 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYouZhi: Towards High-Concurrency Financial LLMs via Adaptive GQA-to-MLA Transition
Jun 04, 2026Large language models (LLMs) drive significant financial innovations, yet their high-concurrency deployment is severely bottlenecked by KV cache memory overhead, which inflates infrastructure costs and throttles scalability. To address this, we propose YouZhi-LLM, a highly efficient financial LLM empowered by a comprehensive structural transition and training pipeline natively built on the Huawei Ascend ecosystem. At its algorithmic core, YouZhi-LLM features a layer-adaptive GQA-to-MLA transition framework that dynamically assigns per-layer FreqFold sizes, maximizing KV-cache compression while minimizing perplexity degradation. To recover representation capacity and inject domain expertise, the Ascend-based training pipeline seamlessly integrates generalized knowledge distillation with financial-specific supervised fine-tuning. Evaluations demonstrate the superiority of this systematic approach, with the adaptive transition reducing perplexity degradation by up to 35% over uniform baselines. Crucially, when evaluated on Ascend NPUs via vLLM-Ascend, the massive KV-cache reduction translates directly into deployment efficiency. Compared to their respective base models, YouZhi-7B yields a 12.3% improvement in average financial benchmark score alongside a 2.69$\times$ increase in maximum concurrency; similarly, YouZhi-14B achieves a 7.0% accuracy gain and a 2.43$\times$ concurrency boost, establishing a new paradigm for cost-effective, high-throughput financial inference.
From Long News to Accurate Forecast: Importance-Aware Fusion and PRM-Guided Reflection for Time Series Forecasting
Jun 02, 2026Incorporating news into time series forecasting is appealing because news can reveal abrupt exogenous events that historical values alone cannot recover. However, existing LLM-based news-forecasting pipelines face two practical limitations: relevant news articles often exceed the model's context window, and iterative retrieval of supplementary news is typically unguided, leading to redundant updates and slow convergence. We address these issues with a novel framework that combines importance-aware news compression and process-level retrieval supervision. First, we train an importance reward model that estimates the forecasting utility of each article and uses this signal to allocate compression budgets during sequential pairwise fusion, preserving informative content within a fixed context limit. Second, we introduce a process reward model (PRM) that ranks multiple supplementary-news candidates conditioned on the current error profile and the history of previously selected articles, replacing one-shot blind retrieval with quality-controlled selection. Both components are trained offline using historical data with ground truth; inference uses the frozen filtering logic and compression modules without any reflection loop. Experiments on finance, energy, traffic, and bitcoin forecasting benchmarks show that our method improves prediction accuracy over strong baselines, significantly reduces the number of refinement iterations compared to the iterative baseline, and remains effective when relevant articles span thousands of tokens.
Investigation of domain gap problem in several deep-learning-based CT metal artefact reduction methods
Nov 25, 2021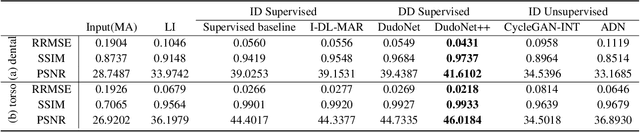
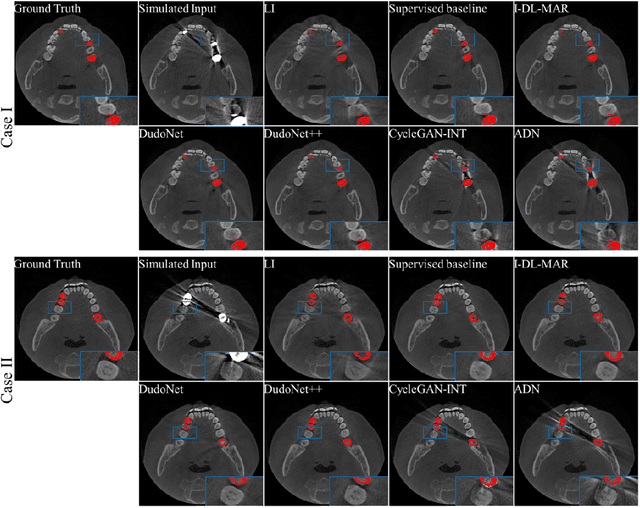
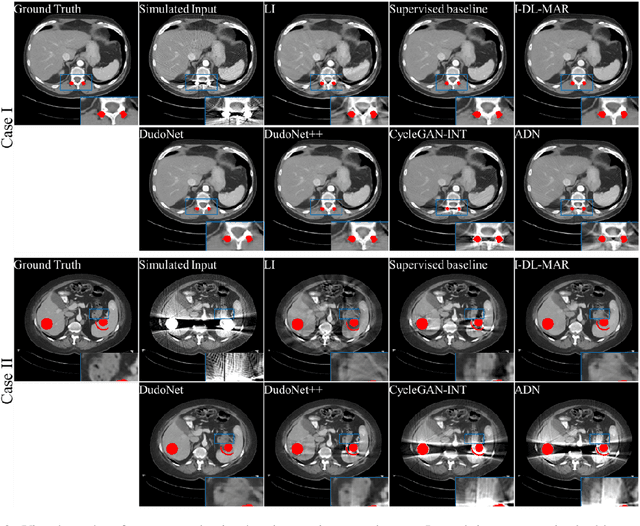
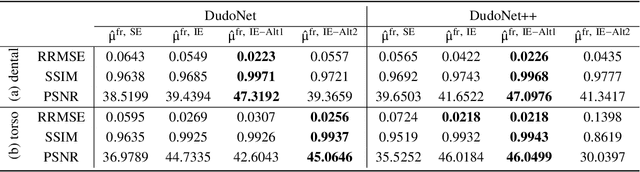
Metal artefacts in CT images may disrupt image quality and interfere with diagnosis. Recently many deep-learning-based CT metal artefact reduction (MAR) methods have been proposed. Current deep MAR methods may be troubled with domain gap problem, where methods trained on simulated data cannot perform well on practical data. In this work, we experimentally investigate two image-domain supervised methods, two dual-domain supervised methods and two image-domain unsupervised methods on a dental dataset and a torso dataset, to explore whether domain gap problem exists or is overcome. We find that I-DL-MAR and DudoNet are effective for practical data of the torso dataset, indicating the domain gap problem is solved. However, none of the investigated methods perform satisfactorily on practical data of the dental dataset. Based on the experimental results, we further analyze the causes of domain gap problem for each method and dataset, which may be beneficial for improving existing methods or designing new ones. The findings suggest that the domain gap problem in deep MAR methods remains to be addressed.