 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKINNEWS and KIRNEWS: Benchmarking Cross-Lingual Text Classification for Kinyarwanda and Kirundi
Oct 23, 2020
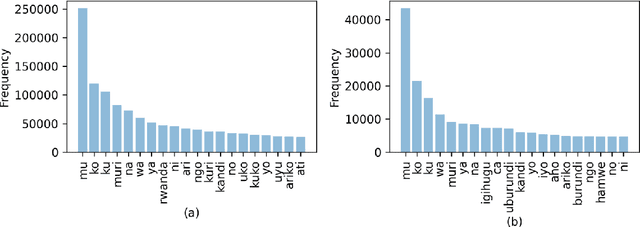

Recent progress in text classification has been focused on high-resource languages such as English and Chinese. For low-resource languages, amongst them most African languages, the lack of well-annotated data and effective preprocessing, is hindering the progress and the transfer of successful methods. In this paper, we introduce two news datasets (KINNEWS and KIRNEWS) for multi-class classification of news articles in Kinyarwanda and Kirundi, two low-resource African languages. The two languages are mutually intelligible, but while Kinyarwanda has been studied in Natural Language Processing (NLP) to some extent, this work constitutes the first study on Kirundi. Along with the datasets, we provide statistics, guidelines for preprocessing, and monolingual and cross-lingual baseline models. Our experiments show that training embeddings on the relatively higher-resourced Kinyarwanda yields successful cross-lingual transfer to Kirundi. In addition, the design of the created datasets allows for a wider use in NLP beyond text classification in future studies, such as representation learning, cross-lingual learning with more distant languages, or as base for new annotations for tasks such as parsing, POS tagging, and NER. The datasets, stopwords, and pre-trained embeddings are publicly available at https://github.com/Andrews2017/KINNEWS-and-KIRNEWS-Corpus .
Inference Strategies for Machine Translation with Conditional Masking
Oct 20, 2020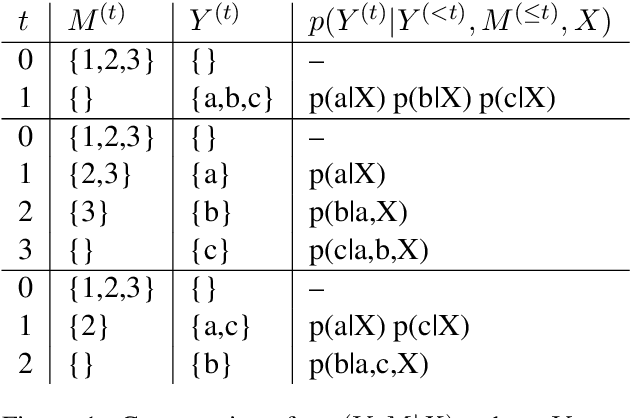
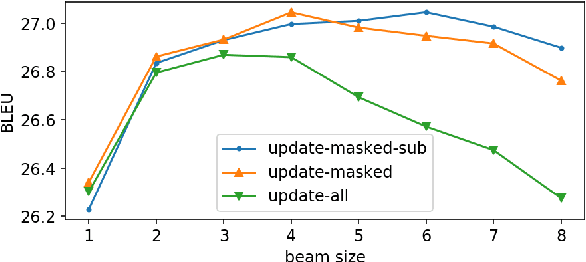
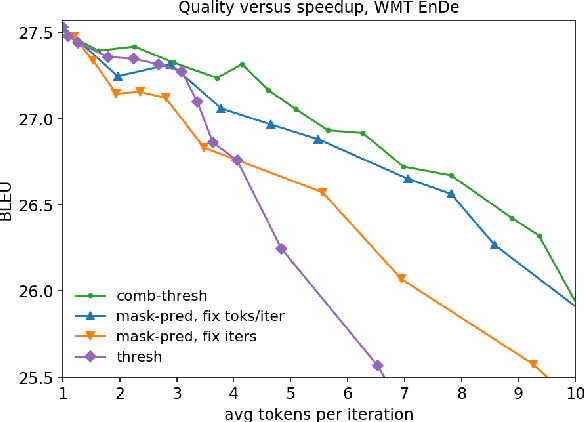
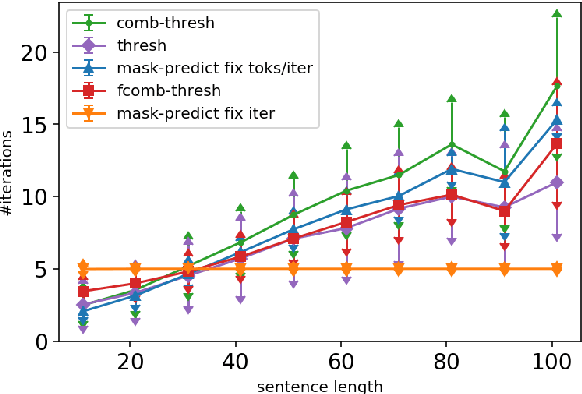
Conditional masked language model (CMLM) training has proven successful for non-autoregressive and semi-autoregressive sequence generation tasks, such as machine translation. Given a trained CMLM, however, it is not clear what the best inference strategy is. We formulate masked inference as a factorization of conditional probabilities of partial sequences, show that this does not harm performance, and investigate a number of simple heuristics motivated by this perspective. We identify a thresholding strategy that has advantages over the standard "mask-predict" algorithm, and provide analyses of its behavior on machine translation tasks.
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020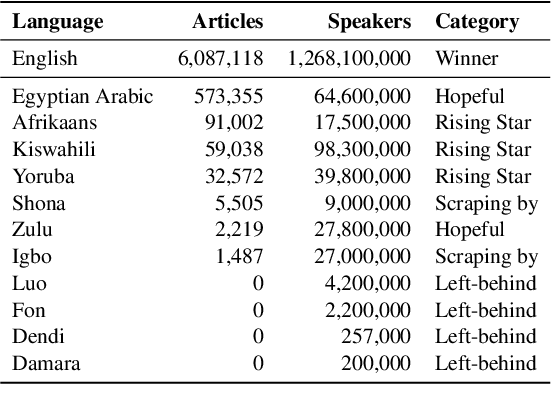
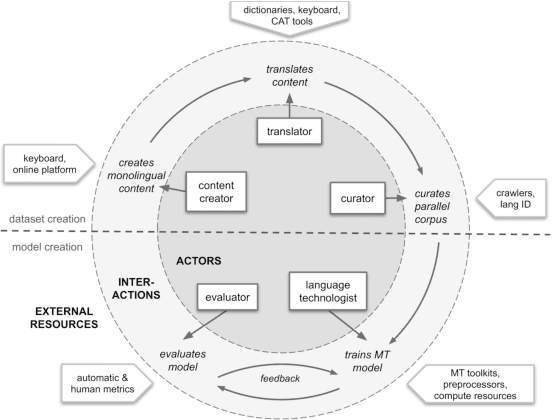
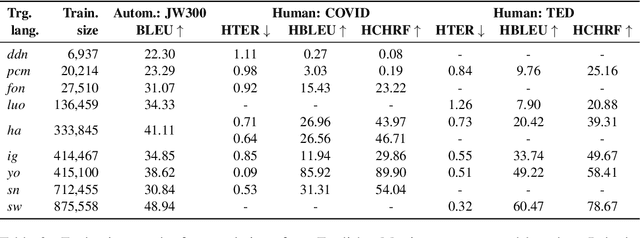
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
Correct Me If You Can: Learning from Error Corrections and Markings
Apr 23, 2020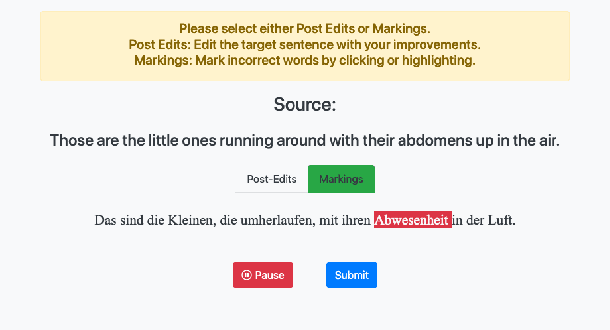


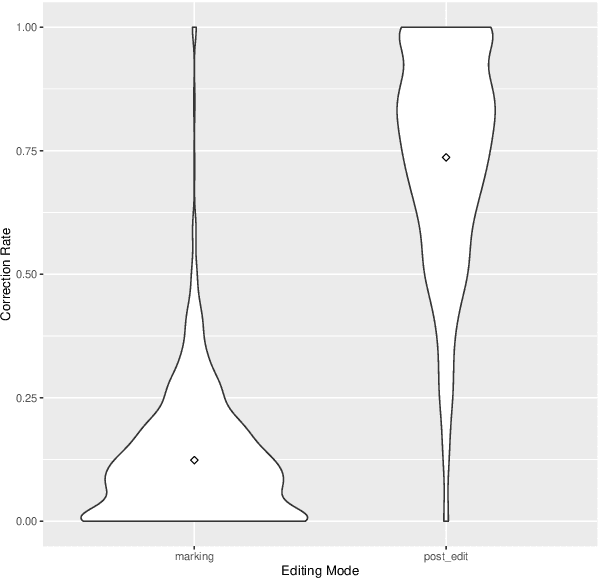
Sequence-to-sequence learning involves a trade-off between signal strength and annotation cost of training data. For example, machine translation data range from costly expert-generated translations that enable supervised learning, to weak quality-judgment feedback that facilitate reinforcement learning. We present the first user study on annotation cost and machine learnability for the less popular annotation mode of error markings. We show that error markings for translations of TED talks from English to German allow precise credit assignment while requiring significantly less human effort than correcting/post-editing, and that error-marked data can be used successfully to fine-tune neural machine translation models.
On Optimal Transformer Depth for Low-Resource Language Translation
Apr 14, 2020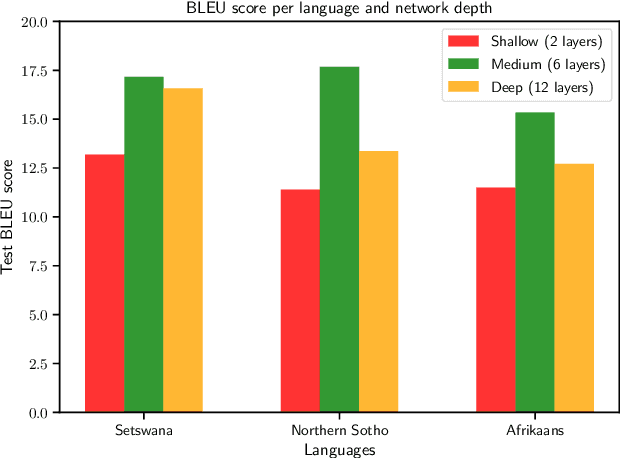



Transformers have shown great promise as an approach to Neural Machine Translation (NMT) for low-resource languages. However, at the same time, transformer models remain difficult to optimize and require careful tuning of hyper-parameters to be useful in this setting. Many NMT toolkits come with a set of default hyper-parameters, which researchers and practitioners often adopt for the sake of convenience and avoiding tuning. These configurations, however, have been optimized for large-scale machine translation data sets with several millions of parallel sentences for European languages like English and French. In this work, we find that the current trend in the field to use very large models is detrimental for low-resource languages, since it makes training more difficult and hurts overall performance, confirming previous observations. We see our work as complementary to the Masakhane project ("Masakhane" means "We Build Together" in isiZulu.) In this spirit, low-resource NMT systems are now being built by the community who needs them the most. However, many in the community still have very limited access to the type of computational resources required for building extremely large models promoted by industrial research. Therefore, by showing that transformer models perform well (and often best) at low-to-moderate depth, we hope to convince fellow researchers to devote less computational resources, as well as time, to exploring overly large models during the development of these systems.
Masakhane -- Machine Translation For Africa
Mar 13, 2020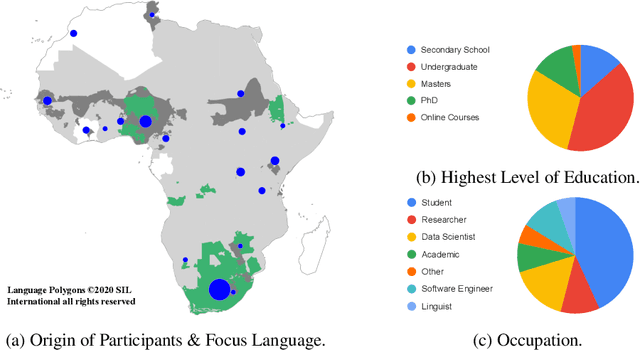
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.
Joey NMT: A Minimalist NMT Toolkit for Novices
Jul 29, 2019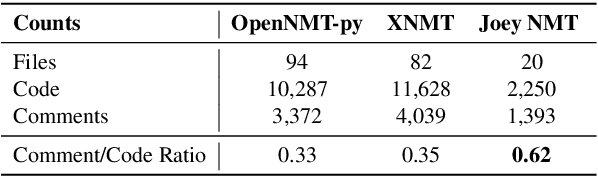
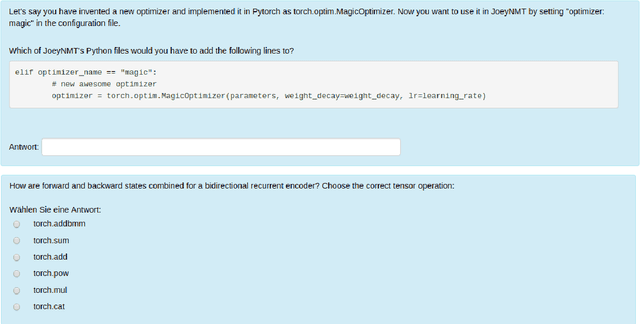
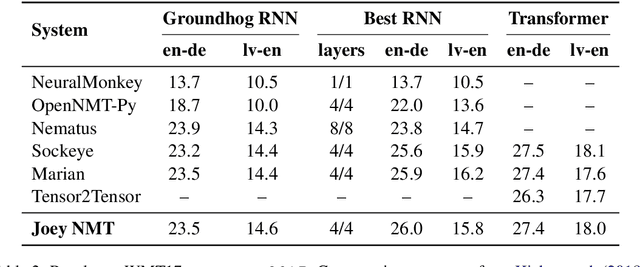
We present Joey NMT, a minimalist neural machine translation toolkit based on PyTorch that is specifically designed for novices. Joey NMT provides many popular NMT features in a small and simple code base, so that novices can easily and quickly learn to use it and adapt it to their needs. Despite its focus on simplicity, Joey NMT supports classic architectures (RNNs, transformers), fast beam search, weight tying, and more, and achieves performance comparable to more complex toolkits on standard benchmarks. We evaluate the accessibility of our toolkit in a user study where novices with general knowledge about Pytorch and NMT and experts work through a self-contained Joey NMT tutorial, showing that novices perform almost as well as experts in a subsequent code quiz. Joey NMT is available at https://github.com/joeynmt/joeynmt .
Self-Regulated Interactive Sequence-to-Sequence Learning
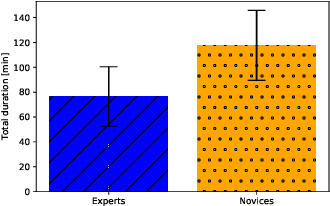
Jul 11, 2019

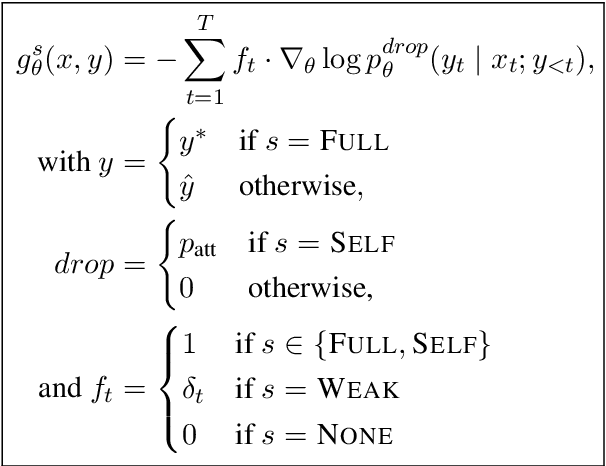
Not all types of supervision signals are created equal: Different types of feedback have different costs and effects on learning. We show how self-regulation strategies that decide when to ask for which kind of feedback from a teacher (or from oneself) can be cast as a learning-to-learn problem leading to improved cost-aware sequence-to-sequence learning. In experiments on interactive neural machine translation, we find that the self-regulator discovers an $\epsilon$-greedy strategy for the optimal cost-quality trade-off by mixing different feedback types including corrections, error markups, and self-supervision. Furthermore, we demonstrate its robustness under domain shift and identify it as a promising alternative to active learning.
Learning to Segment Inputs for NMT Favors Character-Level Processing
Nov 05, 2018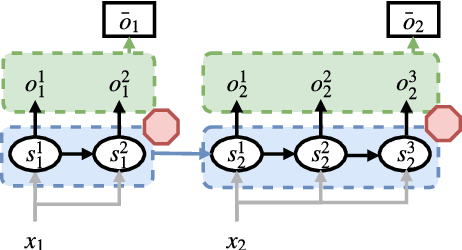
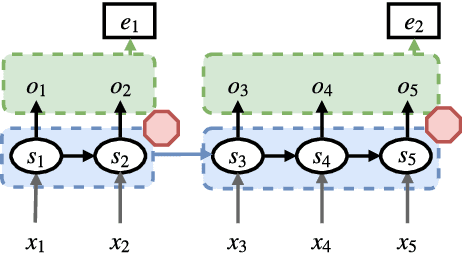
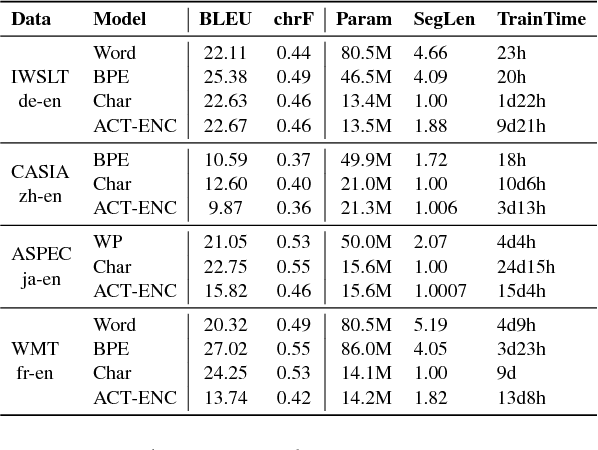
Most modern neural machine translation (NMT) systems rely on presegmented inputs. Segmentation granularity importantly determines the input and output sequence lengths, hence the modeling depth, and source and target vocabularies, which in turn determine model size, computational costs of softmax normalization, and handling of out-of-vocabulary words. However, the current practice is to use static, heuristic-based segmentations that are fixed before NMT training. This begs the question whether the chosen segmentation is optimal for the translation task. To overcome suboptimal segmentation choices, we present an algorithm for dynamic segmentation based on the Adaptative Computation Time algorithm (Graves 2016), that is trainable end-to-end and driven by the NMT objective. In an evaluation on four translation tasks we found that, given the freedom to navigate between different segmentation levels, the model prefers to operate on (almost) character level, providing support for purely character-level NMT models from a novel angle.
Reliability and Learnability of Human Bandit Feedback for Sequence-to-Sequence Reinforcement Learning
Jul 19, 2018
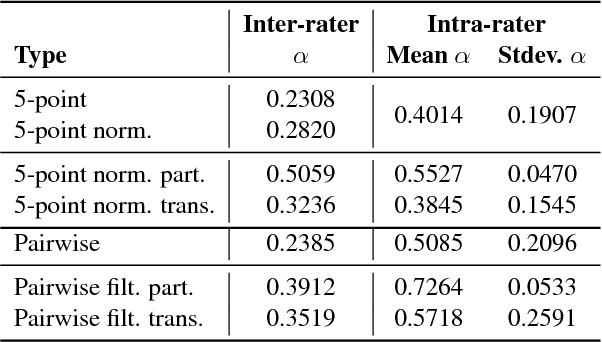
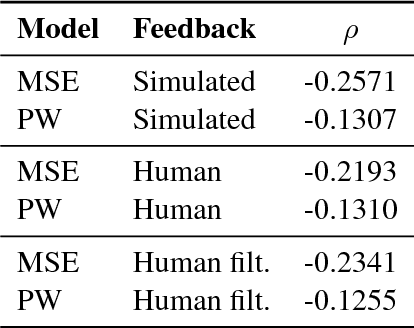
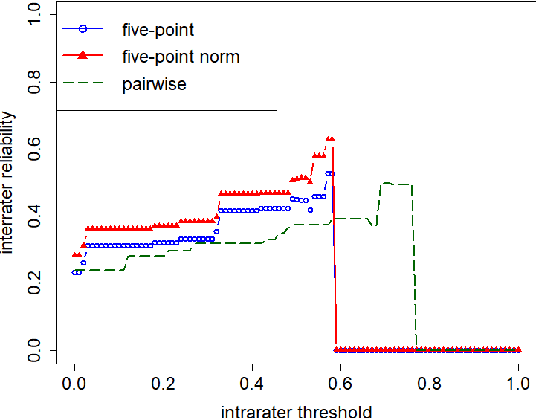
We present a study on reinforcement learning (RL) from human bandit feedback for sequence-to-sequence learning, exemplified by the task of bandit neural machine translation (NMT). We investigate the reliability of human bandit feedback, and analyze the influence of reliability on the learnability of a reward estimator, and the effect of the quality of reward estimates on the overall RL task. Our analysis of cardinal (5-point ratings) and ordinal (pairwise preferences) feedback shows that their intra- and inter-annotator $\alpha$-agreement is comparable. Best reliability is obtained for standardized cardinal feedback, and cardinal feedback is also easiest to learn and generalize from. Finally, improvements of over 1 BLEU can be obtained by integrating a regression-based reward estimator trained on cardinal feedback for 800 translations into RL for NMT. This shows that RL is possible even from small amounts of fairly reliable human feedback, pointing to a great potential for applications at larger scale.