 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Approximate Geodesics for Deep Generative Models
Dec 19, 2018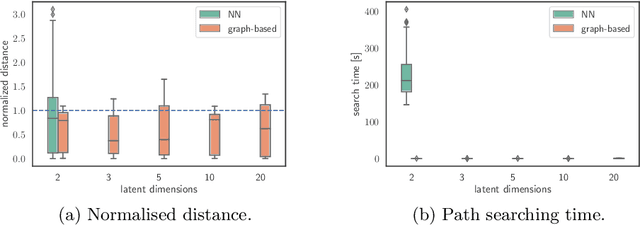
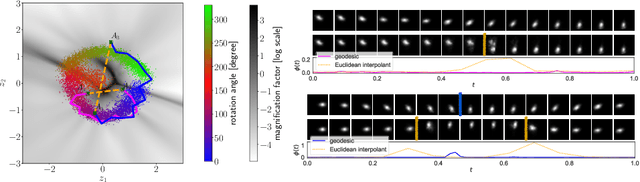
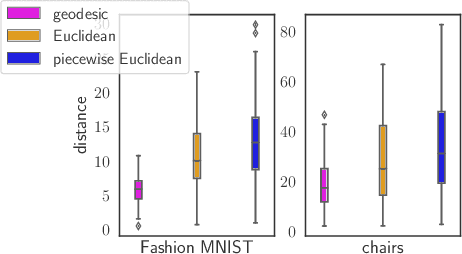
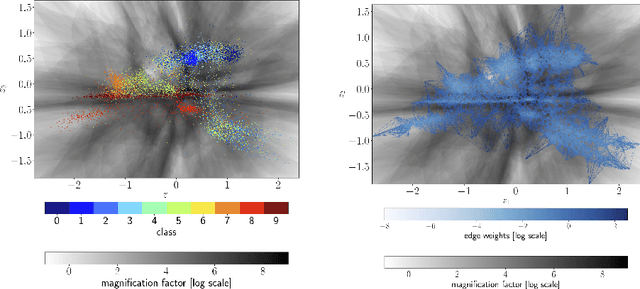
The length of the geodesic between two data points along the Riemannian manifold, induced by a deep generative model, yields a principled measure of similarity. Applications have so far been limited to low-dimensional latent spaces, as the method is computationally demanding: it constitutes to solving a non-convex optimisation problem. Our approach is to tackle a relaxation: finding shortest paths in a finite graph of samples from the aggregate approximate posterior can be solved exactly, at greatly reduced runtime, and without notable loss in quality. The method is hence applicable to high-dimensional problems in the visual domain. We validate the approach empirically on a series of experiments using variational autoencoders applied to image data, tackling the Chair, Faces and FashionMNIST data sets.
Approximate Bayesian inference in spatial environments
May 18, 2018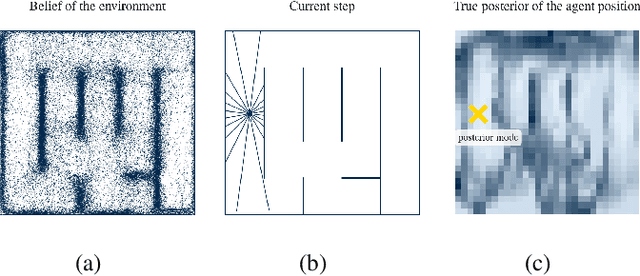
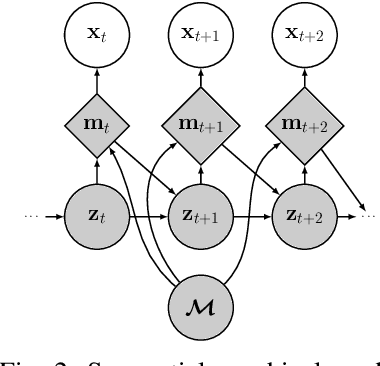
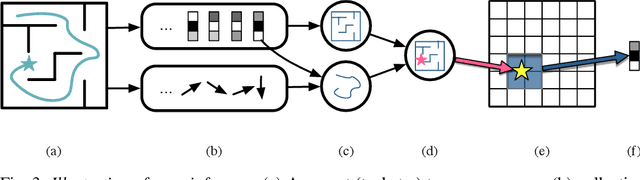
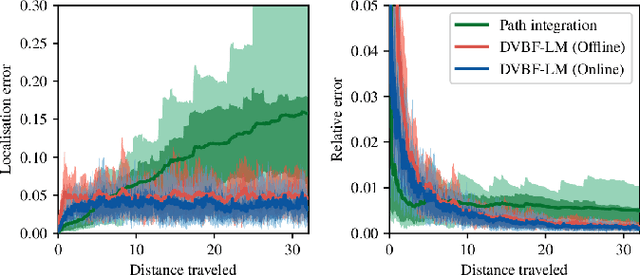
We propose to learn a stochastic recurrent model to solve the problem of simultaneous localisation and mapping (SLAM). Our model is a deep variational Bayes filter augmented with a latent global variable---similar to an external memory component---representing the spatially structured environment. Reasoning about the pose of an agent and the map of the environment is then naturally expressed as posterior inference in the resulting generative model. We evaluate the method on a set of randomly generated mazes which are traversed by an agent equipped with laser range finders. Path integration based on an accurate motion model is consistently outperformed, and most importantly, drift practically eliminated. Our approach inherits favourable properties from neural networks, such as differentiability, flexibility and the ability to train components either in isolation or end-to-end.
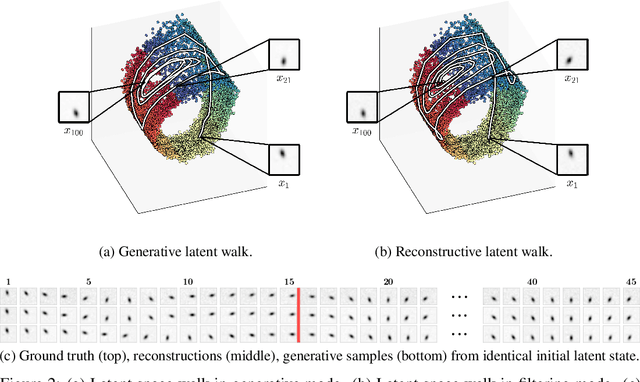
Metrics for Deep Generative Models
Feb 08, 2018
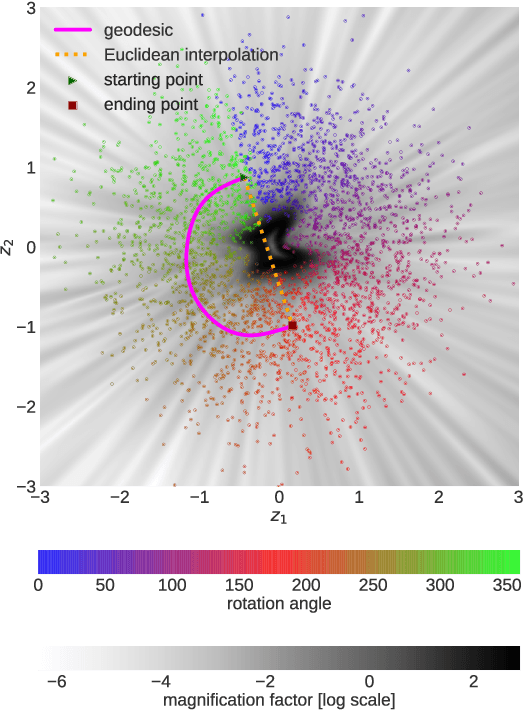
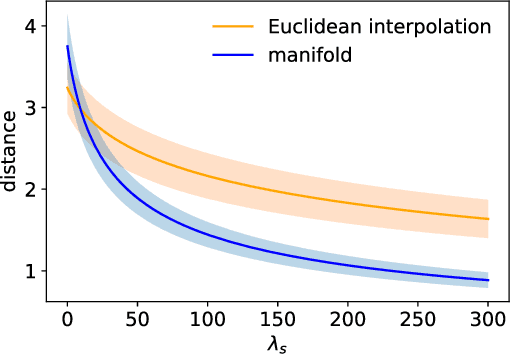
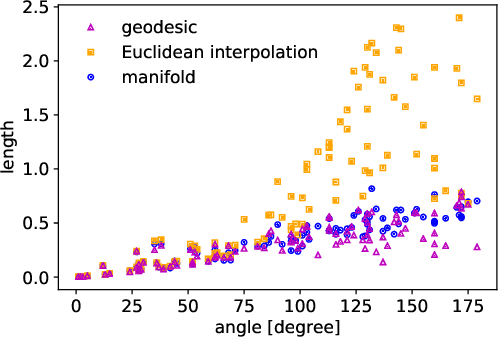
Neural samplers such as variational autoencoders (VAEs) or generative adversarial networks (GANs) approximate distributions by transforming samples from a simple random source---the latent space---to samples from a more complex distribution represented by a dataset. While the manifold hypothesis implies that the density induced by a dataset contains large regions of low density, the training criterions of VAEs and GANs will make the latent space densely covered. Consequently points that are separated by low-density regions in observation space will be pushed together in latent space, making stationary distances poor proxies for similarity. We transfer ideas from Riemannian geometry to this setting, letting the distance between two points be the shortest path on a Riemannian manifold induced by the transformation. The method yields a principled distance measure, provides a tool for visual inspection of deep generative models, and an alternative to linear interpolation in latent space. In addition, it can be applied for robot movement generalization using previously learned skills. The method is evaluated on a synthetic dataset with known ground truth; on a simulated robot arm dataset; on human motion capture data; and on a generative model of handwritten digits.
* Published on the 21st International Conference on Artificial Intelligence and Statistics (AISTATS), 2018
Unsupervised Real-Time Control through Variational Empowerment
Oct 13, 2017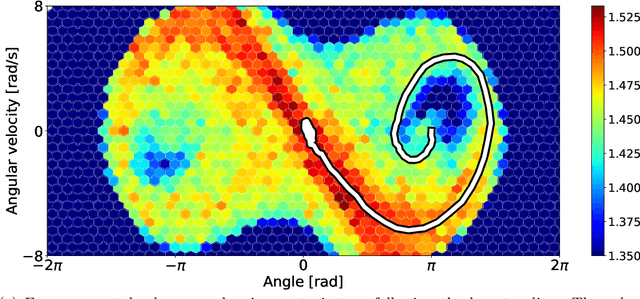
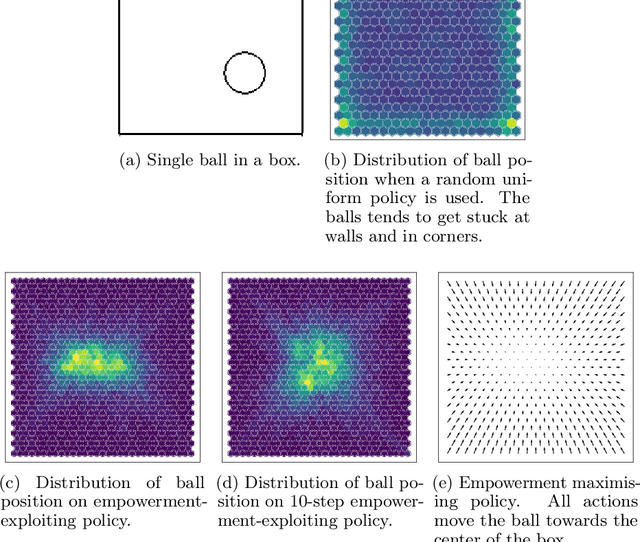
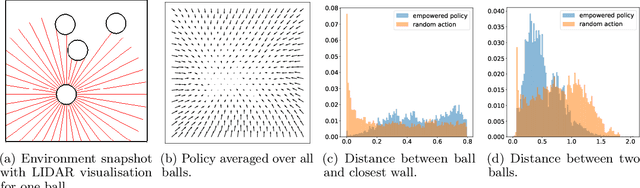
We introduce a methodology for efficiently computing a lower bound to empowerment, allowing it to be used as an unsupervised cost function for policy learning in real-time control. Empowerment, being the channel capacity between actions and states, maximises the influence of an agent on its near future. It has been shown to be a good model of biological behaviour in the absence of an extrinsic goal. But empowerment is also prohibitively hard to compute, especially in nonlinear continuous spaces. We introduce an efficient, amortised method for learning empowerment-maximising policies. We demonstrate that our algorithm can reliably handle continuous dynamical systems using system dynamics learned from raw data. The resulting policies consistently drive the agents into states where they can use their full potential.
Deep Variational Bayes Filters: Unsupervised Learning of State Space Models from Raw Data
Mar 03, 2017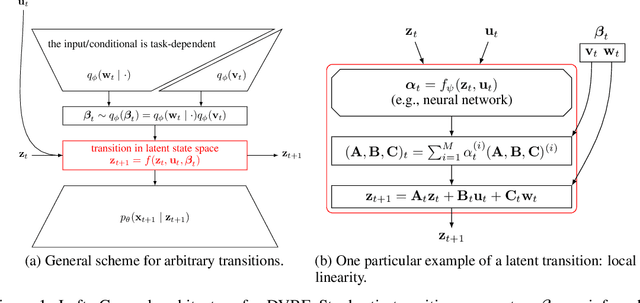
We introduce Deep Variational Bayes Filters (DVBF), a new method for unsupervised learning and identification of latent Markovian state space models. Leveraging recent advances in Stochastic Gradient Variational Bayes, DVBF can overcome intractable inference distributions via variational inference. Thus, it can handle highly nonlinear input data with temporal and spatial dependencies such as image sequences without domain knowledge. Our experiments show that enabling backpropagation through transitions enforces state space assumptions and significantly improves information content of the latent embedding. This also enables realistic long-term prediction.
Unsupervised preprocessing for Tactile Data
Jun 23, 2016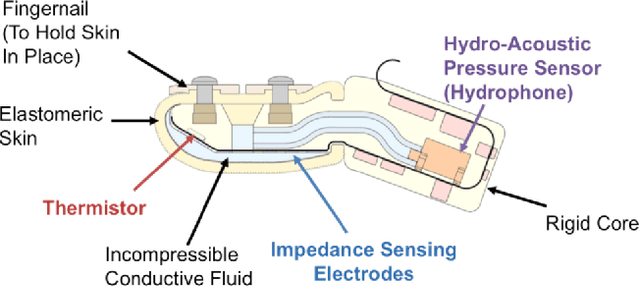

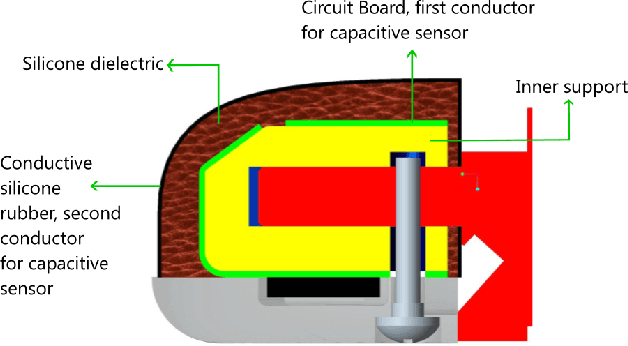
Tactile information is important for gripping, stable grasp, and in-hand manipulation, yet the complexity of tactile data prevents widespread use of such sensors. We make use of an unsupervised learning algorithm that transforms the complex tactile data into a compact, latent representation without the need to record ground truth reference data. These compact representations can either be used directly in a reinforcement learning based controller or can be used to calibrate the tactile sensor to physical quantities with only a few datapoints. We show the quality of our latent representation by predicting important features and with a simple control task.
ML-based tactile sensor calibration: A universal approach
Jun 21, 2016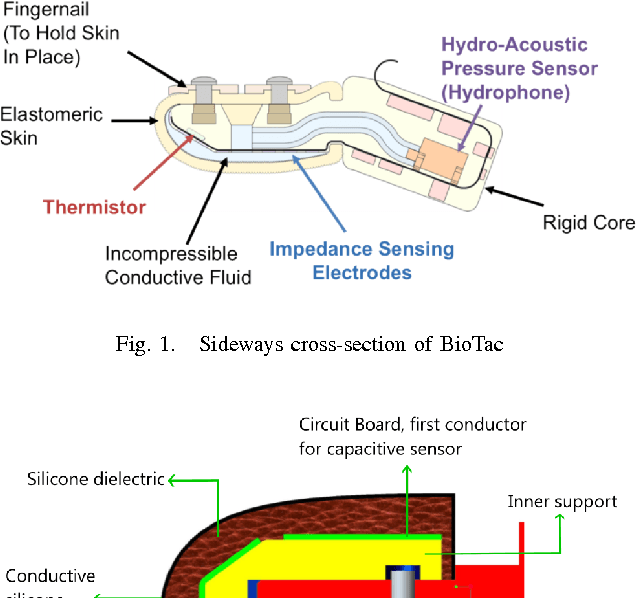
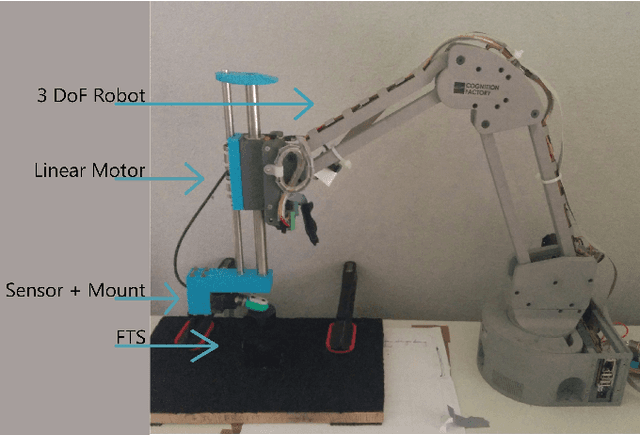

We study the responses of two tactile sensors, the fingertip sensor from the iCub and the BioTac under different external stimuli. The question of interest is to which degree both sensors i) allow the estimation of force exerted on the sensor and ii) enable the recognition of differing degrees of curvature. Making use of a force controlled linear motor affecting the tactile sensors we acquire several high-quality data sets allowing the study of both sensors under exactly the same conditions. We also examined the structure of the representation of tactile stimuli in the recorded tactile sensor data using t-SNE embeddings. The experiments show that both the iCub and the BioTac excel in different settings.
Variational Inference for On-line Anomaly Detection in High-Dimensional Time Series
Jun 14, 2016

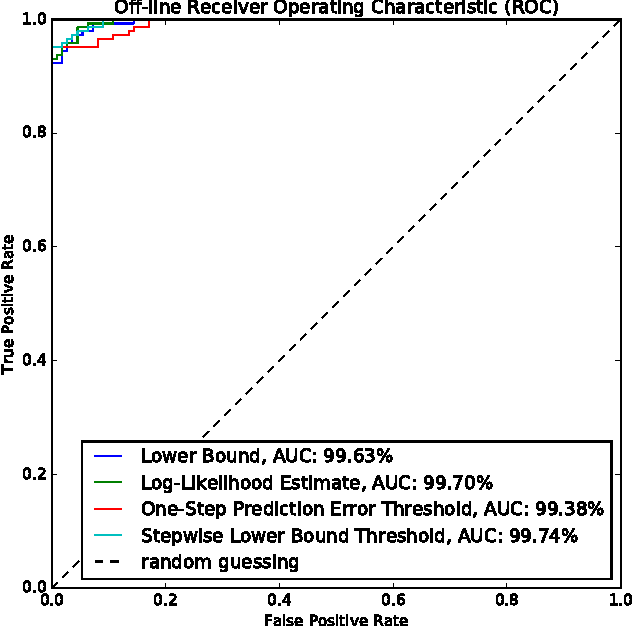
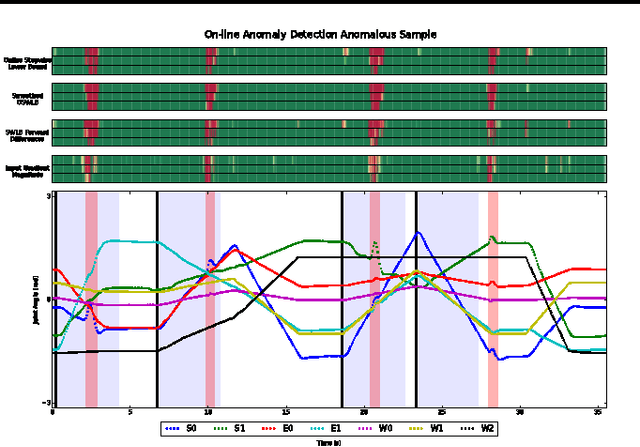
Approximate variational inference has shown to be a powerful tool for modeling unknown complex probability distributions. Recent advances in the field allow us to learn probabilistic models of sequences that actively exploit spatial and temporal structure. We apply a Stochastic Recurrent Network (STORN) to learn robot time series data. Our evaluation demonstrates that we can robustly detect anomalies both off- and on-line.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
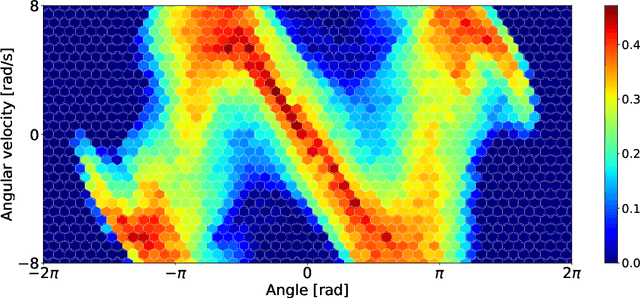
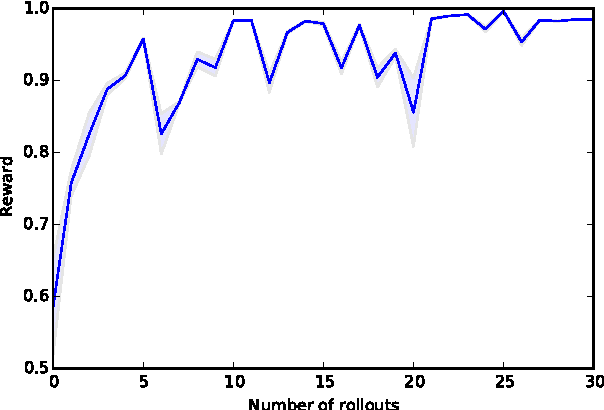
Efficient Empowerment
Sep 28, 2015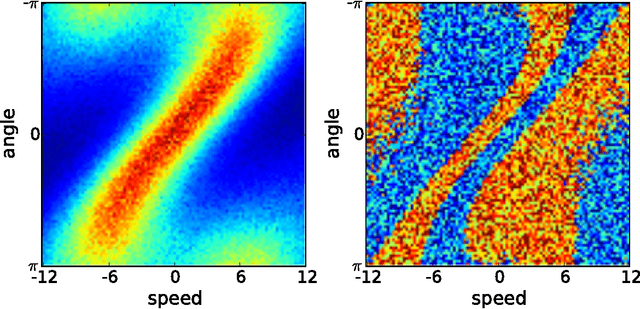
Empowerment quantifies the influence an agent has on its environment. This is formally achieved by the maximum of the expected KL-divergence between the distribution of the successor state conditioned on a specific action and a distribution where the actions are marginalised out. This is a natural candidate for an intrinsic reward signal in the context of reinforcement learning: the agent will place itself in a situation where its action have maximum stability and maximum influence on the future. The limiting factor so far has been the computational complexity of the method: the only way of calculation has so far been a brute force algorithm, reducing the applicability of the method to environments with a small set discrete states. In this work, we propose to use an efficient approximation for marginalising out the actions in the case of continuous environments. This allows fast evaluation of empowerment, paving the way towards challenging environments such as real world robotics. The method is presented on a pendulum swing up problem.