 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022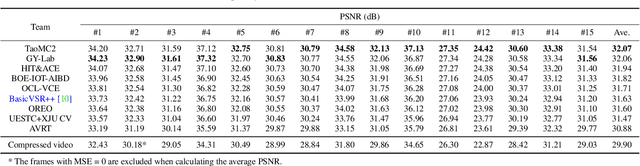
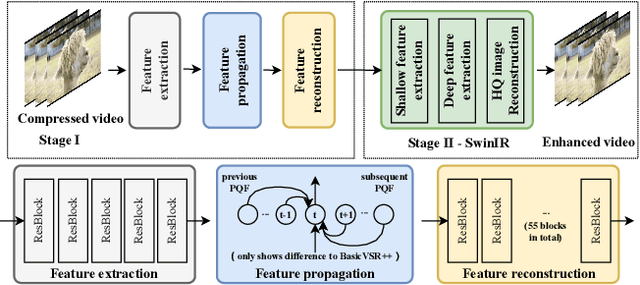
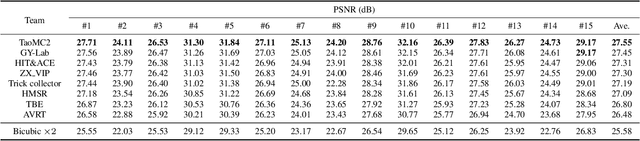

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
DCCRGAN: Deep Complex Convolution Recurrent Generator Adversarial Network for Speech Enhancement
Dec 19, 2020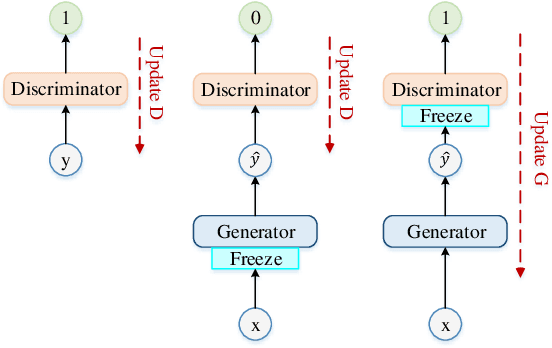
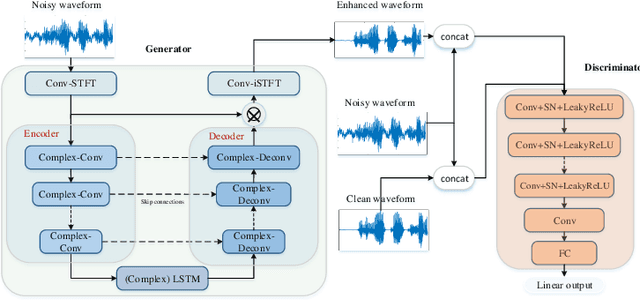
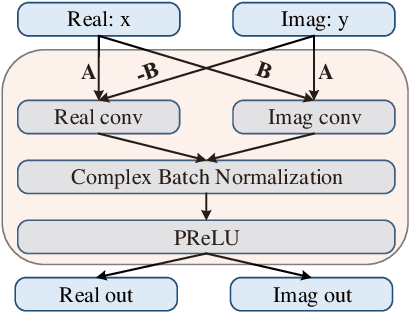
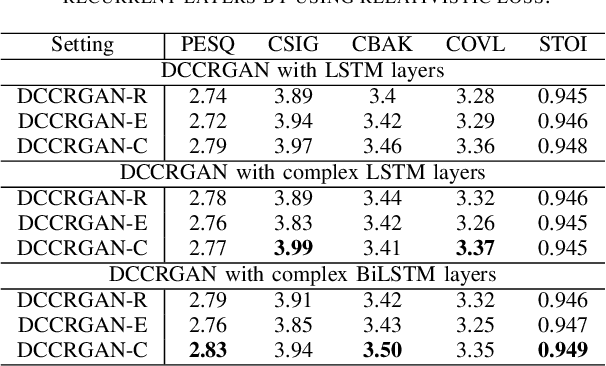
Generative adversarial network (GAN) still exists some problems in dealing with speech enhancement (SE) task. Some GAN-based systems adopt the same structure from Pixel-to-Pixel directly without special optimization. The importance of the generator network has not been fully explored. Other related researches change the generator network but operate in the time-frequency domain, which ignores the phase mismatch problem. In order to solve these problems, a deep complex convolution recurrent GAN (DCCRGAN) structure is proposed in this paper. The complex module builds the correlation between magnitude and phase of the waveform and has been proved to be effective. The proposed structure is trained in an end-to-end way. Different LSTM layers are used in the generator network to sufficiently explore the speech enhancement performance of DCCRGAN. The experimental results confirm that the proposed DCCRGAN outperforms the state-of-the-art GAN-based SE systems.