 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Prompt Complexity for Zero-Shot Classification: A Study of Large Language Models in Computational Social Science
May 23, 2023



Instruction-tuned Large Language Models (LLMs) have exhibited impressive language understanding and the capacity to generate responses that follow specific instructions. However, due to the computational demands associated with training these models, their applications often rely on zero-shot settings. In this paper, we evaluate the zero-shot performance of two publicly accessible LLMs, ChatGPT and OpenAssistant, in the context of Computational Social Science classification tasks, while also investigating the effects of various prompting strategies. Our experiment considers the impact of prompt complexity, including the effect of incorporating label definitions into the prompt, using synonyms for label names, and the influence of integrating past memories during the foundation model training. The findings indicate that in a zero-shot setting, the current LLMs are unable to match the performance of smaller, fine-tuned baseline transformer models (such as BERT). Additionally, we find that different prompting strategies can significantly affect classification accuracy, with variations in accuracy and F1 scores exceeding 10%.
A Large-Scale Comparative Study of Accurate COVID-19 Information versus Misinformation
Apr 10, 2023



The COVID-19 pandemic led to an infodemic where an overwhelming amount of COVID-19 related content was being disseminated at high velocity through social media. This made it challenging for citizens to differentiate between accurate and inaccurate information about COVID-19. This motivated us to carry out a comparative study of the characteristics of COVID-19 misinformation versus those of accurate COVID-19 information through a large-scale computational analysis of over 242 million tweets. The study makes comparisons alongside four key aspects: 1) the distribution of topics, 2) the live status of tweets, 3) language analysis and 4) the spreading power over time. An added contribution of this study is the creation of a COVID-19 misinformation classification dataset. Finally, we demonstrate that this new dataset helps improve misinformation classification by more than 9% based on average F1 measure.
Examining Temporalities on Stance Detection Towards COVID-19 Vaccination
Apr 10, 2023Previous studies have highlighted the importance of vaccination as an effective strategy to control the transmission of the COVID-19 virus. It is crucial for policymakers to have a comprehensive understanding of the public's stance towards vaccination on a large scale. However, attitudes towards COVID-19 vaccination, such as pro-vaccine or vaccine hesitancy, have evolved over time on social media. Thus, it is necessary to account for possible temporal shifts when analysing these stances. This study aims to examine the impact of temporal concept drift on stance detection towards COVID-19 vaccination on Twitter. To this end, we evaluate a range of transformer-based models using chronological and random splits of social media data. Our findings demonstrate significant discrepancies in model performance when comparing random and chronological splits across all monolingual and multilingual datasets. Chronological splits significantly reduce the accuracy of stance classification. Therefore, real-world stance detection approaches need to be further refined to incorporate temporal factors as a key consideration.
Team SheffieldVeraAI at SemEval-2023 Task 3: Mono and multilingual approaches for news genre, topic and persuasion technique classification
Mar 16, 2023



This paper describes our approach for SemEval-2023 Task 3: Detecting the category, the framing, and the persuasion techniques in online news in a multi-lingual setup. For Subtask 1 (News Genre), we propose an ensemble of fully trained and adapter mBERT models which was ranked joint-first for German, and had the highest mean rank of multi-language teams. For Subtask 2 (Framing), we achieved first place in 3 languages, and the best average rank across all the languages, by using two separate ensembles: a monolingual RoBERTa-MUPPETLARGE and an ensemble of XLM-RoBERTaLARGE with adapters and task adaptive pretraining. For Subtask 3 (Persuasion Techniques), we train a monolingual RoBERTa-Base model for English and a multilingual mBERT model for the remaining languages, which achieved top 10 for all languages, including 2nd for English. For each subtask, we compare monolingual and multilingual approaches, and consider class imbalance techniques.
It's about Time: Rethinking Evaluation on Rumor Detection Benchmarks using Chronological Splits
Feb 06, 2023New events emerge over time influencing the topics of rumors in social media. Current rumor detection benchmarks use random splits as training, development and test sets which typically results in topical overlaps. Consequently, models trained on random splits may not perform well on rumor classification on previously unseen topics due to the temporal concept drift. In this paper, we provide a re-evaluation of classification models on four popular rumor detection benchmarks considering chronological instead of random splits. Our experimental results show that the use of random splits can significantly overestimate predictive performance across all datasets and models. Therefore, we suggest that rumor detection models should always be evaluated using chronological splits for minimizing topical overlaps.
VaxxHesitancy: A Dataset for Studying Hesitancy Towards COVID-19 Vaccination on Twitter
Jan 17, 2023



Vaccine hesitancy has been a common concern, probably since vaccines were created and, with the popularisation of social media, people started to express their concerns about vaccines online alongside those posting pro- and anti-vaccine content. Predictably, since the first mentions of a COVID-19 vaccine, social media users posted about their fears and concerns or about their support and belief into the effectiveness of these rapidly developing vaccines. Identifying and understanding the reasons behind public hesitancy towards COVID-19 vaccines is important for policy markers that need to develop actions to better inform the population with the aim of increasing vaccine take-up. In the case of COVID-19, where the fast development of the vaccines was mirrored closely by growth in anti-vaxx disinformation, automatic means of detecting citizen attitudes towards vaccination became necessary. This is an important computational social sciences task that requires data analysis in order to gain in-depth understanding of the phenomena at hand. Annotated data is also necessary for training data-driven models for more nuanced analysis of attitudes towards vaccination. To this end, we created a new collection of over 3,101 tweets annotated with users' attitudes towards COVID-19 vaccination (stance). Besides, we also develop a domain-specific language model (VaxxBERT) that achieves the best predictive performance (73.0 accuracy and 69.3 F1-score) as compared to a robust set of baselines. To the best of our knowledge, these are the first dataset and model that model vaccine hesitancy as a category distinct from pro- and anti-vaccine stance.
On the Impact of Temporal Concept Drift on Model Explanations
Oct 17, 2022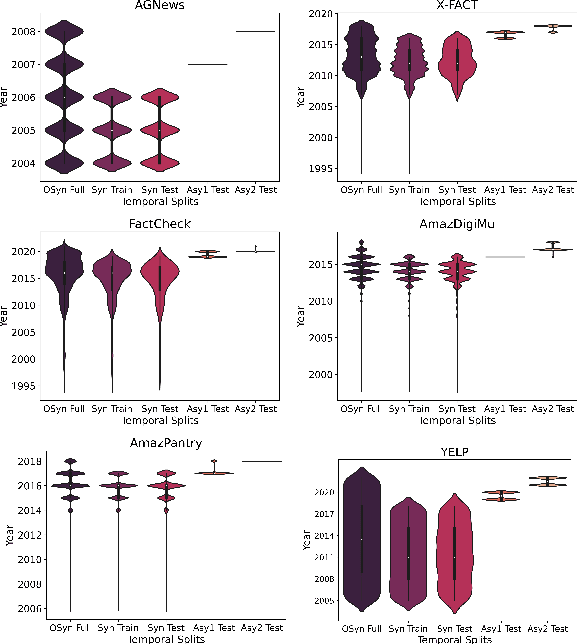
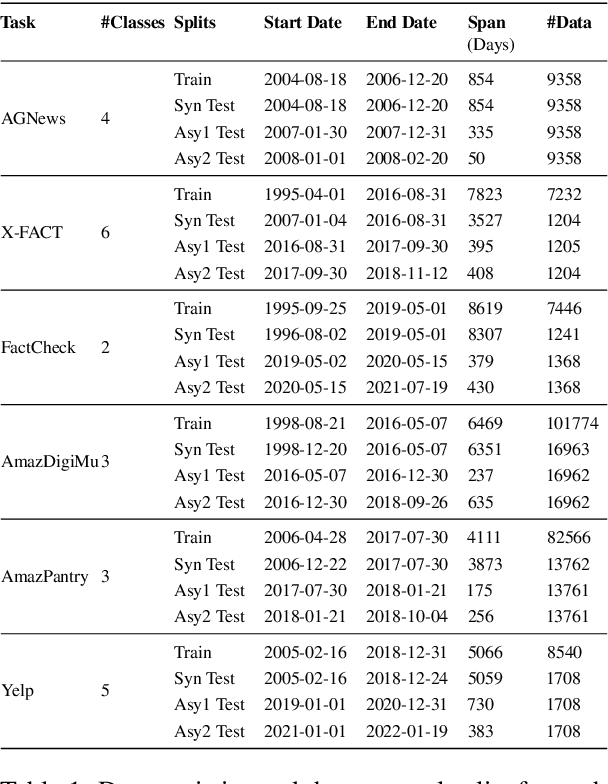
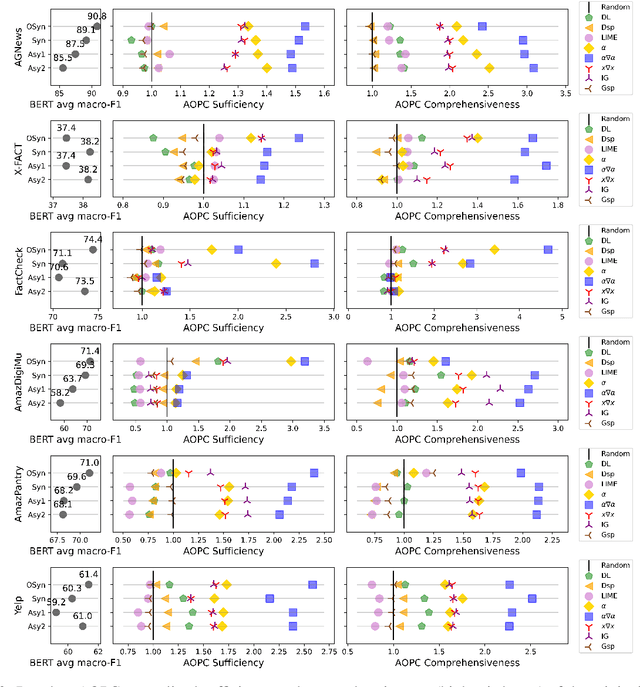
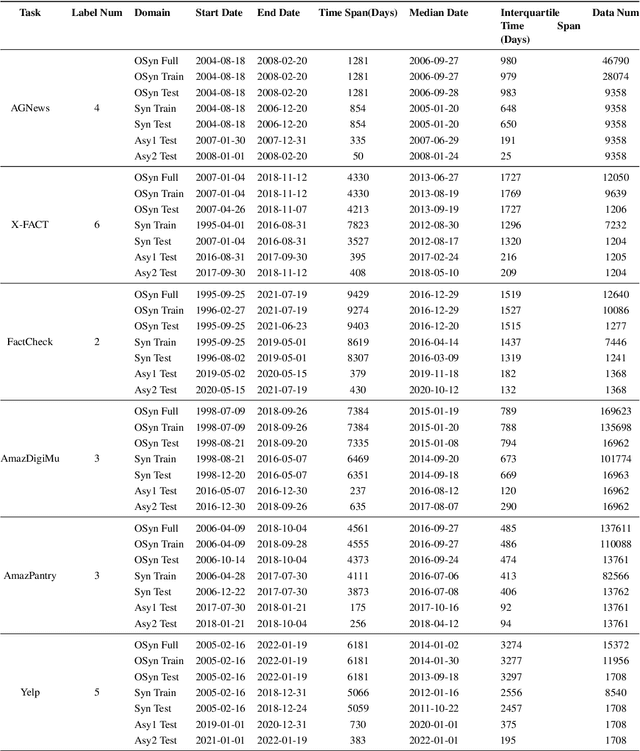
Explanation faithfulness of model predictions in natural language processing is typically evaluated on held-out data from the same temporal distribution as the training data (i.e. synchronous settings). While model performance often deteriorates due to temporal variation (i.e. temporal concept drift), it is currently unknown how explanation faithfulness is impacted when the time span of the target data is different from the data used to train the model (i.e. asynchronous settings). For this purpose, we examine the impact of temporal variation on model explanations extracted by eight feature attribution methods and three select-then-predict models across six text classification tasks. Our experiments show that (i)faithfulness is not consistent under temporal variations across feature attribution methods (e.g. it decreases or increases depending on the method), with an attention-based method demonstrating the most robust faithfulness scores across datasets; and (ii) select-then-predict models are mostly robust in asynchronous settings with only small degradation in predictive performance. Finally, feature attribution methods show conflicting behavior when used in FRESH (i.e. a select-and-predict model) and for measuring sufficiency/comprehensiveness (i.e. as post-hoc methods), suggesting that we need more robust metrics to evaluate post-hoc explanation faithfulness.
Classifying COVID-19 vaccine narratives
Jul 18, 2022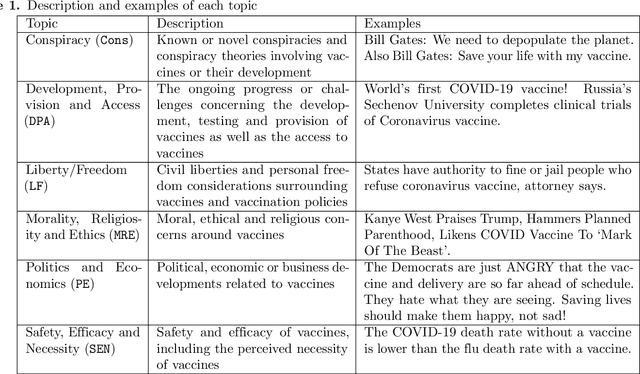
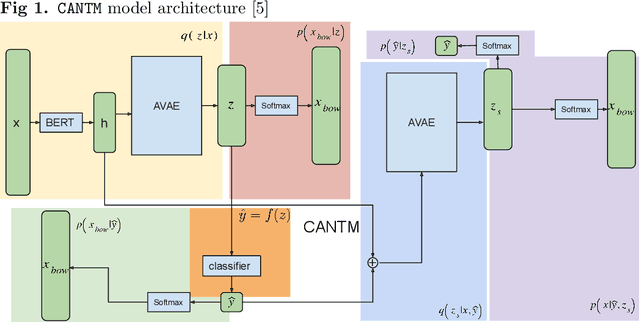
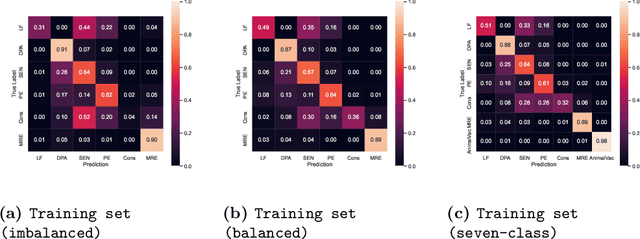
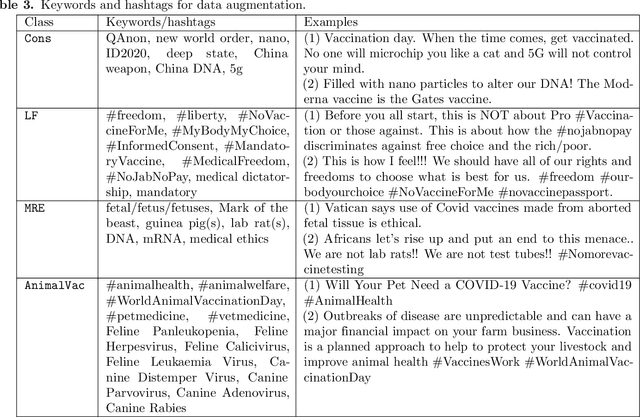
COVID-19 vaccine hesitancy is widespread, despite governments' information campaigns and WHO efforts. One of the reasons behind this is vaccine disinformation which widely spreads in social media. In particular, recent surveys have established that vaccine disinformation is impacting negatively citizen trust in COVID-19 vaccination. At the same time, fact-checkers are struggling with detecting and tracking of vaccine disinformation, due to the large scale of social media. To assist fact-checkers in monitoring vaccine narratives online, this paper studies a new vaccine narrative classification task, which categorises COVID-19 vaccine claims into one of seven categories. Following a data augmentation approach, we first construct a novel dataset for this new classification task, focusing on the minority classes. We also make use of fact-checker annotated data. The paper also presents a neural vaccine narrative classifier that achieves an accuracy of 84% under cross-validation. The classifier is publicly available for researchers and journalists.
Categorising Fine-to-Coarse Grained Misinformation: An Empirical Study of COVID-19 Infodemic
Jul 08, 2021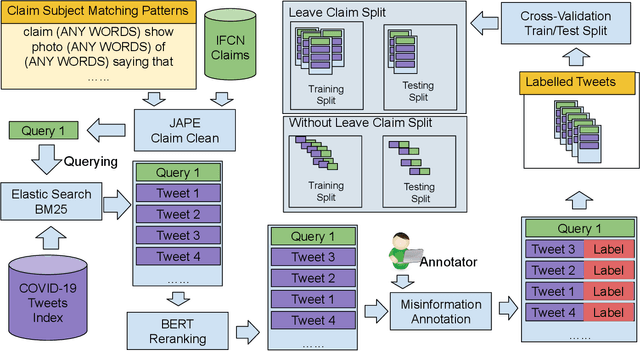
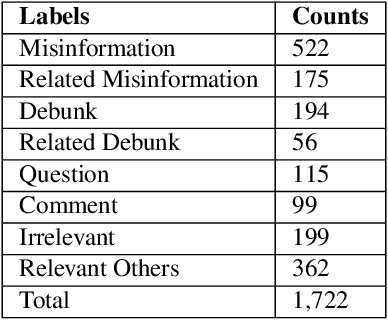
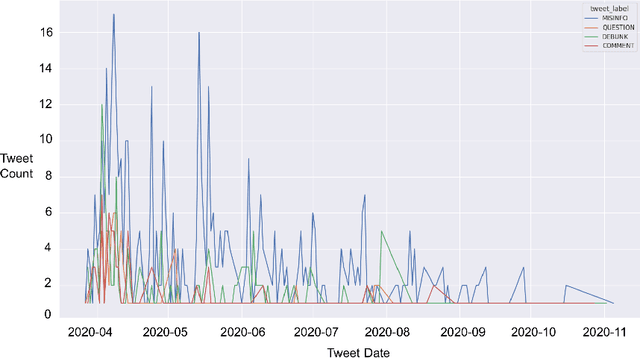
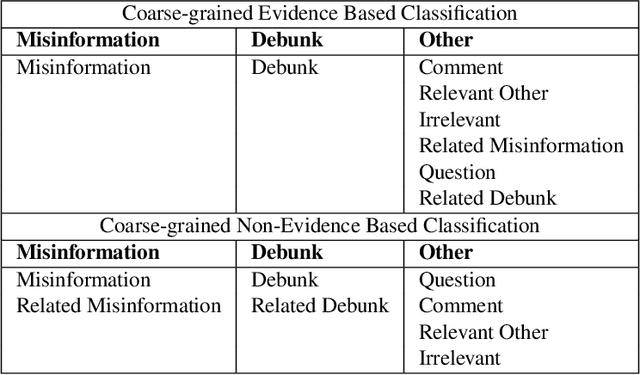
The spreading COVID-19 misinformation over social media already draws the attention of many researchers. According to Google Scholar, about 26000 COVID-19 related misinformation studies have been published to date. Most of these studies focusing on 1) detect and/or 2) analysing the characteristics of COVID-19 related misinformation. However, the study of the social behaviours related to misinformation is often neglected. In this paper, we introduce a fine-grained annotated misinformation tweets dataset including social behaviours annotation (e.g. comment or question to the misinformation). The dataset not only allows social behaviours analysis but also suitable for both evidence-based or non-evidence-based misinformation classification task. In addition, we introduce leave claim out validation in our experiments and demonstrate the misinformation classification performance could be significantly different when applying to real-world unseen misinformation.
MP Twitter Engagement and Abuse Post-first COVID-19 Lockdown in the UK: White Paper
Mar 08, 2021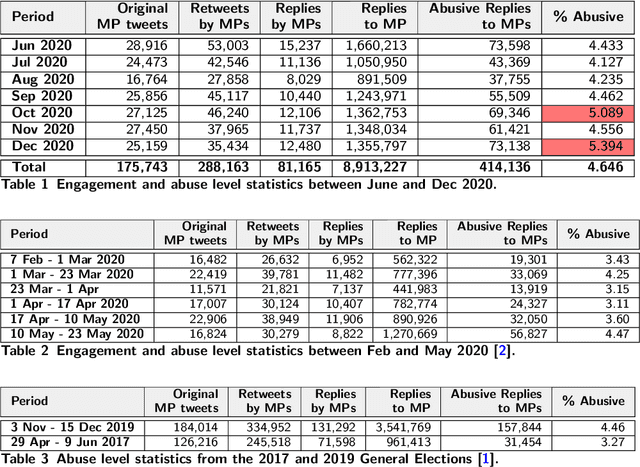
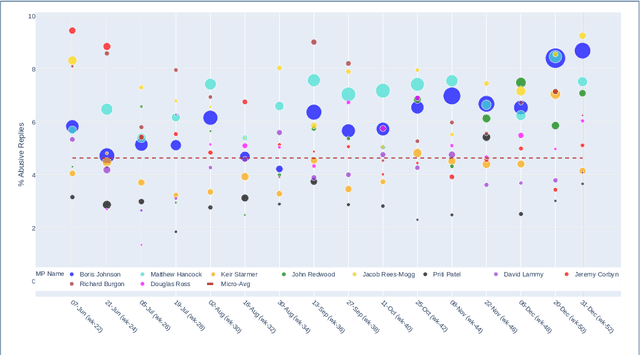
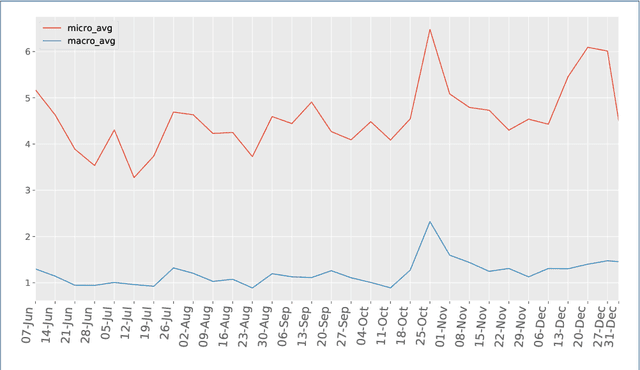
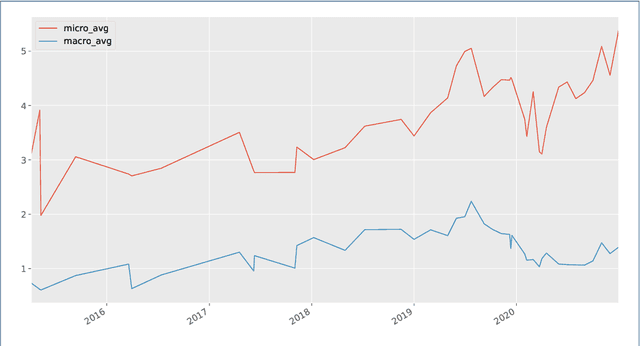
The UK has had a volatile political environment for some years now, with Brexit and leadership crises marking the past five years. With this work, we wanted to understand more about how the global health emergency, COVID-19, influences the amount, type or topics of abuse that UK politicians receive when engaging with the public. With this work, we wanted to understand more about how the global health emergency, COVID-19, influences the amount, type or topics of abuse that UK politicians receive when engaging with the public. This work covers the period of June to December 2020 and analyses Twitter abuse in replies to UK MPs. This work is a follow-up from our analysis of online abuse during the first four months of the COVID-19 pandemic in the UK. The paper examines overall abuse levels during this new seven month period, analyses reactions to members of different political parties and the UK government, and the relationship between online abuse and topics such as Brexit, government's COVID-19 response and policies, and social issues. In addition, we have also examined the presence of conspiracy theories posted in abusive replies to MPs during the period. We have found that abuse levels toward UK MPs were at an all-time high in December 2020 (5.4% of all reply tweets sent to MPs). This is almost 1% higher that the two months preceding the General Election. In a departure from the trend seen in the first four months of the pandemic, MPs from the Tory party received the highest percentage of abusive replies from July 2020 onward, which stays above 5% starting from September 2020 onward, as the COVID-19 crisis deepened and the Brexit negotiations with the EU started nearing completion.