 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Language Models for Specialized Domains
Feb 25, 2025Compression techniques such as pruning and quantization offer a solution for more efficient deployment of language models (LMs), albeit with small performance drops in benchmark performance. However, general-purpose LM compression methods can negatively affect performance in specialized domains (e.g. biomedical or legal). Recent work has sought to address this, yet requires computationally expensive full-parameter fine-tuning. To this end, we propose cross-calibration, a novel training-free approach for improving the domain performance of compressed LMs. Our approach effectively leverages Hessian-based sensitivity to identify weights that are influential for both in-domain and general performance. Through extensive experimentation, we demonstrate that cross-calibration substantially outperforms existing approaches on domain-specific tasks, without compromising general performance. Notably, these gains come without additional computational overhead, displaying remarkable potential towards extracting domain-specialized compressed models from general-purpose LMs.
Self-calibration for Language Model Quantization and Pruning
Oct 22, 2024



Quantization and pruning are fundamental approaches for model compression, enabling efficient inference for language models. In a post-training setting, state-of-the-art quantization and pruning methods require calibration data, a small set of unlabeled examples. Conventionally, randomly sampled web text is used, aiming to reflect the model training data. However, this poses two key problems: (1) unrepresentative calibration examples can harm model performance, and (2) organizations increasingly avoid releasing model training data. In this paper, we propose self-calibration as a solution. Our approach requires no external data, instead leveraging the model itself to generate synthetic calibration data as a better approximation of the pre-training data distribution. We extensively compare the performance of self-calibration with several baselines, across a variety of models, compression methods, and tasks. Our approach proves consistently competitive in maximizing downstream task performance, frequently outperforming even using real data.
Lighter, yet More Faithful: Investigating Hallucinations in Pruned Large Language Models for Abstractive Summarization
Nov 15, 2023Despite their remarkable performance on abstractive summarization, large language models (LLMs) face two significant challenges: their considerable size and tendency to hallucinate. Hallucinations are concerning because they erode the reliability of LLMs and raise safety issues. Pruning is a technique that reduces model size by removing redundant weights to create sparse models that enable more efficient inference. Pruned models yield comparable performance to their counterpart full-sized models, making them ideal alternatives when operating on a limited budget. However, the effect that pruning has upon hallucinations in abstractive summarization with LLMs has yet to be explored. In this paper, we provide an extensive empirical study on the hallucinations produced by pruned models across three standard summarization tasks, two pruning approaches, three instruction-tuned LLMs, and three hallucination evaluation metrics. Surprisingly, we find that pruned LLMs hallucinate less compared to their full-sized counterparts. Our follow-up analysis suggests that pruned models tend to depend more on the source input and less on their parametric knowledge from pre-training for generation. This greater dependency on the source input leads to a higher lexical overlap between generated content and the source input, which can be a reason for the reduction in hallucinations.
On the Impact of Temporal Concept Drift on Model Explanations
Oct 17, 2022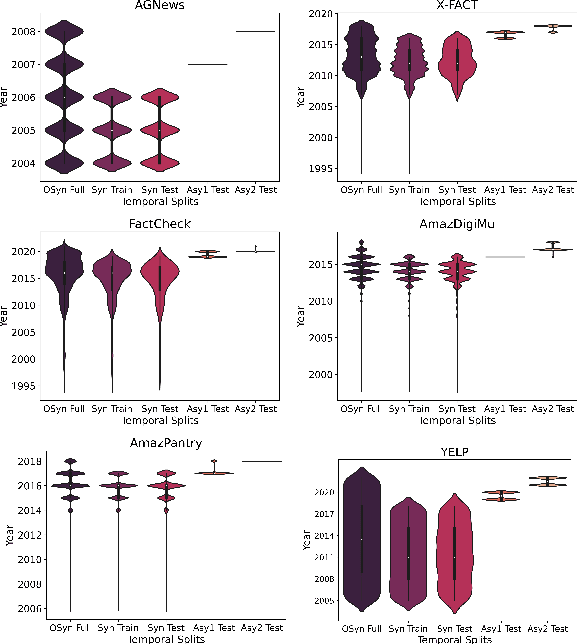
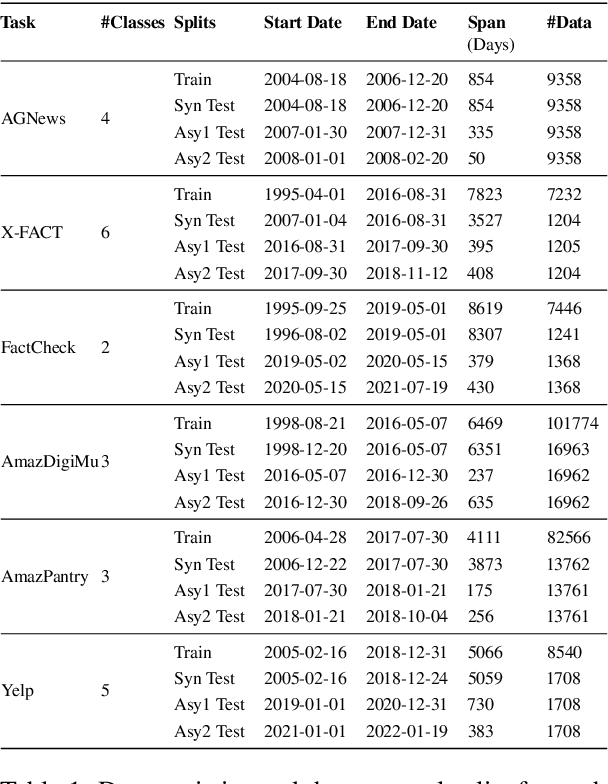
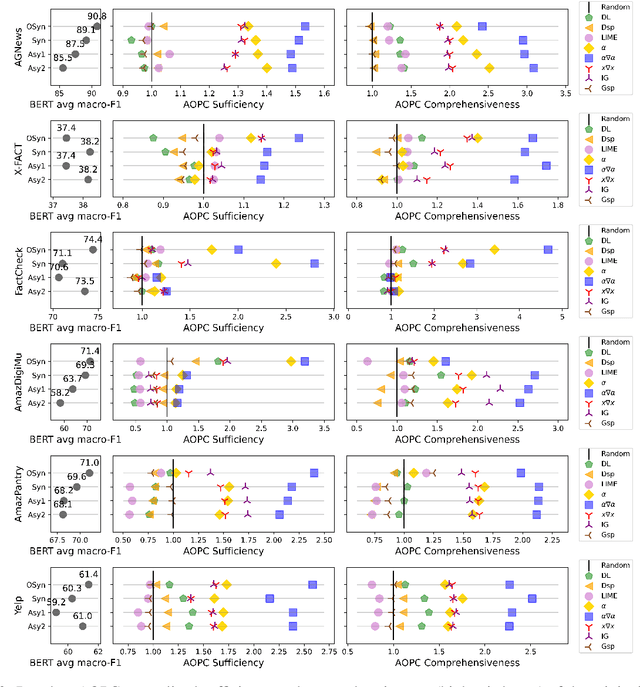
Explanation faithfulness of model predictions in natural language processing is typically evaluated on held-out data from the same temporal distribution as the training data (i.e. synchronous settings). While model performance often deteriorates due to temporal variation (i.e. temporal concept drift), it is currently unknown how explanation faithfulness is impacted when the time span of the target data is different from the data used to train the model (i.e. asynchronous settings). For this purpose, we examine the impact of temporal variation on model explanations extracted by eight feature attribution methods and three select-then-predict models across six text classification tasks. Our experiments show that (i)faithfulness is not consistent under temporal variations across feature attribution methods (e.g. it decreases or increases depending on the method), with an attention-based method demonstrating the most robust faithfulness scores across datasets; and (ii) select-then-predict models are mostly robust in asynchronous settings with only small degradation in predictive performance. Finally, feature attribution methods show conflicting behavior when used in FRESH (i.e. a select-and-predict model) and for measuring sufficiency/comprehensiveness (i.e. as post-hoc methods), suggesting that we need more robust metrics to evaluate post-hoc explanation faithfulness.
An Empirical Study on Explanations in Out-of-Domain Settings
Feb 28, 2022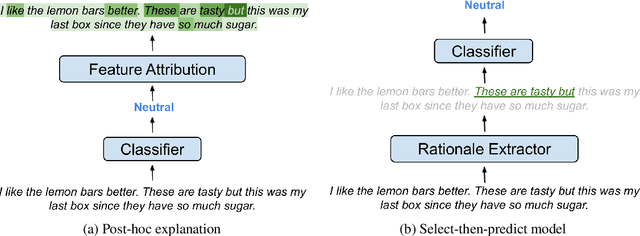
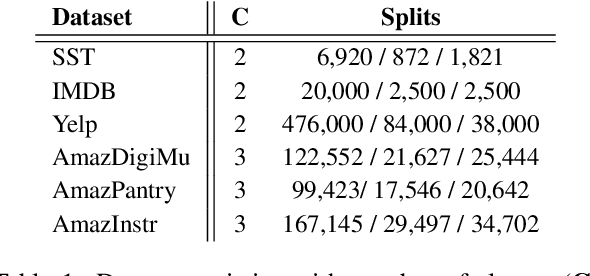
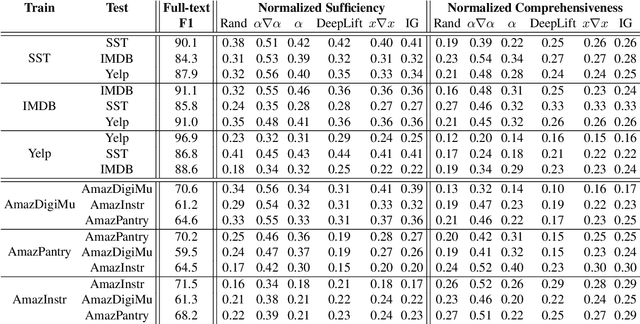
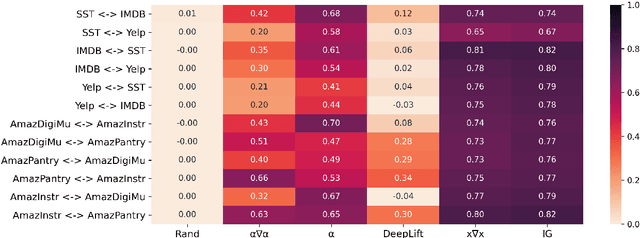
Recent work in Natural Language Processing has focused on developing approaches that extract faithful explanations, either via identifying the most important tokens in the input (i.e. post-hoc explanations) or by designing inherently faithful models that first select the most important tokens and then use them to predict the correct label (i.e. select-then-predict models). Currently, these approaches are largely evaluated on in-domain settings. Yet, little is known about how post-hoc explanations and inherently faithful models perform in out-of-domain settings. In this paper, we conduct an extensive empirical study that examines: (1) the out-of-domain faithfulness of post-hoc explanations, generated by five feature attribution methods; and (2) the out-of-domain performance of two inherently faithful models over six datasets. Contrary to our expectations, results show that in many cases out-of-domain post-hoc explanation faithfulness measured by sufficiency and comprehensiveness is higher compared to in-domain. We find this misleading and suggest using a random baseline as a yardstick for evaluating post-hoc explanation faithfulness. Our findings also show that select-then predict models demonstrate comparable predictive performance in out-of-domain settings to full-text trained models.
Frustratingly Simple Pretraining Alternatives to Masked Language Modeling
Sep 04, 2021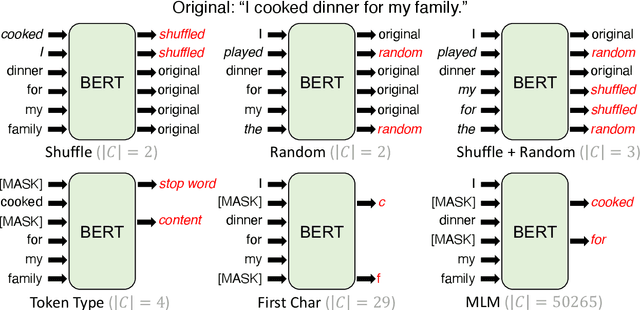
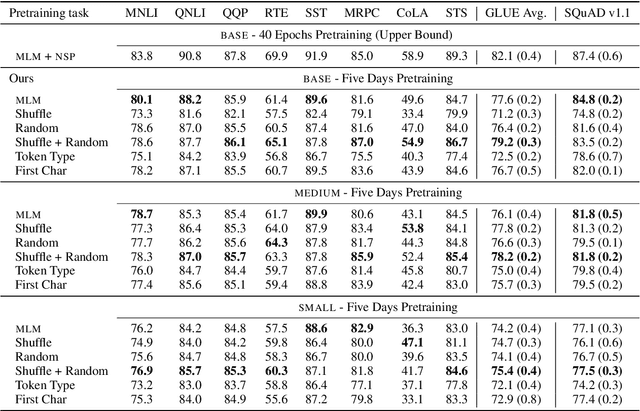
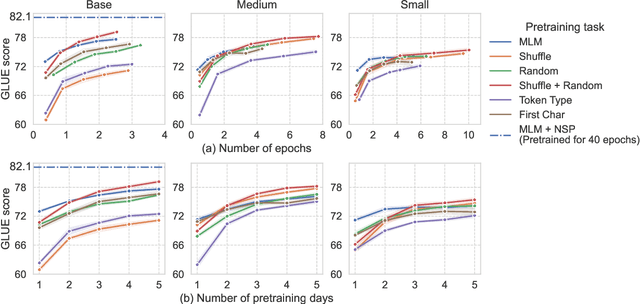
Masked language modeling (MLM), a self-supervised pretraining objective, is widely used in natural language processing for learning text representations. MLM trains a model to predict a random sample of input tokens that have been replaced by a [MASK] placeholder in a multi-class setting over the entire vocabulary. When pretraining, it is common to use alongside MLM other auxiliary objectives on the token or sequence level to improve downstream performance (e.g. next sentence prediction). However, no previous work so far has attempted in examining whether other simpler linguistically intuitive or not objectives can be used standalone as main pretraining objectives. In this paper, we explore five simple pretraining objectives based on token-level classification tasks as replacements of MLM. Empirical results on GLUE and SQuAD show that our proposed methods achieve comparable or better performance to MLM using a BERT-BASE architecture. We further validate our methods using smaller models, showing that pretraining a model with 41% of the BERT-BASE's parameters, BERT-MEDIUM results in only a 1% drop in GLUE scores with our best objective.
Enjoy the Salience: Towards Better Transformer-based Faithful Explanations with Word Salience
Aug 31, 2021
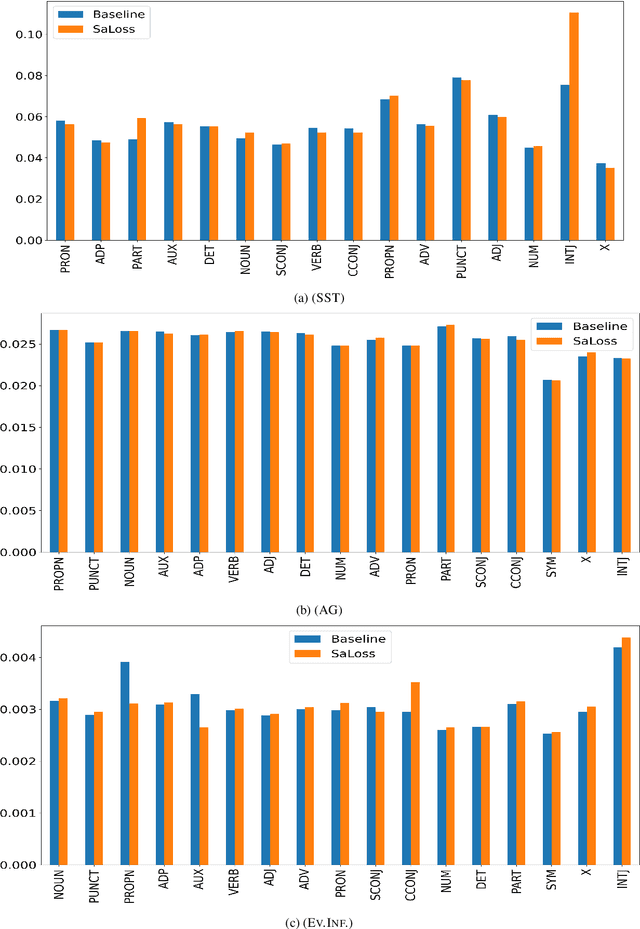
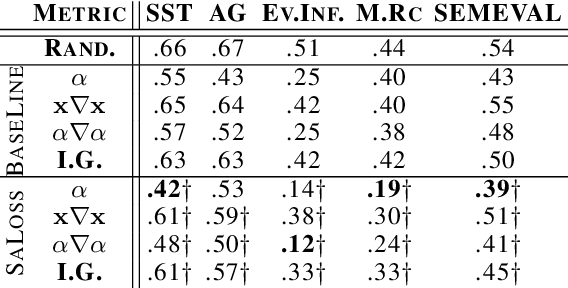
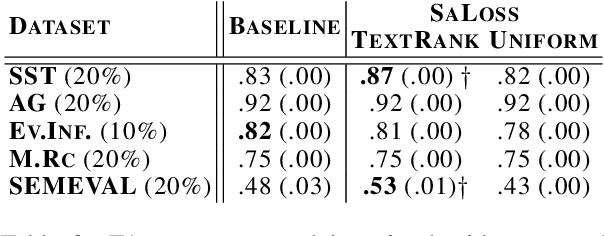
Pretrained transformer-based models such as BERT have demonstrated state-of-the-art predictive performance when adapted into a range of natural language processing tasks. An open problem is how to improve the faithfulness of explanations (rationales) for the predictions of these models. In this paper, we hypothesize that salient information extracted a priori from the training data can complement the task-specific information learned by the model during fine-tuning on a downstream task. In this way, we aim to help BERT not to forget assigning importance to informative input tokens when making predictions by proposing SaLoss; an auxiliary loss function for guiding the multi-head attention mechanism during training to be close to salient information extracted a priori using TextRank. Experiments for explanation faithfulness across five datasets, show that models trained with SaLoss consistently provide more faithful explanations across four different feature attribution methods compared to vanilla BERT. Using the rationales extracted from vanilla BERT and SaLoss models to train inherently faithful classifiers, we further show that the latter result in higher predictive performance in downstream tasks.
Improving the Faithfulness of Attention-based Explanations with Task-specific Information for Text Classification
May 07, 2021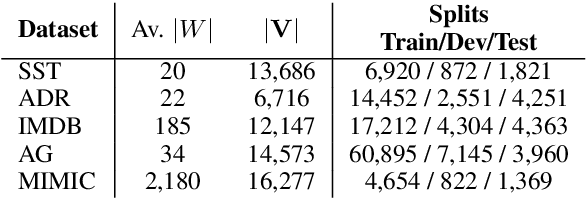
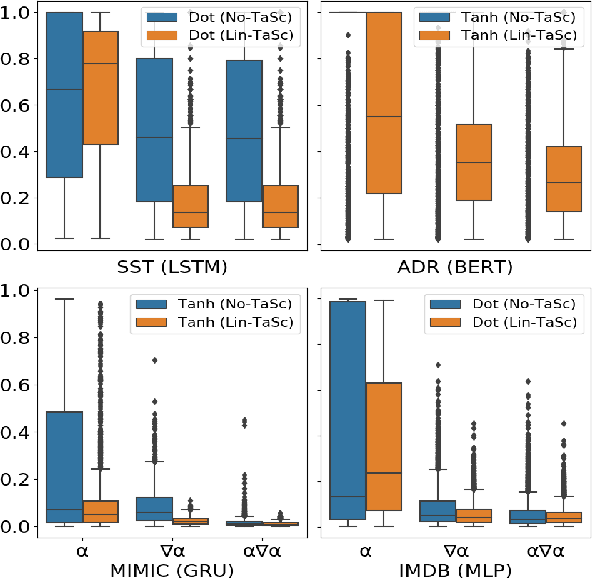
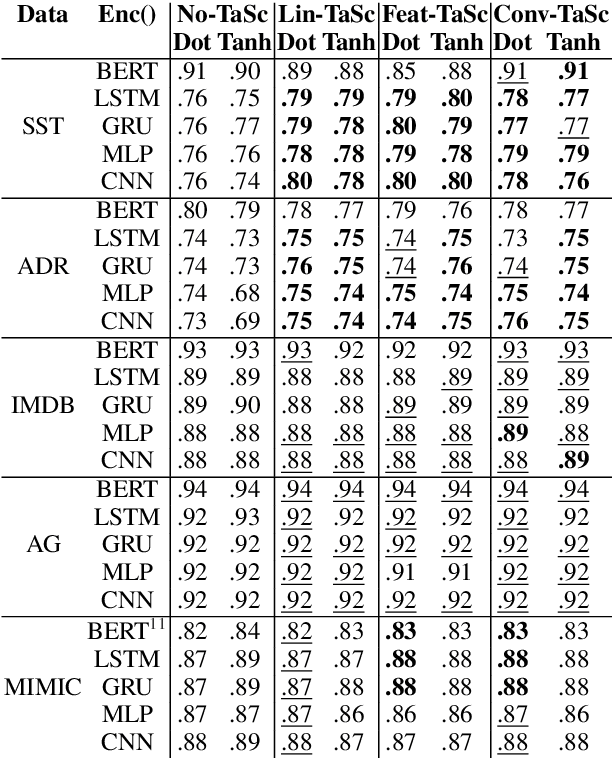
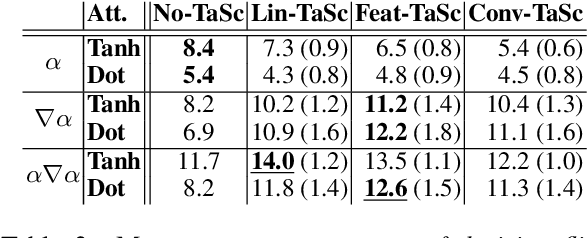
Neural network architectures in natural language processing often use attention mechanisms to produce probability distributions over input token representations. Attention has empirically been demonstrated to improve performance in various tasks, while its weights have been extensively used as explanations for model predictions. Recent studies (Jain and Wallace, 2019; Serrano and Smith, 2019; Wiegreffe and Pinter, 2019) have showed that it cannot generally be considered as a faithful explanation (Jacovi and Goldberg, 2020) across encoders and tasks. In this paper, we seek to improve the faithfulness of attention-based explanations for text classification. We achieve this by proposing a new family of Task-Scaling (TaSc) mechanisms that learn task-specific non-contextualised information to scale the original attention weights. Evaluation tests for explanation faithfulness, show that the three proposed variants of TaSc improve attention-based explanations across two attention mechanisms, five encoders and five text classification datasets without sacrificing predictive performance. Finally, we demonstrate that TaSc consistently provides more faithful attention-based explanations compared to three widely-used interpretability techniques.
Variable Instance-Level Explainability for Text Classification
Apr 16, 2021
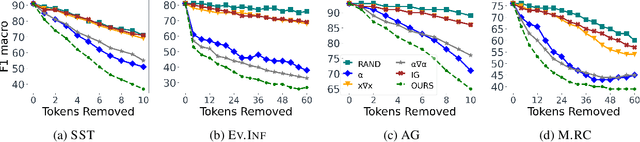
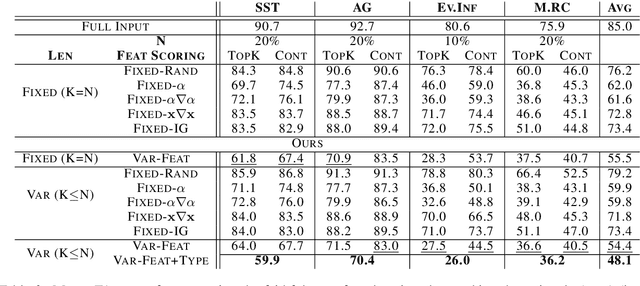
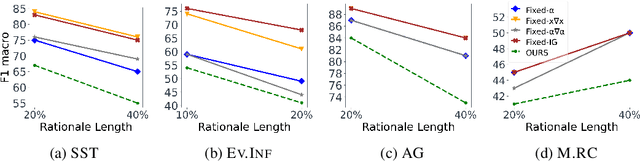
Despite the high accuracy of pretrained transformer networks in text classification, a persisting issue is their significant complexity that makes them hard to interpret. Recent research has focused on developing feature scoring methods for identifying which parts of the input are most important for the model to make a particular prediction and use it as an explanation (i.e. rationale). A limitation of these approaches is that they assume that a particular feature scoring method should be used across all instances in a dataset using a predefined fixed length, which might not be optimal across all instances. To address this, we propose a method for extracting variable-length explanations using a set of different feature scoring methods at instance-level. Our method is inspired by word erasure approaches which assume that the most faithful rationale for a prediction should be the one with the highest divergence between the model's output distribution using the full text and the text after removing the rationale for a particular instance. Evaluation on four standard text classification datasets shows that our method consistently provides more faithful explanations compared to previous fixed-length and fixed-feature scoring methods for rationale extraction.