 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaPhy: Capturing Physical Properties for Animatable Human Avatars
Aug 11, 2023



We present CaPhy, a novel method for reconstructing animatable human avatars with realistic dynamic properties for clothing. Specifically, we aim for capturing the geometric and physical properties of the clothing from real observations. This allows us to apply novel poses to the human avatar with physically correct deformations and wrinkles of the clothing. To this end, we combine unsupervised training with physics-based losses and 3D-supervised training using scanned data to reconstruct a dynamic model of clothing that is physically realistic and conforms to the human scans. We also optimize the physical parameters of the underlying physical model from the scans by introducing gradient constraints of the physics-based losses. In contrast to previous work on 3D avatar reconstruction, our method is able to generalize to novel poses with realistic dynamic cloth deformations. Experiments on several subjects demonstrate that our method can estimate the physical properties of the garments, resulting in superior quantitative and qualitative results compared with previous methods.
DiffuScene: Scene Graph Denoising Diffusion Probabilistic Model for Generative Indoor Scene Synthesis
Mar 24, 2023



We present DiffuScene for indoor 3D scene synthesis based on a novel scene graph denoising diffusion probabilistic model, which generates 3D instance properties stored in a fully-connected scene graph and then retrieves the most similar object geometry for each graph node i.e. object instance which is characterized as a concatenation of different attributes, including location, size, orientation, semantic, and geometry features. Based on this scene graph, we designed a diffusion model to determine the placements and types of 3D instances. Our method can facilitate many downstream applications, including scene completion, scene arrangement, and text-conditioned scene synthesis. Experiments on the 3D-FRONT dataset show that our method can synthesize more physically plausible and diverse indoor scenes than state-of-the-art methods. Extensive ablation studies verify the effectiveness of our design choice in scene diffusion models.
Imitator: Personalized Speech-driven 3D Facial Animation
Dec 30, 2022Speech-driven 3D facial animation has been widely explored, with applications in gaming, character animation, virtual reality, and telepresence systems. State-of-the-art methods deform the face topology of the target actor to sync the input audio without considering the identity-specific speaking style and facial idiosyncrasies of the target actor, thus, resulting in unrealistic and inaccurate lip movements. To address this, we present Imitator, a speech-driven facial expression synthesis method, which learns identity-specific details from a short input video and produces novel facial expressions matching the identity-specific speaking style and facial idiosyncrasies of the target actor. Specifically, we train a style-agnostic transformer on a large facial expression dataset which we use as a prior for audio-driven facial expressions. Based on this prior, we optimize for identity-specific speaking style based on a short reference video. To train the prior, we introduce a novel loss function based on detected bilabial consonants to ensure plausible lip closures and consequently improve the realism of the generated expressions. Through detailed experiments and a user study, we show that our approach produces temporally coherent facial expressions from input audio while preserving the speaking style of the target actors.
MIME: Human-Aware 3D Scene Generation
Dec 08, 2022



Generating realistic 3D worlds occupied by moving humans has many applications in games, architecture, and synthetic data creation. But generating such scenes is expensive and labor intensive. Recent work generates human poses and motions given a 3D scene. Here, we take the opposite approach and generate 3D indoor scenes given 3D human motion. Such motions can come from archival motion capture or from IMU sensors worn on the body, effectively turning human movement in a "scanner" of the 3D world. Intuitively, human movement indicates the free-space in a room and human contact indicates surfaces or objects that support activities such as sitting, lying or touching. We propose MIME (Mining Interaction and Movement to infer 3D Environments), which is a generative model of indoor scenes that produces furniture layouts that are consistent with the human movement. MIME uses an auto-regressive transformer architecture that takes the already generated objects in the scene as well as the human motion as input, and outputs the next plausible object. To train MIME, we build a dataset by populating the 3D FRONT scene dataset with 3D humans. Our experiments show that MIME produces more diverse and plausible 3D scenes than a recent generative scene method that does not know about human movement. Code and data will be available for research at https://mime.is.tue.mpg.de.
ClipFace: Text-guided Editing of Textured 3D Morphable Models
Dec 02, 2022We propose ClipFace, a novel self-supervised approach for text-guided editing of textured 3D morphable model of faces. Specifically, we employ user-friendly language prompts to enable control of the expressions as well as appearance of 3D faces. We leverage the geometric expressiveness of 3D morphable models, which inherently possess limited controllability and texture expressivity, and develop a self-supervised generative model to jointly synthesize expressive, textured, and articulated faces in 3D. We enable high-quality texture generation for 3D faces by adversarial self-supervised training, guided by differentiable rendering against collections of real RGB images. Controllable editing and manipulation are given by language prompts to adapt texture and expression of the 3D morphable model. To this end, we propose a neural network that predicts both texture and expression latent codes of the morphable model. Our model is trained in a self-supervised fashion by exploiting differentiable rendering and losses based on a pre-trained CLIP model. Once trained, our model jointly predicts face textures in UV-space, along with expression parameters to capture both geometry and texture changes in facial expressions in a single forward pass. We further show the applicability of our method to generate temporally changing textures for a given animation sequence.
High-Res Facial Appearance Capture from Polarized Smartphone Images
Dec 02, 2022



We propose a novel method for high-quality facial texture reconstruction from RGB images using a novel capturing routine based on a single smartphone which we equip with an inexpensive polarization foil. Specifically, we turn the flashlight into a polarized light source and add a polarization filter on top of the camera. Leveraging this setup, we capture the face of a subject with cross-polarized and parallel-polarized light. For each subject, we record two short sequences in a dark environment under flash illumination with different light polarization using the modified smartphone. Based on these observations, we reconstruct an explicit surface mesh of the face using structure from motion. We then exploit the camera and light co-location within a differentiable renderer to optimize the facial textures using an analysis-by-synthesis approach. Our method optimizes for high-resolution normal textures, diffuse albedo, and specular albedo using a coarse-to-fine optimization scheme. We show that the optimized textures can be used in a standard rendering pipeline to synthesize high-quality photo-realistic 3D digital humans in novel environments.
DINER: Depth-aware Image-based NEural Radiance fields
Nov 29, 2022We present Depth-aware Image-based NEural Radiance fields (DINER). Given a sparse set of RGB input views, we predict depth and feature maps to guide the reconstruction of a volumetric scene representation that allows us to render 3D objects under novel views. Specifically, we propose novel techniques to incorporate depth information into feature fusion and efficient scene sampling. In comparison to the previous state of the art, DINER achieves higher synthesis quality and can process input views with greater disparity. This allows us to capture scenes more completely without changing capturing hardware requirements and ultimately enables larger viewpoint changes during novel view synthesis. We evaluate our method by synthesizing novel views, both for human heads and for general objects, and observe significantly improved qualitative results and increased perceptual metrics compared to the previous state of the art. The code will be made publicly available for research purposes.
Instant Volumetric Head Avatars
Nov 22, 2022



We present Instant Volumetric Head Avatars (INSTA), a novel approach for reconstructing photo-realistic digital avatars instantaneously. INSTA models a dynamic neural radiance field based on neural graphics primitives embedded around a parametric face model. Our pipeline is trained on a single monocular RGB portrait video that observes the subject under different expressions and views. While state-of-the-art methods take up to several days to train an avatar, our method can reconstruct a digital avatar in less than 10 minutes on modern GPU hardware, which is orders of magnitude faster than previous solutions. In addition, it allows for the interactive rendering of novel poses and expressions. By leveraging the geometry prior of the underlying parametric face model, we demonstrate that INSTA extrapolates to unseen poses. In quantitative and qualitative studies on various subjects, INSTA outperforms state-of-the-art methods regarding rendering quality and training time.
Neural Shape Deformation Priors
Oct 11, 2022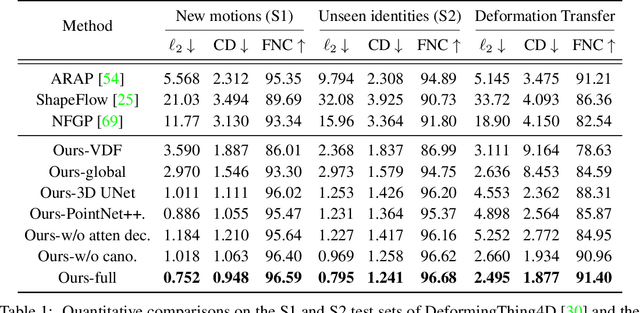
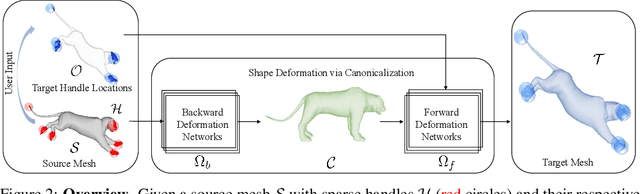
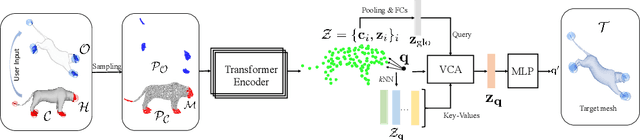
We present Neural Shape Deformation Priors, a novel method for shape manipulation that predicts mesh deformations of non-rigid objects from user-provided handle movements. State-of-the-art methods cast this problem as an optimization task, where the input source mesh is iteratively deformed to minimize an objective function according to hand-crafted regularizers such as ARAP. In this work, we learn the deformation behavior based on the underlying geometric properties of a shape, while leveraging a large-scale dataset containing a diverse set of non-rigid deformations. Specifically, given a source mesh and desired target locations of handles that describe the partial surface deformation, we predict a continuous deformation field that is defined in 3D space to describe the space deformation. To this end, we introduce transformer-based deformation networks that represent a shape deformation as a composition of local surface deformations. It learns a set of local latent codes anchored in 3D space, from which we can learn a set of continuous deformation functions for local surfaces. Our method can be applied to challenging deformations and generalizes well to unseen deformations. We validate our approach in experiments using the DeformingThing4D dataset, and compare to both classic optimization-based and recent neural network-based methods.
Towards Metrical Reconstruction of Human Faces
Apr 13, 2022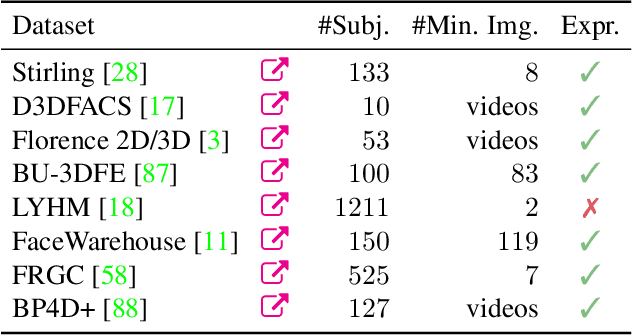
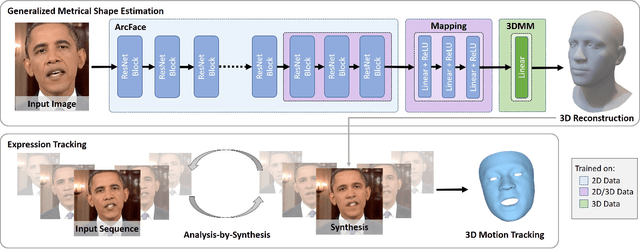
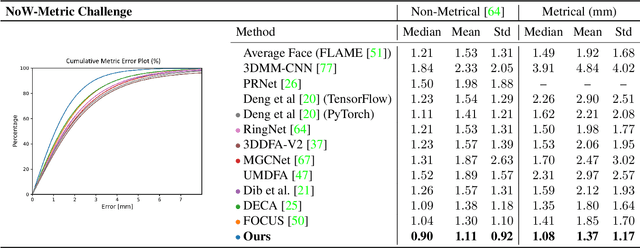
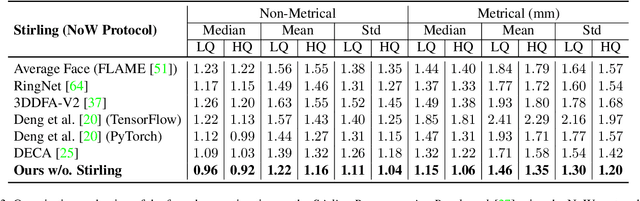
Face reconstruction and tracking is a building block of numerous applications in AR/VR, human-machine interaction, as well as medical applications. Most of these applications rely on a metrically correct prediction of the shape, especially, when the reconstructed subject is put into a metrical context (i.e., when there is a reference object of known size). A metrical reconstruction is also needed for any application that measures distances and dimensions of the subject (e.g., to virtually fit a glasses frame). State-of-the-art methods for face reconstruction from a single image are trained on large 2D image datasets in a self-supervised fashion. However, due to the nature of a perspective projection they are not able to reconstruct the actual face dimensions, and even predicting the average human face outperforms some of these methods in a metrical sense. To learn the actual shape of a face, we argue for a supervised training scheme. Since there exists no large-scale 3D dataset for this task, we annotated and unified small- and medium-scale databases. The resulting unified dataset is still a medium-scale dataset with more than 2k identities and training purely on it would lead to overfitting. To this end, we take advantage of a face recognition network pretrained on a large-scale 2D image dataset, which provides distinct features for different faces and is robust to expression, illumination, and camera changes. Using these features, we train our face shape estimator in a supervised fashion, inheriting the robustness and generalization of the face recognition network. Our method, which we call MICA (MetrIC fAce), outperforms the state-of-the-art reconstruction methods by a large margin, both on current non-metric benchmarks as well as on our metric benchmarks (15% and 24% lower average error on NoW, respectively).