 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Matching via Optimal Transport
Nov 09, 2021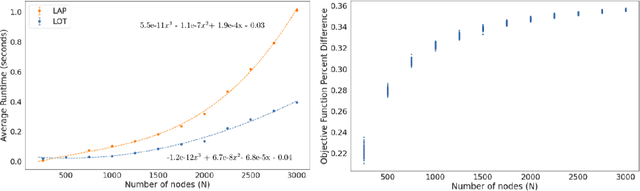
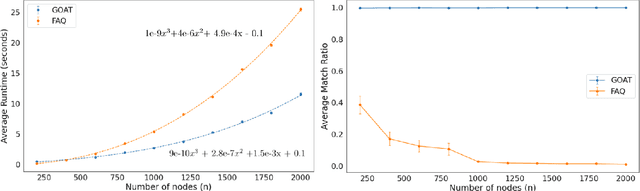
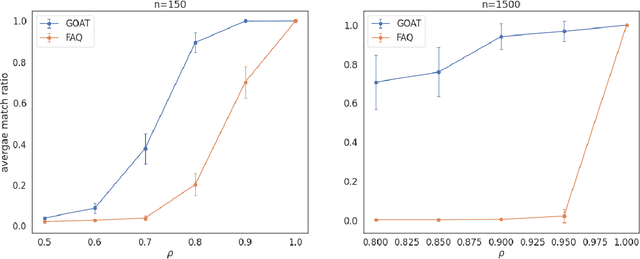
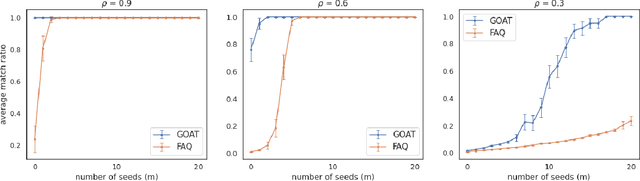
The graph matching problem seeks to find an alignment between the nodes of two graphs that minimizes the number of adjacency disagreements. Solving the graph matching is increasingly important due to it's applications in operations research, computer vision, neuroscience, and more. However, current state-of-the-art algorithms are inefficient in matching very large graphs, though they produce good accuracy. The main computational bottleneck of these algorithms is the linear assignment problem, which must be solved at each iteration. In this paper, we leverage the recent advances in the field of optimal transport to replace the accepted use of linear assignment algorithms. We present GOAT, a modification to the state-of-the-art graph matching approximation algorithm "FAQ" (Vogelstein, 2015), replacing its linear sum assignment step with the "Lightspeed Optimal Transport" method of Cuturi (2013). The modification provides improvements to both speed and empirical matching accuracy. The effectiveness of the approach is demonstrated in matching graphs in simulated and real data examples.
Streaming Decision Trees and Forests
Oct 16, 2021
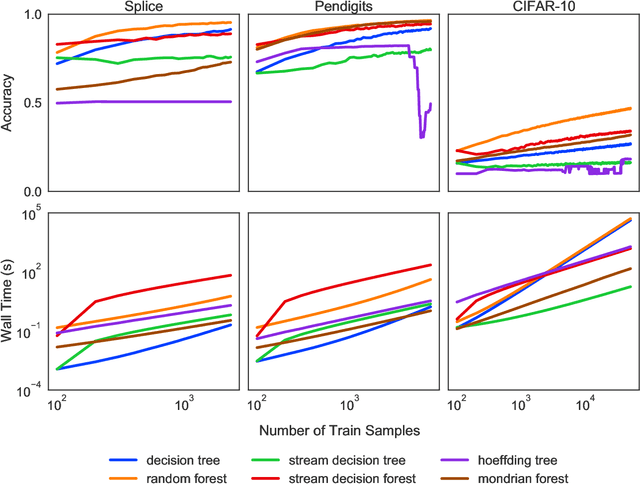
Machine learning has successfully leveraged modern data and provided computational solutions to innumerable real-world problems, including physical and biomedical discoveries. Currently, estimators could handle both scenarios with all samples available and situations requiring continuous updates. However, there is still room for improvement on streaming algorithms based on batch decision trees and random forests, which are the leading methods in batch data tasks. In this paper, we explore the simplest partial fitting algorithm to extend batch trees and test our models: stream decision tree (SDT) and stream decision forest (SDF) on three classification tasks of varying complexities. For reference, both existing streaming trees (Hoeffding trees and Mondrian forests) and batch estimators are included in the experiments. In all three tasks, SDF consistently produces high accuracy, whereas existing estimators encounter space restraints and accuracy fluctuations. Thus, our streaming trees and forests show great potential for further improvements, which are good candidates for solving problems like distribution drift and transfer learning.
Towards a theory of out-of-distribution learning
Oct 07, 2021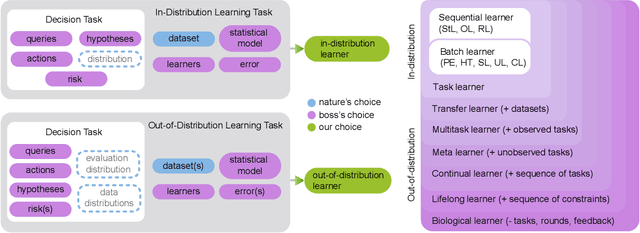
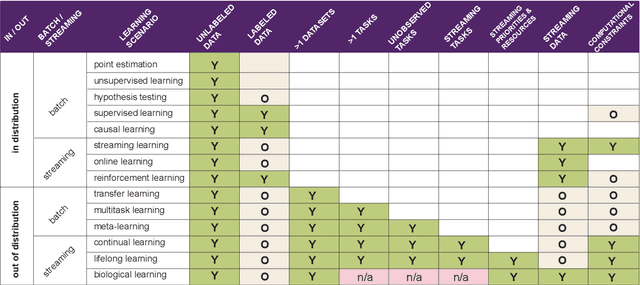
What is learning? 20$^{st}$ century formalizations of learning theory -- which precipitated revolutions in artificial intelligence -- focus primarily on $\mathit{in-distribution}$ learning, that is, learning under the assumption that the training data are sampled from the same distribution as the evaluation distribution. This assumption renders these theories inadequate for characterizing 21$^{st}$ century real world data problems, which are typically characterized by evaluation distributions that differ from the training data distributions (referred to as out-of-distribution learning). We therefore make a small change to existing formal definitions of learnability by relaxing that assumption. We then introduce $\mathbf{learning\ efficiency}$ (LE) to quantify the amount a learner is able to leverage data for a given problem, regardless of whether it is an in- or out-of-distribution problem. We then define and prove the relationship between generalized notions of learnability, and show how this framework is sufficiently general to characterize transfer, multitask, meta, continual, and lifelong learning. We hope this unification helps bridge the gap between empirical practice and theoretical guidance in real world problems. Finally, because biological learning continues to outperform machine learning algorithms on certain OOD challenges, we discuss the limitations of this framework vis-\'a-vis its ability to formalize biological learning, suggesting multiple avenues for future research.
When are Deep Networks really better than Random Forests at small sample sizes?
Aug 31, 2021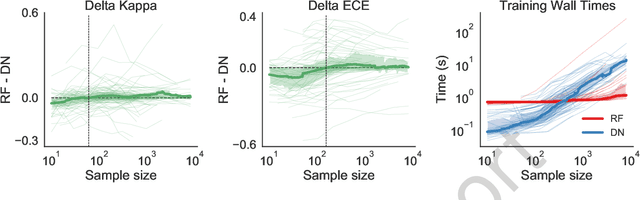

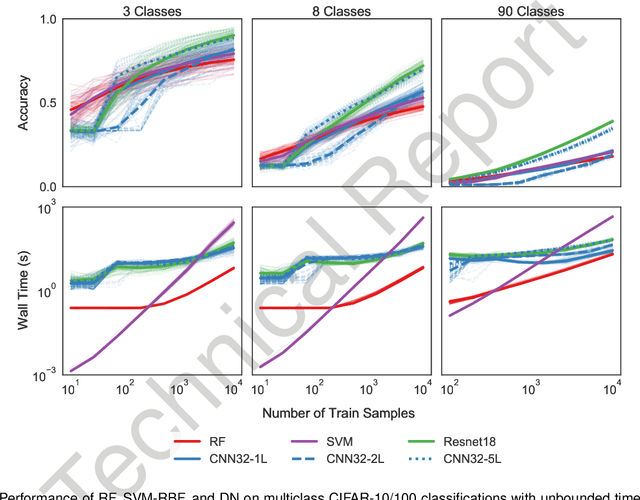
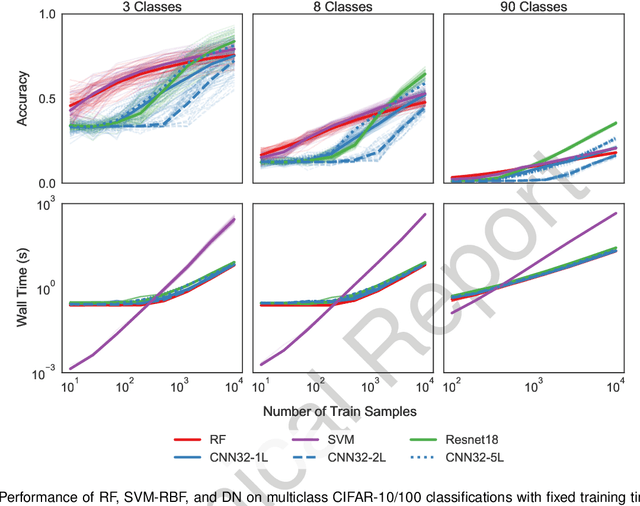
Random forests (RF) and deep networks (DN) are two of the most popular machine learning methods in the current scientific literature and yield differing levels of performance on different data modalities. We wish to further explore and establish the conditions and domains in which each approach excels, particularly in the context of sample size and feature dimension. To address these issues, we tested the performance of these approaches across tabular, image, and audio settings using varying model parameters and architectures. Our focus is on datasets with at most 10,000 samples, which represent a large fraction of scientific and biomedical datasets. In general, we found RF to excel at tabular and structured data (image and audio) with small sample sizes, whereas DN performed better on structured data with larger sample sizes. Although we plan to continue updating this technical report in the coming months, we believe the current preliminary results may be of interest to others.
Federated Causal Inference in Heterogeneous Observational Data
Aug 10, 2021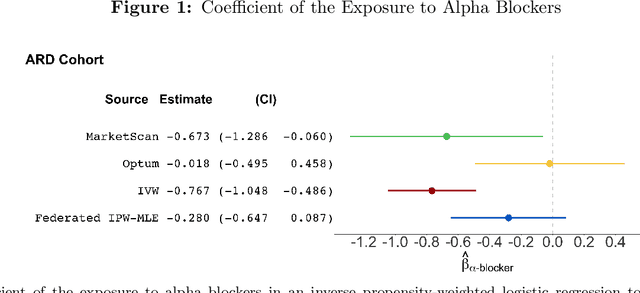

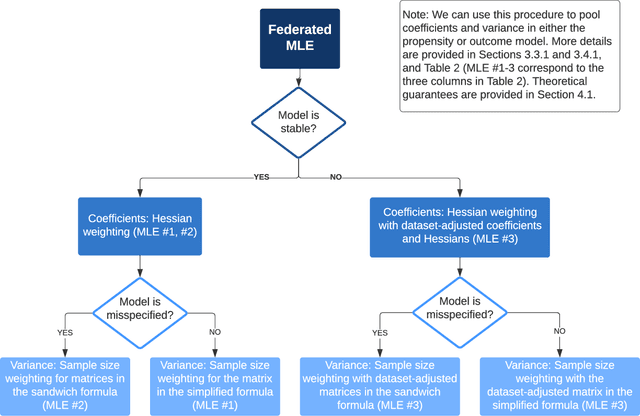
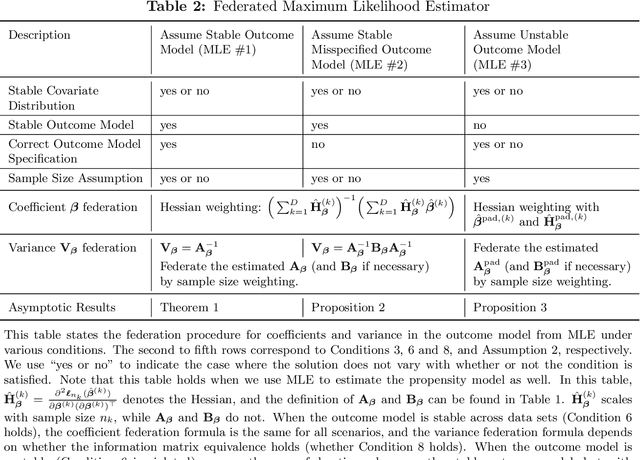
Analyzing observational data from multiple sources can be useful for increasing statistical power to detect a treatment effect; however, practical constraints such as privacy considerations may restrict individual-level information sharing across data sets. This paper develops federated methods that only utilize summary-level information from heterogeneous data sets. Our federated methods provide doubly-robust point estimates of treatment effects as well as variance estimates. We derive the asymptotic distributions of our federated estimators, which are shown to be asymptotically equivalent to the corresponding estimators from the combined, individual-level data. We show that to achieve these properties, federated methods should be adjusted based on conditions such as whether models are correctly specified and stable across heterogeneous data sets.
A partition-based similarity for classification distributions
Nov 12, 2020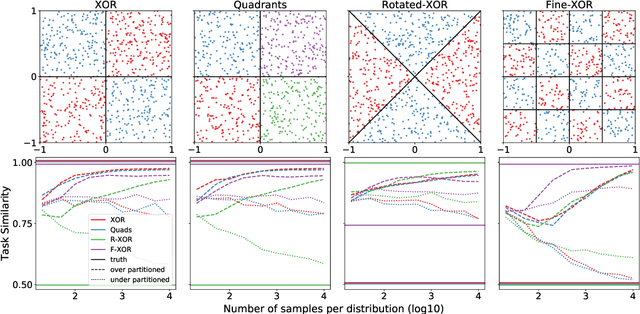
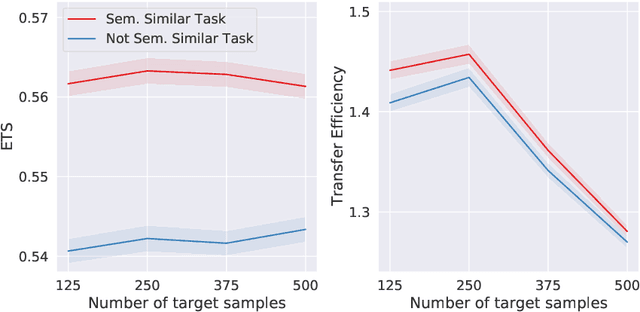
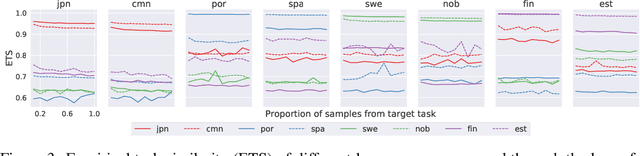
Herein we define a measure of similarity between classification distributions that is both principled from the perspective of statistical pattern recognition and useful from the perspective of machine learning practitioners. In particular, we propose a novel similarity on classification distributions, dubbed task similarity, that quantifies how an optimally-transformed optimal representation for a source distribution performs when applied to inference related to a target distribution. The definition of task similarity allows for natural definitions of adversarial and orthogonal distributions. We highlight limiting properties of representations induced by (universally) consistent decision rules and demonstrate in simulation that an empirical estimate of task similarity is a function of the decision rule deployed for inference. We demonstrate that for a given target distribution, both transfer efficiency and semantic similarity of candidate source distributions correlate with empirical task similarity.
Robust Similarity and Distance Learning via Decision Forests
Aug 21, 2020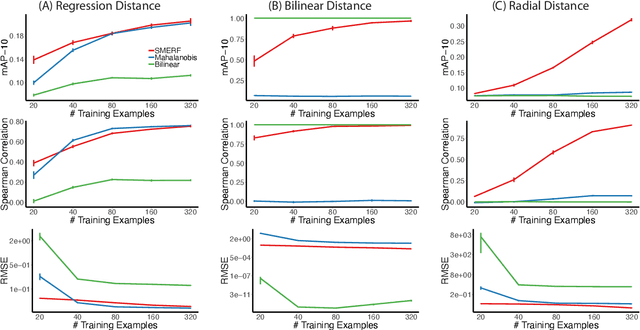
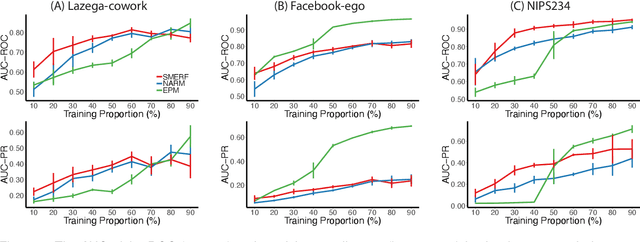
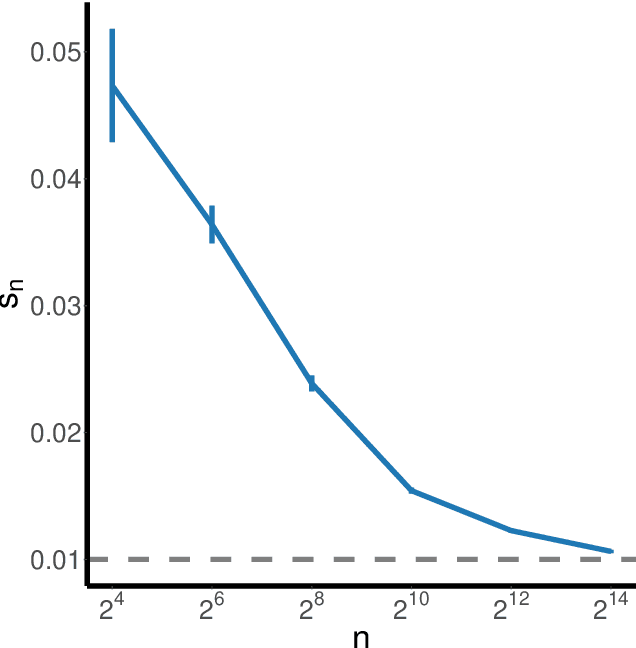
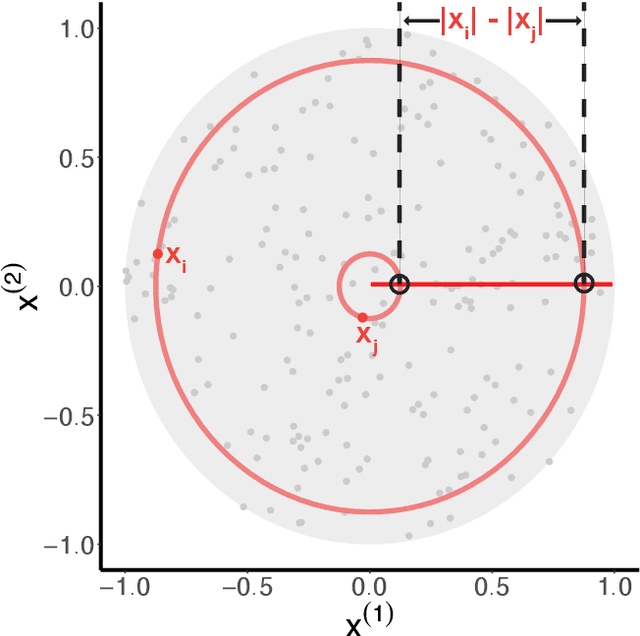
Canonical distances such as Euclidean distance often fail to capture the appropriate relationships between items, subsequently leading to subpar inference and prediction. Many algorithms have been proposed for automated learning of suitable distances, most of which employ linear methods to learn a global metric over the feature space. While such methods offer nice theoretical properties, interpretability, and computationally efficient means for implementing them, they are limited in expressive capacity. Methods which have been designed to improve expressiveness sacrifice one or more of the nice properties of the linear methods. To bridge this gap, we propose a highly expressive novel decision forest algorithm for the task of distance learning, which we call Similarity and Metric Random Forests (SMERF). We show that the tree construction procedure in SMERF is a proper generalization of standard classification and regression trees. Thus, the mathematical driving forces of SMERF are examined via its direct connection to regression forests, for which theory has been developed. Its ability to approximate arbitrary distances and identify important features is empirically demonstrated on simulated data sets. Last, we demonstrate that it accurately predicts links in networks.
mvlearn: Multiview Machine Learning in Python
May 25, 2020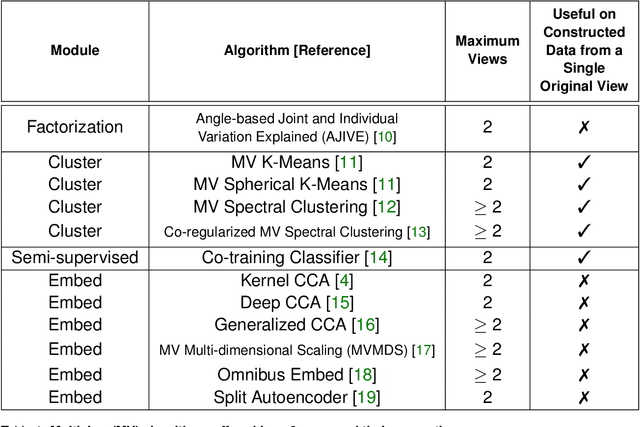
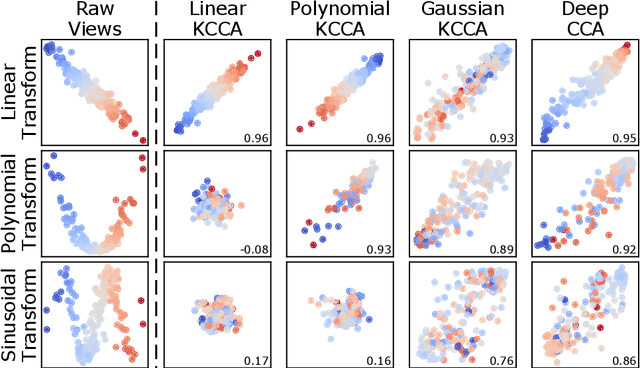

As data are generated more and more from multiple disparate sources, multiview datasets, where each sample has features in distinct views, have ballooned in recent years. However, no comprehensive package exists that enables non-specialists to use these methods easily. mvlearn, is a Python library which implements the leading multiview machine learning methods. Its simple API closely follows that of scikit-learn for increased ease-of-use. The package can be installed from Python Package Index (PyPI) or the conda package manager and is released under the Apache 2.0 open-source license. The documentation, detailed tutorials, and all releases are available at https://mvlearn.neurodata.io/.
Learning to rank via combining representations
May 20, 2020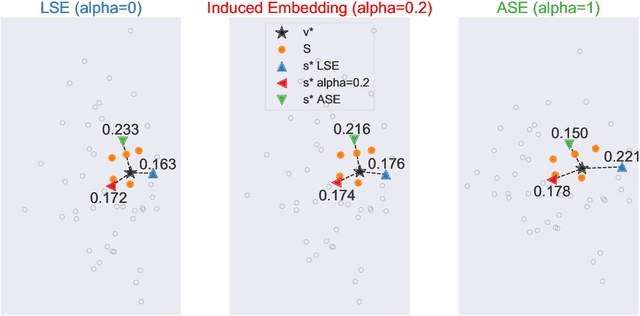
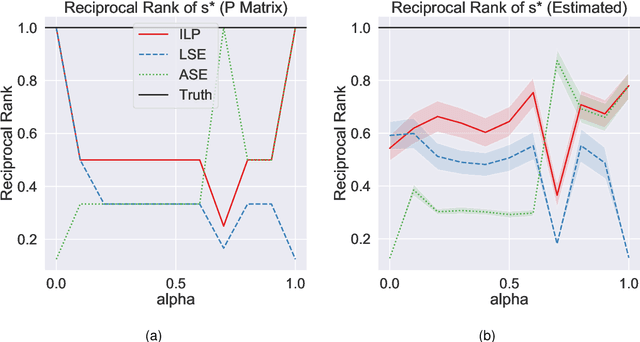
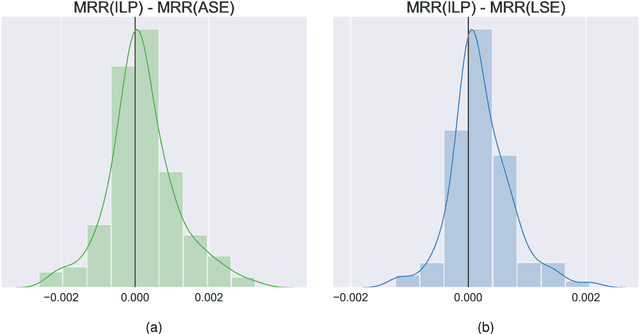
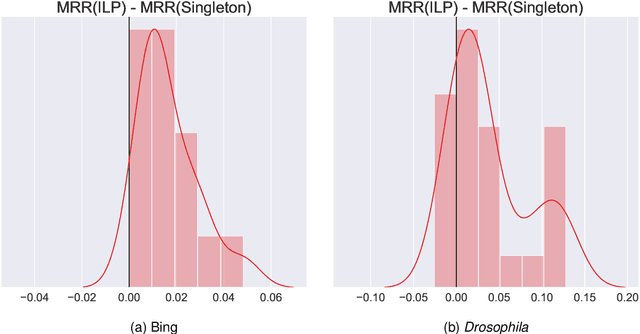
Learning to rank -- producing a ranked list of items specific to a query and with respect to a set of supervisory items -- is a problem of general interest. The setting we consider is one in which no analytic description of what constitutes a good ranking is available. Instead, we have a collection of representations and supervisory information consisting of a (target item, interesting items set) pair. We demonstrate -- analytically, in simulation, and in real data examples -- that learning to rank via combining representations using an integer linear program is effective when the supervision is as light as "these few items are similar to your item of interest." While this nomination task is of general interest, for specificity we present our methodology from the perspective of vertex nomination in graphs. The methodology described herein is model agnostic.
A general approach to progressive learning
Apr 28, 2020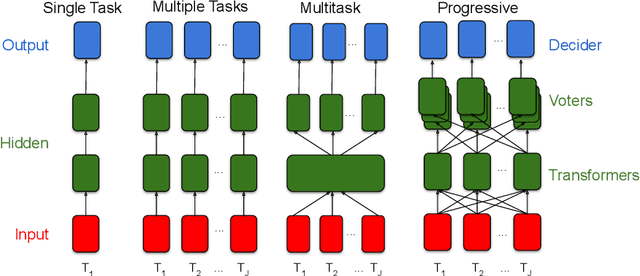


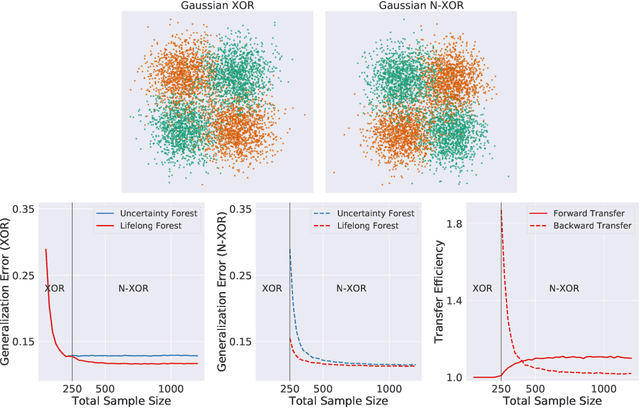
In biological learning, data is used to improve performance on the task at hand, while simultaneously improving performance on both previously encountered tasks and as yet unconsidered future tasks. In contrast, classical machine learning starts from a blank slate, or tabula rasa, using data only for the single task at hand. While typical transfer learning algorithms can improve performance on future tasks, their performance degrades upon learning new tasks. Many recent approaches have attempted to mitigate this issue, called catastrophic forgetting, to maintain performance given new tasks. But striving to avoid forgetting sets the goal unnecessarily low: the goal of progressive learning, whether biological or artificial, is to improve performance on all tasks (including past and future) with any new data. We propose a general approach to progressive learning that ensembles representations, rather than learners. We show that ensembling representations---including representations learned by decision forests or neural networks---enables both forward and backward transfer on a variety of simulated and real data tasks, including vision, language, and adversarial tasks. This work suggests that further improvements in progressive learning may follow from a deeper understanding of how biological learning achieves such high degrees of efficiency.