 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurest Quantum State Identification
Feb 20, 2025
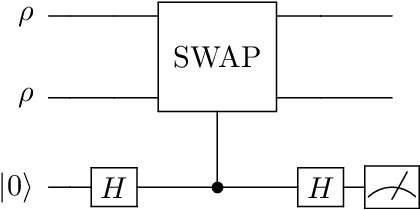
Precise identification of quantum states under noise constraints is essential for quantum information processing. In this study, we generalize the classical best arm identification problem to quantum domains, designing methods for identifying the purest one within $K$ unknown $n$-qubit quantum states using $N$ samples. %, with direct applications in quantum computation and quantum communication. We propose two distinct algorithms: (1) an algorithm employing incoherent measurements, achieving error $\exp\left(- \Omega\left(\frac{N H_1}{\log(K) 2^n }\right) \right)$, and (2) an algorithm utilizing coherent measurements, achieving error $\exp\left(- \Omega\left(\frac{N H_2}{\log(K) }\right) \right)$, highlighting the power of quantum memory. Furthermore, we establish a lower bound by proving that all strategies with fixed two-outcome incoherent POVM must suffer error probability exceeding $ \exp\left( - O\left(\frac{NH_1}{2^n}\right)\right)$. This framework provides concrete design principles for overcoming sampling bottlenecks in quantum technologies.
SoK: Benchmarking Poisoning Attacks and Defenses in Federated Learning
Feb 06, 2025



Federated learning (FL) enables collaborative model training while preserving data privacy, but its decentralized nature exposes it to client-side data poisoning attacks (DPAs) and model poisoning attacks (MPAs) that degrade global model performance. While numerous proposed defenses claim substantial effectiveness, their evaluation is typically done in isolation with limited attack strategies, raising concerns about their validity. Additionally, existing studies overlook the mutual effectiveness of defenses against both DPAs and MPAs, causing fragmentation in this field. This paper aims to provide a unified benchmark and analysis of defenses against DPAs and MPAs, clarifying the distinction between these two similar but slightly distinct domains. We present a systematic taxonomy of poisoning attacks and defense strategies, outlining their design, strengths, and limitations. Then, a unified comparative evaluation across FL algorithms and data heterogeneity is conducted to validate their individual and mutual effectiveness and derive key insights for design principles and future research. Along with the analysis, we frame our work to a unified benchmark, FLPoison, with high modularity and scalability to evaluate 15 representative poisoning attacks and 17 defense strategies, facilitating future research in this domain. Code is available at https://github.com/vio1etus/FLPoison.
Compliance while resisting: a shear-thickening fluid controller for physical human-robot interaction
Feb 03, 2025



Physical human-robot interaction (pHRI) is widely needed in many fields, such as industrial manipulation, home services, and medical rehabilitation, and puts higher demands on the safety of robots. Due to the uncertainty of the working environment, the pHRI may receive unexpected impact interference, which affects the safety and smoothness of the task execution. The commonly used linear admittance control (L-AC) can cope well with high-frequency small-amplitude noise, but for medium-frequency high-intensity impact, the effect is not as good. Inspired by the solid-liquid phase change nature of shear-thickening fluid, we propose a Shear-thickening Fluid Control (SFC) that can achieve both an easy human-robot collaboration and resistance to impact interference. The SFC's stability, passivity, and phase trajectory are analyzed in detail, the frequency and time domain properties are quantified, and parameter constraints in discrete control and coupled stability conditions are provided. We conducted simulations to compare the frequency and time domain characteristics of L-AC, nonlinear admittance controller (N-AC), and SFC, and validated their dynamic properties. In real-world experiments, we compared the performance of L-AC, N-AC, and SFC in both fixed and mobile manipulators. L-AC exhibits weak resistance to impact. N-AC can resist moderate impacts but not high-intensity ones, and may exhibit self-excited oscillations. In contrast, SFC demonstrated superior impact resistance and maintained stable collaboration, enhancing comfort in cooperative water delivery tasks. Additionally, a case study was conducted in a factory setting, further affirming the SFC's capability in facilitating human-robot collaborative manipulation and underscoring its potential in industrial applications.
Trustworthy Transfer Learning: A Survey
Dec 18, 2024



Transfer learning aims to transfer knowledge or information from a source domain to a relevant target domain. In this paper, we understand transfer learning from the perspectives of knowledge transferability and trustworthiness. This involves two research questions: How is knowledge transferability quantitatively measured and enhanced across domains? Can we trust the transferred knowledge in the transfer learning process? To answer these questions, this paper provides a comprehensive review of trustworthy transfer learning from various aspects, including problem definitions, theoretical analysis, empirical algorithms, and real-world applications. Specifically, we summarize recent theories and algorithms for understanding knowledge transferability under (within-domain) IID and non-IID assumptions. In addition to knowledge transferability, we review the impact of trustworthiness on transfer learning, e.g., whether the transferred knowledge is adversarially robust or algorithmically fair, how to transfer the knowledge under privacy-preserving constraints, etc. Beyond discussing the current advancements, we highlight the open questions and future directions for understanding transfer learning in a reliable and trustworthy manner.
Low Time Complexity Near-Field Channel and Position Estimations
Dec 18, 2024With the application of high-frequency communication and extremely large MIMO (XL-MIMO), the near-field effect has become increasingly apparent. The near-field channel estimation and position estimation problems both rely on the Angle of Arrival (AoA) and the Curvature of Arrival (CoA) estimation. However, in the near-field channel model, the coupling of AoA and CoA information poses a challenge to the estimation of the near-field channel. This paper proposes a Joint Autocorrelation and Cross-correlation (JAC) scheme to decouple AoA and CoA estimation. Based on the JAC scheme, we propose two specific near-field estimation algorithms, namely Inverse Sinc Function (JAC-ISF) and Gradient Descent (JAC-GD) algorithms. Finally, we analyzed the time complexity of the JAC scheme and the cramer-rao lower bound (CRLB) for near-field position estimation. The simulation experiment results show that the algorithm designed based on JAC scheme can solve the problem of coupled CoA and AoA information in near-field estimation, thereby improving the algorithm performance. The JAC-GD algorithm shows significant performance in channel estimation and position estimation at different SNRs, snapshot points, and communication distances compared to other algorithms. This indicates that the JAC-GD algorithm can achieve more accurate channel and position estimation results while saving time overhead.
A Lightweight U-like Network Utilizing Neural Memory Ordinary Differential Equations for Slimming the Decoder
Dec 09, 2024



In recent years, advanced U-like networks have demonstrated remarkable performance in medical image segmentation tasks. However, their drawbacks, including excessive parameters, high computational complexity, and slow inference speed, pose challenges for practical implementation in scenarios with limited computational resources. Existing lightweight U-like networks have alleviated some of these problems, but they often have pre-designed structures and consist of inseparable modules, limiting their application scenarios. In this paper, we propose three plug-and-play decoders by employing different discretization methods of the neural memory Ordinary Differential Equations (nmODEs). These decoders integrate features at various levels of abstraction by processing information from skip connections and performing numerical operations on upward path. Through experiments on the PH2, ISIC2017, and ISIC2018 datasets, we embed these decoders into different U-like networks, demonstrating their effectiveness in significantly reducing the number of parameters and FLOPs while maintaining performance. In summary, the proposed discretized nmODEs decoders are capable of reducing the number of parameters by about 20% ~ 50% and FLOPs by up to 74%, while possessing the potential to adapt to all U-like networks. Our code is available at https://github.com/nayutayuki/Lightweight-nmODE-Decoders-For-U-like-networks.
Learning to Hash for Recommendation: A Survey
Dec 05, 2024



With the explosive growth of users and items, Recommender Systems (RS) are facing unprecedented challenges on both retrieval efficiency and storage cost. Fortunately, Learning to Hash (L2H) techniques have been shown as a promising solution to address the two dilemmas, whose core idea is encoding high-dimensional data into compact hash codes. To this end, L2H for RS (HashRec for short) has recently received widespread attention to support large-scale recommendations. In this survey, we present a comprehensive review of current HashRec algorithms. Specifically, we first introduce the commonly used two-tower models in the recall stage and identify two search strategies frequently employed in L2H. Then, we categorize prior works into two-tier taxonomy based on: (i) the type of loss function and (ii) the optimization strategy. We also introduce some commonly used evaluation metrics to measure the performance of HashRec algorithms. Finally, we shed light on the limitations of the current research and outline the future research directions. Furthermore, the summary of HashRec methods reviewed in this survey can be found at \href{https://github.com/Luo-Fangyuan/HashRec}{https://github.com/Luo-Fangyuan/HashRec}.
MOVE: Multi-skill Omnidirectional Legged Locomotion with Limited View in 3D Environments
Dec 04, 2024



Legged robots possess inherent advantages in traversing complex 3D terrains. However, previous work on low-cost quadruped robots with egocentric vision systems has been limited by a narrow front-facing view and exteroceptive noise, restricting omnidirectional mobility in such environments. While building a voxel map through a hierarchical structure can refine exteroception processing, it introduces significant computational overhead, noise, and delays. In this paper, we present MOVE, a one-stage end-to-end learning framework capable of multi-skill omnidirectional legged locomotion with limited view in 3D environments, just like what a real animal can do. When movement aligns with the robot's line of sight, exteroceptive perception enhances locomotion, enabling extreme climbing and leaping. When vision is obstructed or the direction of movement lies outside the robot's field of view, the robot relies on proprioception for tasks like crawling and climbing stairs. We integrate all these skills into a single neural network by introducing a pseudo-siamese network structure combining supervised and contrastive learning which helps the robot infer its surroundings beyond its field of view. Experiments in both simulations and real-world scenarios demonstrate the robustness of our method, broadening the operational environments for robotics with egocentric vision.
Low-Complexity Minimum BER Precoder Design for ISAC Systems: A Delay-Doppler Perspective
Oct 21, 2024



Orthogonal time frequency space (OTFS) modulation is anticipated to be a promising candidate for supporting integrated sensing and communications (ISAC) systems, which is considered as a pivotal technique for realizing next generation wireless networks. In this paper, we develop a minimum bit error rate (BER) precoder design for an OTFS-based ISAC system. In particular, the BER minimization problem takes into account the maximum available transmission power budget and the required sensing performance. Different from prior studies that considered ISAC in the time-frequency (TF) domain, we devise the precoder from the perspective of the delay-Doppler (DD) domain by exploiting the equivalent DD domain channel due to the fact that the DD domain channel generally tends to be sparse and quasi-static, which can facilitate a low-overhead ISAC system design. To address the non-convex optimization design problem, we resort to optimizing the lower bound of the derived average BER by adopting Jensen's inequality. Subsequently, the formulated problem is decoupled into two independent sub-problems via singular value decomposition (SVD) methodology. We then theoretically analyze the feasibility conditions of the proposed problem and present a low-complexity iterative solution via leveraging the Lagrangian duality approach. Simulation results verify the effectiveness of our proposed precoder compared to the benchmark schemes and reveal the interplay between sensing and communication for dual-functional precoder design, indicating a trade-off where transmission efficiency is sacrificed for increasing transmission reliability and sensing accuracy.
PIE: Parkour with Implicit-Explicit Learning Framework for Legged Robots
Aug 27, 2024



Parkour presents a highly challenging task for legged robots, requiring them to traverse various terrains with agile and smooth locomotion. This necessitates comprehensive understanding of both the robot's own state and the surrounding terrain, despite the inherent unreliability of robot perception and actuation. Current state-of-the-art methods either rely on complex pre-trained high-level terrain reconstruction modules or limit the maximum potential of robot parkour to avoid failure due to inaccurate perception. In this paper, we propose a one-stage end-to-end learning-based parkour framework: Parkour with Implicit-Explicit learning framework for legged robots (PIE) that leverages dual-level implicit-explicit estimation. With this mechanism, even a low-cost quadruped robot equipped with an unreliable egocentric depth camera can achieve exceptional performance on challenging parkour terrains using a relatively simple training process and reward function. While the training process is conducted entirely in simulation, our real-world validation demonstrates successful zero-shot deployment of our framework, showcasing superior parkour performance on harsh terrains.