 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWrite, Execute, Assess: Program Synthesis with a REPL
Jun 09, 2019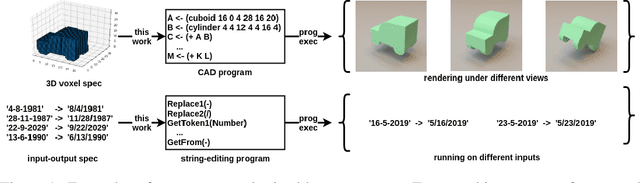
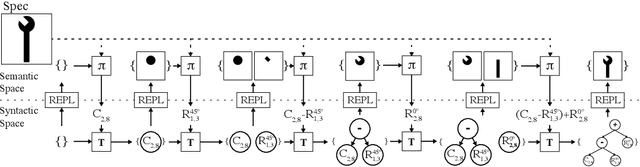
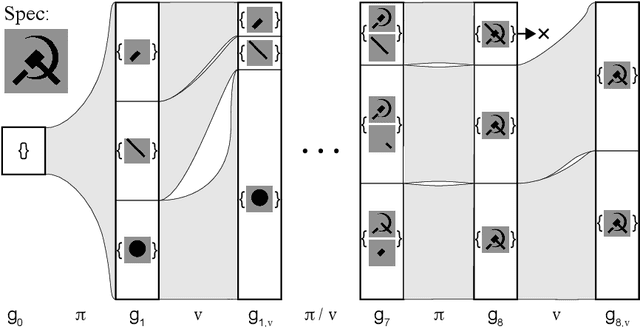
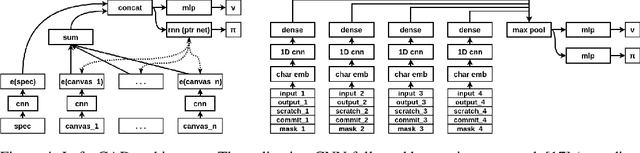
We present a neural program synthesis approach integrating components which write, execute, and assess code to navigate the search space of possible programs. We equip the search process with an interpreter or a read-eval-print-loop (REPL), which immediately executes partially written programs, exposing their semantics. The REPL addresses a basic challenge of program synthesis: tiny changes in syntax can lead to huge changes in semantics. We train a pair of models, a policy that proposes the new piece of code to write, and a value function that assesses the prospects of the code written so-far. At test time we can combine these models with a Sequential Monte Carlo algorithm. We apply our approach to two domains: synthesizing text editing programs and inferring 2D and 3D graphics programs.
Few-Shot Bayesian Imitation Learning with Logic over Programs
Apr 12, 2019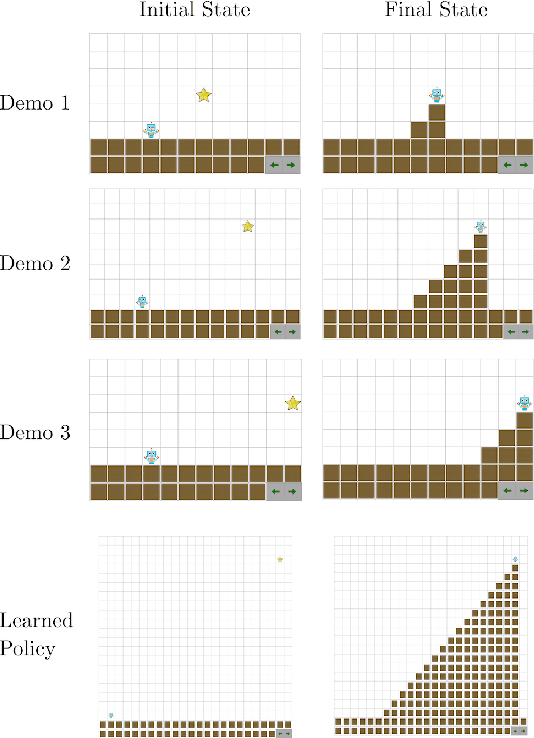



We describe an expressive class of policies that can be efficiently learned from a few demonstrations. Policies are represented as logical combinations of programs drawn from a small domain-specific language (DSL). We define a prior over policies with a probabilistic grammar and derive an approximate Bayesian inference algorithm to learn policies from demonstrations. In experiments, we study five strategy games played on a 2D grid with one shared DSL. After a few demonstrations of each game, the inferred policies generalize to new game instances that differ substantially from the demonstrations. We argue that the proposed method is an apt choice for policy learning tasks that have scarce training data and feature significant, structured variation between task instances.
Residual Policy Learning
Jan 03, 2019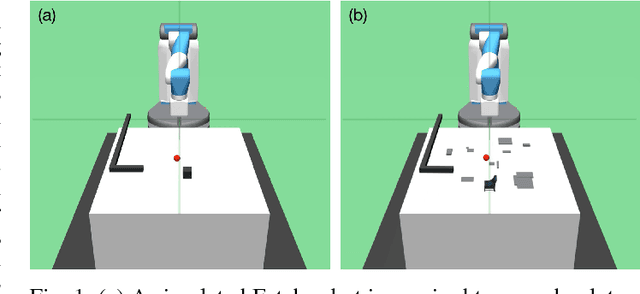
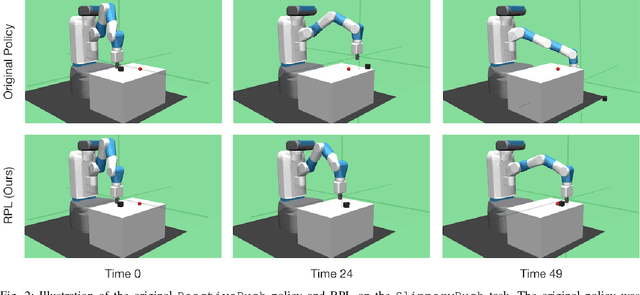
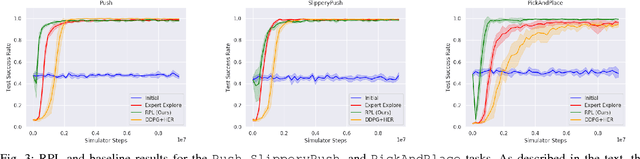
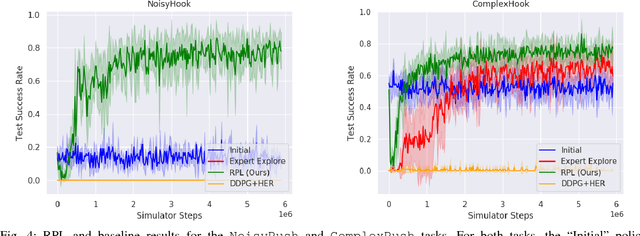
We present Residual Policy Learning (RPL): a simple method for improving nondifferentiable policies using model-free deep reinforcement learning. RPL thrives in complex robotic manipulation tasks where good but imperfect controllers are available. In these tasks, reinforcement learning from scratch remains data-inefficient or intractable, but learning a residual on top of the initial controller can yield substantial improvements. We study RPL in six challenging MuJoCo tasks involving partial observability, sensor noise, model misspecification, and controller miscalibration. For initial controllers, we consider both hand-designed policies and model-predictive controllers with known or learned transition models. By combining learning with control algorithms, RPL can perform long-horizon, sparse-reward tasks for which reinforcement learning alone fails. Moreover, we find that RPL consistently and substantially improves on the initial controllers. We argue that RPL is a promising approach for combining the complementary strengths of deep reinforcement learning and robotic control, pushing the boundaries of what either can achieve independently. Video and code at https://k-r-allen.github.io/residual-policy-learning/.
At Human Speed: Deep Reinforcement Learning with Action Delay
Oct 16, 2018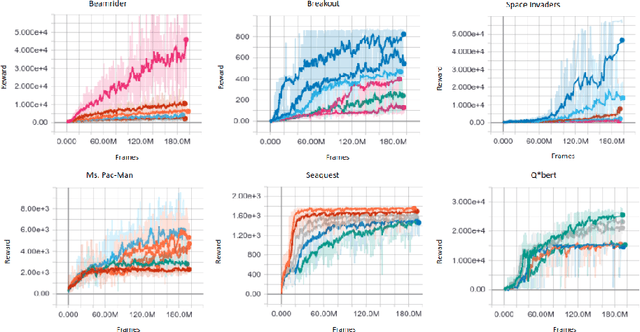

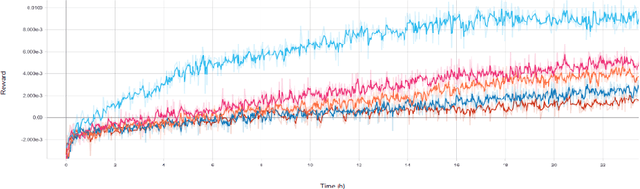
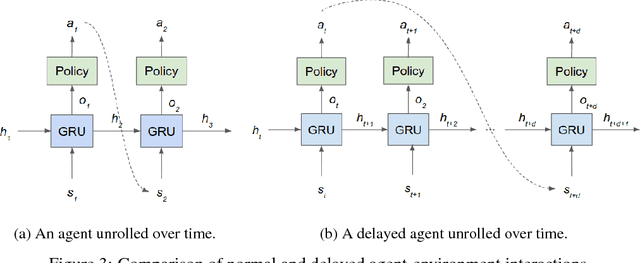
There has been a recent explosion in the capabilities of game-playing artificial intelligence. Many classes of tasks, from video games to motor control to board games, are now solvable by fairly generic algorithms, based on deep learning and reinforcement learning, that learn to play from experience with minimal prior knowledge. However, these machines often do not win through intelligence alone -- they possess vastly superior speed and precision, allowing them to act in ways a human never could. To level the playing field, we restrict the machine's reaction time to a human level, and find that standard deep reinforcement learning methods quickly drop in performance. We propose a solution to the action delay problem inspired by human perception -- to endow agents with a neural predictive model of the environment which "undoes" the delay inherent in their environment -- and demonstrate its efficacy against professional players in Super Smash Bros. Melee, a popular console fighting game.
Logical Rule Induction and Theory Learning Using Neural Theorem Proving
Sep 12, 2018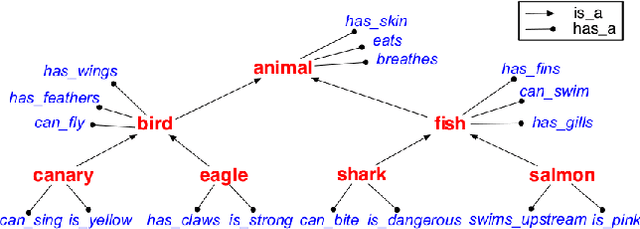
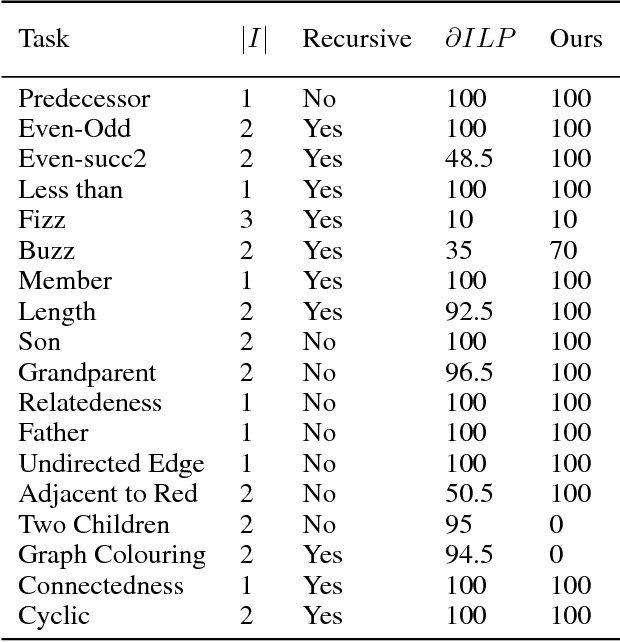
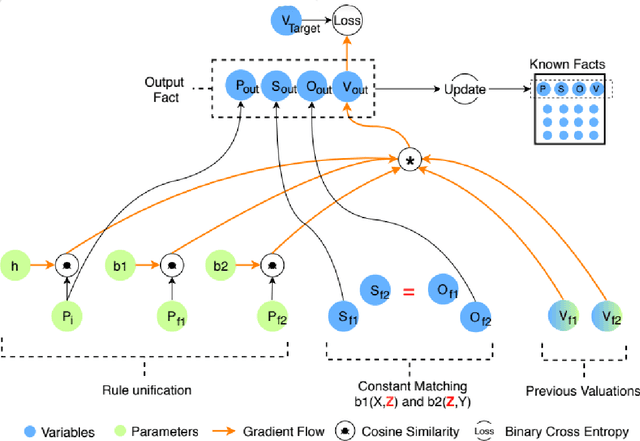
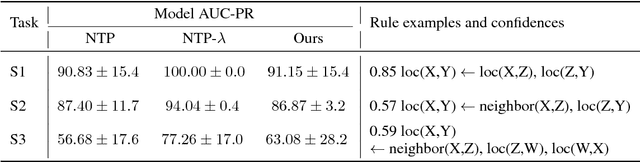
A hallmark of human cognition is the ability to continually acquire and distill observations of the world into meaningful, predictive theories. In this paper we present a new mechanism for logical theory acquisition which takes a set of observed facts and learns to extract from them a set of logical rules and a small set of core facts which together entail the observations. Our approach is neuro-symbolic in the sense that the rule pred- icates and core facts are given dense vector representations. The rules are applied to the core facts using a soft unification procedure to infer additional facts. After k steps of forward inference, the consequences are compared to the initial observations and the rules and core facts are then encouraged towards representations that more faithfully generate the observations through inference. Our approach is based on a novel neural forward-chaining differentiable rule induction network. The rules are interpretable and learned compositionally from their predicates, which may be invented. We demonstrate the efficacy of our approach on a variety of ILP rule induction and domain theory learning datasets.
Learning to Share and Hide Intentions using Information Regularization
Aug 06, 2018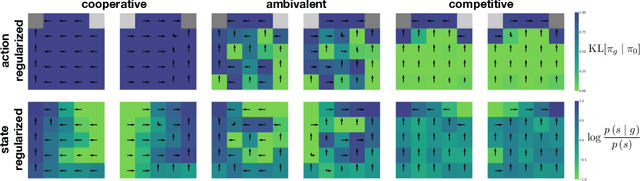
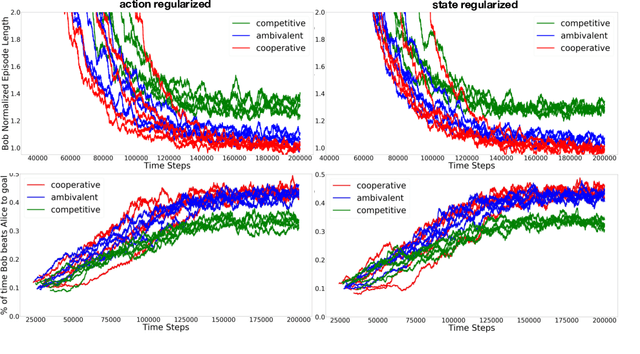
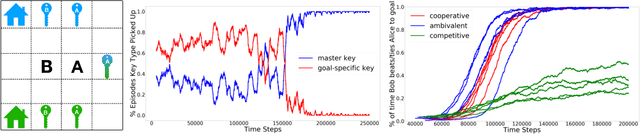
Learning to cooperate with friends and compete with foes is a key component of multi-agent reinforcement learning. Typically to do so, one requires access to either a model of or interaction with the other agent(s). Here we show how to learn effective strategies for cooperation and competition in an asymmetric information game with no such model or interaction. Our approach is to encourage an agent to reveal or hide their intentions using an information-theoretic regularizer. We consider both the mutual information between goal and action given state, as well as the mutual information between goal and state. We show how to stochastically optimize these regularizers in a way that is easy to integrate with policy gradient reinforcement learning. Finally, we demonstrate that cooperative (competitive) policies learned with our approach lead to more (less) reward for a second agent in two simple asymmetric information games.
A Computational Model of Commonsense Moral Decision Making
Jan 12, 2018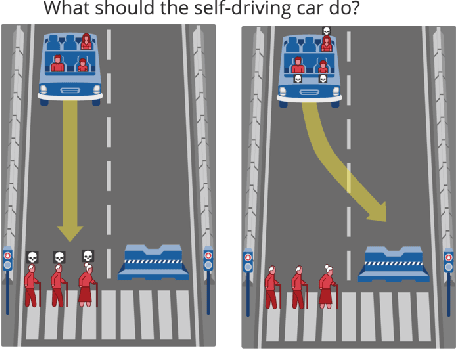

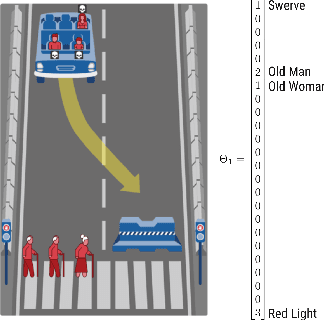
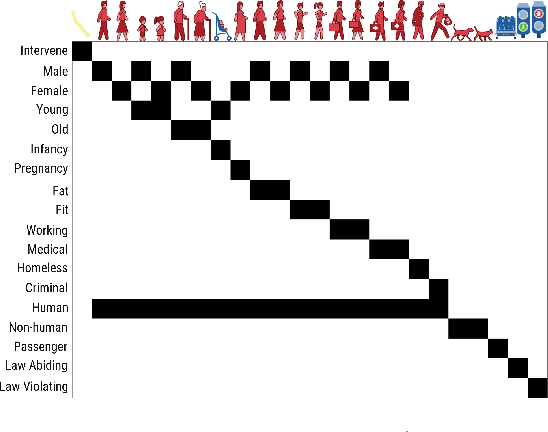
We introduce a new computational model of moral decision making, drawing on a recent theory of commonsense moral learning via social dynamics. Our model describes moral dilemmas as a utility function that computes trade-offs in values over abstract moral dimensions, which provide interpretable parameter values when implemented in machine-led ethical decision-making. Moreover, characterizing the social structures of individuals and groups as a hierarchical Bayesian model, we show that a useful description of an individual's moral values - as well as a group's shared values - can be inferred from a limited amount of observed data. Finally, we apply and evaluate our approach to data from the Moral Machine, a web application that collects human judgments on moral dilemmas involving autonomous vehicles.
Physical problem solving: Joint planning with symbolic, geometric, and dynamic constraints
Jul 25, 2017
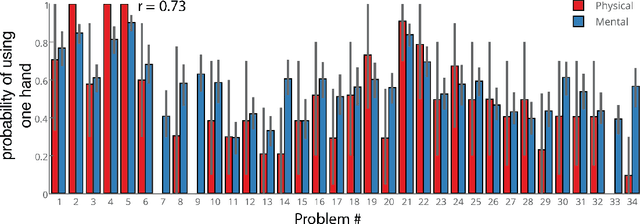
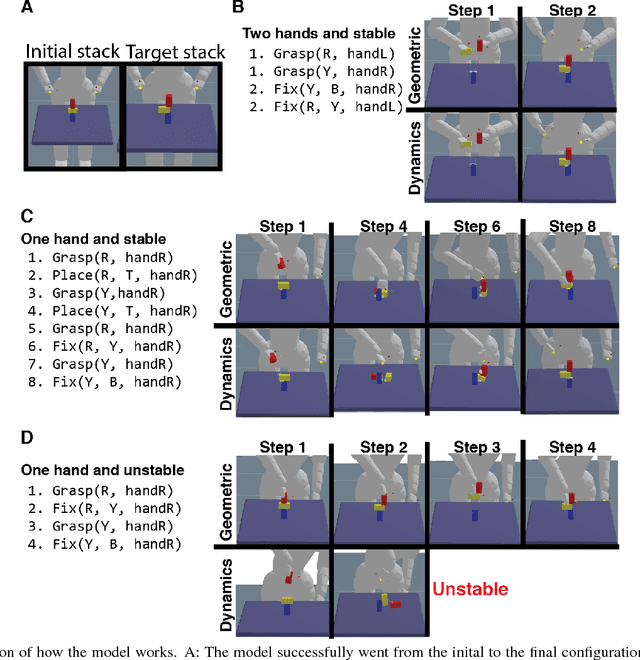
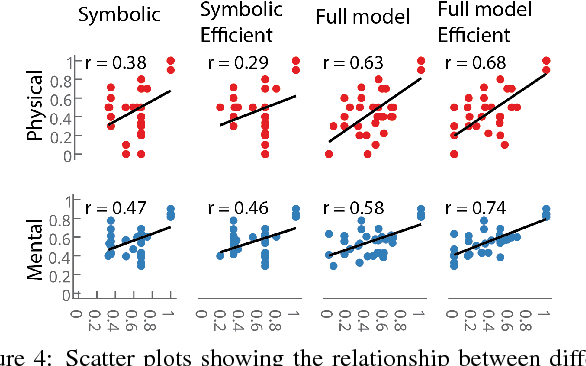
In this paper, we present a new task that investigates how people interact with and make judgments about towers of blocks. In Experiment~1, participants in the lab solved a series of problems in which they had to re-configure three blocks from an initial to a final configuration. We recorded whether they used one hand or two hands to do so. In Experiment~2, we asked participants online to judge whether they think the person in the lab used one or two hands. The results revealed a close correspondence between participants' actions in the lab, and the mental simulations of participants online. To explain participants' actions and mental simulations, we develop a model that plans over a symbolic representation of the situation, executes the plan using a geometric solver, and checks the plan's feasibility by taking into account the physical constraints of the scene. Our model explains participants' actions and judgments to a high degree of quantitative accuracy.