 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Temp: Relation-Aware Temporal Representation Learning for Temporal Knowledge Graph Completion
Oct 24, 2023



Temporal Knowledge Graph Completion (TKGC) under the extrapolation setting aims to predict the missing entity from a fact in the future, posing a challenge that aligns more closely with real-world prediction problems. Existing research mostly encodes entities and relations using sequential graph neural networks applied to recent snapshots. However, these approaches tend to overlook the ability to skip irrelevant snapshots according to entity-related relations in the query and disregard the importance of explicit temporal information. To address this, we propose our model, Re-Temp (Relation-Aware Temporal Representation Learning), which leverages explicit temporal embedding as input and incorporates skip information flow after each timestamp to skip unnecessary information for prediction. Additionally, we introduce a two-phase forward propagation method to prevent information leakage. Through the evaluation on six TKGC (extrapolation) datasets, we demonstrate that our model outperforms all eight recent state-of-the-art models by a significant margin.
MC-DRE: Multi-Aspect Cross Integration for Drug Event/Entity Extraction
Aug 15, 2023Extracting meaningful drug-related information chunks, such as adverse drug events (ADE), is crucial for preventing morbidity and saving many lives. Most ADEs are reported via an unstructured conversation with the medical context, so applying a general entity recognition approach is not sufficient enough. In this paper, we propose a new multi-aspect cross-integration framework for drug entity/event detection by capturing and aligning different context/language/knowledge properties from drug-related documents. We first construct multi-aspect encoders to describe semantic, syntactic, and medical document contextual information by conducting those slot tagging tasks, main drug entity/event detection, part-of-speech tagging, and general medical named entity recognition. Then, each encoder conducts cross-integration with other contextual information in three ways: the key-value cross, attention cross, and feedforward cross, so the multi-encoders are integrated in depth. Our model outperforms all SOTA on two widely used tasks, flat entity detection and discontinuous event extraction.
Workshop on Document Intelligence Understanding
Jul 31, 2023


Document understanding and information extraction include different tasks to understand a document and extract valuable information automatically. Recently, there has been a rising demand for developing document understanding among different domains, including business, law, and medicine, to boost the efficiency of work that is associated with a large number of documents. This workshop aims to bring together researchers and industry developers in the field of document intelligence and understanding diverse document types to boost automatic document processing and understanding techniques. We also released a data challenge on the recently introduced document-level VQA dataset, PDFVQA. The PDFVQA challenge examines the structural and contextual understandings of proposed models on the natural full document level of multiple consecutive document pages by including questions with a sequence of answers extracted from multi-pages of the full document. This task helps to boost the document understanding step from the single-page level to the full document level understanding.
Tri-level Joint Natural Language Understanding for Multi-turn Conversational Datasets
May 28, 2023Natural language understanding typically maps single utterances to a dual level semantic frame, sentence level intent and slot labels at the word level. The best performing models force explicit interaction between intent detection and slot filling. We present a novel tri-level joint natural language understanding approach, adding domain, and explicitly exchange semantic information between all levels. This approach enables the use of multi-turn datasets which are a more natural conversational environment than single utterance. We evaluate our model on two multi-turn datasets for which we are the first to conduct joint slot-filling and intent detection. Our model outperforms state-of-the-art joint models in slot filling and intent detection on multi-turn data sets. We provide an analysis of explicit interaction locations between the layers. We conclude that including domain information improves model performance.
SimCGNN: Simple Contrastive Graph Neural Network for Session-based Recommendation
Feb 08, 2023



Session-based recommendation (SBR) problem, which focuses on next-item prediction for anonymous users, has received increasingly more attention from researchers. Existing graph-based SBR methods all lack the ability to differentiate between sessions with the same last item, and suffer from severe popularity bias. Inspired by nowadays emerging contrastive learning methods, this paper presents a Simple Contrastive Graph Neural Network for Session-based Recommendation (SimCGNN). In SimCGNN, we first obtain normalized session embeddings on constructed session graphs. We next construct positive and negative samples of the sessions by two forward propagation and a novel negative sample selection strategy, and then calculate the constructive loss. Finally, session embeddings are used to give prediction. Extensive experiments conducted on two real-word datasets show our SimCGNN achieves a significant improvement over state-of-the-art methods.
StockEmotions: Discover Investor Emotions for Financial Sentiment Analysis and Multivariate Time Series
Jan 23, 2023



There has been growing interest in applying NLP techniques in the financial domain, however, resources are extremely limited. This paper introduces StockEmotions, a new dataset for detecting emotions in the stock market that consists of 10,000 English comments collected from StockTwits, a financial social media platform. Inspired by behavioral finance, it proposes 12 fine-grained emotion classes that span the roller coaster of investor emotion. Unlike existing financial sentiment datasets, StockEmotions presents granular features such as investor sentiment classes, fine-grained emotions, emojis, and time series data. To demonstrate the usability of the dataset, we perform a dataset analysis and conduct experimental downstream tasks. For financial sentiment/emotion classification tasks, DistilBERT outperforms other baselines, and for multivariate time series forecasting, a Temporal Attention LSTM model combining price index, text, and emotion features achieves the best performance than using a single feature.
Spoken Language Understanding for Conversational AI: Recent Advances and Future Direction
Dec 21, 2022

When a human communicates with a machine using natural language on the web and online, how can it understand the human's intention and semantic context of their talk? This is an important AI task as it enables the machine to construct a sensible answer or perform a useful action for the human. Meaning is represented at the sentence level, identification of which is known as intent detection, and at the word level, a labelling task called slot filling. This dual-level joint task requires innovative thinking about natural language and deep learning network design, and as a result, many approaches and models have been proposed and applied. This tutorial will discuss how the joint task is set up and introduce Spoken Language Understanding/Natural Language Understanding (SLU/NLU) with Deep Learning techniques. We will cover the datasets, experiments and metrics used in the field. We will describe how the machine uses the latest NLP and Deep Learning techniques to address the joint task, including recurrent and attention-based Transformer networks and pre-trained models (e.g. BERT). We will then look in detail at a network that allows the two levels of the task, intent classification and slot filling, to interact to boost performance explicitly. We will do a code demonstration of a Python notebook for this model and attendees will have an opportunity to watch coding demo tasks on this joint NLU to further their understanding.
SceneGATE: Scene-Graph based co-Attention networks for TExt visual question answering
Dec 16, 2022



Most TextVQA approaches focus on the integration of objects, scene texts and question words by a simple transformer encoder. But this fails to capture the semantic relations between different modalities. The paper proposes a Scene Graph based co-Attention Network (SceneGATE) for TextVQA, which reveals the semantic relations among the objects, Optical Character Recognition (OCR) tokens and the question words. It is achieved by a TextVQA-based scene graph that discovers the underlying semantics of an image. We created a guided-attention module to capture the intra-modal interplay between the language and the vision as a guidance for inter-modal interactions. To make explicit teaching of the relations between the two modalities, we proposed and integrated two attention modules, namely a scene graph-based semantic relation-aware attention and a positional relation-aware attention. We conducted extensive experiments on two benchmark datasets, Text-VQA and ST-VQA. It is shown that our SceneGATE method outperformed existing ones because of the scene graph and its attention modules.
SG-Shuffle: Multi-aspect Shuffle Transformer for Scene Graph Generation
Nov 09, 2022Scene Graph Generation (SGG) serves a comprehensive representation of the images for human understanding as well as visual understanding tasks. Due to the long tail bias problem of the object and predicate labels in the available annotated data, the scene graph generated from current methodologies can be biased toward common, non-informative relationship labels. Relationship can sometimes be non-mutually exclusive, which can be described from multiple perspectives like geometrical relationships or semantic relationships, making it even more challenging to predict the most suitable relationship label. In this work, we proposed the SG-Shuffle pipeline for scene graph generation with 3 components: 1) Parallel Transformer Encoder, which learns to predict object relationships in a more exclusive manner by grouping relationship labels into groups of similar purpose; 2) Shuffle Transformer, which learns to select the final relationship labels from the category-specific feature generated in the previous step; and 3) Weighted CE loss, used to alleviate the training bias caused by the imbalanced dataset.
An Analysis of Deep Reinforcement Learning Agents for Text-based Games
Sep 12, 2022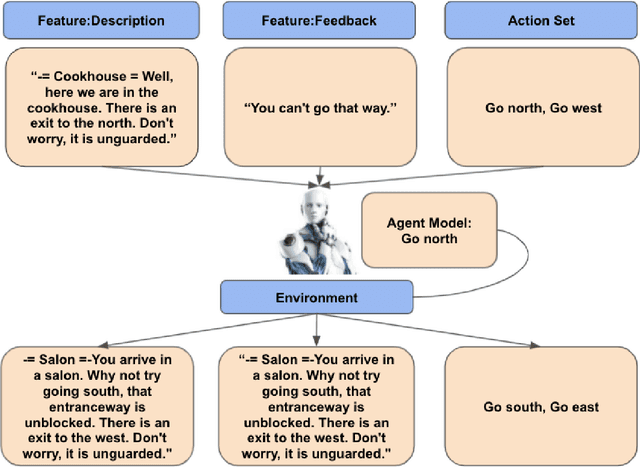
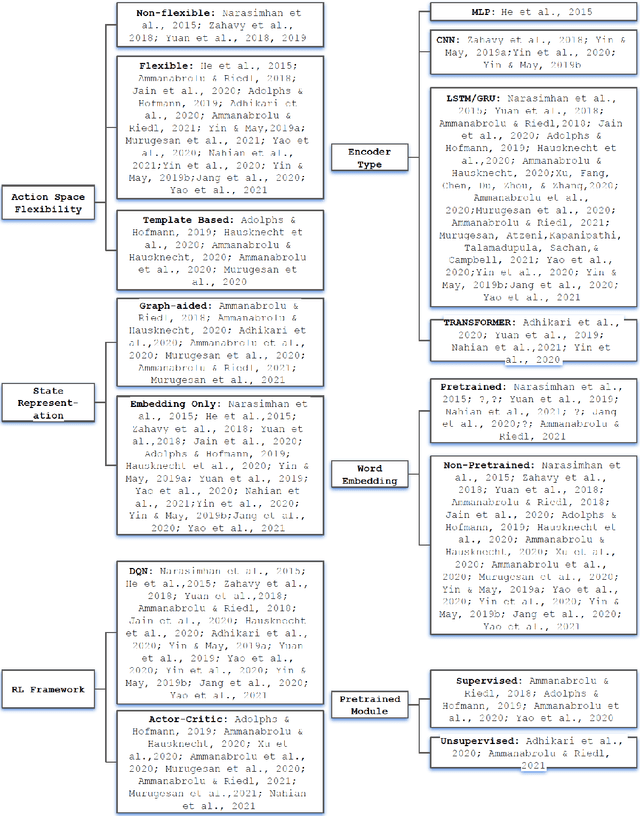
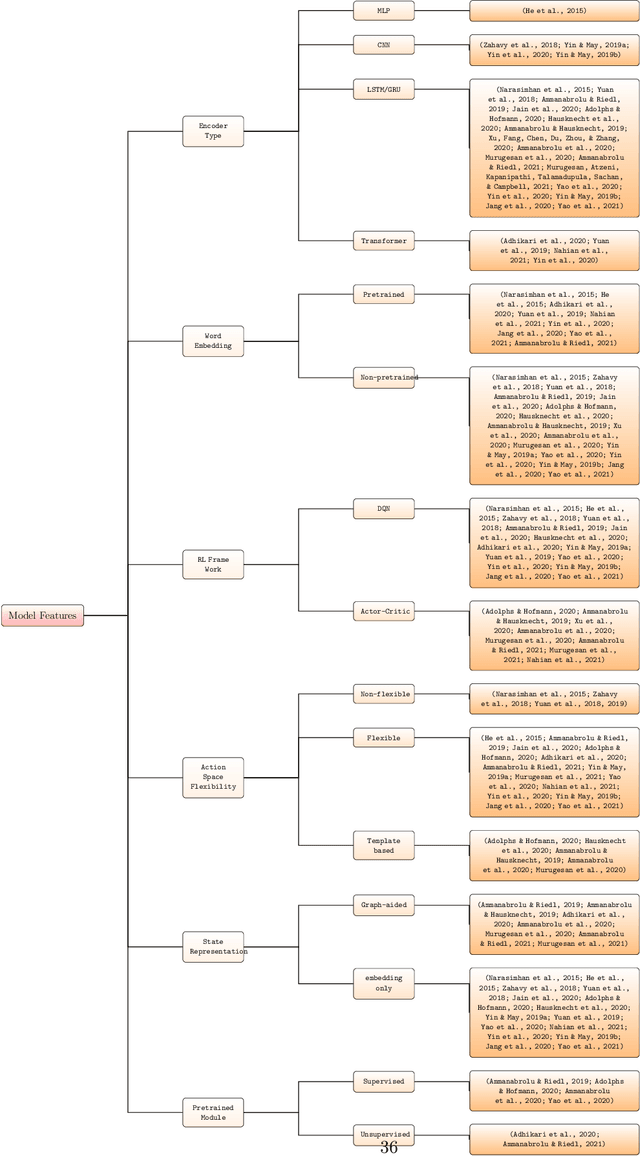
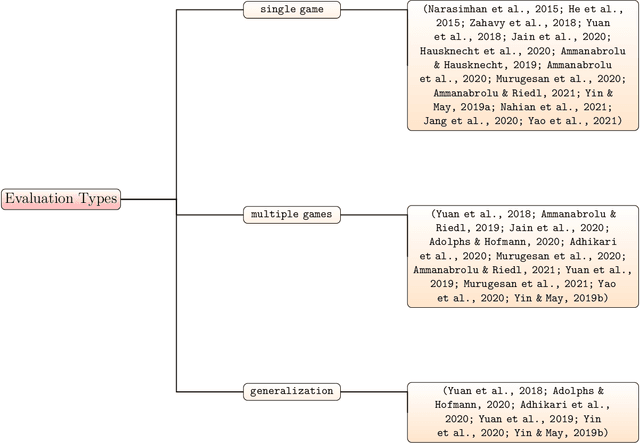
Text-based games(TBG) are complex environments which allow users or computer agents to make textual interactions and achieve game goals.In TBG agent design and training process, balancing the efficiency and performance of the agent models is a major challenge. Finding TBG agent deep learning modules' performance in standardized environments, and testing their performance among different evaluation types is also important for TBG agent research. We constructed a standardized TBG agent with no hand-crafted rules, formally categorized TBG evaluation types, and analyzed selected methods in our environment.