 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Object Co-segmentation via Spatial-Semantic Network Modulation
Nov 29, 2019
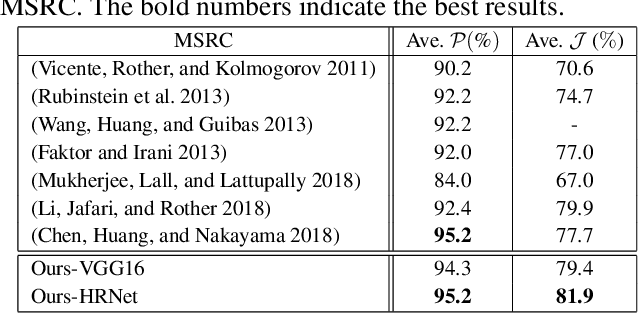
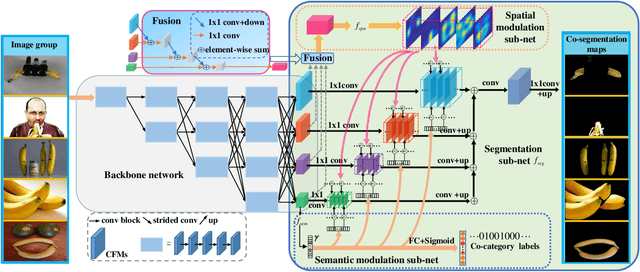
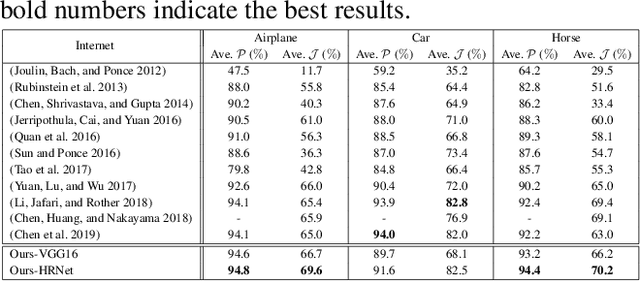
Object co-segmentation is to segment the shared objects in multiple relevant images, which has numerous applications in computer vision. This paper presents a spatial and semantic modulated deep network framework for object co-segmentation. A backbone network is adopted to extract multi-resolution image features. With the multi-resolution features of the relevant images as input, we design a spatial modulator to learn a mask for each image. The spatial modulator captures the correlations of image feature descriptors via unsupervised learning. The learned mask can roughly localize the shared foreground object while suppressing the background. For the semantic modulator, we model it as a supervised image classification task. We propose a hierarchical second-order pooling module to transform the image features for classification use. The outputs of the two modulators manipulate the multi-resolution features by a shift-and-scale operation so that the features focus on segmenting co-object regions. The proposed model is trained end-to-end without any intricate post-processing. Extensive experiments on four image co-segmentation benchmark datasets demonstrate the superior accuracy of the proposed method compared to state-of-the-art methods.
Unsupervised Video Segmentation via Spatio-Temporally Nonlocal Appearance Learning
Dec 24, 2016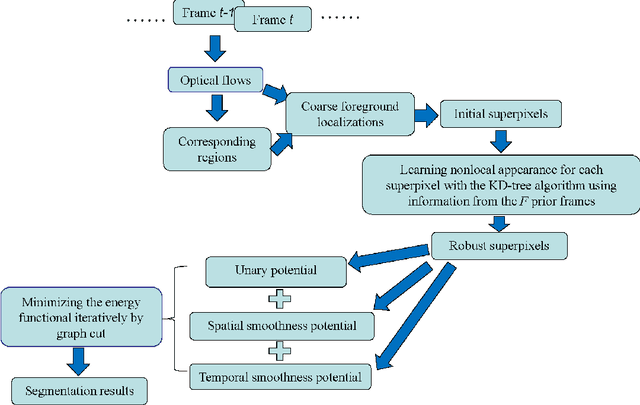
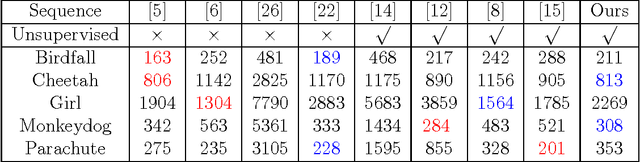
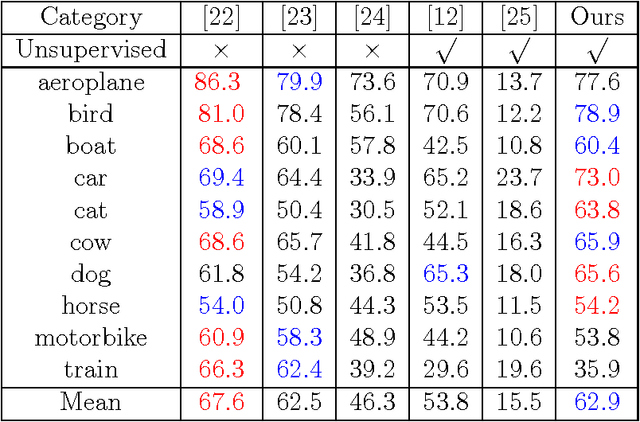
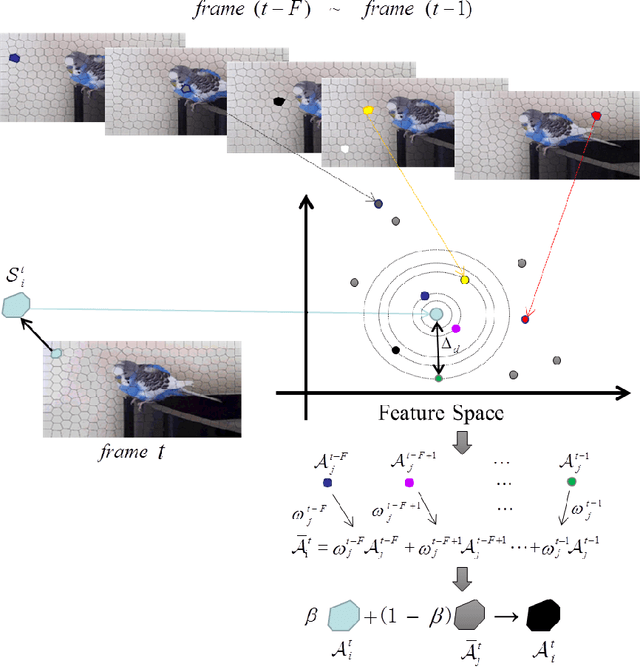
Video object segmentation is challenging due to the factors like rapidly fast motion, cluttered backgrounds, arbitrary object appearance variation and shape deformation. Most existing methods only explore appearance information between two consecutive frames, which do not make full use of the usefully long-term nonlocal information that is helpful to make the learned appearance stable, and hence they tend to fail when the targets suffer from large viewpoint changes and significant non-rigid deformations. In this paper, we propose a simple yet effective approach to mine the long-term sptatio-temporally nonlocal appearance information for unsupervised video segmentation. The motivation of our algorithm comes from the spatio-temporal nonlocality of the region appearance reoccurrence in a video. Specifically, we first generate a set of superpixels to represent the foreground and background, and then update the appearance of each superpixel with its long-term sptatio-temporally nonlocal counterparts generated by the approximate nearest neighbor search method with the efficient KD-tree algorithm. Then, with the updated appearances, we formulate a spatio-temporal graphical model comprised of the superpixel label consistency potentials. Finally, we generate the segmentation by optimizing the graphical model via iteratively updating the appearance model and estimating the labels. Extensive evaluations on the SegTrack and Youtube-Objects datasets demonstrate the effectiveness of the proposed method, which performs favorably against some state-of-art methods.
An Efficient Algorithm for the Piecewise-Smooth Model with Approximately Explicit Solutions
Dec 08, 2016

This paper presents an efficient approach to image segmentation that approximates the piecewise-smooth (PS) functional in [12] with explicit solutions. By rendering some rational constraints on the initial conditions and the final solutions of the PS functional, we propose two novel formulations which can be approximated to be the explicit solutions of the evolution partial differential equations (PDEs) of the PS model, in which only one PDE needs to be solved efficiently. Furthermore, an energy term that regularizes the level set function to be a signed distance function is incorporated into our evolution formulation, and the time-consuming re-initialization is avoided. Experiments on synthetic and real images show that our method is more efficient than both the PS model and the local binary fitting (LBF) model [4], while having similar segmentation accuracy as the LBF model.
Visual Tracking via Boolean Map Representations
Oct 30, 2016
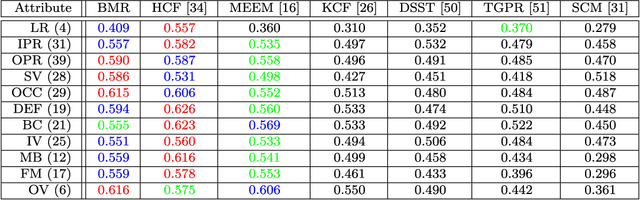

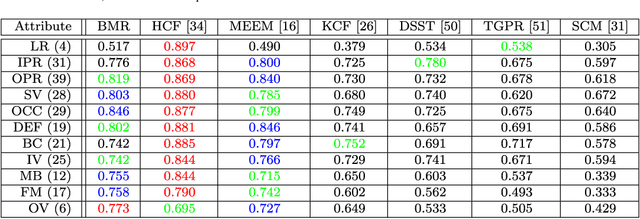
In this paper, we present a simple yet effective Boolean map based representation that exploits connectivity cues for visual tracking. We describe a target object with histogram of oriented gradients and raw color features, of which each one is characterized by a set of Boolean maps generated by uniformly thresholding their values. The Boolean maps effectively encode multi-scale connectivity cues of the target with different granularities. The fine-grained Boolean maps capture spatially structural details that are effective for precise target localization while the coarse-grained ones encode global shape information that are robust to large target appearance variations. Finally, all the Boolean maps form together a robust representation that can be approximated by an explicit feature map of the intersection kernel, which is fed into a logistic regression classifier with online update, and the target location is estimated within a particle filter framework. The proposed representation scheme is computationally efficient and facilitates achieving favorable performance in terms of accuracy and robustness against the state-of-the-art tracking methods on a large benchmark dataset of 50 image sequences.
Robust Visual Tracking via Convolutional Networks
Aug 24, 2015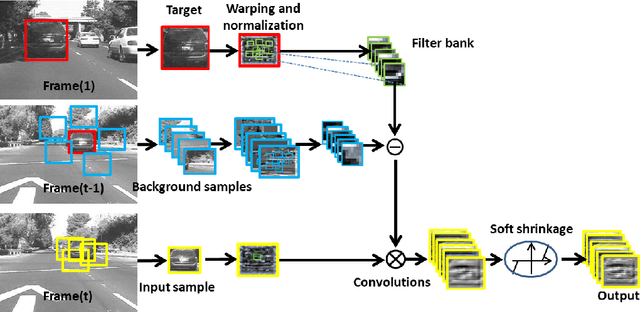
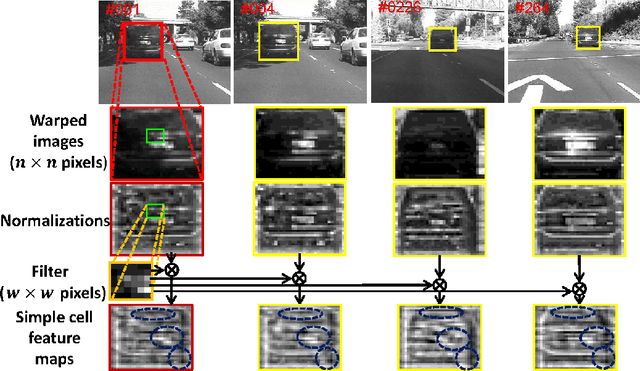

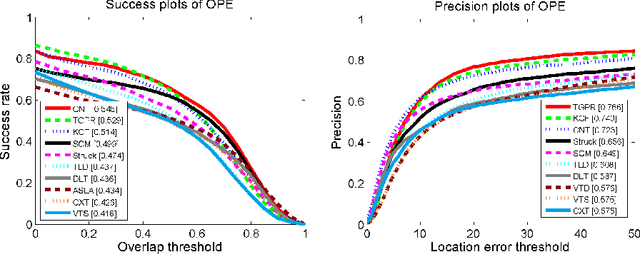
Deep networks have been successfully applied to visual tracking by learning a generic representation offline from numerous training images. However the offline training is time-consuming and the learned generic representation may be less discriminative for tracking specific objects. In this paper we present that, even without offline training with a large amount of auxiliary data, simple two-layer convolutional networks can be powerful enough to develop a robust representation for visual tracking. In the first frame, we employ the k-means algorithm to extract a set of normalized patches from the target region as fixed filters, which integrate a series of adaptive contextual filters surrounding the target to define a set of feature maps in the subsequent frames. These maps measure similarities between each filter and the useful local intensity patterns across the target, thereby encoding its local structural information. Furthermore, all the maps form together a global representation, which is built on mid-level features, thereby remaining close to image-level information, and hence the inner geometric layout of the target is also well preserved. A simple soft shrinkage method with an adaptive threshold is employed to de-noise the global representation, resulting in a robust sparse representation. The representation is updated via a simple and effective online strategy, allowing it to robustly adapt to target appearance variations. Our convolution networks have surprisingly lightweight structure, yet perform favorably against several state-of-the-art methods on the CVPR2013 tracking benchmark dataset with 50 challenging videos.
Adaptive Compressive Tracking via Online Vector Boosting Feature Selection
Apr 22, 2015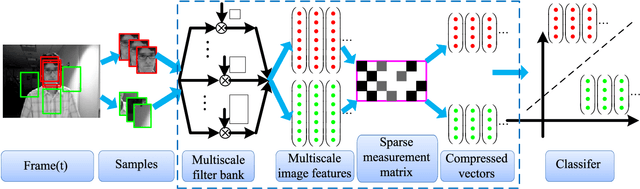
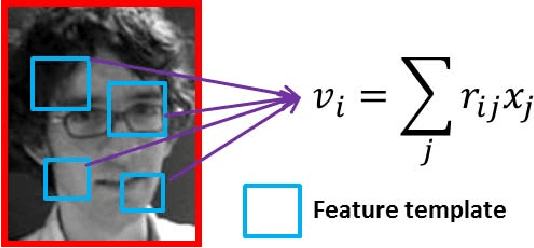
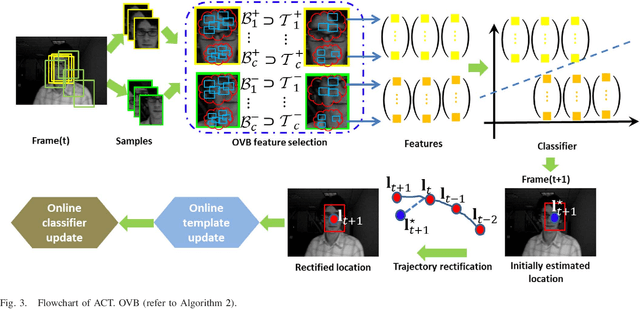
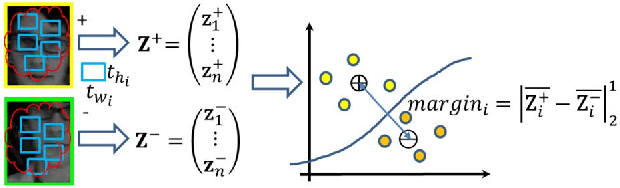
Recently, the compressive tracking (CT) method has attracted much attention due to its high efficiency, but it cannot well deal with the large scale target appearance variations due to its data-independent random projection matrix that results in less discriminative features. To address this issue, in this paper we propose an adaptive CT approach, which selects the most discriminative features to design an effective appearance model. Our method significantly improves CT in three aspects: Firstly, the most discriminative features are selected via an online vector boosting method. Secondly, the object representation is updated in an effective online manner, which preserves the stable features while filtering out the noisy ones. Finally, a simple and effective trajectory rectification approach is adopted that can make the estimated location more accurate. Extensive experiments on the CVPR2013 tracking benchmark demonstrate the superior performance of our algorithm compared over state-of-the-art tracking algorithms.
Fast Tracking via Spatio-Temporal Context Learning
Nov 08, 2013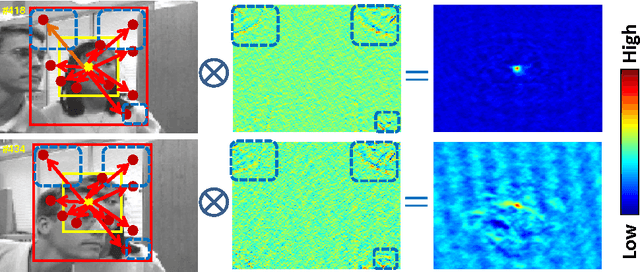
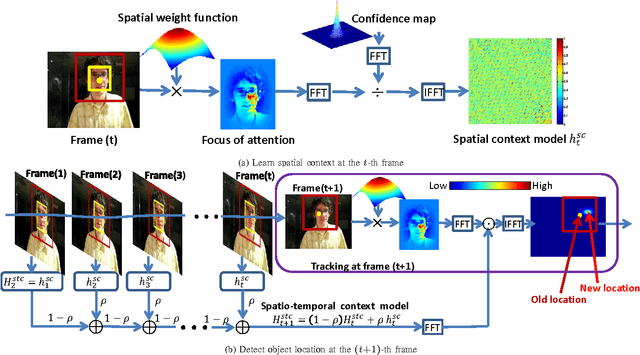
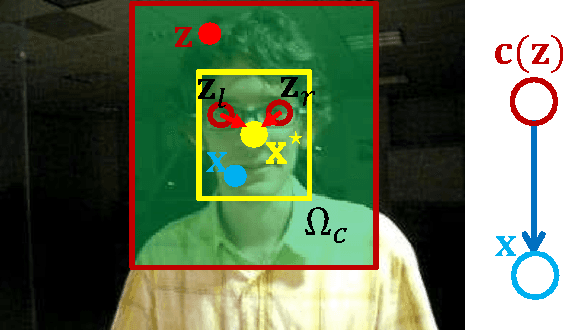
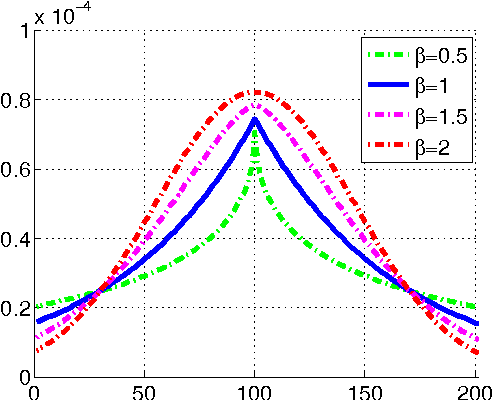
In this paper, we present a simple yet fast and robust algorithm which exploits the spatio-temporal context for visual tracking. Our approach formulates the spatio-temporal relationships between the object of interest and its local context based on a Bayesian framework, which models the statistical correlation between the low-level features (i.e., image intensity and position) from the target and its surrounding regions. The tracking problem is posed by computing a confidence map, and obtaining the best target location by maximizing an object location likelihood function. The Fast Fourier Transform is adopted for fast learning and detection in this work. Implemented in MATLAB without code optimization, the proposed tracker runs at 350 frames per second on an i7 machine. Extensive experimental results show that the proposed algorithm performs favorably against state-of-the-art methods in terms of efficiency, accuracy and robustness.
A Local Active Contour Model for Image Segmentation with Intensity Inhomogeneity
May 30, 2013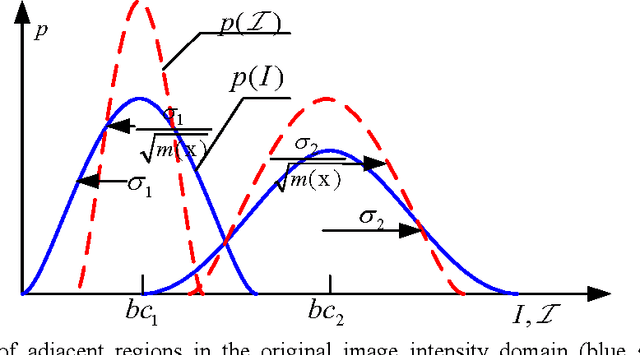
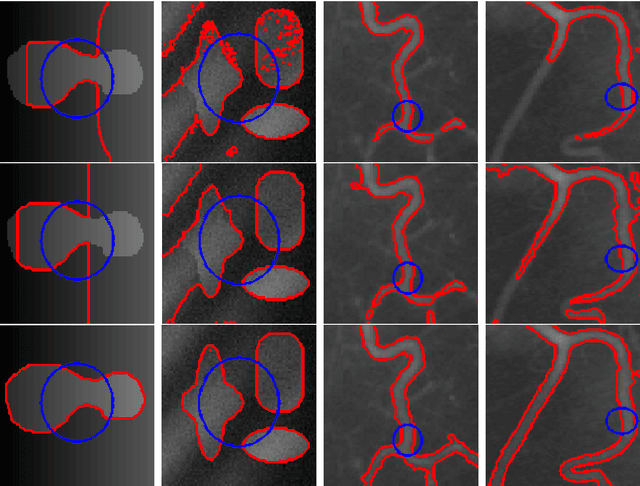
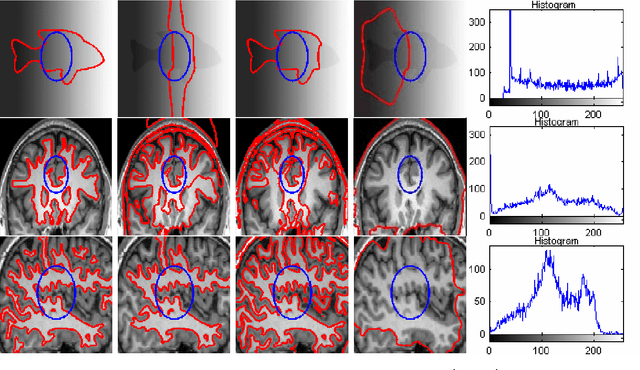

A novel locally statistical active contour model (ACM) for image segmentation in the presence of intensity inhomogeneity is presented in this paper. The inhomogeneous objects are modeled as Gaussian distributions of different means and variances, and a moving window is used to map the original image into another domain, where the intensity distributions of inhomogeneous objects are still Gaussian but are better separated. The means of the Gaussian distributions in the transformed domain can be adaptively estimated by multiplying a bias field with the original signal within the window. A statistical energy functional is then defined for each local region, which combines the bias field, the level set function, and the constant approximating the true signal of the corresponding object. Experiments on both synthetic and real images demonstrate the superiority of our proposed algorithm to state-of-the-art and representative methods.
Re-initialization Free Level Set Evolution via Reaction Diffusion
Aug 08, 2012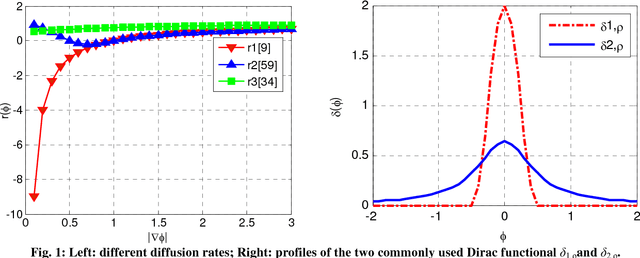
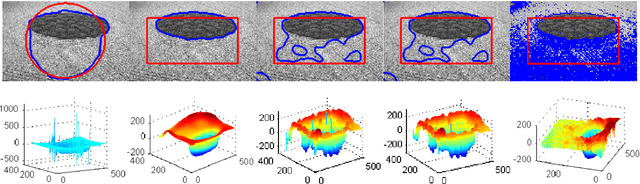

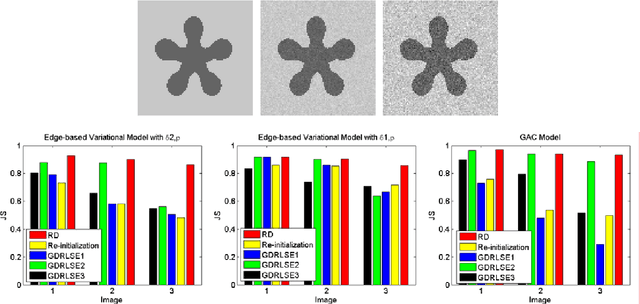
This paper presents a novel reaction-diffusion (RD) method for implicit active contours, which is completely free of the costly re-initialization procedure in level set evolution (LSE). A diffusion term is introduced into LSE, resulting in a RD-LSE equation, to which a piecewise constant solution can be derived. In order to have a stable numerical solution of the RD based LSE, we propose a two-step splitting method (TSSM) to iteratively solve the RD-LSE equation: first iterating the LSE equation, and then solving the diffusion equation. The second step regularizes the level set function obtained in the first step to ensure stability, and thus the complex and costly re-initialization procedure is completely eliminated from LSE. By successfully applying diffusion to LSE, the RD-LSE model is stable by means of the simple finite difference method, which is very easy to implement. The proposed RD method can be generalized to solve the LSE for both variational level set method and PDE-based level set method. The RD-LSE method shows very good performance on boundary anti-leakage, and it can be readily extended to high dimensional level set method. The extensive and promising experimental results on synthetic and real images validate the effectiveness of the proposed RD-LSE approach.