 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpstreamQA: A Modular Framework for Explicit Reasoning on Video Question Answering Tasks
Apr 25, 2026Video Question Answering (VideoQA) demands models that jointly reason over spatial, temporal, and linguistic cues. However, the task's inherent complexity often requires multi-step reasoning that current large multimodal models (LMMs) perform implicitly, leaving their internal decision process opaque. In contrast, large reasoning models (LRMs) explicitly generate intermediate logical steps that enhance interpretability and can improve multi-hop reasoning accuracy. Yet, these models are not designed for native video understanding, as they typically rely on static frame sampling. We propose UpstreamQA, a modular framework that disentangles and evaluates core video reasoning components through explicit upstream reasoning modules. Specifically, we employ multimodal LRMs to perform object identification and scene context generation before passing enriched reasoning traces to downstream LMMs for VideoQA. We evaluate UpstreamQA on the OpenEQA and NExTQA datasets using two LRMs (o4-mini, Gemini 2.5 Pro) and two LMMs (GPT-4o, Gemini 2.5 Flash). Our results demonstrate that introducing explicit reasoning can significantly boost performance and interpretability of downstream VideoQA, but can also lead to performance degradation when baseline performance is sufficiently high. Overall, UpstreamQA offers a principled framework for combining explicit reasoning and multimodal understanding, advancing both performance and diagnostic transparency in VideoQA in several scenarios.
Anomaly Detection in Cybersecurity: Unsupervised, Graph-Based and Supervised Learning Methods in Adversarial Environments
May 14, 2021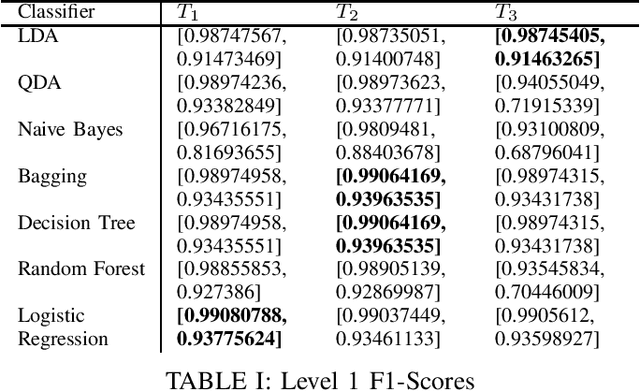
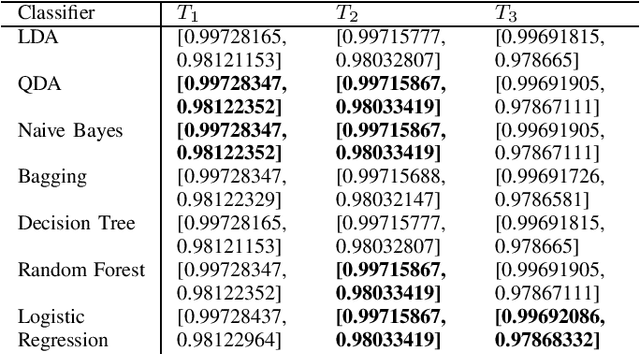

Machine learning for anomaly detection has become a widely researched field in cybersecurity. Inherent to today's operating environment is the practice of adversarial machine learning, which attempts to circumvent machine learning models. In this work, we examine the feasibility of unsupervised learning and graph-based methods for anomaly detection in the network intrusion detection system setting, as well as leverage an ensemble approach to supervised learning of the anomaly detection problem. We incorporate a realistic adversarial training mechanism when training our supervised models to enable strong classification performance in adversarial environments. Our results indicate that the unsupervised and graph-based methods were outperformed in detecting anomalies (malicious activity) by the supervised stacking ensemble method with two levels. This model consists of three different classifiers in the first level, followed by either a Naive Bayes or Decision Tree classifier for the second level. We see that our model maintains an F1-score above 0.97 for malicious samples across all tested level two classifiers. Notably, Naive Bayes is the fastest level two classifier averaging 1.12 seconds while Decision Tree maintains the highest AUC score of 0.98.
mvlearn: Multiview Machine Learning in Python
May 25, 2020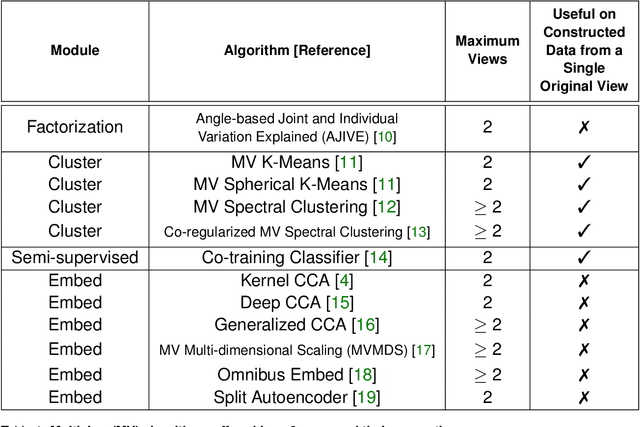
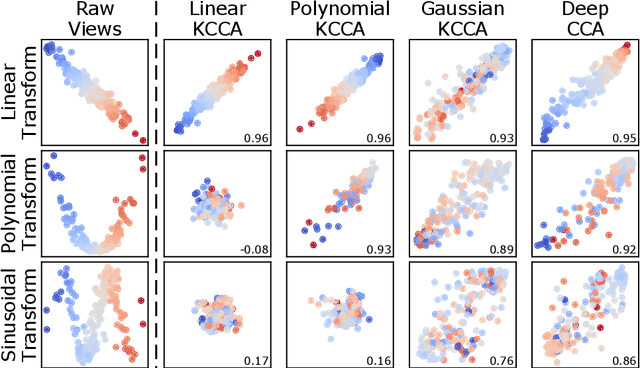

As data are generated more and more from multiple disparate sources, multiview datasets, where each sample has features in distinct views, have ballooned in recent years. However, no comprehensive package exists that enables non-specialists to use these methods easily. mvlearn, is a Python library which implements the leading multiview machine learning methods. Its simple API closely follows that of scikit-learn for increased ease-of-use. The package can be installed from Python Package Index (PyPI) or the conda package manager and is released under the Apache 2.0 open-source license. The documentation, detailed tutorials, and all releases are available at https://mvlearn.neurodata.io/.