection dataset. This dataset, published in accordance to open access mandate, consist of multiple detection scenarios with varying levels of complexity. It allows to test the performance of Machine Learning methods in relation to different acquisition environments, types of background, age of blood and presence of other blood-like substances. We explored the dataset with blood detection experiments. We used hyperspectral target detection algorithm based on the well-known Matched Filter detector. Our results and their discussion highlight the challenges of blood detection in hyperspectral data and form a reference for further works
Band selection with Higher Order Multivariate Cumulants for small target detection in hyperspectral images
Aug 10, 2018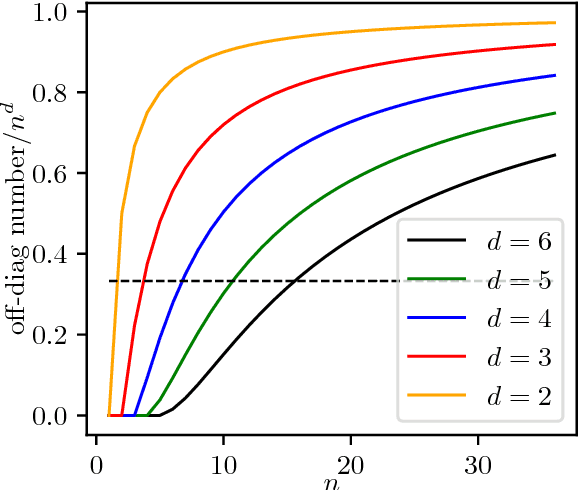

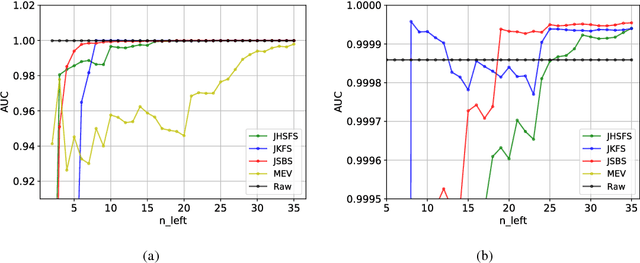
In the small target detection problem a pattern to be located is on the order of magnitude less numerous than other patterns present in the dataset. This applies both to the case of supervised detection, where the known template is expected to match in just a few areas and unsupervised anomaly detection, as anomalies are rare by definition. This problem is frequently related to the imaging applications, i.e. detection within the scene acquired by a camera. To maximize available data about the scene, hyperspectral cameras are used; at each pixel, they record spectral data in hundreds of narrow bands. The typical feature of hyperspectral imaging is that characteristic properties of target materials are visible in the small number of bands, where light of certain wavelength interacts with characteristic molecules. A target-independent band selection method based on statistical principles is a versatile tool for solving this problem in different practical applications. Combination of a regular background and a rare standing out anomaly will produce a distortion in the joint distribution of hyperspectral pixels. Higher Order Cumulants Tensors are a natural `window' into this distribution, allowing to measure properties and suggest candidate bands for removal. While there have been attempts at producing band selection algorithms based on the 3 rd cumulant's tensor i.e. the joint skewness, the literature lacks a systematic analysis of how the order of the cumulant tensor used affects effectiveness of band selection in detection applications. In this paper we present an analysis of a general algorithm for band selection based on higher order cumulants. We discuss its usability related to the observed breaking points in performance, depending both on method order and the desired number of bands. Finally we perform experiments and evaluate these methods in a hyperspectral detection scenario.
Deciding of HMM parameters based on number of critical points for gesture recognition from motion capture data
Oct 28, 2011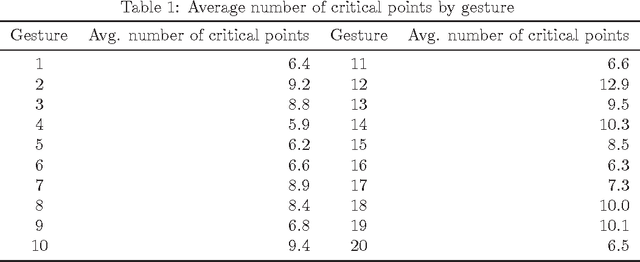
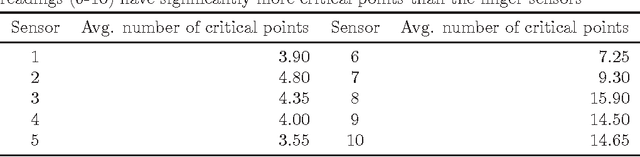
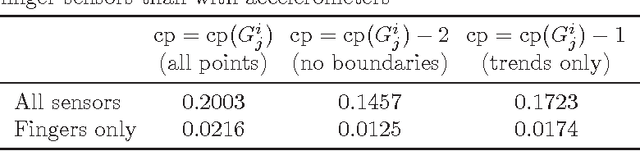
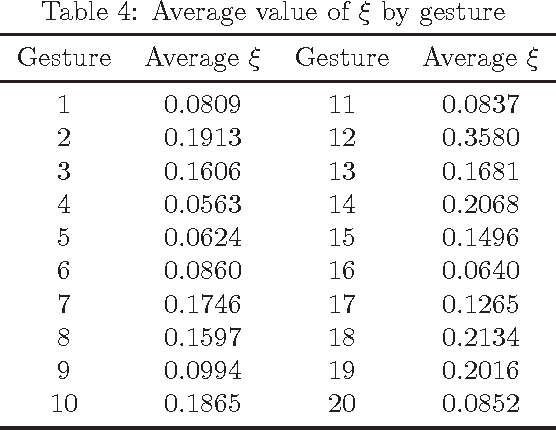
This paper presents a method of choosing number of states of a HMM based on number of critical points of the motion capture data. The choice of Hidden Markov Models(HMM) parameters is crucial for recognizer's performance as it is the first step of the training and cannot be corrected automatically within HMM. In this article we define predictor of number of states based on number of critical points of the sequence and test its effectiveness against sample data.