 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREBEL: Hidden Knowledge Recovery via Evolutionary-Based Evaluation Loop
Feb 05, 2026Machine unlearning for LLMs aims to remove sensitive or copyrighted data from trained models. However, the true efficacy of current unlearning methods remains uncertain. Standard evaluation metrics rely on benign queries that often mistake superficial information suppression for genuine knowledge removal. Such metrics fail to detect residual knowledge that more sophisticated prompting strategies could still extract. We introduce REBEL, an evolutionary approach for adversarial prompt generation designed to probe whether unlearned data can still be recovered. Our experiments demonstrate that REBEL successfully elicits ``forgotten'' knowledge from models that seemed to be forgotten in standard unlearning benchmarks, revealing that current unlearning methods may provide only a superficial layer of protection. We validate our framework on subsets of the TOFU and WMDP benchmarks, evaluating performance across a diverse suite of unlearning algorithms. Our experiments show that REBEL consistently outperforms static baselines, recovering ``forgotten'' knowledge with Attack Success Rates (ASRs) reaching up to 60% on TOFU and 93% on WMDP. We will make all code publicly available upon acceptance. Code is available at https://github.com/patryk-rybak/REBEL/
ReLAPSe: Reinforcement-Learning-trained Adversarial Prompt Search for Erased concepts in unlearned diffusion models
Jan 30, 2026Machine unlearning is a key defense mechanism for removing unauthorized concepts from text-to-image diffusion models, yet recent evidence shows that latent visual information often persists after unlearning. Existing adversarial approaches for exploiting this leakage are constrained by fundamental limitations: optimization-based methods are computationally expensive due to per-instance iterative search. At the same time, reasoning-based and heuristic techniques lack direct feedback from the target model's latent visual representations. To address these challenges, we introduce ReLAPSe, a policy-based adversarial framework that reformulates concept restoration as a reinforcement learning problem. ReLAPSe trains an agent using Reinforcement Learning with Verifiable Rewards (RLVR), leveraging the diffusion model's noise prediction loss as a model-intrinsic and verifiable feedback signal. This closed-loop design directly aligns textual prompt manipulation with latent visual residuals, enabling the agent to learn transferable restoration strategies rather than optimizing isolated prompts. By pioneering the shift from per-instance optimization to global policy learning, ReLAPSe achieves efficient, near-real-time recovery of fine-grained identities and styles across multiple state-of-the-art unlearning methods, providing a scalable tool for rigorous red-teaming of unlearned diffusion models. Some experimental evaluations involve sensitive visual concepts, such as nudity. Code is available at https://github.com/gmum/ReLaPSe
PRL: Prompts from Reinforcement Learning
May 20, 2025Effective prompt engineering remains a central challenge in fully harnessing the capabilities of LLMs. While well-designed prompts can dramatically enhance performance, crafting them typically demands expert intuition and a nuanced understanding of the task. Moreover, the most impactful prompts often hinge on subtle semantic cues, ones that may elude human perception but are crucial for guiding LLM behavior. In this paper, we introduce PRL (Prompts from Reinforcement Learning), a novel RL-based approach for automatic prompt generation. Unlike previous methods, PRL can produce novel few-shot examples that were not seen during training. Our approach achieves state-of-the-art performance across a range of benchmarks, including text classification, simplification, and summarization. On the classification task, it surpasses prior methods by 2.58% over APE and 1.00% over EvoPrompt. Additionally, it improves the average ROUGE scores on the summarization task by 4.32 over APE and by 2.12 over EvoPrompt and the SARI score on simplification by 6.93 over APE and by 6.01 over EvoPrompt. Our code is available at https://github.com/Batorskq/prl .
NSA: Neuro-symbolic ARC Challenge
Jan 08, 2025



The Abstraction and Reasoning Corpus (ARC) evaluates general reasoning capabilities that are difficult for both machine learning models and combinatorial search methods. We propose a neuro-symbolic approach that combines a transformer for proposal generation with combinatorial search using a domain-specific language. The transformer narrows the search space by proposing promising search directions, which allows the combinatorial search to find the actual solution in short time. We pre-train the trainsformer with synthetically generated data. During test-time we generate additional task-specific training tasks and fine-tune our model. Our results surpass comparable state of the art on the ARC evaluation set by 27% and compare favourably on the ARC train set. We make our code and dataset publicly available at https://github.com/Batorskq/NSA.
HyperInterval: Hypernetwork approach to training weight interval regions in continual learning
May 27, 2024Recently, a new Continual Learning (CL) paradigm was presented to control catastrophic forgetting, called Interval Continual Learning (InterContiNet), which relies on enforcing interval constraints on the neural network parameter space. Unfortunately, InterContiNet training is challenging due to the high dimensionality of the weight space, making intervals difficult to manage. To address this issue, we introduce HyperInterval, a technique that employs interval arithmetic within the embedding space and utilizes a hypernetwork to map these intervals to the target network parameter space. We train interval embeddings for consecutive tasks and train a hypernetwork to transform these embeddings into weights of the target network. An embedding for a given task is trained along with the hypernetwork, preserving the response of the target network for the previous task embeddings. Interval arithmetic works with a more manageable, lower-dimensional embedding space rather than directly preparing intervals in a high-dimensional weight space. Our model allows faster and more efficient training. Furthermore, HyperInterval maintains the guarantee of not forgetting. At the end of training, we can choose one universal embedding to produce a single network dedicated to all tasks. In such a framework, hypernetwork is used only for training and can be seen as a meta-trainer. HyperInterval obtains significantly better results than InterContiNet and gives SOTA results on several benchmarks.
HyperPlanes: Hypernetwork Approach to Rapid NeRF Adaptation
Feb 02, 2024Neural radiance fields (NeRFs) are a widely accepted standard for synthesizing new 3D object views from a small number of base images. However, NeRFs have limited generalization properties, which means that we need to use significant computational resources to train individual architectures for each item we want to represent. To address this issue, we propose a few-shot learning approach based on the hypernetwork paradigm that does not require gradient optimization during inference. The hypernetwork gathers information from the training data and generates an update for universal weights. As a result, we have developed an efficient method for generating a high-quality 3D object representation from a small number of images in a single step. This has been confirmed by direct comparison with the state-of-the-art solutions and a comprehensive ablation study.
Bounding Evidence and Estimating Log-Likelihood in VAE
Jun 19, 2022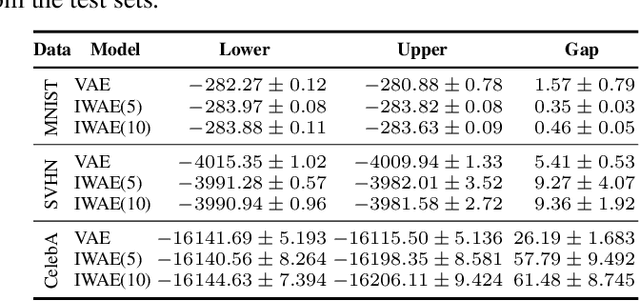
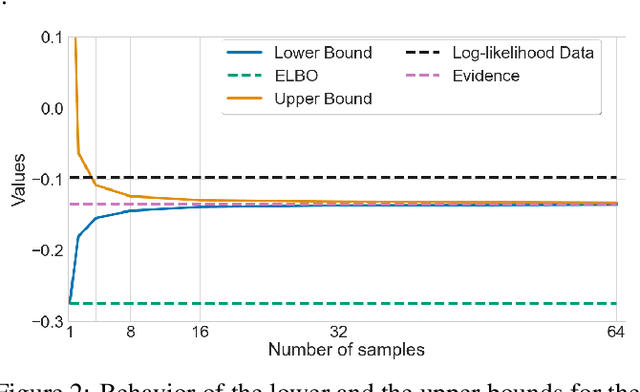
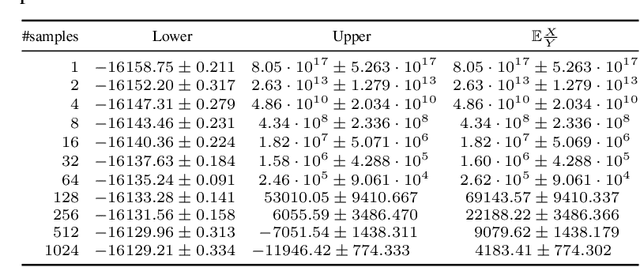

Many crucial problems in deep learning and statistics are caused by a variational gap, i.e., a difference between evidence and evidence lower bound (ELBO). As a consequence, in the classical VAE model, we obtain only the lower bound on the log-likelihood since ELBO is used as a cost function, and therefore we cannot compare log-likelihood between models. In this paper, we present a general and effective upper bound of the variational gap, which allows us to efficiently estimate the true evidence. We provide an extensive theoretical study of the proposed approach. Moreover, we show that by applying our estimation, we can easily obtain lower and upper bounds for the log-likelihood of VAE models.