 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Copying in Generative Models: A Formal Framework
Mar 01, 2023



There has been some recent interest in detecting and addressing memorization of training data by deep neural networks. A formal framework for memorization in generative models, called "data-copying," was proposed by Meehan et. al. (2020). We build upon their work to show that their framework may fail to detect certain kinds of blatant memorization. Motivated by this and the theory of non-parametric methods, we provide an alternative definition of data-copying that applies more locally. We provide a method to detect data-copying, and provably show that it works with high probability when enough data is available. We also provide lower bounds that characterize the sample requirement for reliable detection.
A Two-Stage Active Learning Algorithm for $k$-Nearest Neighbors
Nov 19, 2022
We introduce a simple and intuitive two-stage active learning algorithm for the training of $k$-nearest neighbors classifiers. We provide consistency guarantees for a modified $k$-nearest neighbors classifier trained on samples acquired via our scheme, and show that when the conditional probability function $\mathbb{P}(Y=y|X=x)$ is sufficiently smooth and the Tsybakov noise condition holds, our actively trained classifiers converge to the Bayes optimal classifier at a faster asymptotic rate than passively trained $k$-nearest neighbor classifiers.
The Interpolated MVU Mechanism For Communication-efficient Private Federated Learning
Nov 08, 2022



We consider private federated learning (FL), where a server aggregates differentially private gradient updates from a large number of clients in order to train a machine learning model. The main challenge is balancing privacy with both classification accuracy of the learned model as well as the amount of communication between the clients and server. In this work, we build on a recently proposed method for communication-efficient private FL -- the MVU mechanism -- by introducing a new interpolation mechanism that can accommodate a more efficient privacy analysis. The result is the new Interpolated MVU mechanism that provides SOTA results on communication-efficient private FL on a variety of datasets.
Robust Empirical Risk Minimization with Tolerance
Oct 02, 2022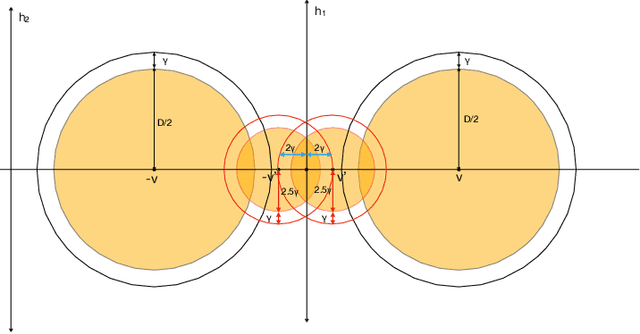
Developing simple, sample-efficient learning algorithms for robust classification is a pressing issue in today's tech-dominated world, and current theoretical techniques requiring exponential sample complexity and complicated improper learning rules fall far from answering the need. In this work we study the fundamental paradigm of (robust) $\textit{empirical risk minimization}$ (RERM), a simple process in which the learner outputs any hypothesis minimizing its training error. RERM famously fails to robustly learn VC classes (Montasser et al., 2019a), a bound we show extends even to `nice' settings such as (bounded) halfspaces. As such, we study a recent relaxation of the robust model called $\textit{tolerant}$ robust learning (Ashtiani et al., 2022) where the output classifier is compared to the best achievable error over slightly larger perturbation sets. We show that under geometric niceness conditions, a natural tolerant variant of RERM is indeed sufficient for $\gamma$-tolerant robust learning VC classes over $\mathbb{R}^d$, and requires only $\tilde{O}\left( \frac{VC(H)d\log \frac{D}{\gamma\delta}}{\epsilon^2}\right)$ samples for robustness regions of (maximum) diameter $D$.
Forgetting Data from Pre-trained GANs
Jun 29, 2022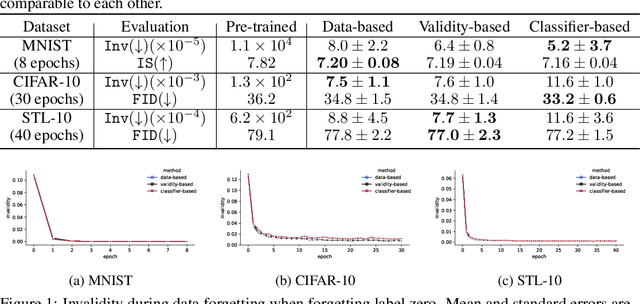
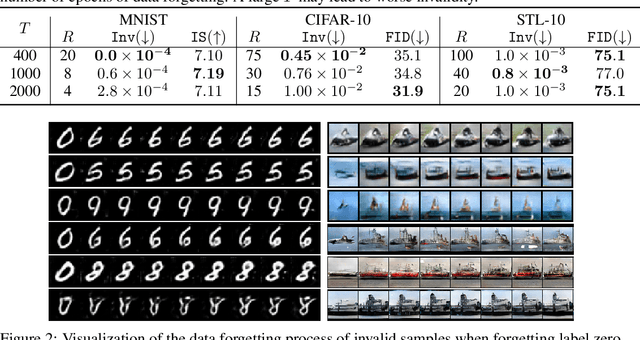


Large pre-trained generative models are known to occasionally provide samples that may be undesirable for various reasons. The standard way to mitigate this is to re-train the models differently. In this work, we take a different, more compute-friendly approach and investigate how to post-edit a model after training so that it forgets certain kinds of samples. We provide three different algorithms for GANs that differ on how the samples to be forgotten are described. Extensive evaluations on real-world image datasets show that our algorithms are capable of forgetting data while retaining high generation quality at a fraction of the cost of full re-training.
Thompson Sampling for Robust Transfer in Multi-Task Bandits
Jun 17, 2022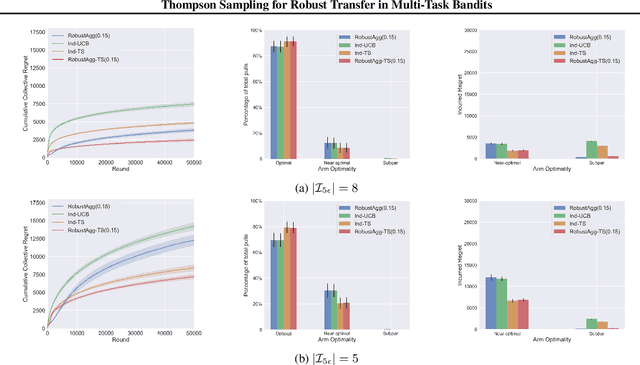
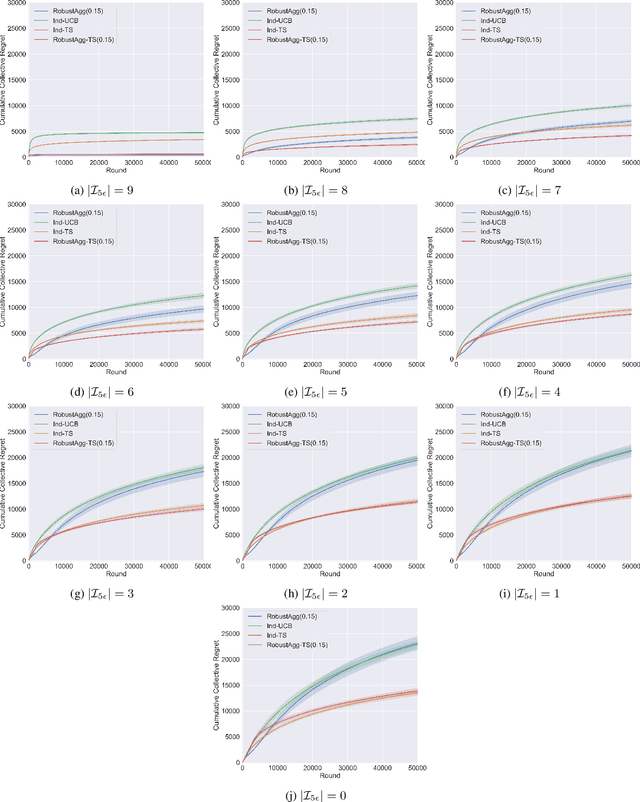
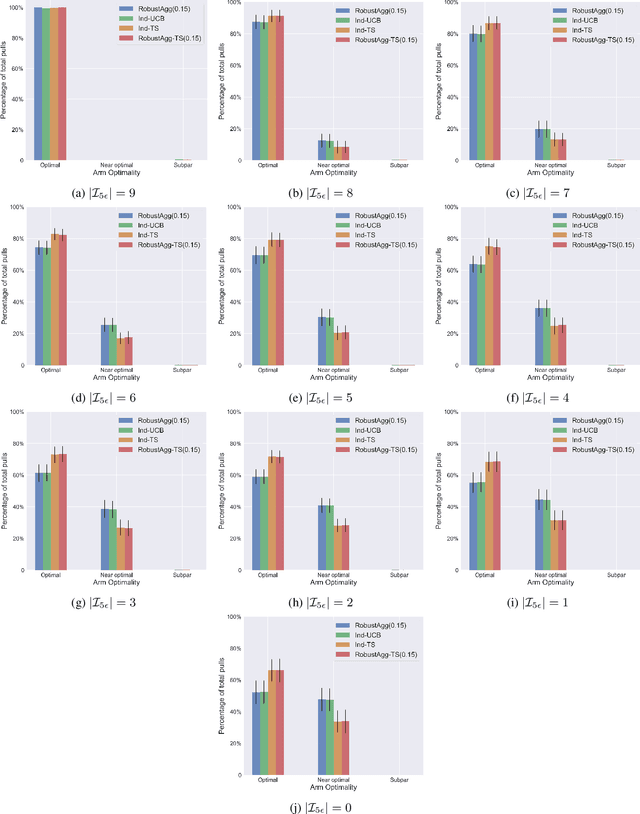
We study the problem of online multi-task learning where the tasks are performed within similar but not necessarily identical multi-armed bandit environments. In particular, we study how a learner can improve its overall performance across multiple related tasks through robust transfer of knowledge. While an upper confidence bound (UCB)-based algorithm has recently been shown to achieve nearly-optimal performance guarantees in a setting where all tasks are solved concurrently, it remains unclear whether Thompson sampling (TS) algorithms, which have superior empirical performance in general, share similar theoretical properties. In this work, we present a TS-type algorithm for a more general online multi-task learning protocol, which extends the concurrent setting. We provide its frequentist analysis and prove that it is also nearly-optimal using a novel concentration inequality for multi-task data aggregation at random stopping times. Finally, we evaluate the algorithm on synthetic data and show that the TS-type algorithm enjoys superior empirical performance in comparison with the UCB-based algorithm and a baseline algorithm that performs TS for each individual task without transfer.
A Learning-Theoretic Framework for Certified Auditing of Machine Learning Models
Jun 09, 2022
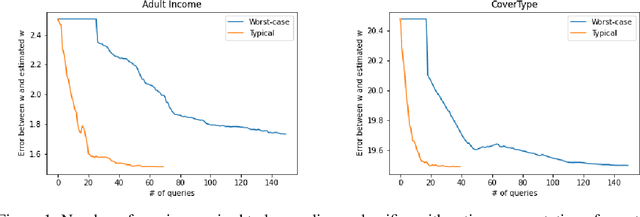
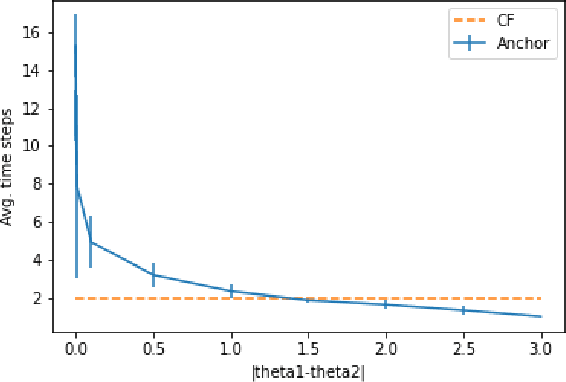
Responsible use of machine learning requires that models be audited for undesirable properties. However, how to do principled auditing in a general setting has remained ill-understood. In this paper, we propose a formal learning-theoretic framework for auditing. We propose algorithms for auditing linear classifiers for feature sensitivity using label queries as well as different kinds of explanations, and provide performance guarantees. Our results illustrate that while counterfactual explanations can be extremely helpful for auditing, anchor explanations may not be as beneficial in the worst case.
Throwing Away Data Improves Worst-Class Error in Imbalanced Classification
May 23, 2022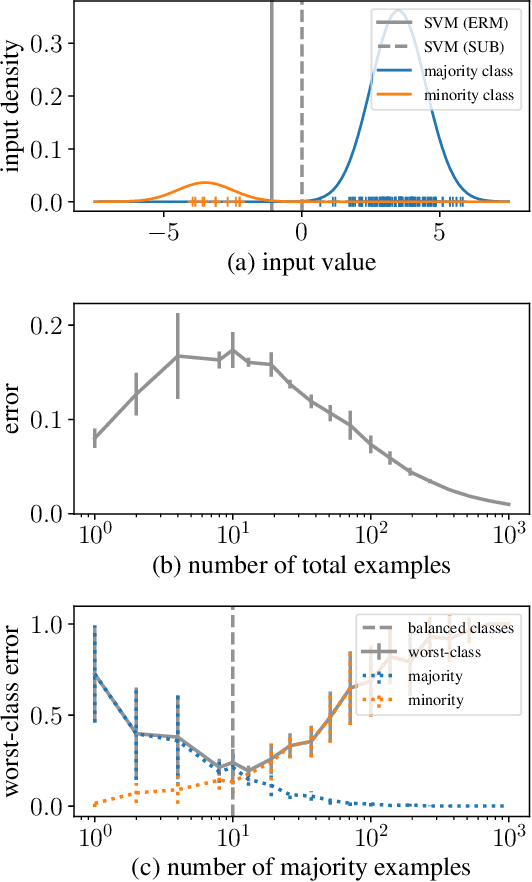
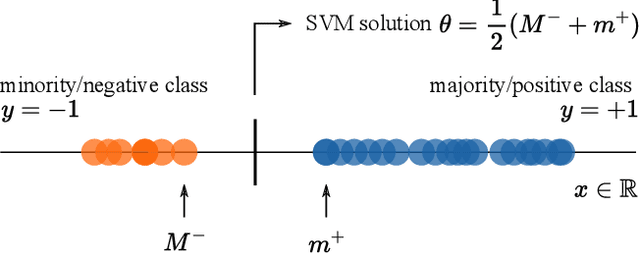
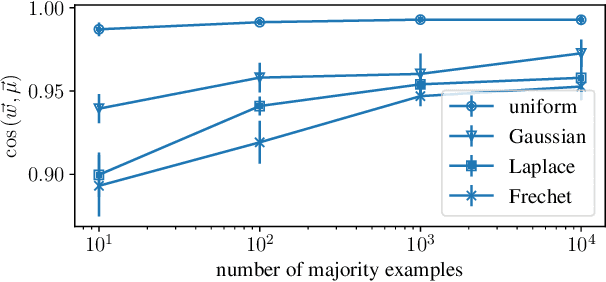
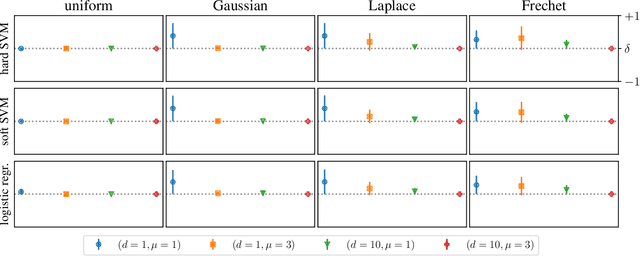
Class imbalances pervade classification problems, yet their treatment differs in theory and practice. On the one hand, learning theory instructs us that \emph{more data is better}, as sample size relates inversely to the average test error over the entire data distribution. On the other hand, practitioners have long developed a plethora of tricks to improve the performance of learning machines over imbalanced data. These include data reweighting and subsampling, synthetic construction of additional samples from minority classes, ensembling expensive one-versus all architectures, and tweaking classification losses and thresholds. All of these are efforts to minimize the worst-class error, which is often associated to the minority group in the training data, and finds additional motivation in the robustness, fairness, and out-of-distribution literatures. Here we take on the challenge of developing learning theory able to describe the worst-class error of classifiers over linearly-separable data when fitted either on (i) the full training set, or (ii) a subset where the majority class is subsampled to match in size the minority class. We borrow tools from extreme value theory to show that, under distributions with certain tail properties, \emph{throwing away most data from the majority class leads to better worst-class error}.
Sentence-level Privacy for Document Embeddings
May 10, 2022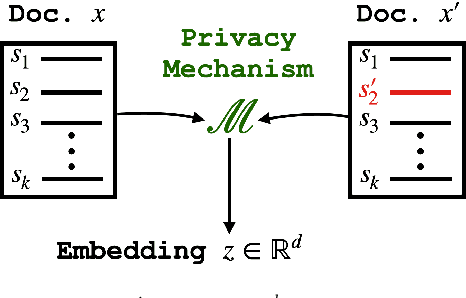
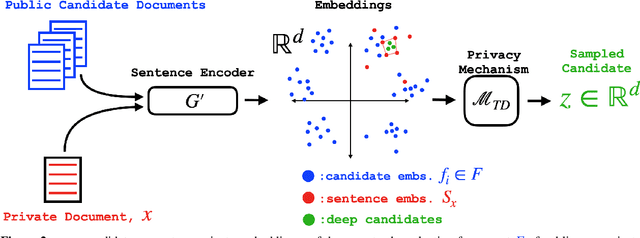
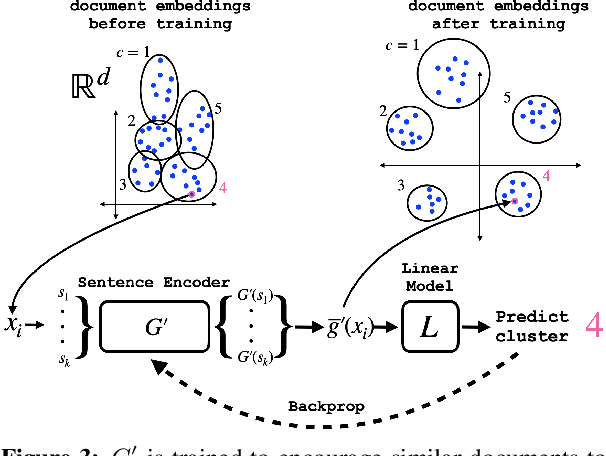
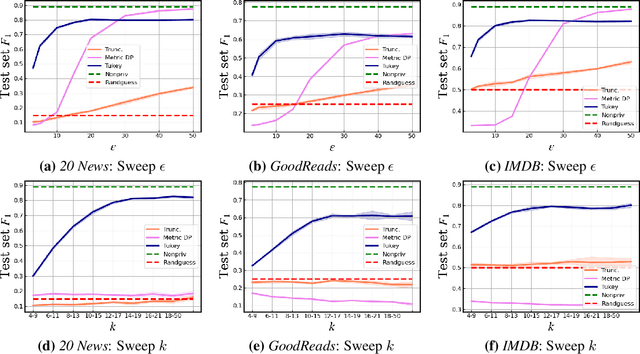
User language data can contain highly sensitive personal content. As such, it is imperative to offer users a strong and interpretable privacy guarantee when learning from their data. In this work, we propose SentDP: pure local differential privacy at the sentence level for a single user document. We propose a novel technique, DeepCandidate, that combines concepts from robust statistics and language modeling to produce high-dimensional, general-purpose $\epsilon$-SentDP document embeddings. This guarantees that any single sentence in a document can be substituted with any other sentence while keeping the embedding $\epsilon$-indistinguishable. Our experiments indicate that these private document embeddings are useful for downstream tasks like sentiment analysis and topic classification and even outperform baseline methods with weaker guarantees like word-level Metric DP.
Privacy-Aware Compression for Federated Data Analysis
Mar 15, 2022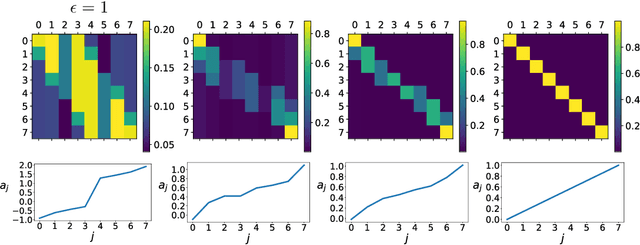
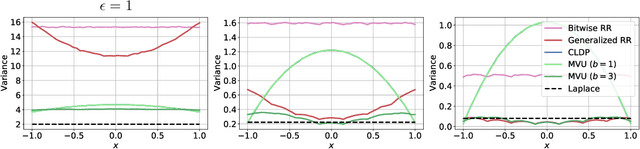

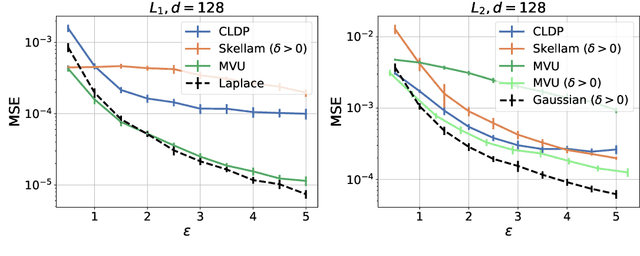
Federated data analytics is a framework for distributed data analysis where a server compiles noisy responses from a group of distributed low-bandwidth user devices to estimate aggregate statistics. Two major challenges in this framework are privacy, since user data is often sensitive, and compression, since the user devices have low network bandwidth. Prior work has addressed these challenges separately by combining standard compression algorithms with known privacy mechanisms. In this work, we take a holistic look at the problem and design a family of privacy-aware compression mechanisms that work for any given communication budget. We first propose a mechanism for transmitting a single real number that has optimal variance under certain conditions. We then show how to extend it to metric differential privacy for location privacy use-cases, as well as vectors, for application to federated learning. Our experiments illustrate that our mechanism can lead to better utility vs. compression trade-offs for the same privacy loss in a number of settings.