 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Out-of-Distribution Generalization of GNNs: An Architecture Perspective
Feb 14, 2024Graph neural networks (GNNs) have exhibited remarkable performance under the assumption that test data comes from the same distribution of training data. However, in real-world scenarios, this assumption may not always be valid. Consequently, there is a growing focus on exploring the Out-of-Distribution (OOD) problem in the context of graphs. Most existing efforts have primarily concentrated on improving graph OOD generalization from two \textbf{model-agnostic} perspectives: data-driven methods and strategy-based learning. However, there has been limited attention dedicated to investigating the impact of well-known \textbf{GNN model architectures} on graph OOD generalization, which is orthogonal to existing research. In this work, we provide the first comprehensive investigation of OOD generalization on graphs from an architecture perspective, by examining the common building blocks of modern GNNs. Through extensive experiments, we reveal that both the graph self-attention mechanism and the decoupled architecture contribute positively to graph OOD generalization. In contrast, we observe that the linear classification layer tends to compromise graph OOD generalization capability. Furthermore, we provide in-depth theoretical insights and discussions to underpin these discoveries. These insights have empowered us to develop a novel GNN backbone model, DGAT, designed to harness the robust properties of both graph self-attention mechanism and the decoupled architecture. Extensive experimental results demonstrate the effectiveness of our model under graph OOD, exhibiting substantial and consistent enhancements across various training strategies.
Deterministic Computing Power Networking: Architecture, Technologies and Prospects
Jan 31, 2024With the development of new Internet services such as computation-intensive and delay-sensitive tasks, the traditional "Best Effort" network transmission mode has been greatly challenged. The network system is urgently required to provide end-to-end transmission determinacy and computing determinacy for new applications to ensure the safe and efficient operation of services. Based on the research of the convergence of computing and networking, a new network paradigm named deterministic computing power networking (Det-CPN) is proposed. In this article, we firstly introduce the research advance of computing power networking. And then the motivations and scenarios of Det-CPN are analyzed. Following that, we present the system architecture, technological capabilities, workflow as well as key technologies for Det-CPN. Finally, the challenges and future trends of Det-CPN are analyzed and discussed.
EFL Students' Attitudes and Contradictions in a Machine-in-the-loop Activity System
Jul 13, 2023This study applies Activity Theory and investigates the attitudes and contradictions of 67 English as a foreign language (EFL) students from four Hong Kong secondary schools towards machine-in-the-loop writing, where artificial intelligence (AI) suggests ideas during composition. Students answered an open-ended question about their feelings on writing with AI. Results revealed mostly positive attitudes, with some negative or mixed feelings. From a thematic analysis, contradictions or points of tension between students and AI stemmed from AI inadequacies, students' balancing enthusiasm with preference, and their striving for language autonomy. The research highlights the benefits and challenges of implementing machine-in-the-loop writing in EFL classrooms, suggesting educators align activity goals with students' values, language abilities, and AI capabilities to enhance students' activity systems.
Cases of EFL Secondary Students' Prompt Engineering Pathways to Complete a Writing Task with ChatGPT
Jun 19, 2023ChatGPT is a state-of-the-art (SOTA) chatbot. Although it has potential to support English as a foreign language (EFL) students' writing, to effectively collaborate with it, a student must learn to engineer prompts, that is, the skill of crafting appropriate instructions so that ChatGPT produces desired outputs. However, writing an appropriate prompt for ChatGPT is not straightforward for non-technical users who suffer a trial-and-error process. This paper examines the content of EFL students' ChatGPT prompts when completing a writing task and explores patterns in the quality and quantity of the prompts. The data come from iPad screen recordings of secondary school EFL students who used ChatGPT and other SOTA chatbots for the first time to complete the same writing task. The paper presents a case study of four distinct pathways that illustrate the trial-and-error process and show different combinations of prompt content and quantity. The cases contribute evidence for the need to provide prompt engineering education in the context of the EFL writing classroom, if students are to move beyond an individual trial-and-error process, learning a greater variety of prompt content and more sophisticated prompts to support their writing.
Exploring EFL students' prompt engineering in human-AI story writing: an Activity Theory perspective
Jun 01, 2023This study applies Activity Theory to investigate how English as a foreign language (EFL) students prompt generative artificial intelligence (AI) tools during short story writing. Sixty-seven Hong Kong secondary school students created generative-AI tools using open-source language models and wrote short stories with them. The study collected and analyzed the students' generative-AI tools, short stories, and written reflections on their conditions or purposes for prompting. The research identified three main themes regarding the purposes for which students prompt generative-AI tools during short story writing: a lack of awareness of purposes, overcoming writer's block, and developing, expanding, and improving the story. The study also identified common characteristics of students' activity systems, including the sophistication of their generative-AI tools, the quality of their stories, and their school's overall academic achievement level, for their prompting of generative-AI tools for the three purposes during short story writing. The study's findings suggest that teachers should be aware of students' purposes for prompting generative-AI tools to provide tailored instructions and scaffolded guidance. The findings may also help designers provide differentiated instructions for users at various levels of story development when using a generative-AI tool.
The Role of AI in Human-AI Creative Writing for Hong Kong Secondary Students
Apr 21, 2023The recent advancement in Natural Language Processing (NLP) capability has led to the development of language models (e.g., ChatGPT) that is capable of generating human-like language. In this study, we explore how language models can be utilized to help the ideation aspect of creative writing. Our empirical findings show that language models play different roles in helping student writers to be more creative, such as the role of a collaborator, a provocateur, etc
Multi-head Uncertainty Inference for Adversarial Attack Detection
Dec 20, 2022Deep neural networks (DNNs) are sensitive and susceptible to tiny perturbation by adversarial attacks which causes erroneous predictions. Various methods, including adversarial defense and uncertainty inference (UI), have been developed in recent years to overcome the adversarial attacks. In this paper, we propose a multi-head uncertainty inference (MH-UI) framework for detecting adversarial attack examples. We adopt a multi-head architecture with multiple prediction heads (i.e., classifiers) to obtain predictions from different depths in the DNNs and introduce shallow information for the UI. Using independent heads at different depths, the normalized predictions are assumed to follow the same Dirichlet distribution, and we estimate distribution parameter of it by moment matching. Cognitive uncertainty brought by the adversarial attacks will be reflected and amplified on the distribution. Experimental results show that the proposed MH-UI framework can outperform all the referred UI methods in the adversarial attack detection task with different settings.
Gated Recurrent Unit for Video Denoising
Oct 17, 2022
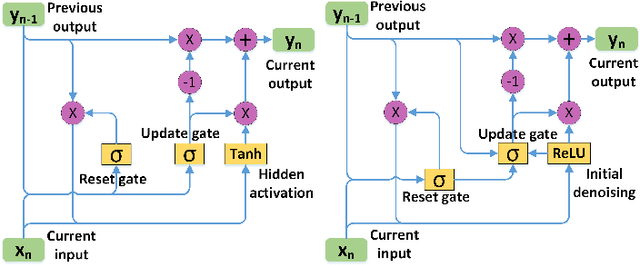
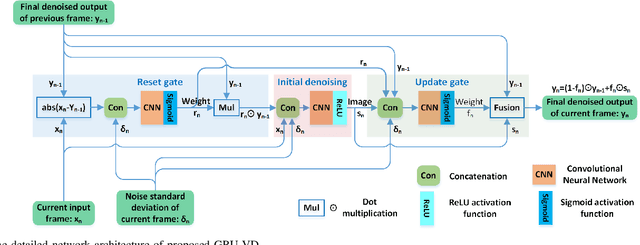

Current video denoising methods perform temporal fusion by designing convolutional neural networks (CNN) or combine spatial denoising with temporal fusion into basic recurrent neural networks (RNNs). However, there have not yet been works which adapt gated recurrent unit (GRU) mechanisms for video denoising. In this letter, we propose a new video denoising model based on GRU, namely GRU-VD. First, the reset gate is employed to mark the content related to the current frame in the previous frame output. Then the hidden activation works as an initial spatial-temporal denoising with the help from the marked relevant content. Finally, the update gate recursively fuses the initial denoised result with previous frame output to further increase accuracy. To handle various light conditions adaptively, the noise standard deviation of the current frame is also fed to these three modules. A weighted loss is adopted to regulate initial denoising and final fusion at the same time. The experimental results show that the GRU-VD network not only can achieve better quality than state of the arts objectively and subjectively, but also can obtain satisfied subjective quality on real video.
Bioinspired composite learning control under discontinuous friction for industrial robots
Jun 24, 2022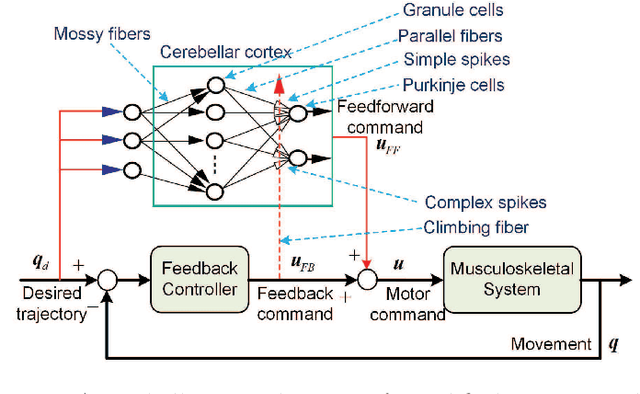
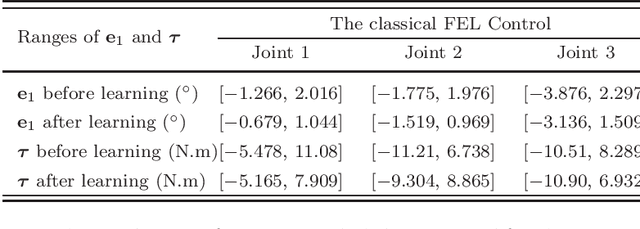
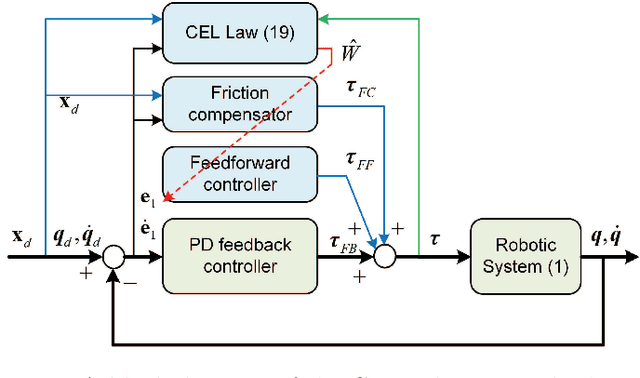

Adaptive control can be applied to robotic systems with parameter uncertainties, but improving its performance is usually difficult, especially under discontinuous friction. Inspired by the human motor learning control mechanism, an adaptive learning control approach is proposed for a broad class of robotic systems with discontinuous friction, where a composite error learning technique that exploits data memory is employed to enhance parameter estimation. Compared with the classical feedback error learning control, the proposed approach can achieve superior transient and steady-state tracking without high-gain feedback and persistent excitation at the cost of extra computational burden and memory usage. The performance improvement of the proposed approach has been verified by experiments based on a DENSO industrial robot.
Ternary and Binary Quantization for Improved Classification
Mar 31, 2022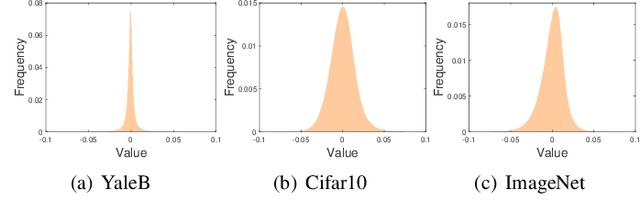
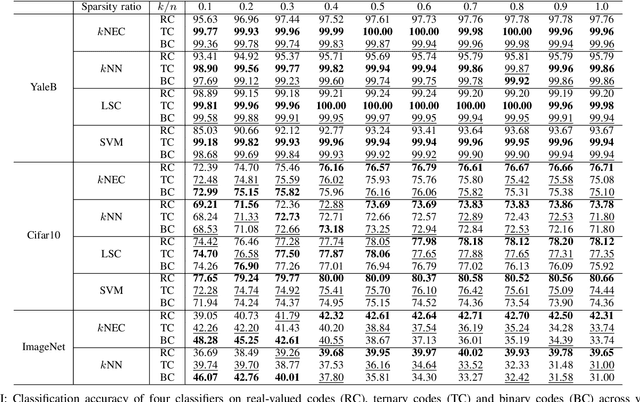
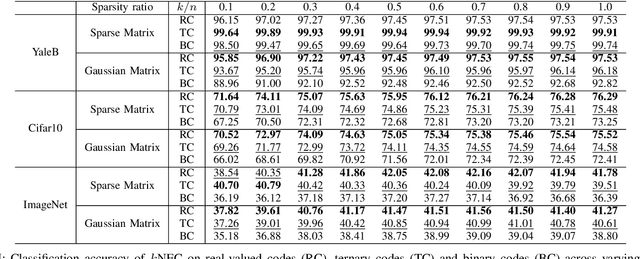
Dimension reduction and data quantization are two important methods for reducing data complexity. In the paper, we study the methodology of first reducing data dimension by random projection and then quantizing the projections to ternary or binary codes, which has been widely applied in classification. Usually, the quantization will seriously degrade the accuracy of classification due to high quantization errors. Interestingly, however, we observe that the quantization could provide comparable and often superior accuracy, as the data to be quantized are sparse features generated with common filters. Furthermore, this quantization property could be maintained in the random projections of sparse features, if both the features and random projection matrices are sufficiently sparse. By conducting extensive experiments, we validate and analyze this intriguing property.