 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIlluminating Diverse Neural Cellular Automata for Level Generation
Sep 12, 2021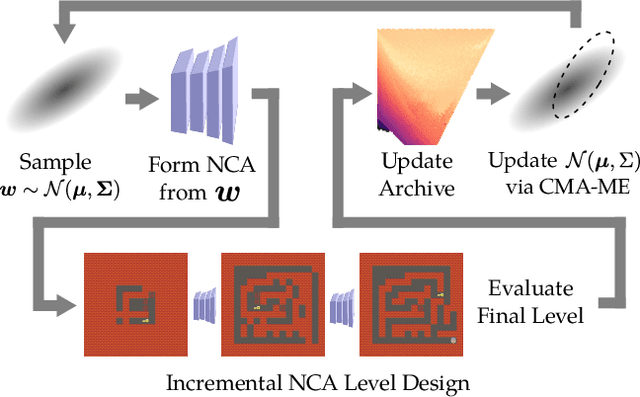
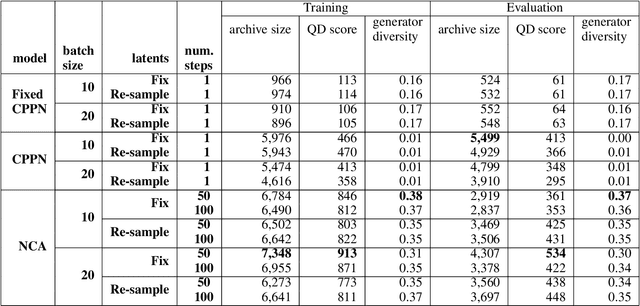
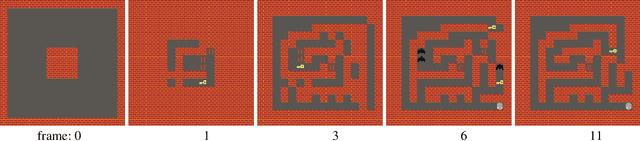
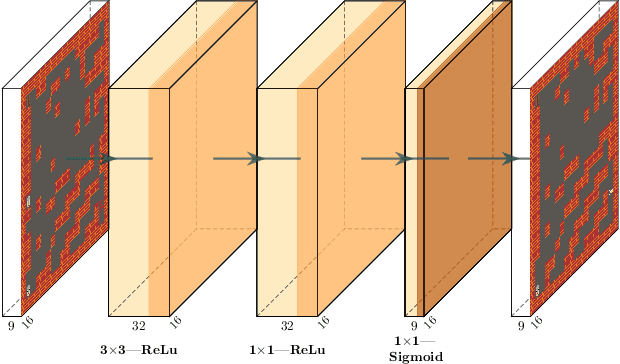
We present a method of generating a collection of neural cellular automata (NCA) to design video game levels. While NCAs have so far only been trained via supervised learning, we present a quality diversity (QD) approach to generating a collection of NCA level generators. By framing the problem as a QD problem, our approach can train diverse level generators, whose output levels vary based on aesthetic or functional criteria. To efficiently generate NCAs, we train generators via Covariance Matrix Adaptation MAP-Elites (CMA-ME), a quality diversity algorithm which specializes in continuous search spaces. We apply our new method to generate level generators for several 2D tile-based games: a maze game, Sokoban, and Zelda. Our results show that CMA-ME can generate small NCAs that are diverse yet capable, often satisfying complex solvability criteria for deterministic agents. We compare against a Compositional Pattern-Producing Network (CPPN) baseline trained to produce diverse collections of generators and show that the NCA representation yields a better exploration of level-space.
Self-Referential Quality Diversity Through Differential Map-Elites
Jul 11, 2021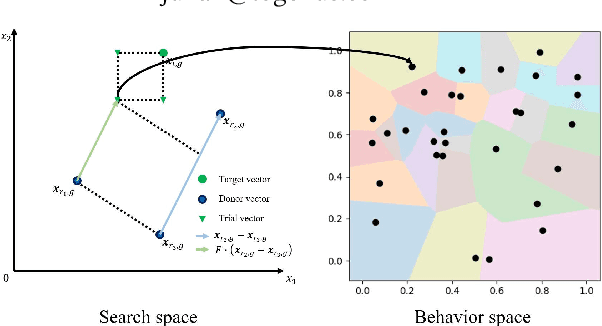
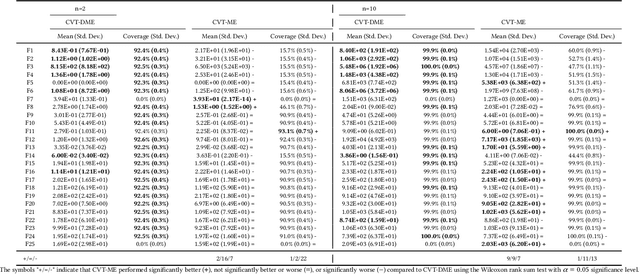
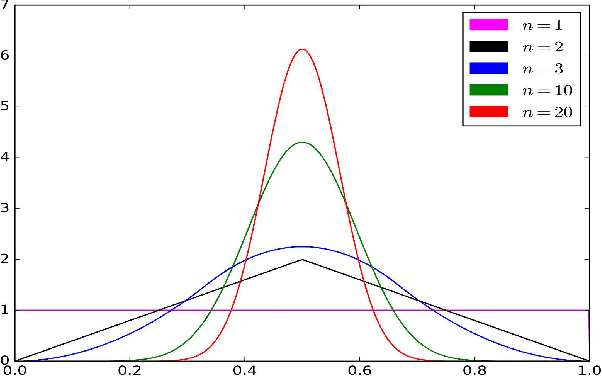
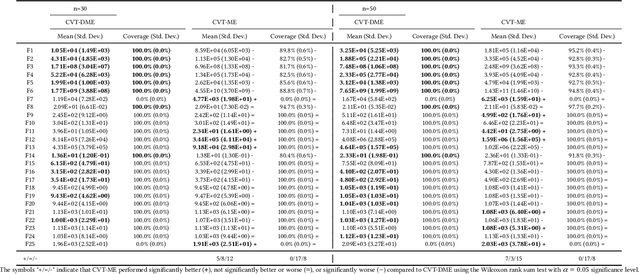
Differential MAP-Elites is a novel algorithm that combines the illumination capacity of CVT-MAP-Elites with the continuous-space optimization capacity of Differential Evolution. The algorithm is motivated by observations that illumination algorithms, and quality-diversity algorithms in general, offer qualitatively new capabilities and applications for evolutionary computation yet are in their original versions relatively unsophisticated optimizers. The basic Differential MAP-Elites algorithm, introduced for the first time here, is relatively simple in that it simply combines the operators from Differential Evolution with the map structure of CVT-MAP-Elites. Experiments based on 25 numerical optimization problems suggest that Differential MAP-Elites clearly outperforms CVT-MAP-Elites, finding better-quality and more diverse solutions.
An Evolutionary Algorithm for Task Scheduling in Crowdsourced Software Development
Jul 05, 2021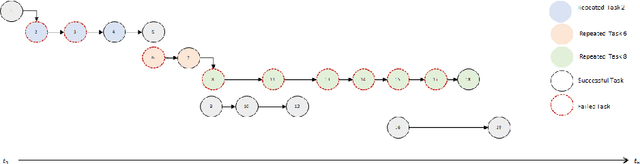

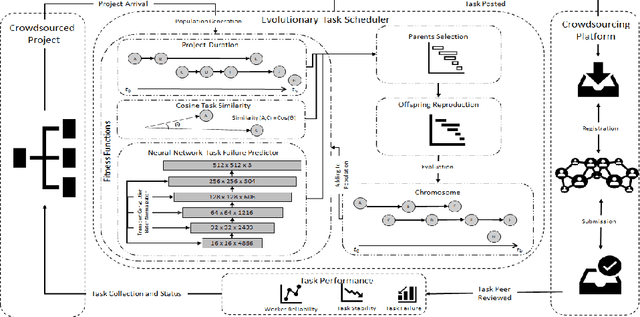
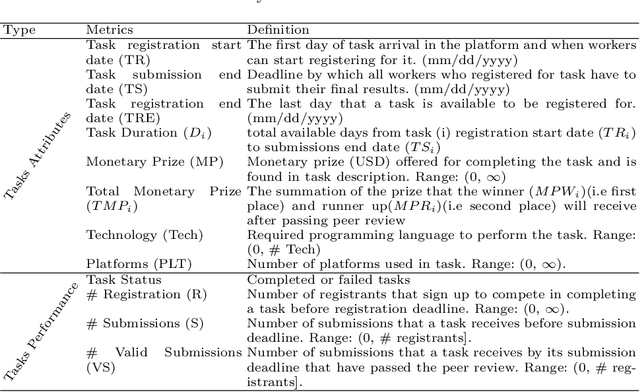
The complexity of software tasks and the uncertainty of crowd developer behaviors make it challenging to plan crowdsourced software development (CSD) projects. In a competitive crowdsourcing marketplace, competition for shared worker resources from multiple simultaneously open tasks adds another layer of uncertainty to the potential outcomes of software crowdsourcing. These factors lead to the need for supporting CSD managers with automated scheduling to improve the visibility and predictability of crowdsourcing processes and outcomes. To that end, this paper proposes an evolutionary algorithm-based task scheduling method for crowdsourced software development. The proposed evolutionary scheduling method uses a multiobjective genetic algorithm to recommend an optimal task start date. The method uses three fitness functions, based on project duration, task similarity, and task failure prediction, respectively. The task failure fitness function uses a neural network to predict the probability of task failure with respect to a specific task start date. The proposed method then recommends the best tasks start dates for the project as a whole and each individual task so as to achieve the lowest project failure ratio. Experimental results on 4 projects demonstrate that the proposed method has the potential to reduce project duration by a factor of 33-78%.
Physics-informed attention-based neural network for solving non-linear partial differential equations
May 17, 2021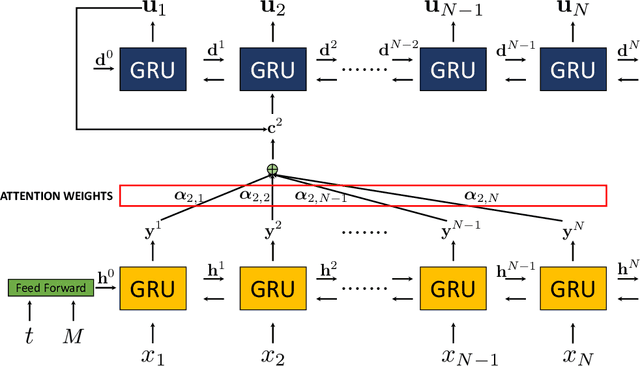
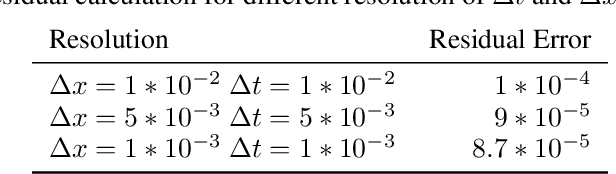
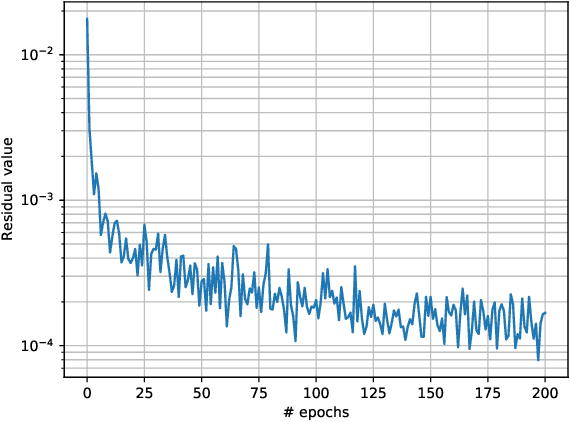
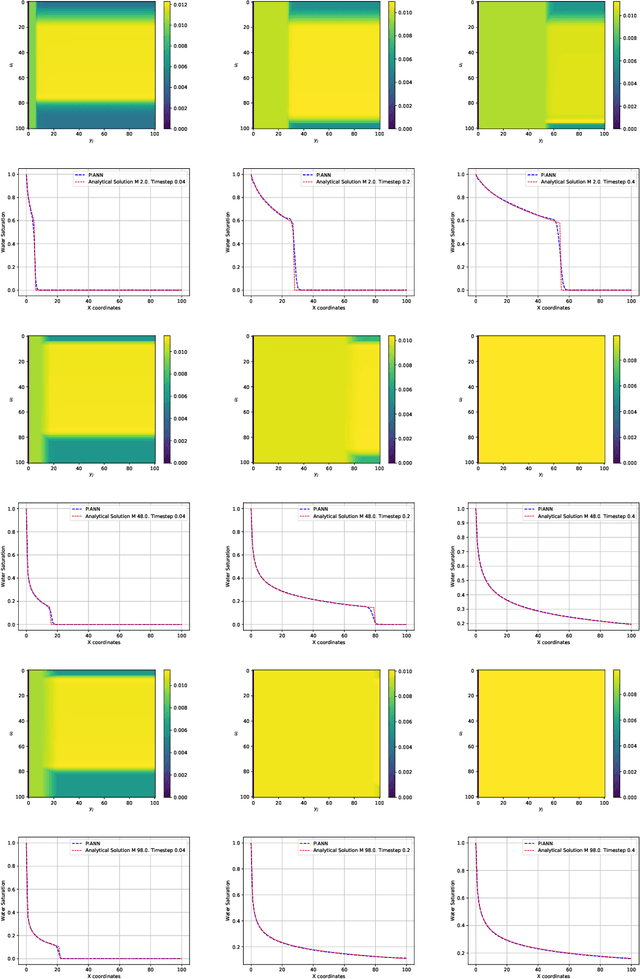
Physics-Informed Neural Networks (PINNs) have enabled significant improvements in modelling physical processes described by partial differential equations (PDEs). PINNs are based on simple architectures, and learn the behavior of complex physical systems by optimizing the network parameters to minimize the residual of the underlying PDE. Current network architectures share some of the limitations of classical numerical discretization schemes when applied to non-linear differential equations in continuum mechanics. A paradigmatic example is the solution of hyperbolic conservation laws that develop highly localized nonlinear shock waves. Learning solutions of PDEs with dominant hyperbolic character is a challenge for current PINN approaches, which rely, like most grid-based numerical schemes, on adding artificial dissipation. Here, we address the fundamental question of which network architectures are best suited to learn the complex behavior of non-linear PDEs. We focus on network architecture rather than on residual regularization. Our new methodology, called Physics-Informed Attention-based Neural Networks, (PIANNs), is a combination of recurrent neural networks and attention mechanisms. The attention mechanism adapts the behavior of the deep neural network to the non-linear features of the solution, and break the current limitations of PINNs. We find that PIANNs effectively capture the shock front in a hyperbolic model problem, and are capable of providing high-quality solutions inside and beyond the training set.
Learning Controllable Content Generators
May 06, 2021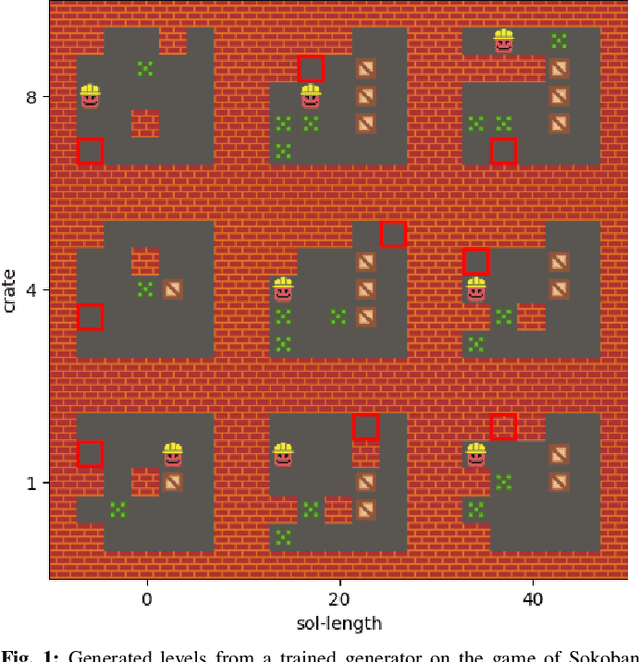
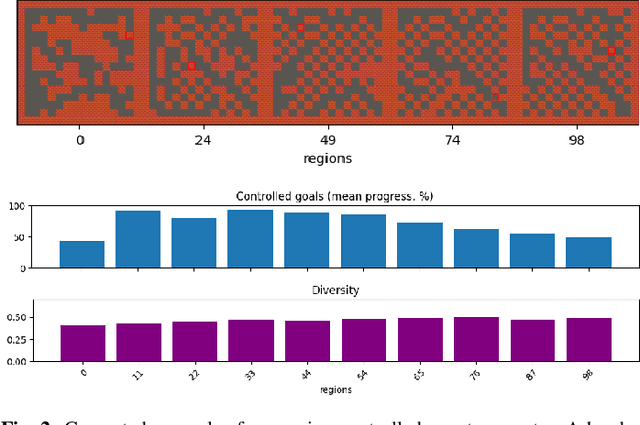
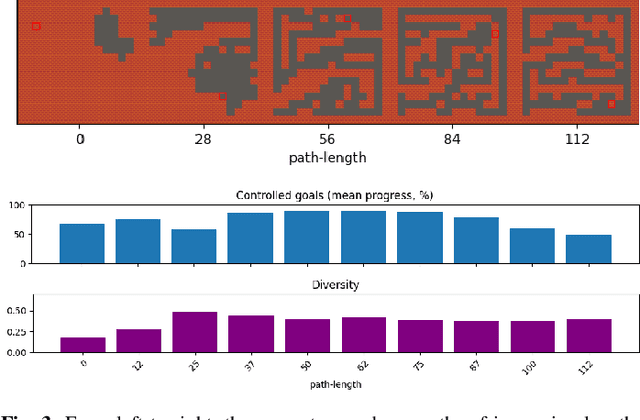
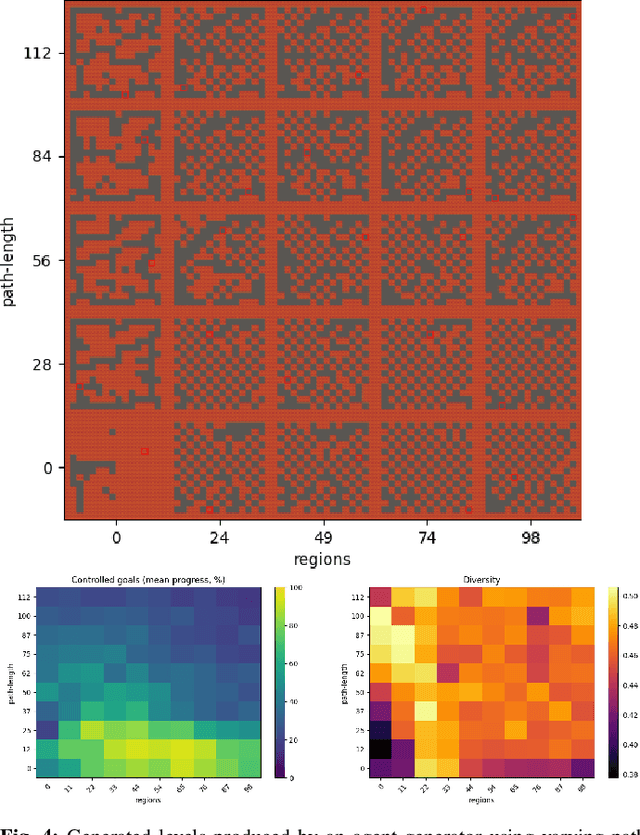
It has recently been shown that reinforcement learning can be used to train generators capable of producing high-quality game levels, with quality defined in terms of some user-specified heuristic. To ensure that these generators' output is sufficiently diverse (that is, not amounting to the reproduction of a single optimal level configuration), the generation process is constrained such that the initial seed results in some variance in the generator's output. However, this results in a loss of control over the generated content for the human user. We propose to train generators capable of producing controllably diverse output, by making them "goal-aware." To this end, we add conditional inputs representing how close a generator is to some heuristic, and also modify the reward mechanism to incorporate that value. Testing on multiple domains, we show that the resulting level generators are capable of exploring the space of possible levels in a targeted, controllable manner, producing levels of comparable quality as their goal-unaware counterparts, that are diverse along designer-specified dimensions.
The AI Settlement Generation Challenge in Minecraft: First Year Report
Mar 27, 2021

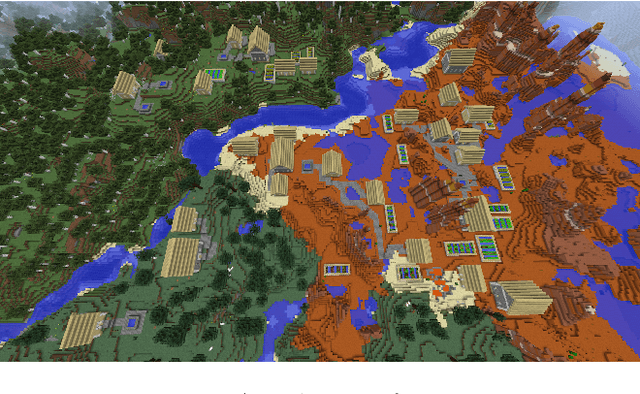

This article outlines what we learned from the first year of the AI Settlement Generation Competition in Minecraft, a competition about producing AI programs that can generate interesting settlements in Minecraft for an unseen map. This challenge seeks to focus research into adaptive and holistic procedural content generation. Generating Minecraft towns and villages given existing maps is a suitable task for this, as it requires the generated content to be adaptive, functional, evocative and aesthetic at the same time. Here, we present the results from the first iteration of the competition. We discuss the evaluation methodology, present the different technical approaches by the competitors, and outline the open problems.
* 14 pages, 9 figures, published in KI-K\"unstliche Intelligenz
Transforming Exploratory Creativity with DeLeNoX
Mar 22, 2021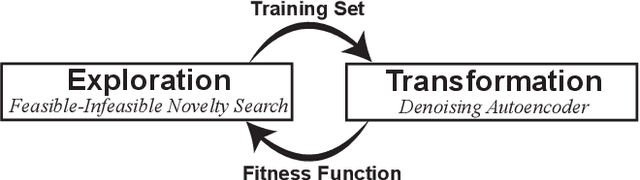
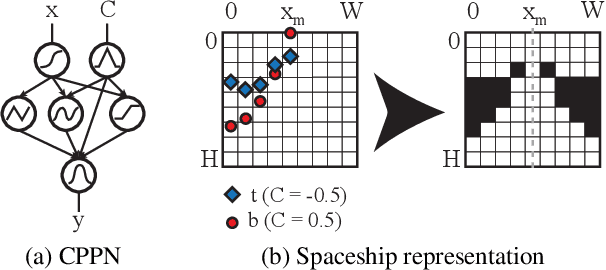
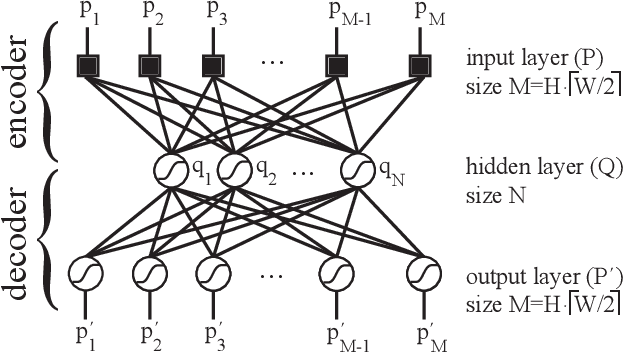
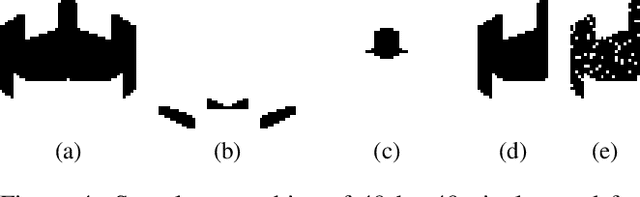
We introduce DeLeNoX (Deep Learning Novelty Explorer), a system that autonomously creates artifacts in constrained spaces according to its own evolving interestingness criterion. DeLeNoX proceeds in alternating phases of exploration and transformation. In the exploration phases, a version of novelty search augmented with constraint handling searches for maximally diverse artifacts using a given distance function. In the transformation phases, a deep learning autoencoder learns to compress the variation between the found artifacts into a lower-dimensional space. The newly trained encoder is then used as the basis for a new distance function, transforming the criteria for the next exploration phase. In the current paper, we apply DeLeNoX to the creation of spaceships suitable for use in two-dimensional arcade-style computer games, a representative problem in procedural content generation in games. We also situate DeLeNoX in relation to the distinction between exploratory and transformational creativity, and in relation to Schmidhuber's theory of creativity through the drive for compression progress.
* 8 pages
Game Mechanic Alignment Theory and Discovery
Feb 20, 2021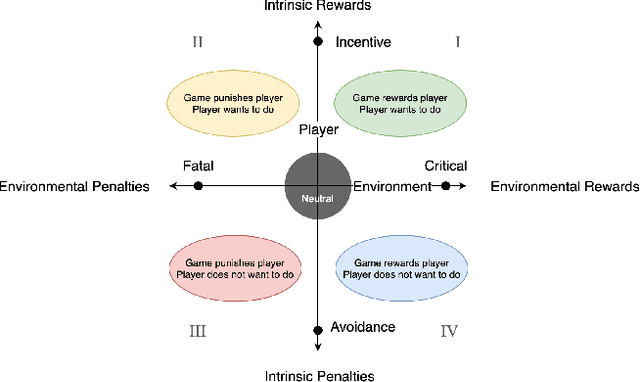
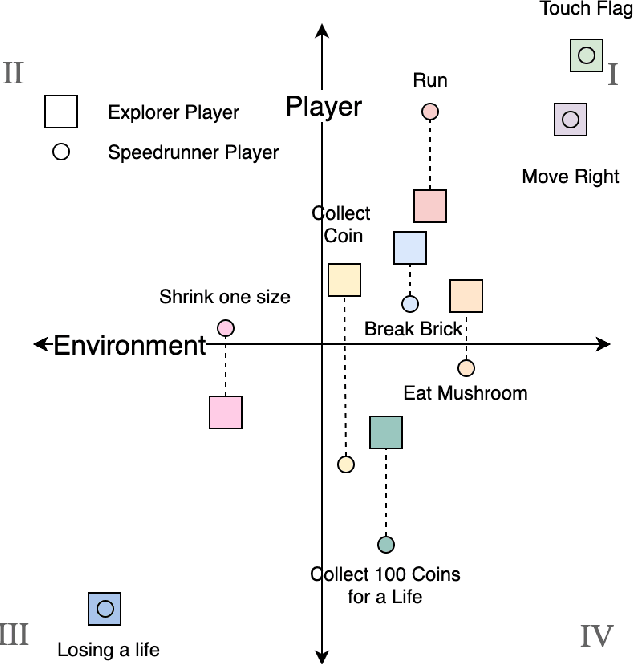
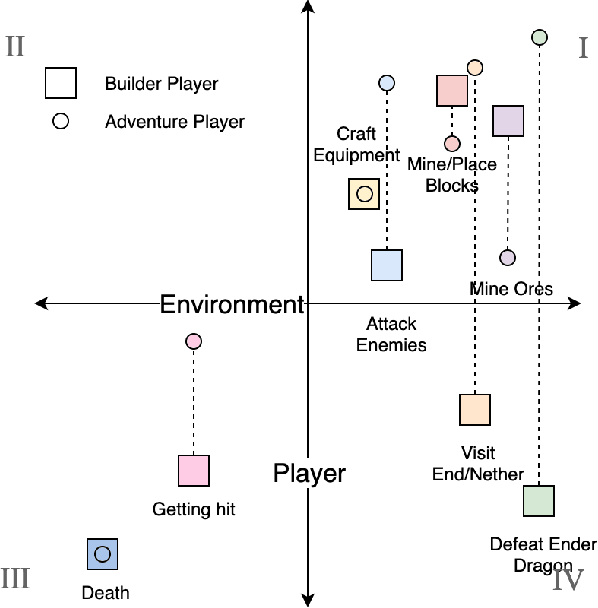
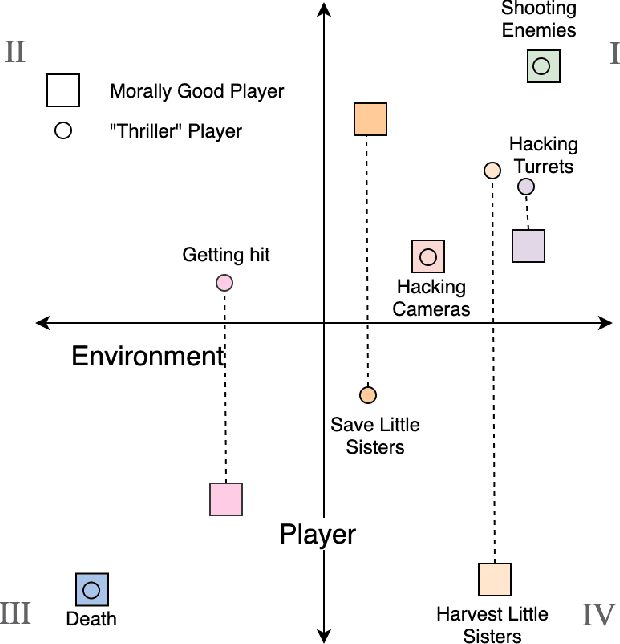
We present a new concept called Game Mechanic Alignment theory as a way to organize game mechanics through the lens of environmental rewards and intrinsic player motivations. By disentangling player and environmental influences, mechanics may be better identified for use in an automated tutorial generation system, which could tailor tutorials for a particular playstyle or player. Within, we apply this theory to several well-known games to demonstrate how designers can benefit from it, we describe a methodology for how to estimate mechanic alignment, and we apply this methodology on multiple games in the GVGAI framework. We discuss how effectively this estimation captures intrinsic/extrinsic rewards and how our theory could be used as an alternative to critical mechanic discovery methods for tutorial generation.
Model-free Neural Counterfactual Regret Minimization with Bootstrap Learning
Dec 03, 2020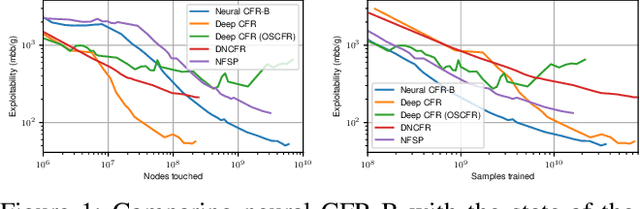
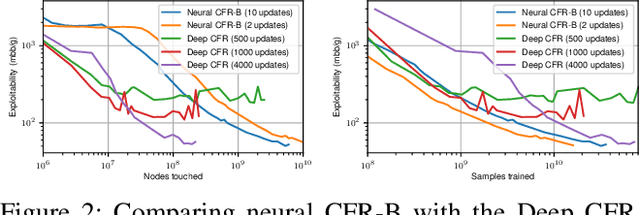
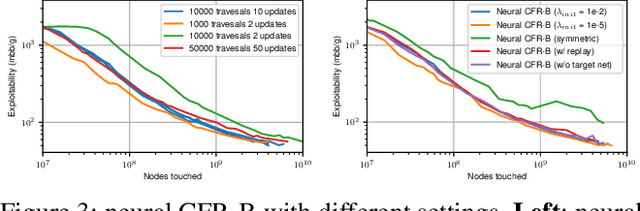
Counterfactual Regret Minimization (CFR) has achieved many fascinating results in solving large scale Imperfect Information Games (IIGs). Neural CFR is one of the promising techniques that can effectively reduce the computation and memory consumption of CFR by generalizing decision information between similar states. However, current neural CFR algorithms have to approximate the cumulative variables in iterations with neural networks, which usually results in large estimation variance given the huge complexity of IIGs. Moreover, model-based sampling and inefficient training make current neural CFR algorithms still computationally expensive. In this paper, a new model-free neural CFR algorithm with bootstrap learning is proposed, in which, a Recursive Substitute Value (RSV) network is trained to replace the cumulative variables in CFR. The RSV is defined recursively and can be estimated independently in every iteration using bootstrapping. Then there is no need to track or approximate the cumulative variables any more. Based on the RSV, the new neural CFR algorithm is model-free and has higher training efficiency. Experimental results show that the new algorithm can match the state-of-the-art neural CFR algorithms and with less training cost.
Robust Reinforcement Learning for General Video Game Playing
Nov 11, 2020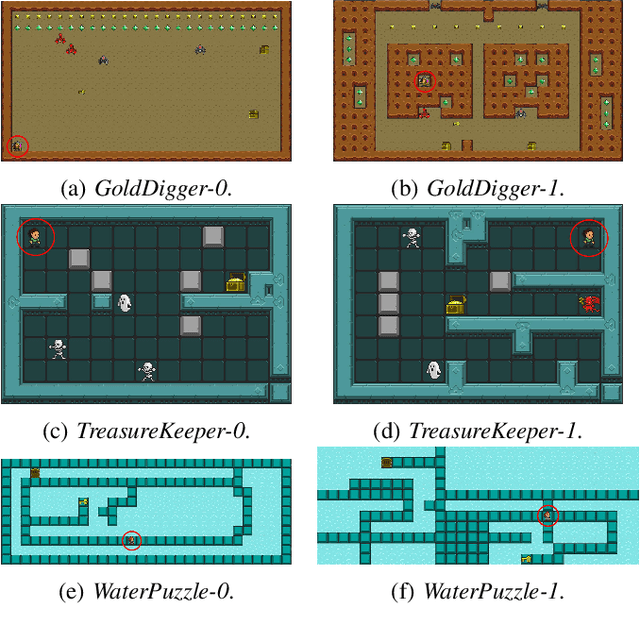
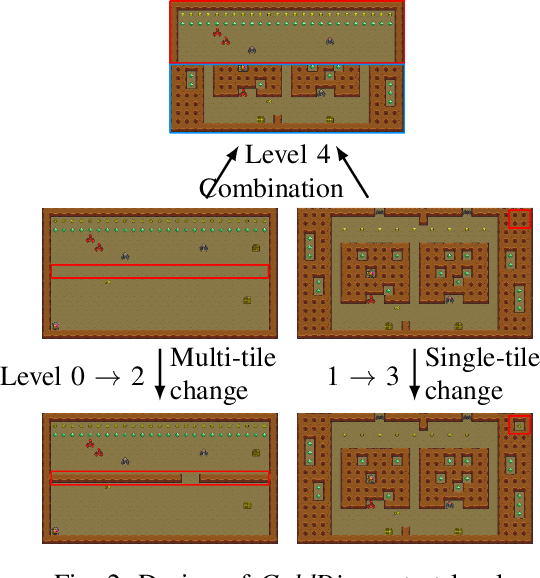
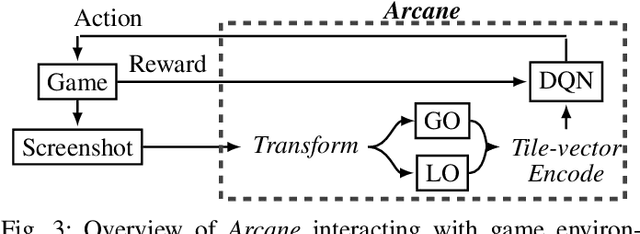
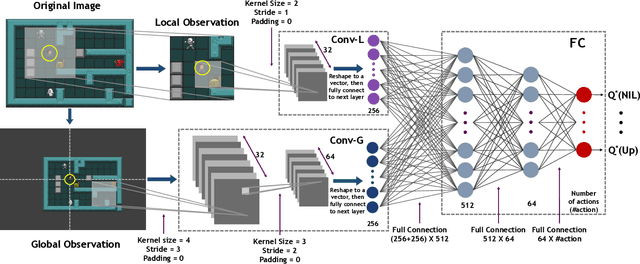
Reinforcement learning has successfully learned to play challenging board and video games. However, its generalization ability remains under-explored. The General Video Game AI Learning Competition aims at designing agents that are capable of learning to play different games levels that were unseen during training. This paper presents the games, entries and results of the 2020 General Video Game AI Learning Competition, held at the Sixteenth International Conference on Parallel Problem Solving from Nature and the 2020 IEEE Conference on Games. Three new games with sparse, periodic and dense rewards, respectively, were designed for this competition and the test levels were generated by adding minor perturbations to training levels or combining training levels. In this paper, we also design a reinforcement learning agent, called Arcane, for general video game playing. We assume that it is more likely to observe similar local information in different levels rather than global information. Therefore, instead of directly inputting a single, raw pixel-based screenshot of current game screen, Arcane takes the encoded, transformed global and local observations of the game screen as two simultaneous inputs, aiming at learning local information for playing new levels. Two versions of Arcane, using a stochastic or deterministic policy for decision-making during test, both show robust performance on the game set of the 2020 General Video Game AI Learning Competition.